长文多图,建议先star再看
做一下必要的介绍:
- 小一使用的Python版本是3.8
- 开发环境是Pycharm2019.3
- 图形可视化使用matplotlib+seaborn+echarts
为了显示美观,部分截图是在Jupyter 下运行的结果,大家不用纠结
使用echarts 是因为小一做过前端的一些开发,对echarts 的使用还相对熟悉点,文章中主要会用echarts 来做热力图
这是一篇关于深圳租房数据分析的文章
文章会对深圳整体、各区域的租房价格、房屋属性等多个维度进行分析
也会对深圳的租房价格洼地、热点区域分布等进行相关探索
首先,今天的数据集来自于之前的爬虫项目:
今天的分析流程主要分为以下三步:
- 提出问题&问题分析
- 数据预处理
- 可视化分析与探索
如果对数据分析流程还不是很了解的同学可以看看前面的这篇文章:
想必在提出问题之前,避免问题太大太夸张不能完成,我们得先了解一下数据都有什么
这里直接拿爬虫的需求字段数据看一下
# 数据字段
city: 城市
house_id:房源编号
house_rental_method:房租出租方式:整租/合租/不限
house_address:房屋地址:城市/行政区/小区/地址
house_longitude:经度
house_latitude:纬度
house_layout:房屋户型
house_rental_area:房屋出租面积
house_rental_price:房屋出租价格
house_update_time:房源维护时间
house_orientation:房屋朝向
house_tag:房屋标签
house_floor:房屋楼层
house_elevator:是否有电梯
house_parking:房屋车位
house_water:房屋用水
house_electricity:房屋用电
house_gas:房屋燃气
house_heating:房屋采暖
create_time:创建时间
house_note:房屋备注
一共21个字段,共21750条数据
到这你可能会有疑问了,为什么先进行这个步骤?
在我们上面的22个特征中,会存在一些主要特征
像地址、房租价格、面积这些,是我们重点要分析的特征,而像房屋用水、用电、采暖这些就属于次要特征,可以进行辅助参考
就类似你去租房的时候你会首先考虑房屋的水电吗?你肯定是看了户型和价格觉得可以才会继续问水电,甚至就算水电不符合你的要求你也可能会说服自己租下的
在数据的21个特征中,其中主要数据特征包括:
- 出租方式(整租 or 合租)
- 地址(行政区-区域-小区名)
- 经纬度(房源经纬度数据)
- 格局(x室x厅x卫)
- 面积(xx m?)
- 价格(xxxx元/月)
房源编号、创建时间、采暖、备注等特征为多余特征
房源编号是房子的唯一标识,我们用小区名可以替代
深圳是沿海城市,暖气这个词似乎很遥远
创建时间没有可对比性
如果你的数据时间跨度比较大,可以做环比分析,这个时候时间字段就有用了,今天我们暂且用不上
剩下的特征都是次要特征,主要描述房屋的一些附加属性,例如车位、楼层、燃气等
重头戏来啦,我们需要解决的问题是什么?
小一我每次搬家找房子的时候都会超级焦虑,每次都是
所以在准备做这个项目时就立刻有一个目标:如何找一个便宜又超值的房子?
嗯!也就是文章的标题,我要租个好房
我们都知道地铁口周围的房租会贵很多,那么我们知道了房源分布和价格,能不能模拟出城市的地铁线路?
这,是小一想到的第二个问题
另外,小一目前是做运营商网络数据分析的,所以就想着这个项目能够对网络的运营优化有一点点帮助,或者有个参考思路也行
这,是小一想到的第三个问题
自己提的问题流着泪也要想出解决方法
对于上面的三个问题,我们首先需要对深圳的租房数据做一个整体统计
通过整体分布情况再次细分需要研究的数据特征,通过特征结果筛选分析确定最终的心仪目标
整体就是一个总—分的思想,从整体中选出符合要求的部分,针对部分再次分析,筛选、分析......
对于本次数据,我们可以从以下几个问题去进行分析:
- 深圳整体房源出租方式比例是什么样的?
- 深圳的房源数量分布是什么样的?
- 房租价格分布呢?
- 价格相对便宜的房源分布在哪些区域?
- 这些区域的房租、房源数据分布?
- ......
这样我们就可以在目标的导向下,一步步的去细分数据,去靠近目标,并完成最终的探索分析
终于到了预处理这一步,前面学习的Pandas、NumPy 都能派上用场了,是不是有点小激动?
问题已经明确,数据也都准备好了,开始我们的第一个难题:数据预处理
数据预处理我们需要处理以下问题:
- 数据统计、分布情况
- 找出缺失数据,选用合适的方法处理
- 找出异常数据,选用合适的方法处理
- 数据合并重塑
先来看一下数据的分布情况
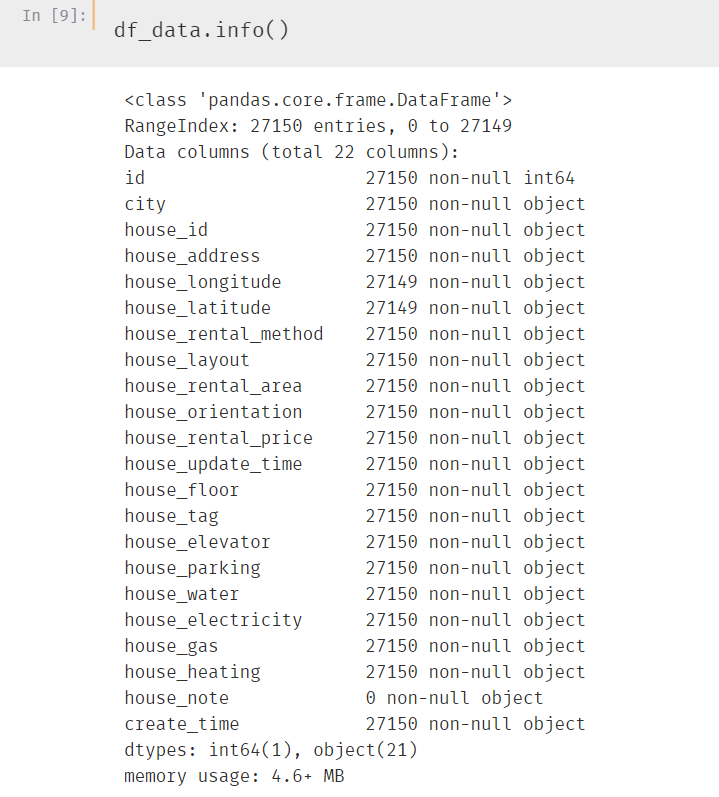
一共22个字段,其中house_note 全部为空,经纬度数据有一条为空,其他全部不为空
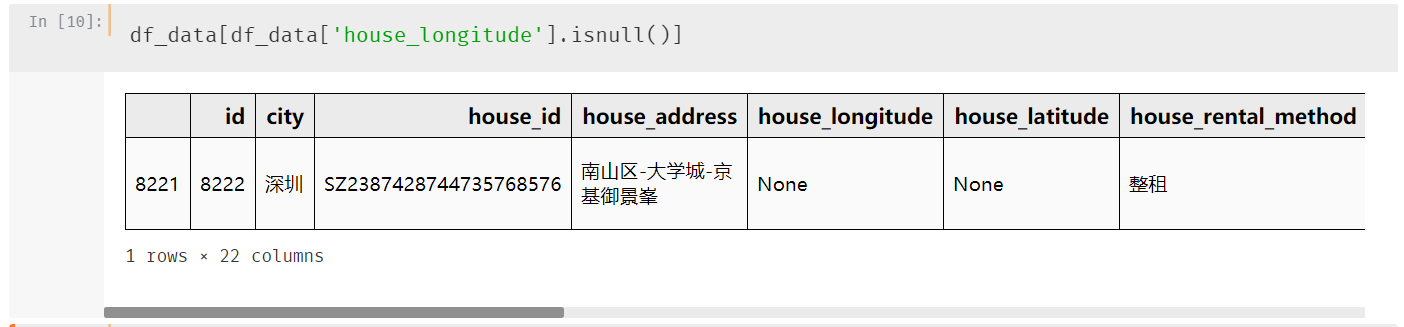
等一下,经纬度只有一条空数据,是不是可以先处理一下?
ok,满足你,看一下缺失经纬度的数据
这里直接用最简单粗暴的处理方式:
去百度坐标拾取系统输入房屋地址拿到经纬度信息
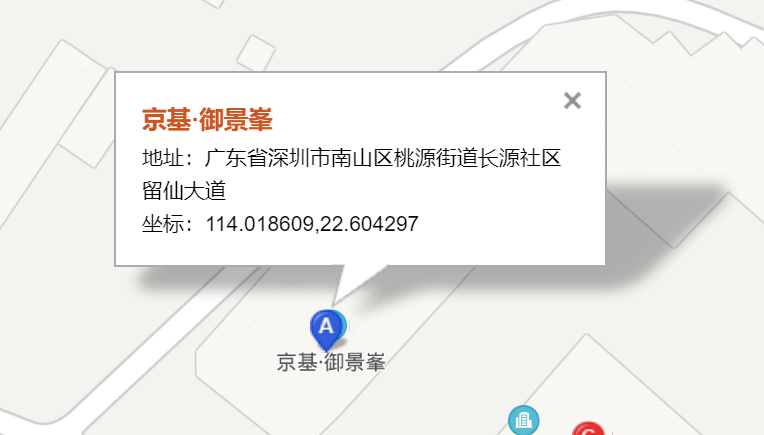
# 使用经纬度填充异常值
df_data.loc[df_data.house_longitude.isnull(), 'house_longitude'] = 114.018609
df_data.loc[df_data.house_latitude.isnull(), 'house_latitude'] = 22.604297再来看字段:22个字段中,房源编号、房屋备注、房源维护时间、创建时间、供暖等五个字段可以直接删除
我们在提出问题的时候已经分析过可以删除的原因
# 即删除房源编号、供暖、房屋备注、房源维护时间和创建时间字段
df_data.drop(columns=['city', 'house_id', 'house_update_time', 'create_time', 'house_heating', 'house_note'],
axis=1, inplace=True
)剩余的字段中,我们需要挨个处理,一起来看一下
1. 出租方式应该有:整租/合租 这两种,如果不是的话需要处理【需要处理】
2. 地址中的:可以划分为行政区+区域+详细地址【需要处理】
3. 经度&纬度:应该是float 类型,如果不是的话转换一下即可 【需要处理】
4. 户型:标准应该是xx室xx厅xx卫,如果不是的话进行合理处理 【需要处理】
5. 出租面积:应该是一个float 类型的数值,如果再严格点应该是int 类型 【需要处理】
6. 出租价格:应该是int 类型的数值 【需要处理】
7. 房屋标签:官方核验、近地铁、精装等标签都比较有用 【需要处理】
8. 所在楼层:高中低+楼层 【需要处理】
9. 是否有电梯:是|否 【需要处理】
10. 用水、用电:民水民电和商水商电,这两个字段可以确定小区的性质 【需要处理】
11. 提供车位:感觉无关紧要,先放着 【暂不处理】
12. 房屋燃气:感觉无关紧要,先放着 【暂不处理】
基本上数据的要求都列出来了,目前我们就先按照这个流程来
第一个字段:出租方式
先统计一下都有哪些房屋出租方式,

看来很规整,整租和合租都整的明明白白,没有异常数据,不需要再进行处理
第二个字段:地址
房屋地址的数据格式是行政区-区域-详细地址
直接通过split 方法进行划分,划分为行政区、区域、小区地址三列
等等,如果地址为空呢?刚好是 "--" 的这种形式呢?
对,所以我们先检测一下是否存在这样的数据

果然存在,有一条数据。
我们已知它的经纬度,直接通过经纬度去匹配数据集中的周边小区
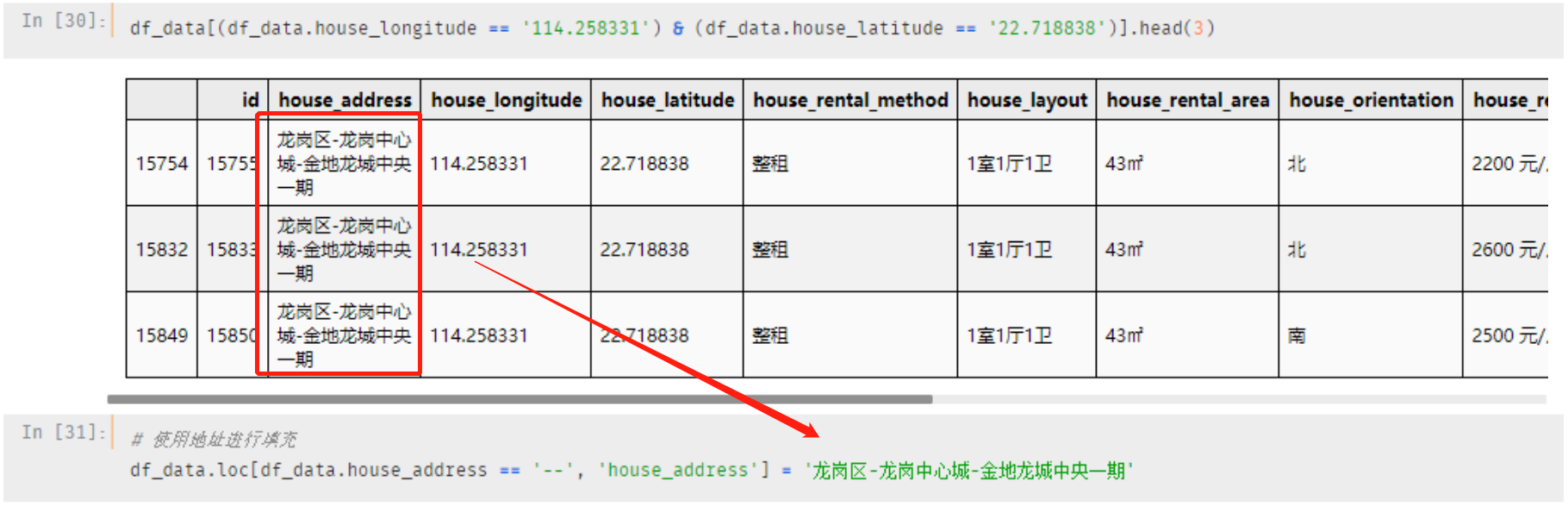
可能有人会说:就一条数据,删了就完事了,还搞这么麻烦?
如果说这个字段不是主要字段,或者我们没有能力去填充它,那可能删了就删了。
题外话:数据清洗的难点在于过程的繁琐,而不是因为它的技术复杂,希望大家有点点耐心哈
接上面的,利用地址进行字段切分
# 将地址字段划分为行政区、区域和小区地址
df_data['station'] = df_data['house_address'].apply(lambda str: str.split('-')[0])
df_data['area'] = df_data['house_address'].apply(lambda str: str.split('-')[1])
df_data['address'] = df_data['house_address'].apply(lambda str: str.split('-')[2])你可能以为这一步就结束了,细心点的同学会发现这样处理完之后存在空数据
其中有7个区域字段为空,看看是什么样的
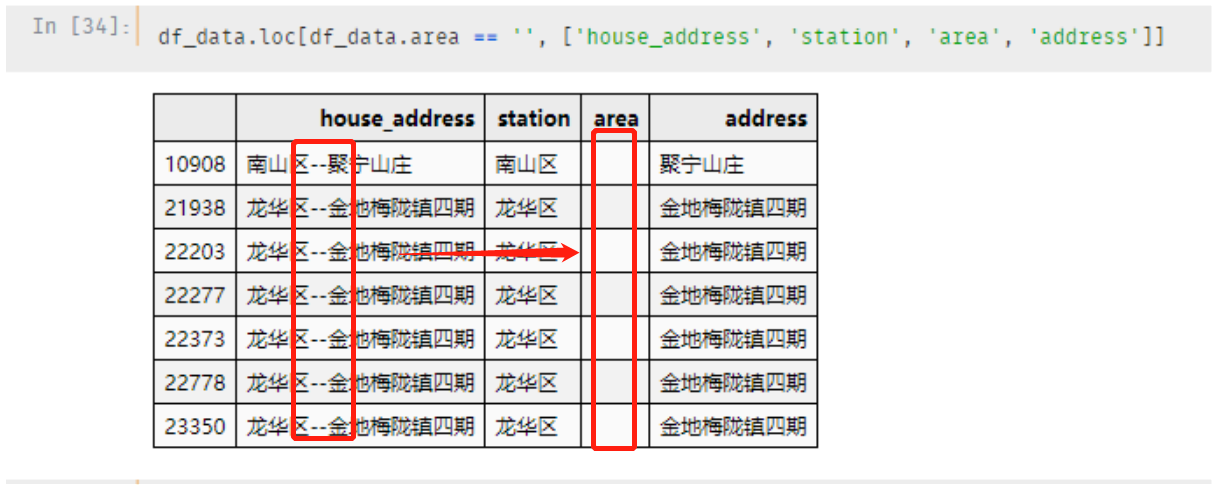
中间的区域内容缺失,造成了切分字符串的时候为空
这一步小一是这样处理的
- 通过小区名查询到区域不为空的同名小区
- 使用同名小区的区域数据进行填充
即用同名小区的区域字段去填充(后面也会多次用到这个填充方法)
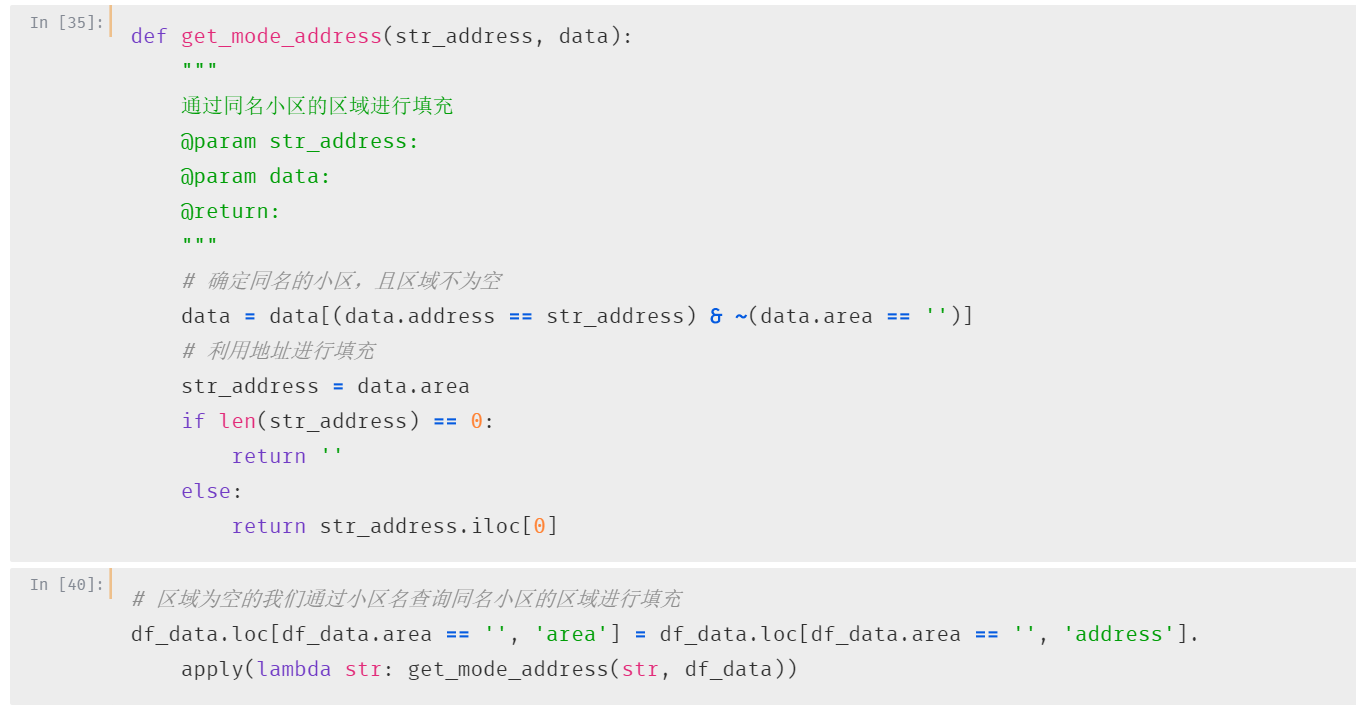
最后只有一条记录“南山区--聚宁山庄“没有区域,需要我们手动填充一下。
# 手动填充
df_data.loc[df_data.id == 10909, 'area'] = '西丽'第三个字段:经度&纬度
将数据直接转换为float 类型即可
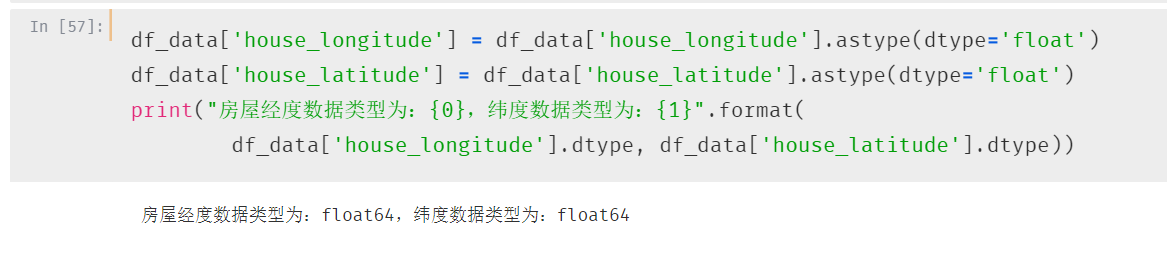
第四个字段:经度&纬度
剔除m?,并将数据转换成int
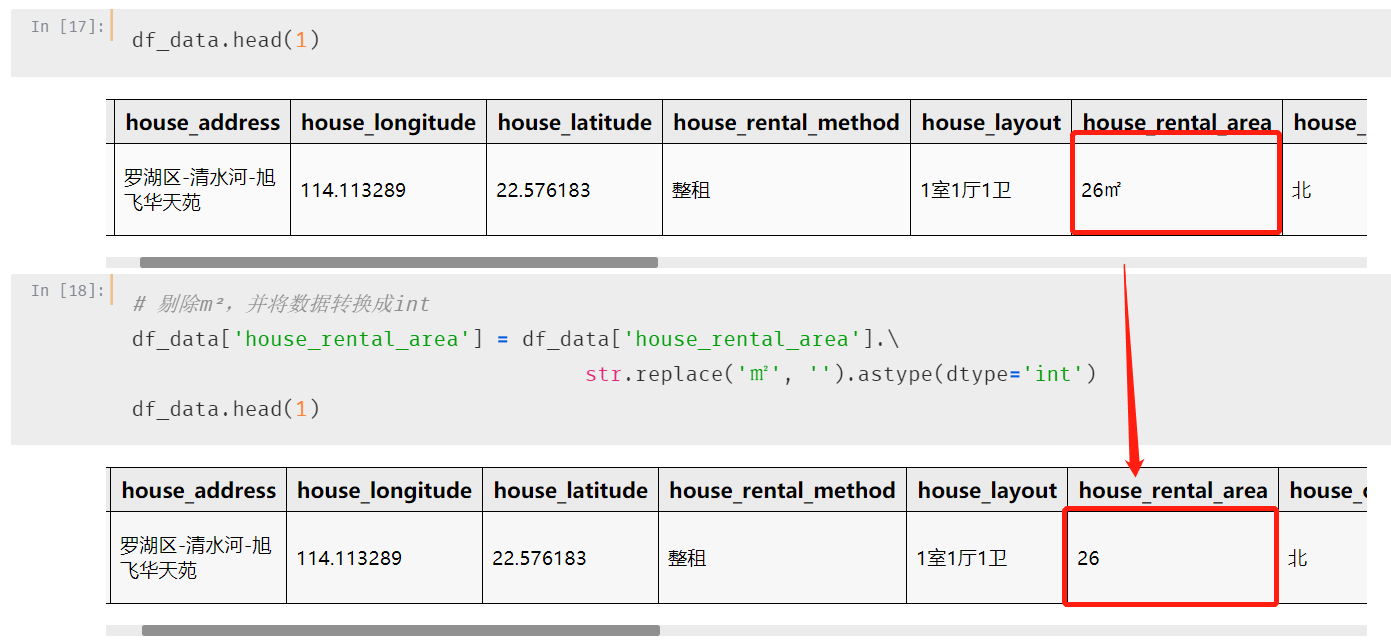
第五个字段:户型
户型数据应该是规整的xx室xx厅xx卫的格式,这样我们可以通过正则去匹配一下,如果都匹配到那就正常
import re
# 验证户型格式
df_data['house_layout'].map(lambda str: re.findall(r'^\d+室\d厅\d卫', str)[0]).shape[0]不幸的是,报错了,检查之后发现“未知”的这种户型

同样的方法,使用同名小区的户型众数进行填充
如果不存在同名小区,则根据房屋的面积进行填充(粗略的标准,见代码if 部分)

第六个字段:房租价格
只保留价格数据,' 元/月'需要删除,注意空格
这里使用正则搞定:\d+表示至少为一个0-9的数字
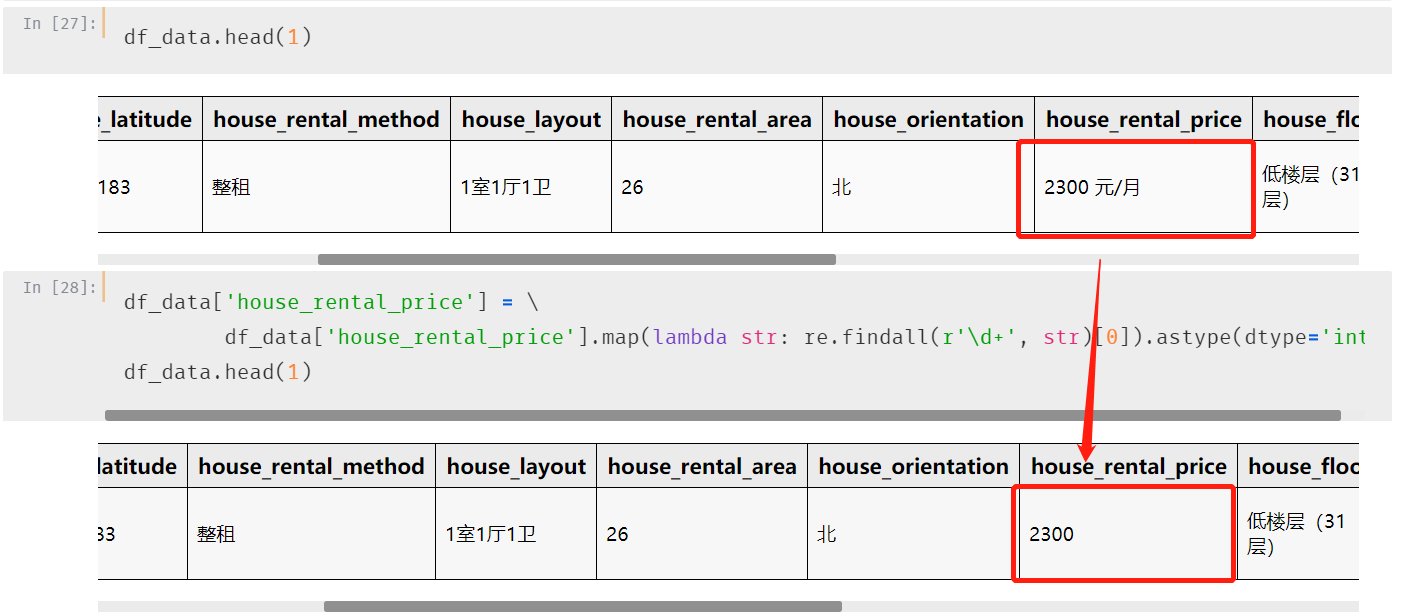
从图中可以看到,处理后变为单纯的数字
第七个字段:房屋标签
去掉房屋标签的头尾 / ,并通过 / 进行划分
df_data['house_tag'] = df_data['house_tag'].str.slice(1, -1)

可以看到,每个记录中都包括不止一个标签,到底哪个标签标记最多?最多是多少次?
我们将在可视化部分继续分析
第八个字段:房屋楼层
这个数据很有迷惑性,先来看一下数据
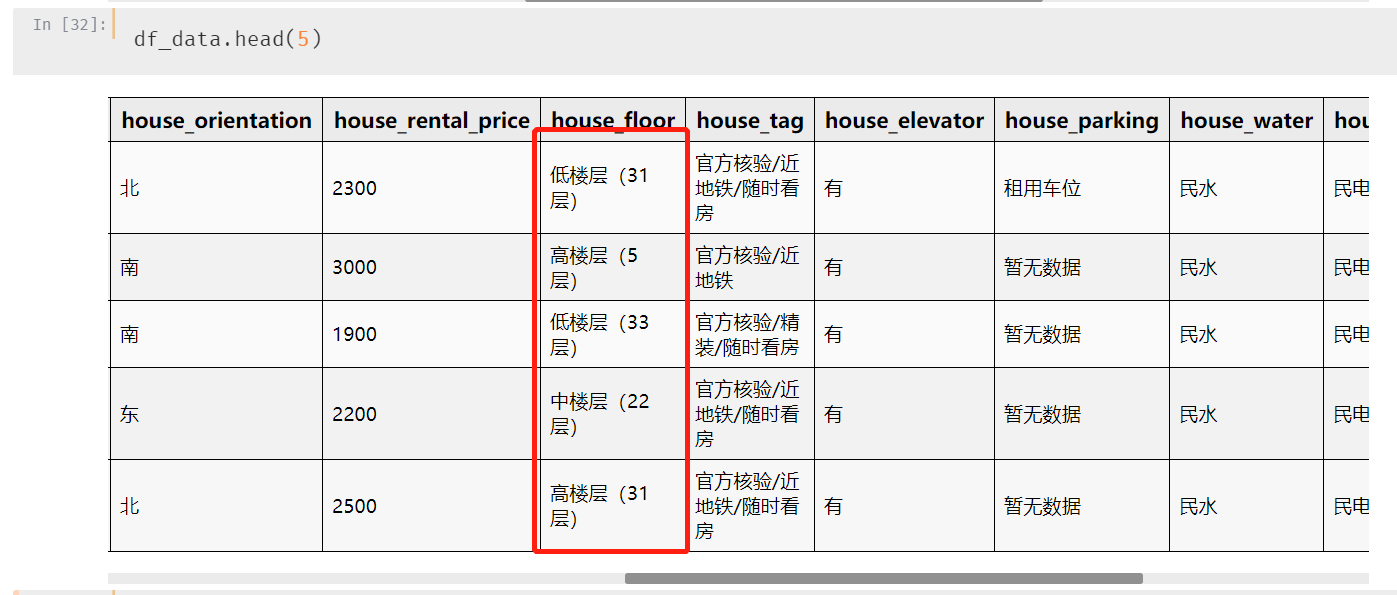
前面的楼层高中低是根据后面的具体楼层来看的,但是31层楼的高楼层和5层楼的高楼层并不能比较
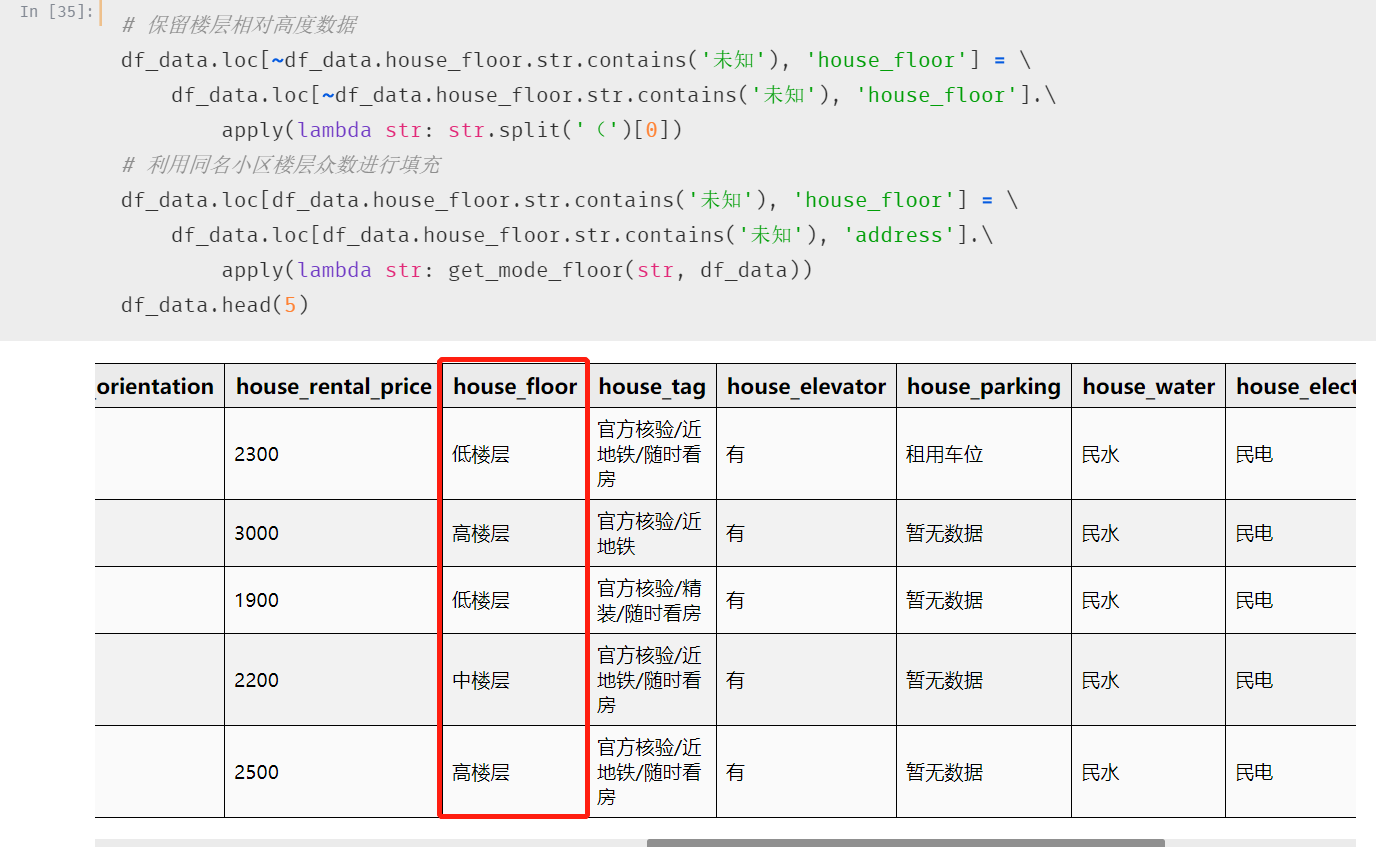
这里我们取直接保留前面的楼层范围,取一个相对值
另外,对于显示“未知”的楼层,我们通过同名小区的楼层众数进行填充
处理后效果如下:
第九个字段:是否有电梯
同样存在缺失数据,使用和楼层同样的处理方式进行处理
并且针对无同名小区的数据通过前面的楼层高度数据进行填充
例如:低楼层的默认无电梯
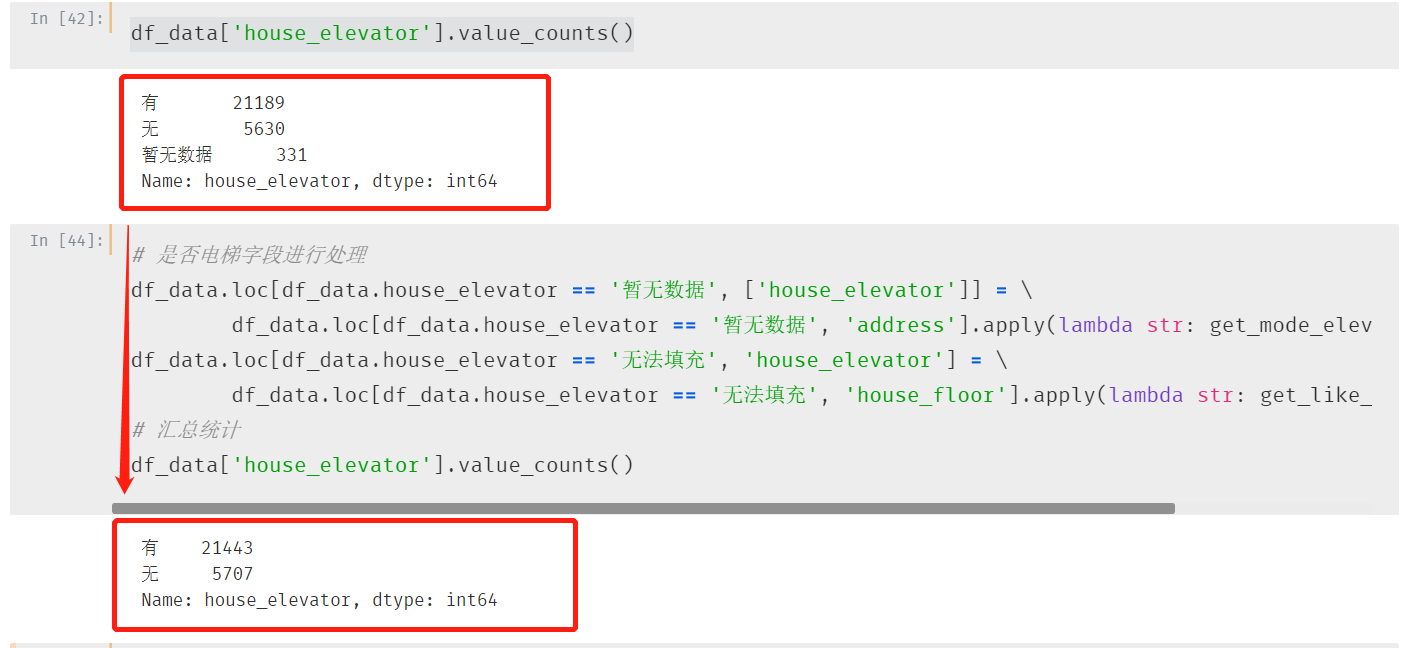
对331 个缺失数据进行了相应的填充
第九、十个字段:提供停车位&提供燃气
这两个字段属于我们直接看一下统计情况
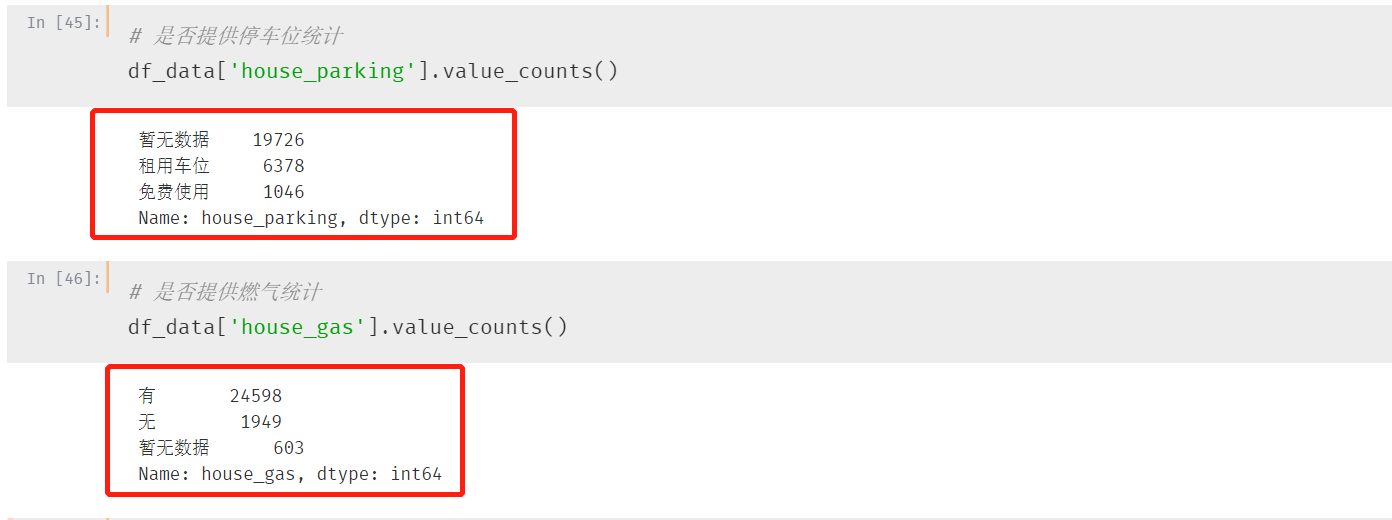
缺失数据较多,而且没有有用的填充方法,这两个字段我们了解就行
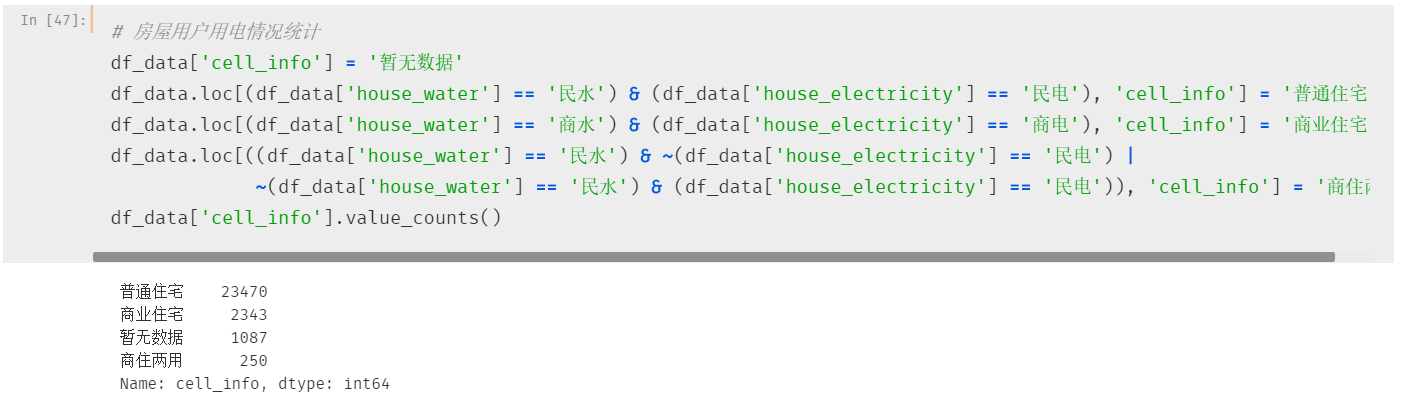
最后两个字段:用水&用电
通过水电字段可以将房屋分为普通住宅、商业住宅、商住两用三种
(房屋性质这个欢迎补充,这个领域小一真不了解,补课也没查到多少,555)
终于,我们的重头戏算是落下帷幕了,你会发现,数据清洗的过程就是一个不断的去寻找方法验证数据、填充数据的过程。
这个验证、填充方法一定要合理,要和实际的业务结合,本文中的业务指实际的租房现状。
读到这,请思考一个问题,我们的数据现在一定是对的吗?
一起来看看漂亮的图表吧
同样,我们在进行可视化之前,得先明确一下目的:
- 异常数据的检查与处理
- 单特征对房租价格的影响
- 多个特征下房租价格的分布情况
- 热力图探索地铁路线
对,你没看错,通过可视化进行异常数据的检查
这是很重要的一步,在预处理的过程中我们并不能直观的发现异常数据,但是通过可视化,就一目了然了。
先看看一下数值型数据的描述性统计,其中数据值数据包括:房租价格、经纬度、房屋面积
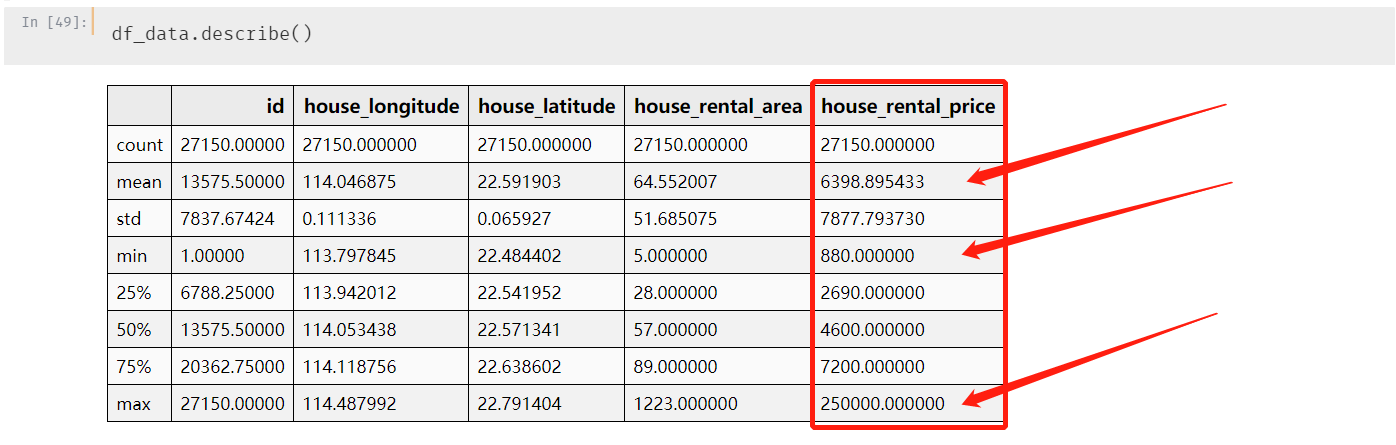
统计包括:均值,中位数,众数,方差,标准差,最大值,最小值等
其中房屋面积最大1223m?,最小5m?;
房租价格最大25w 元,最小880 元,平均值6398。
这个值,怎么说呢,要不就是小一见识短,要不就是数据还有异常值。
你怎么看?
首先先来看房租价格,为什么先看这个呢?先暂时保密,看看你能不能发现。
对合租和整租数据分开进行可视化,画出各自的箱型图
可视化的代码有点多,需要的同学直接拉文末获取源码
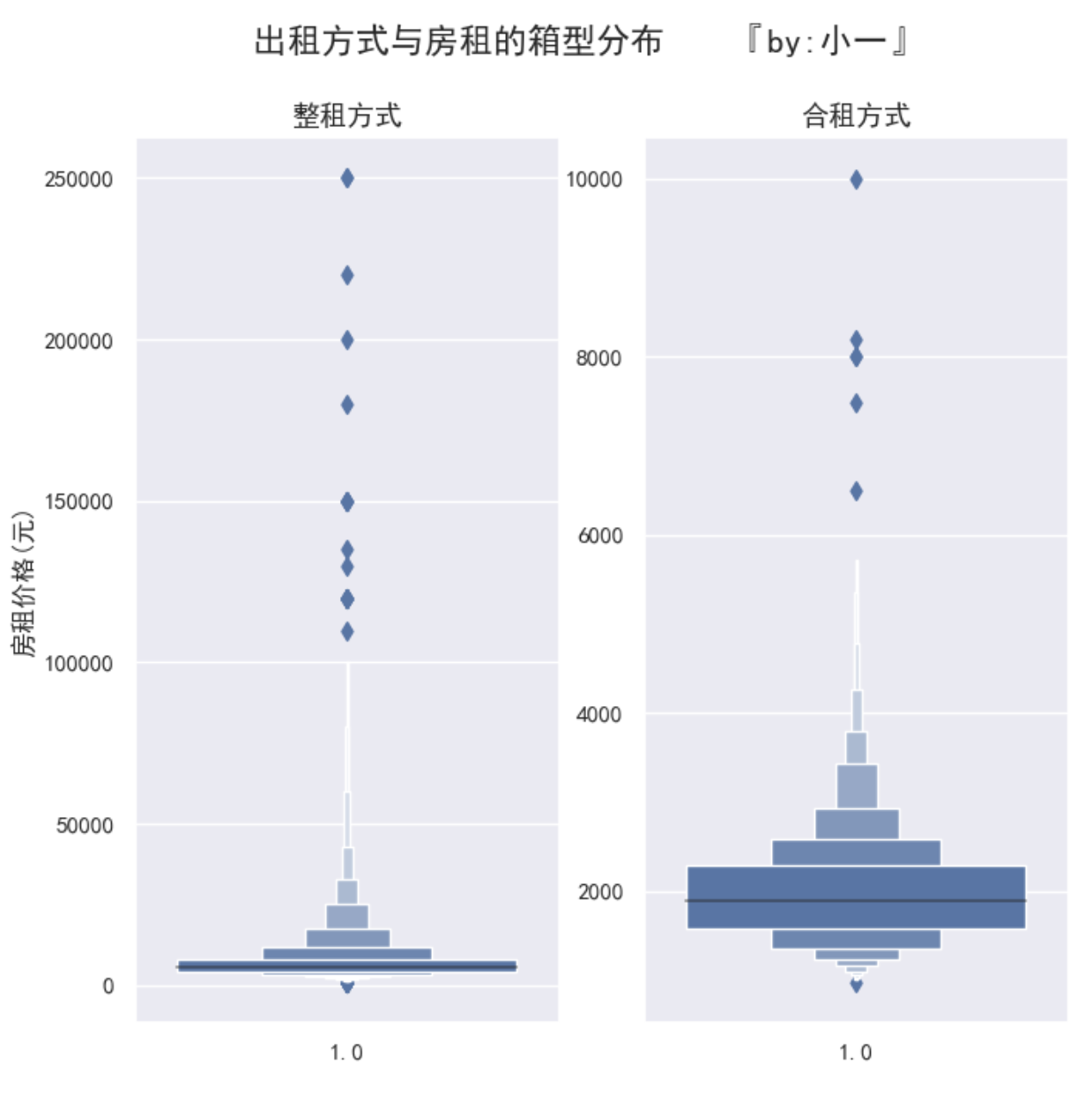
哦豁,是不是有一些值看着有点过分,比如像25w 的那个整租房,1w的那个合租房
到底是什么神仙房子,租不起的我只想去看看
于是就有了下面这些图:


第一张是25w/月的整租房,第二张是1w/月的合租(海景房),是你想要的房子吗?
不过,小一也不是光看豪宅了,还发现了这个图
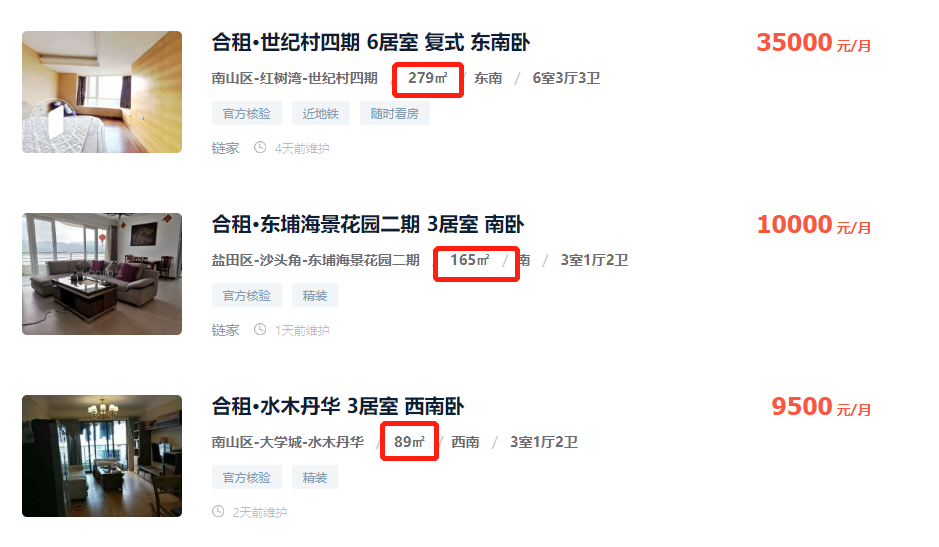
像这些,面积比较大的房屋,应该是整租的房屋,而并不是合租房。
所以,一个严重的问题出来了:
合租的房屋里面有整租的房屋,同理,整租的应该也有合租的。
这就是我们遇到的异常数据了,如果只是看分布很难直观看出来的。
异常数据找到了,怎么纠正呢?总不能直接删掉吧
肯定不能删,小一我手动查了大概几十上百个合租房(竟然没被官方限制),做了如下的探索:
- 首先,通过房屋面积去进行过滤,大于45㎡
- 其次,通过价钱进行过滤,大于4500元
- 接着,通过房屋户型进行过滤,非一居室的
整合起来就是:面积大于45㎡、房租超过4500元、户型是两室及以上,注意是合租房!合租房!合租房!基本都应该是整租房
同样的操作,小一我又查了几十上百个整租房(这次还没被封,哈哈,以后租房一定去你家)
大概确定了价钱低于3800、面积超过55㎡的非一室的整租房基本都是合租房
加上面积是因为一室两室这种标准太宽泛,而且没有定数,需要用面积再次限制
处理之后我们再来看一下箱型图
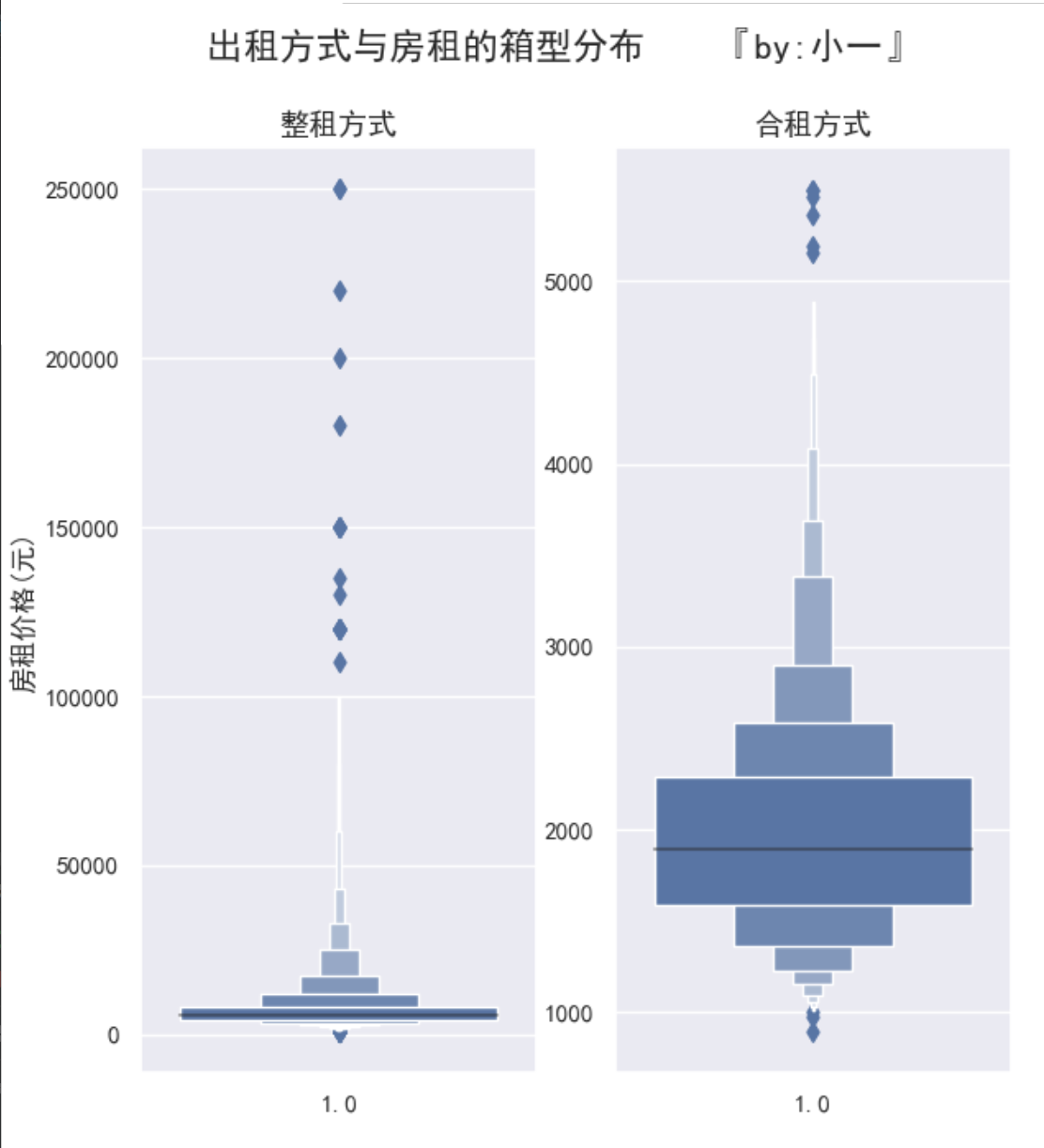
可以发现:
整租的价格是在3000-25000范围内,均价为5600,大于50000的房屋占比较少
合租的价格是在1000-3400范围内,均值为1900,大于3400的房屋占比较少
接下来,到了看图时间,多图预警
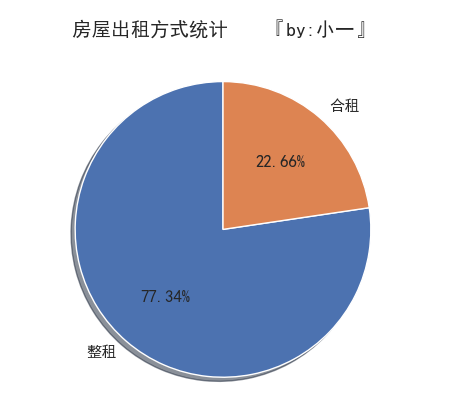
先来看出租方式的整体统计
似乎有点单调,那我们把其他的特征都拎出来看看
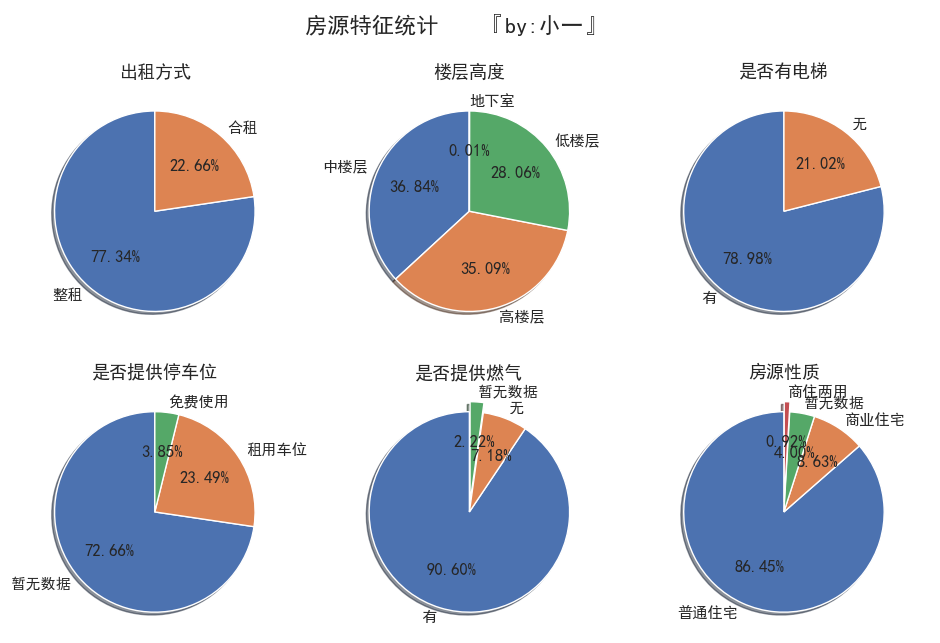
我们大概能从27150条记录中得出这些数据
- 深圳市的整租房源较多,占比77.34%远高于合租的22.66%
- 房源的楼层高度分布很均匀,竟然有0.01% 的地下室出租
- 有电梯的房源占比较多,为78.98%
- 有3.85%的房屋提供免费车位
- 提供燃气的房屋占比90.60%
- 普通住宅的占比86.45%
继续看图:
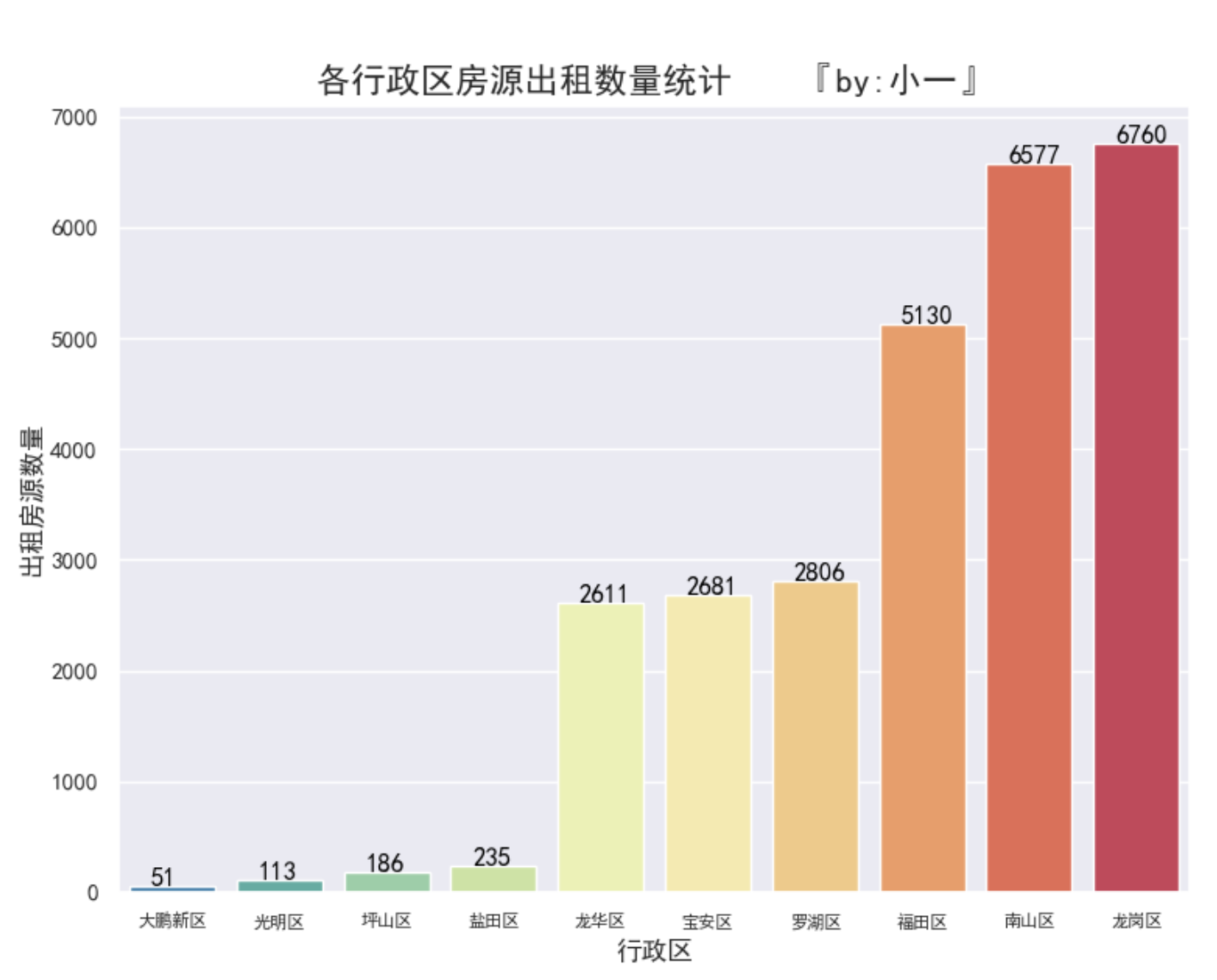
深圳市房屋出租数量前三的分别是龙岗区、南山区和福田区,分别占比24.90%、24.22%、18.90%,为房屋出租的主要区域
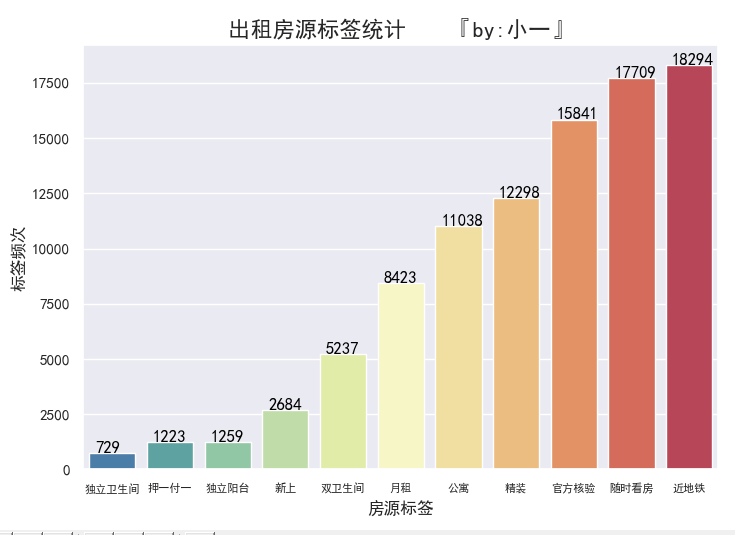
房屋标签数量前三的分别是近地铁、随时看房、官方核验
看来某家已经牢牢把握住租房用户的心思了,连标签都这么符合民意
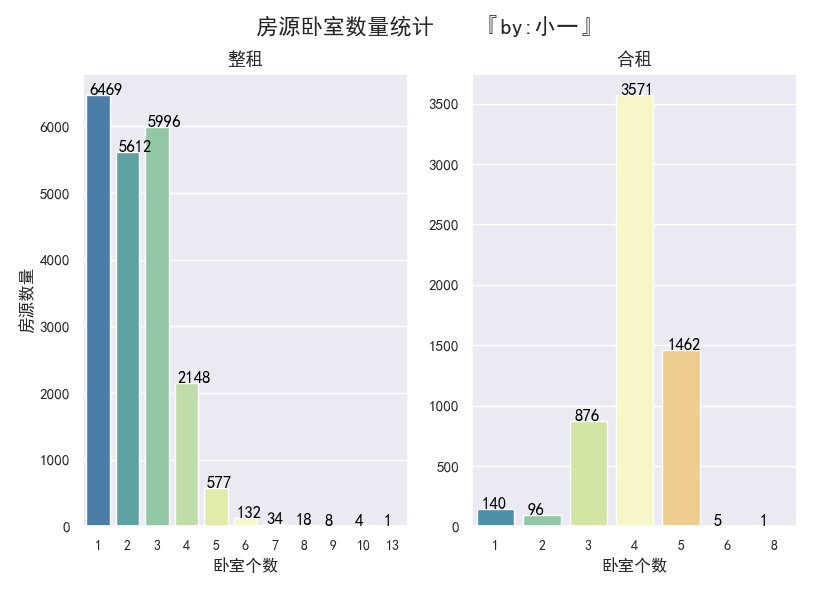
房屋卧室数量:整租类型的出租房卧室数量前三分别是1居室、3居室和2居室;
合租类型的前三分别是4居室、5居室和3居室。其中整租的一居室数量最多
咦,竟然有一个13个卧室的房屋,小一我又好奇了,走,一起去看看

搜了一下这个房子,看房屋介绍应该是公寓,平摊下来一个卧室也有二十多m?,ok,属于正常数据
看完房屋的基本信息,心里大概有了一个底,那接下来我们应该选择哪个行政区呢?
先来看个行政区整租的价格分布
选取价格小于15000/月的数据
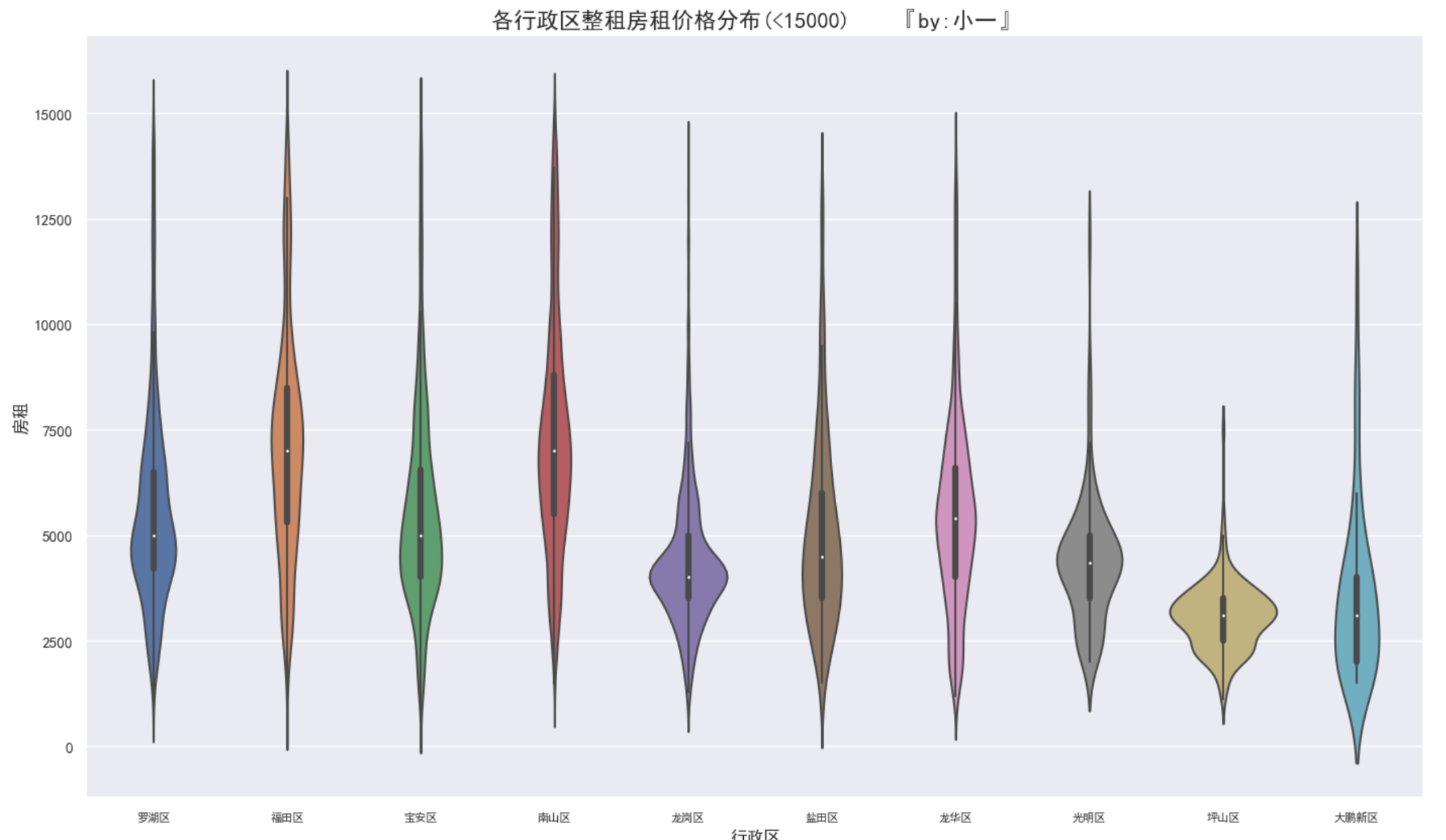
除了罗湖、福田和南山价格稍高些,其他几个区的价格分布都稍低
再来看看各行政区合租的情况
选取价格小于4000/月的数据
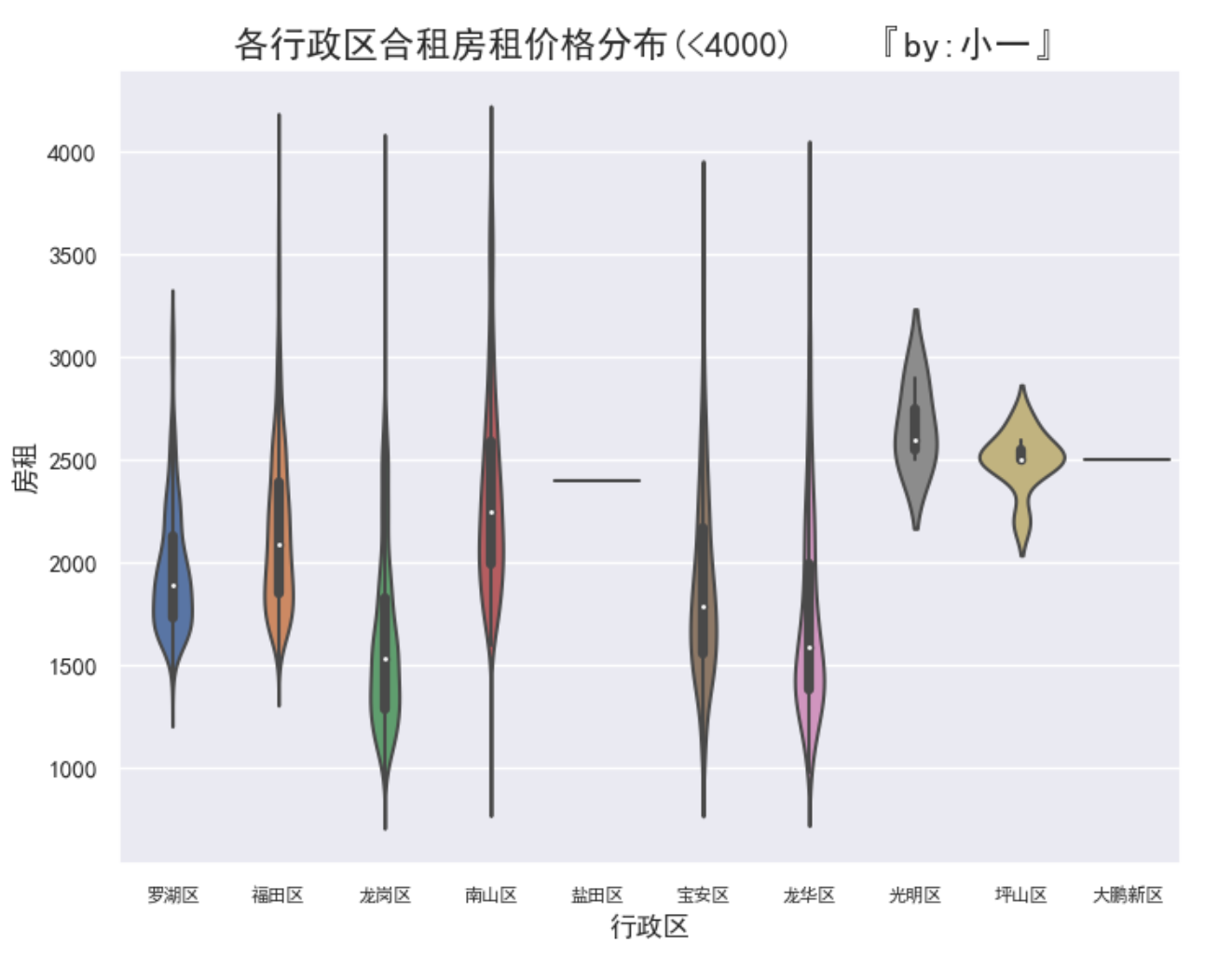
从整体来说福田、南山和罗湖的合租房租最低价在1500,而其他区域最低房价在1000附近,
另外,盐田区和坪山区数量太少,可以不用考虑
小总结:
从房价的分布来看,龙岗和龙华的房价较低,罗湖、福田和南山的房价较高
房源最多的三个区分别是龙岗、南山和福田。
可以初步确定:便宜的房源->龙岗区最佳、龙华次之;不在乎价格的话优选福田、南山
既然确定了区域,那我们针对这几个区域再进行分析
分析完了单一维度的特征,接下来需要进行特征组合分析。
举个例子:我们前面提出的假设--楼层、车位、燃气、电梯等会对房租有影响吗?在分析的时候它们只和房租有关,属于两个特征的相关分析
但是像区域分布、房屋面积、房租等是可以互相影响的,需要联立特征分析,比如福田区的房屋面积和房租的关系、福田区整租的房租分布等等这些
记住我们的最终目标:确定价值洼地
看一下龙岗区的房源分布情况
我们把整租的房价选取价格调低至小于12000/月的数据,合租房的房价调低至3800/月
以下区域同此标准
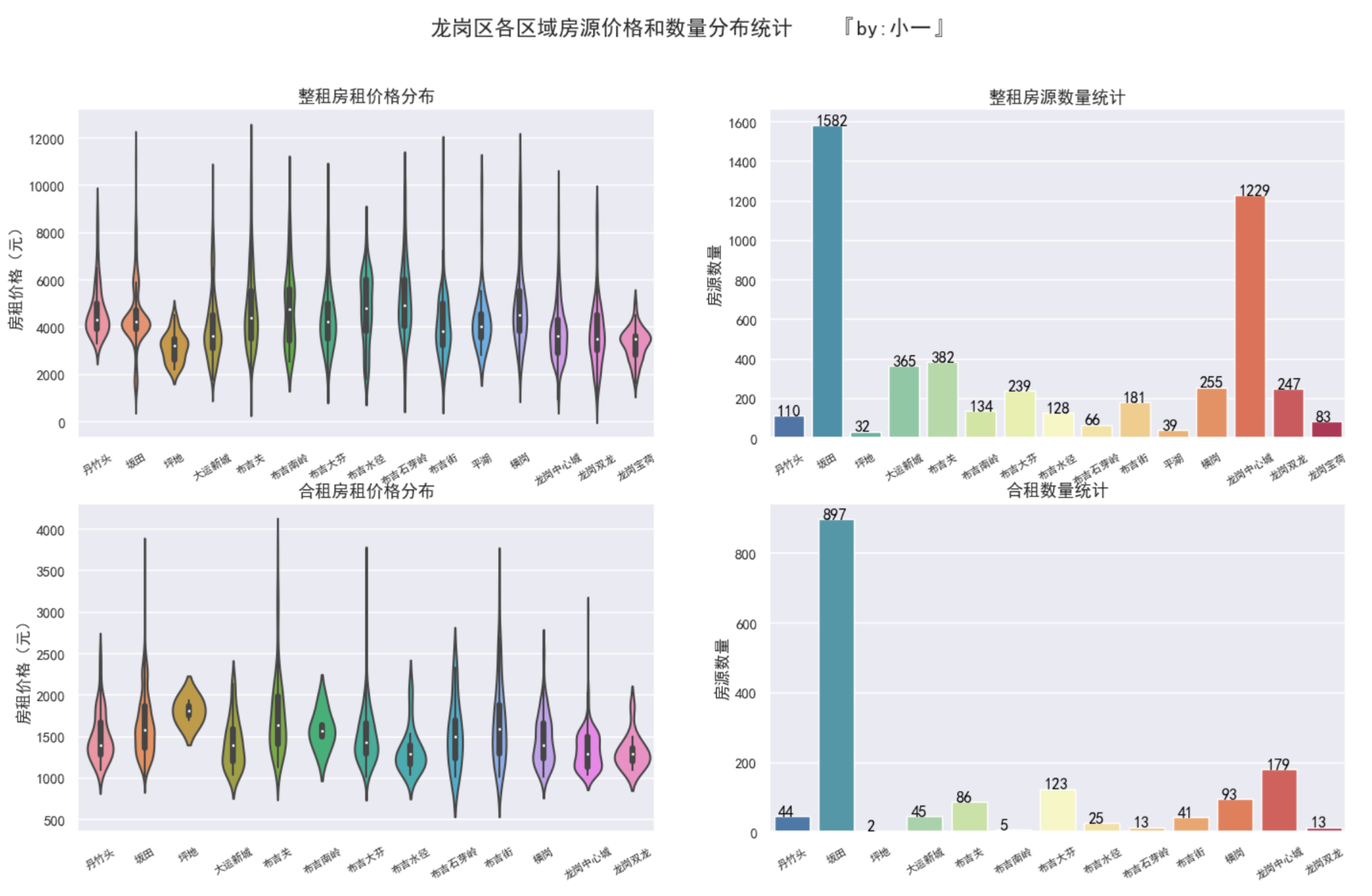
其中,坂田、龙岗中心城区域的房源最多,可以重点考虑。
整租房的价格在3000 ~ 5000元左右 ,合租房的价格在1200 ~ 1700元之间
龙华区的房源分布
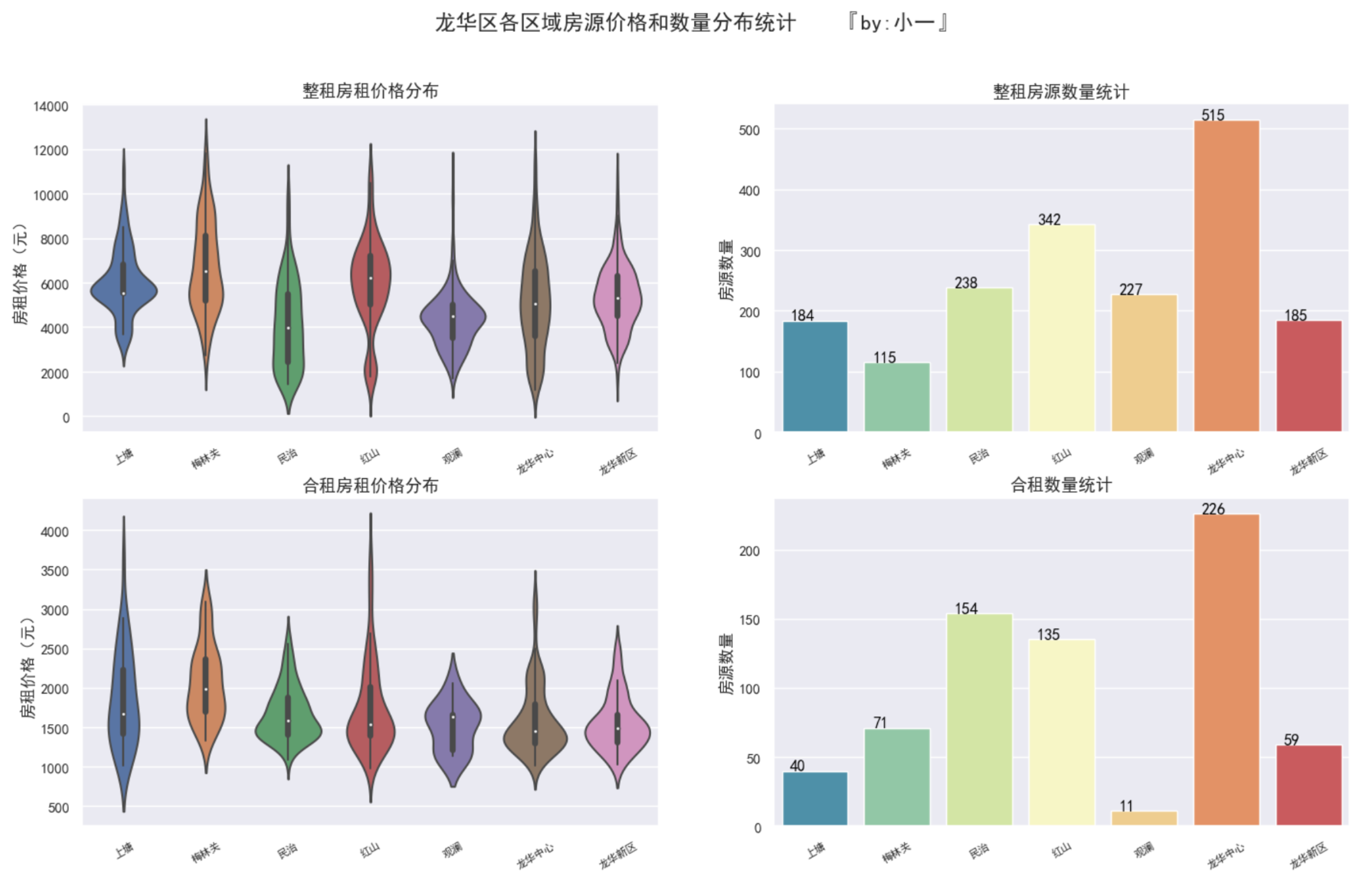
其中,龙华中心、民治、红山区域房源最多,可以重点考虑。
整租房的价格在3000 ~ 7000元之间, 合租房的价格在1000 ~ 2500元之间
再来看关内区域
深圳有一个关内关外的概念,关内指的是市中心的几个行政区。
福田区的房源分布
此图的小提琴图太过密集,容易引起不适感,换成了箱型图
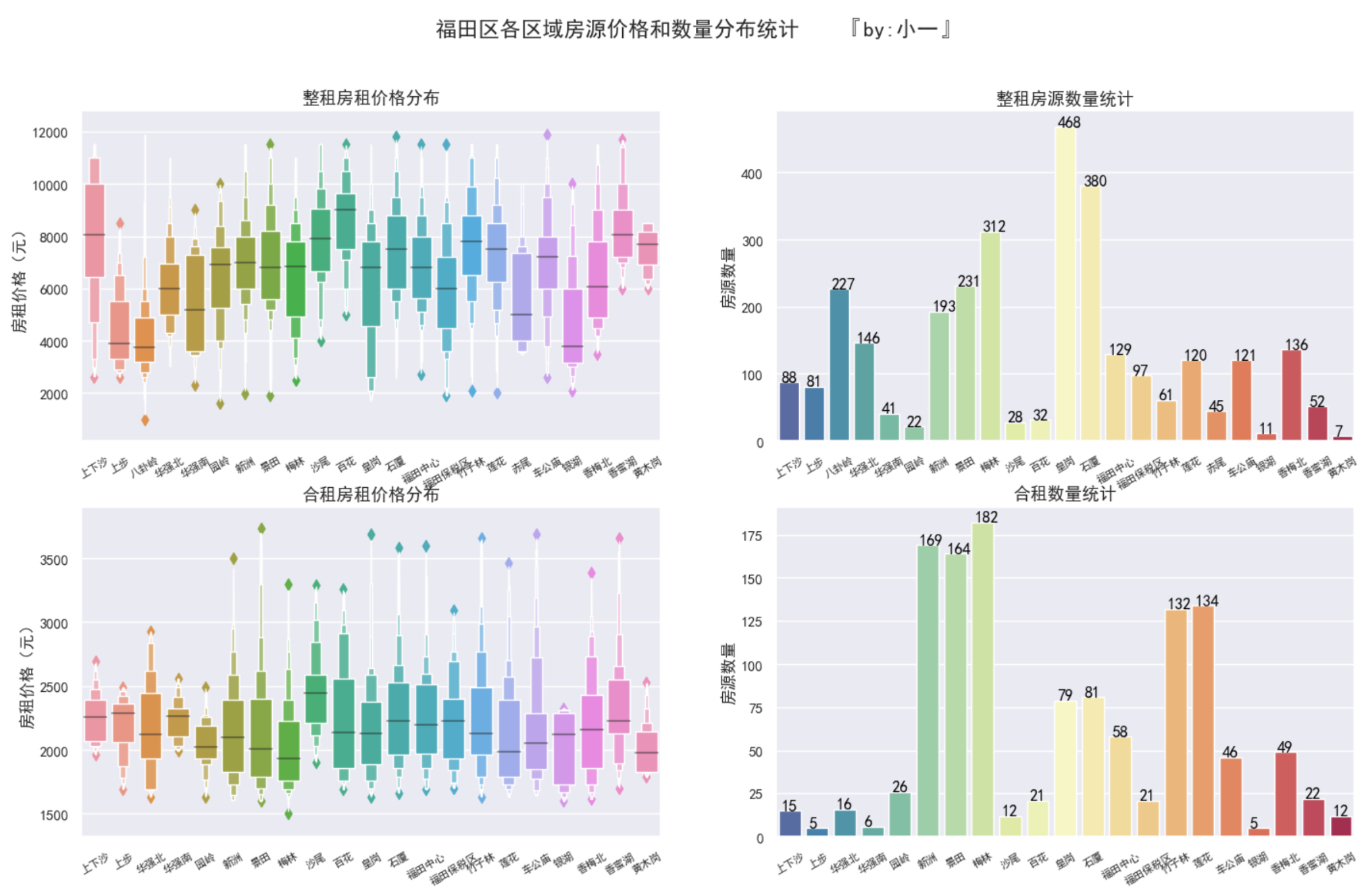
福田区整租房屋中,皇岗、石厦和梅林的房源最多,房租价格在4500~8500元之间
福田区合租房屋中,梅林、新洲和景田的房源最多,房租价格在1800~2400元之间
南山区的房源分布
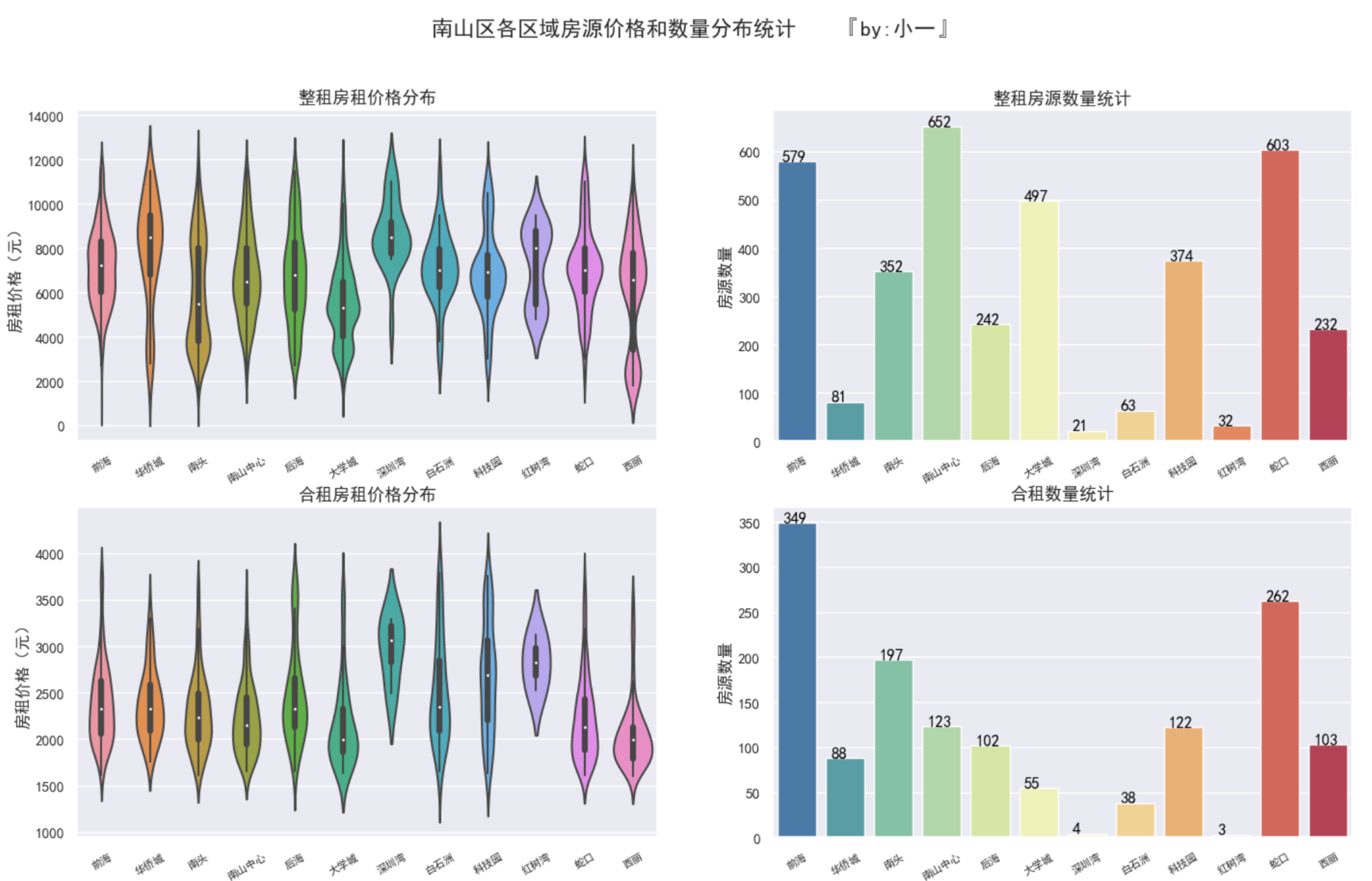
南山区整租房屋中,前海、蛇口和南山中心房源最多,房租价格在4000~10000元之间
南山区合租房屋中,前海、蛇口和南头房源最多,房租价格在1600~3000元之间
罗湖区的房源分布
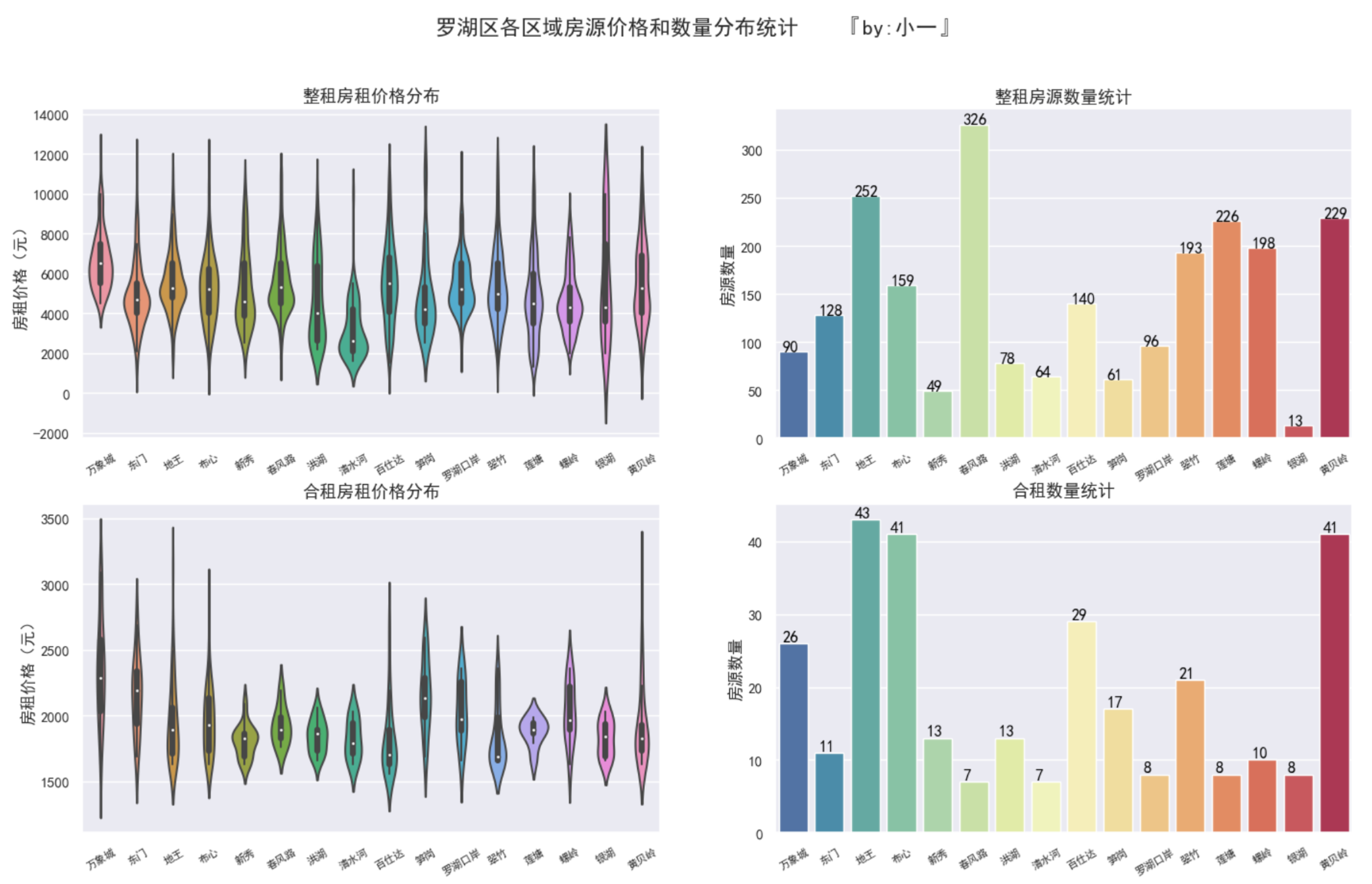
罗湖区整租房屋中,春风路、地王和黄贝岭房源最多,房租价格在3000~7000元之间,整体房源较少
罗湖区合租房源相对偏少,房租均价在1800~2200元之间
小总结:
小一直接做了个对比表格,一起看看吧
整租优先区域 |
整租分布均价 |
合租优先区域 |
合租分布均价 |
|
|---|---|---|---|---|
| 龙岗区 | 坂田、龙岗中心城 | 3000~5000元 | 坂田、龙岗中心城 | 1200~1700 |
| 龙华区 | 龙华中心、民治、红山 | 3000~7000元 | 龙华中心、民治、红山 | 1000~2500元 |
| 福田区 | 皇岗、石厦、梅林 | 4500~8500元 | 梅林、新洲、景田 | 1800~2400元 |
| 南山区 | 前海、蛇口、南山中心 | 4000~10000元 | 前海、蛇口、南头 | 1600~3000元 |
| 罗湖区 | 春风路、地王、黄贝岭 | 3000~7000元 | 无 | 1800~2200元 |
你以为这就完了?当然没有,上面一大堆推荐区域,到底选哪啊?
想到这的时候,小一的脑海突然冒出两个词:单价
对啊,买房有单价,租房也有啊,和买房一样,我们想要的价值洼地一定是单价低、地段好的区域
基于上面的思考,我们进行了进一步的探索
-
首先需要对数据进行处理,筛选出上面表中的区域
-
然后对每个区域计算房屋单价,取单价的倒数作为权重
-
最后根据百度热力图,进行可视化展示,确定价值洼地
筛选区域数据并计算权重
# 筛选数据
df_data_area = df_data.loc[(df_data.area.isin(area)) &
(df_data.house_rental_method == type) &
(df_data.house_rental_price < max_price),
['house_rental_price', 'house_rental_area', 'house_longitude', 'house_latitude']]
# 计算每平米的房屋价值当做权重
df_data_area['weight'] = 1.0/df_data_area['house_rental_price']/df_data_area['house_rental_area']保存上一步的数据,打开Echarts 官网选择热力图
在弹出的窗口上加载我们的数据
这一步需要将数据改成热力图需要的格式:经度+维度+权重
同样我们需要将合租和整租分开作图,先来看一下热力图长什么样
这一步需要注意,因为爬取到的房屋经纬度是基于百度坐标系,这样用百度地图作可视化底图是不需要进行经纬度转换的
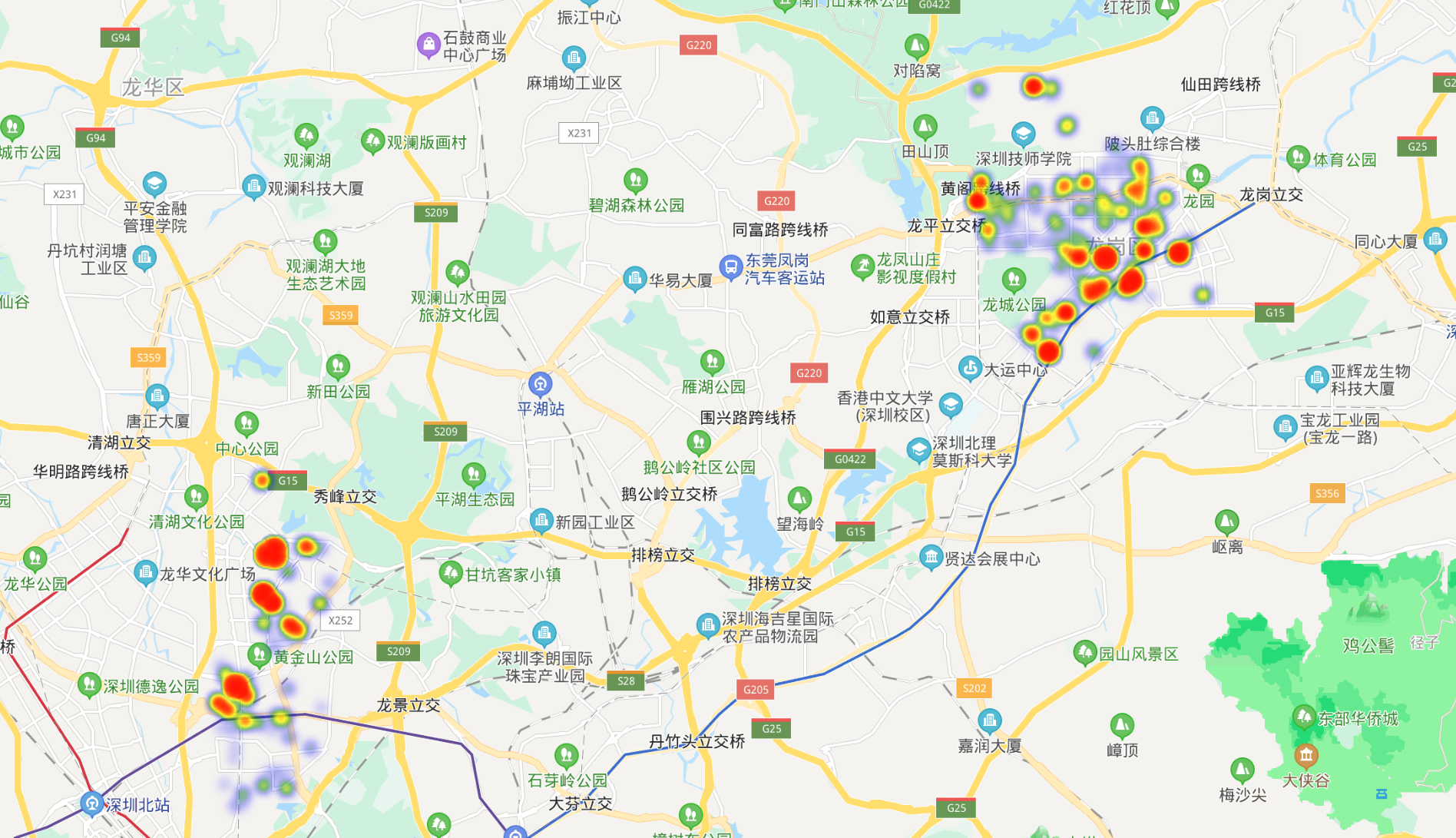
emmm,西红柿炒蛋的颜色,虽然这个颜色不止一次被我和同事们嘲笑,但是官方推荐的就是这个,而且似乎也没有比这个更好的配色了
上面这个图是龙岗区整租的推荐区域,放小一点会看的更清楚
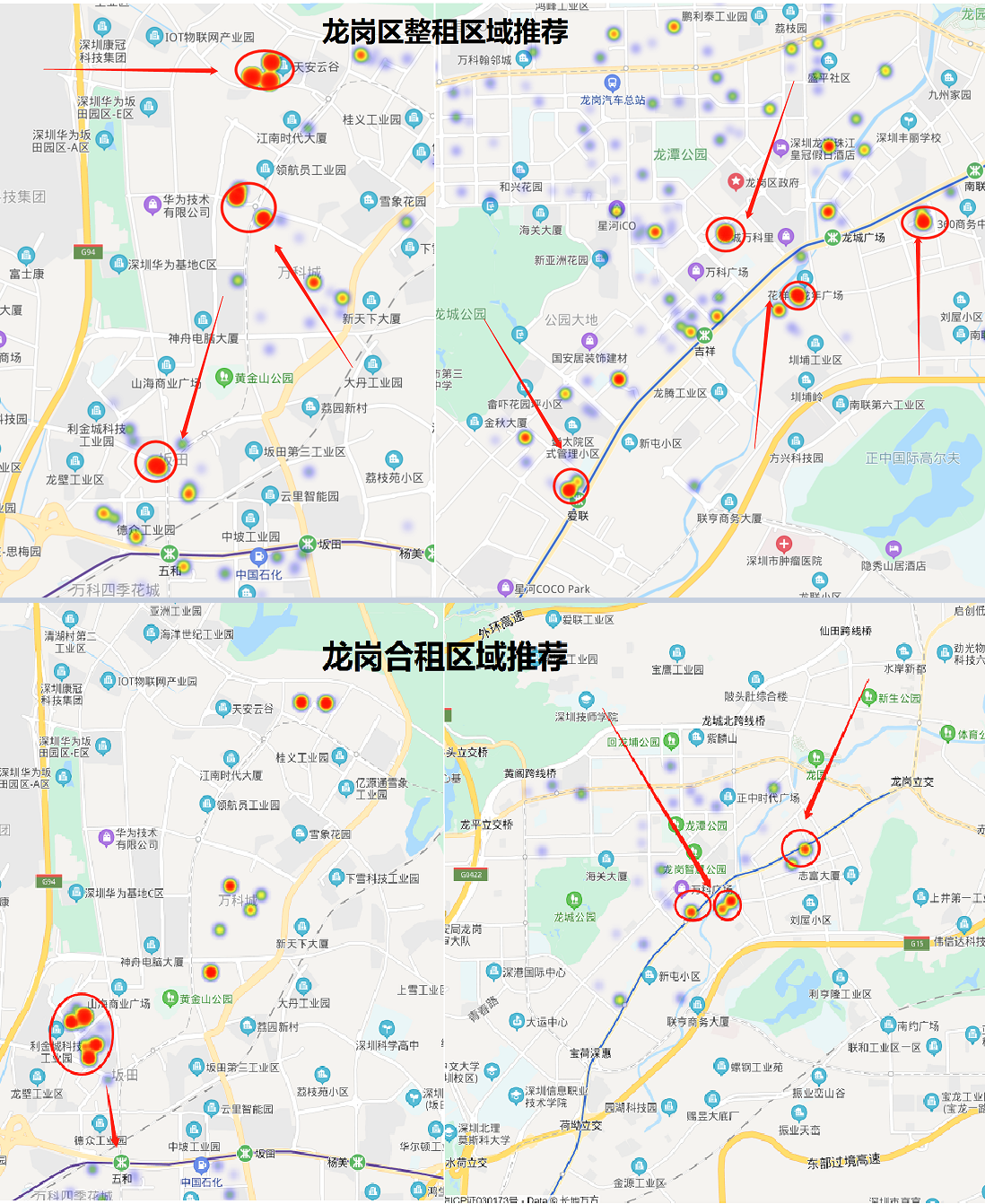
再来看龙华区的推荐
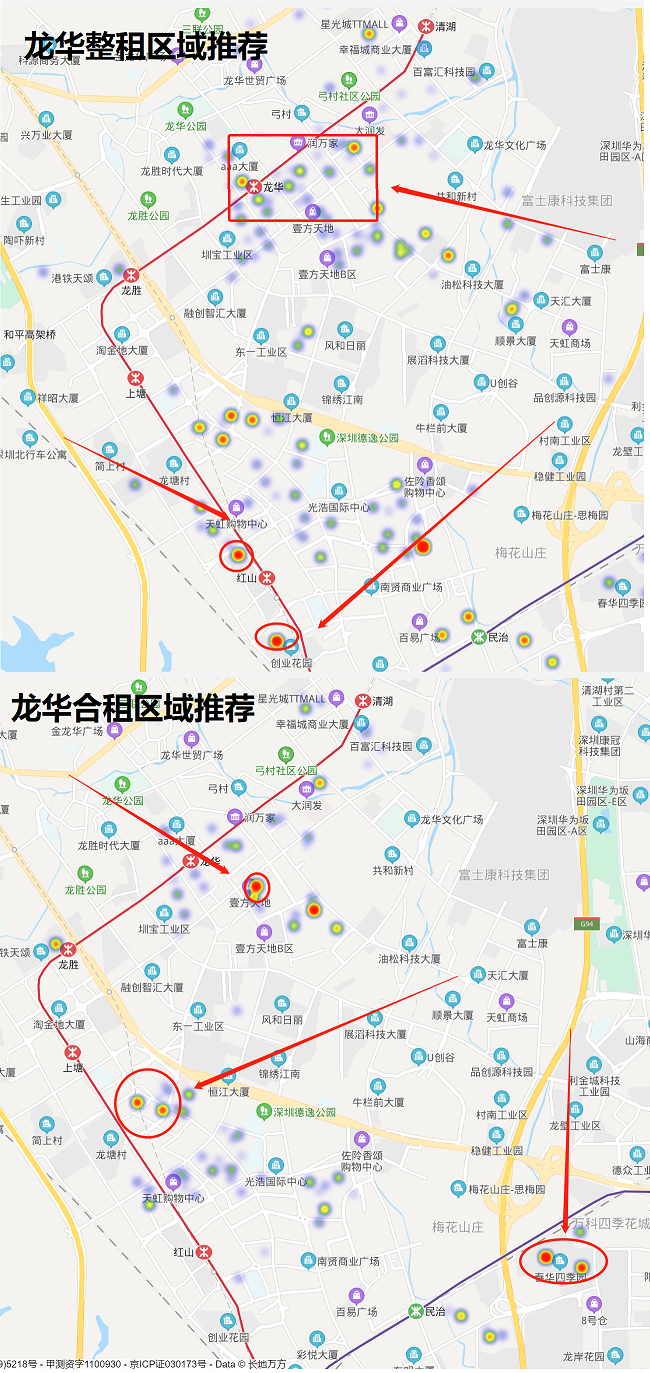
福田区的推荐
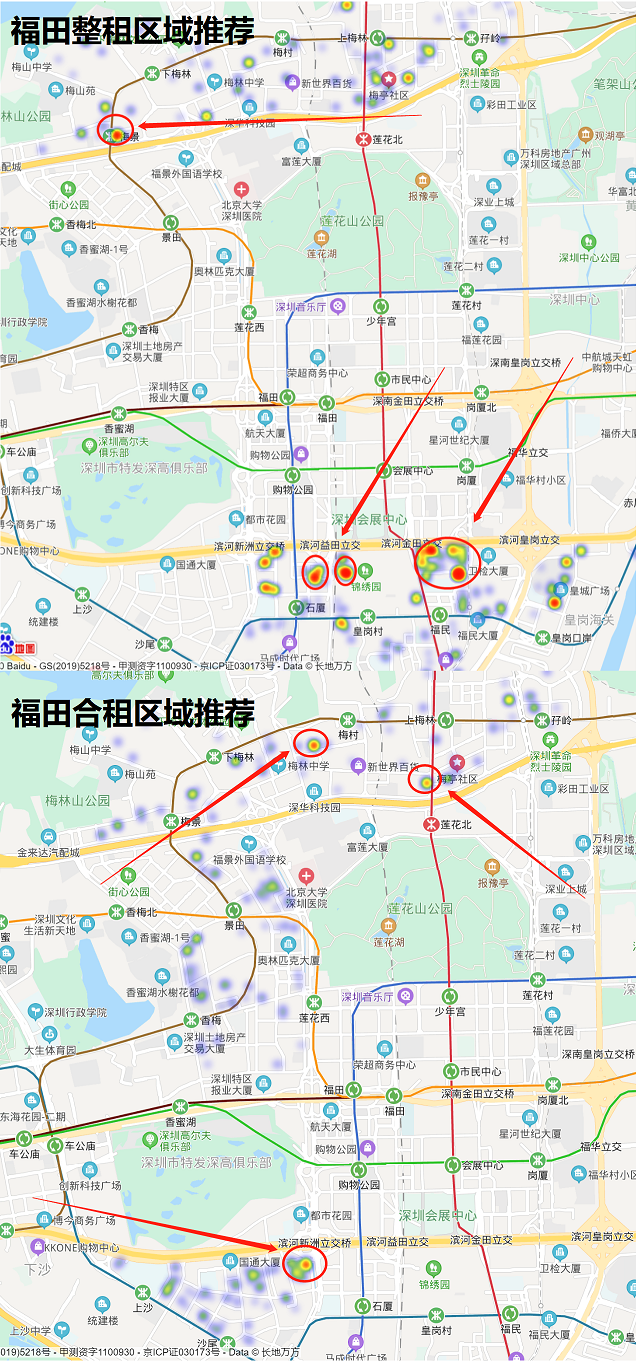
南山区的推荐
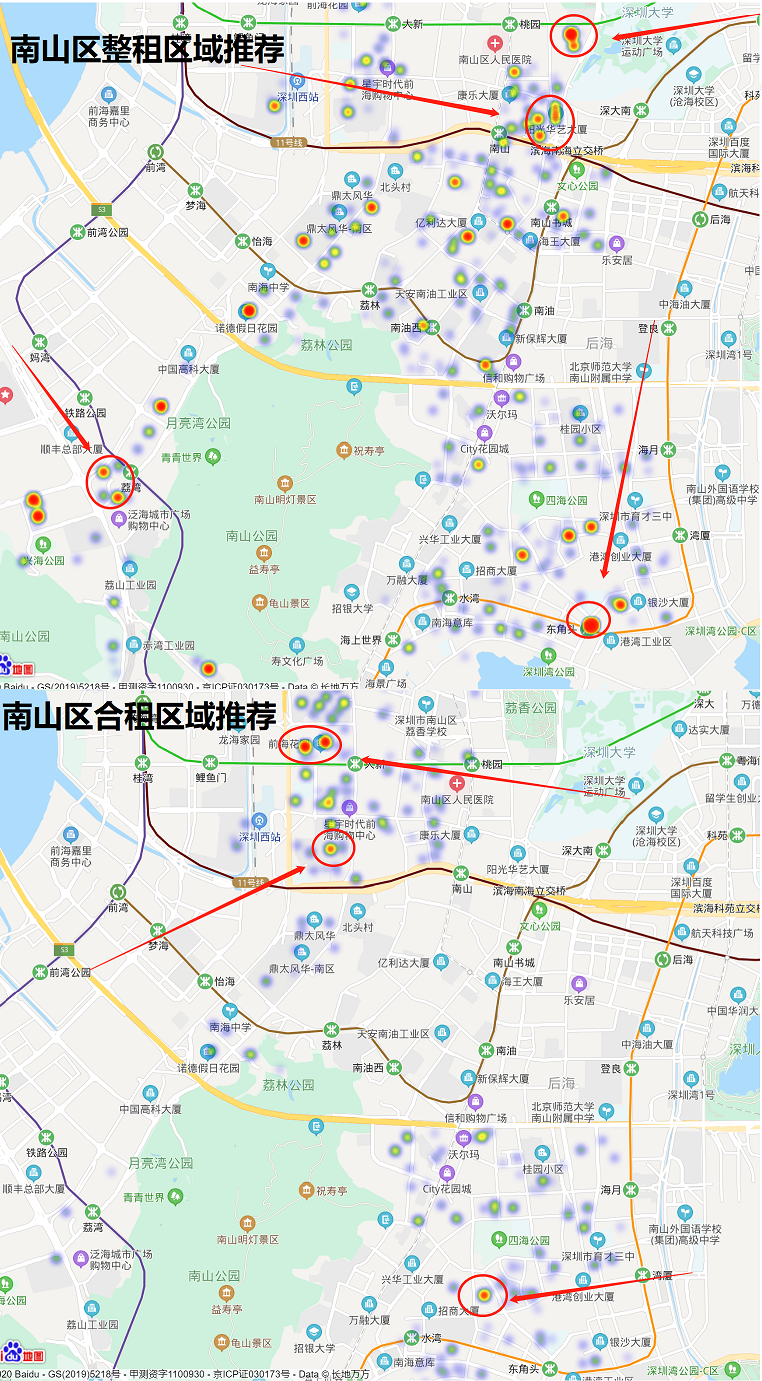
如果你也恰巧准备租房,希望上面的图会对你有用,不过这个数据是今年1月份的,需要注意噢。
借鉴于这个方法,小一将全市的单价数据做成了热力图,希望能够找到解决第二个设想的方法
因为Echarts的配色去显示全市的数据会让人更加不适(主要是饿),这里用Excel 的三维地图进行可视化
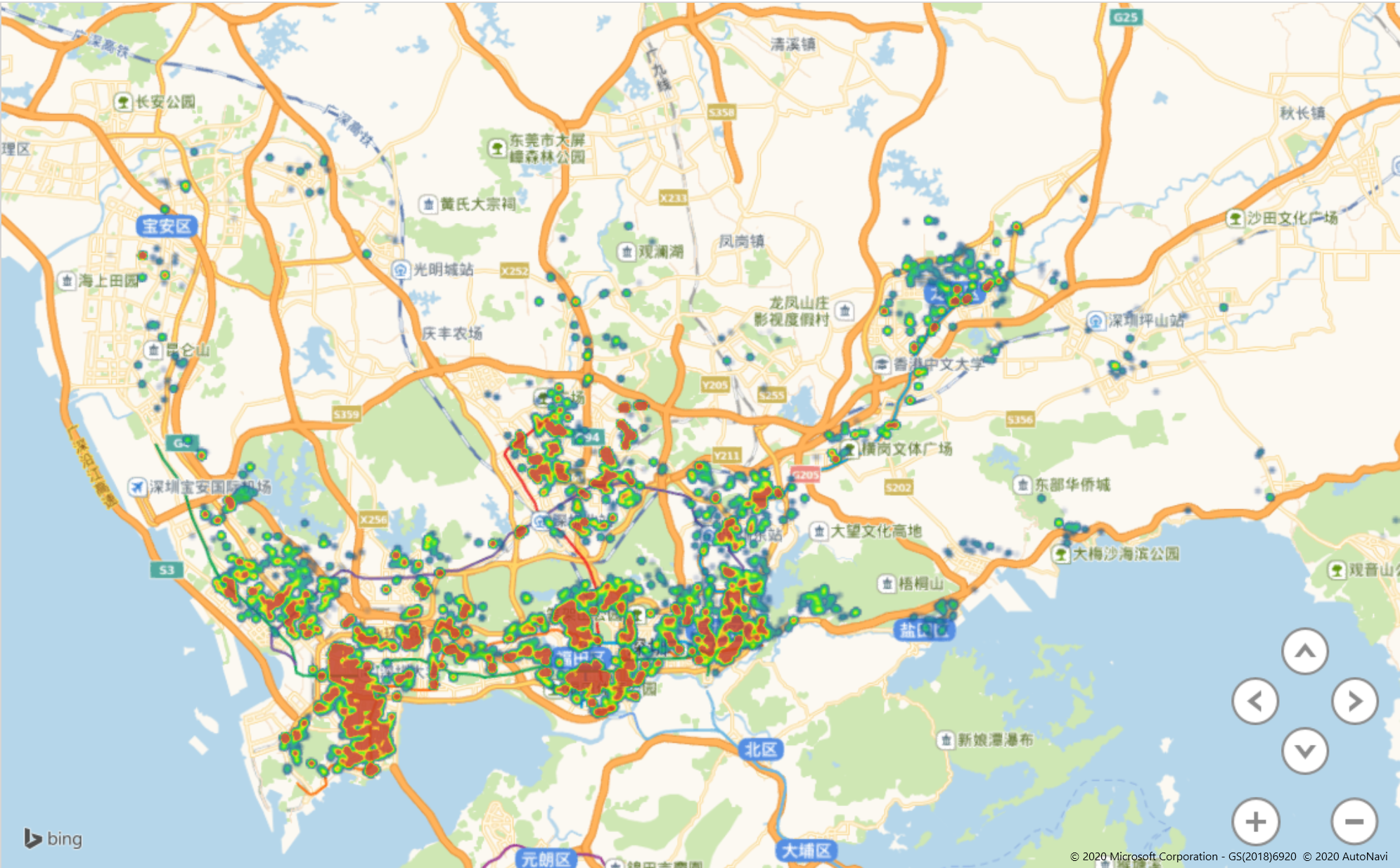
放大之后我们看一下具体某个区域的图
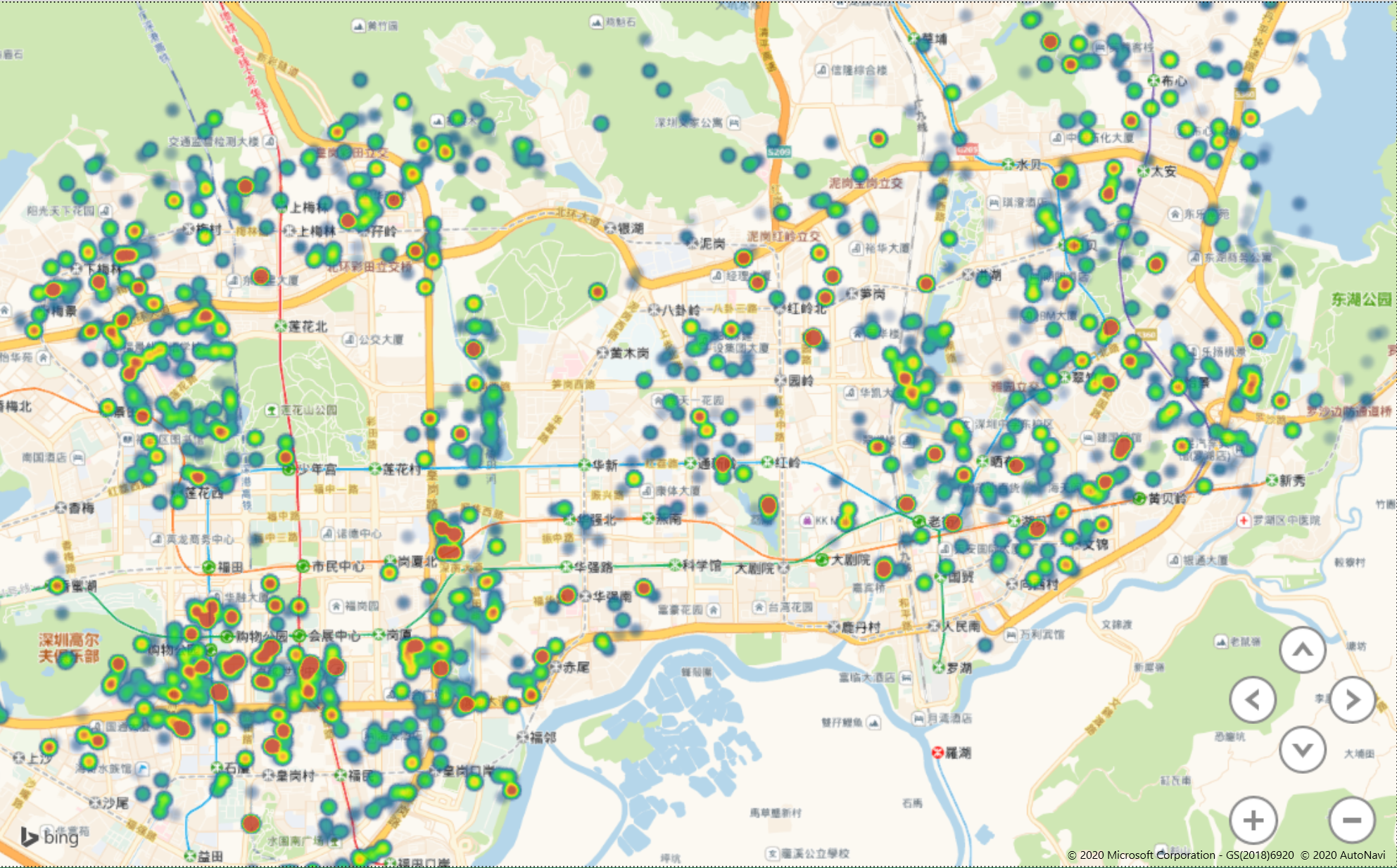
这是福田区和罗湖区的部分截图,图中红色的点表示单价较高的点
如果我们将红色的点进行连接,是不是就是我们想要的地铁图呢?
注意了,灵魂画家上线了
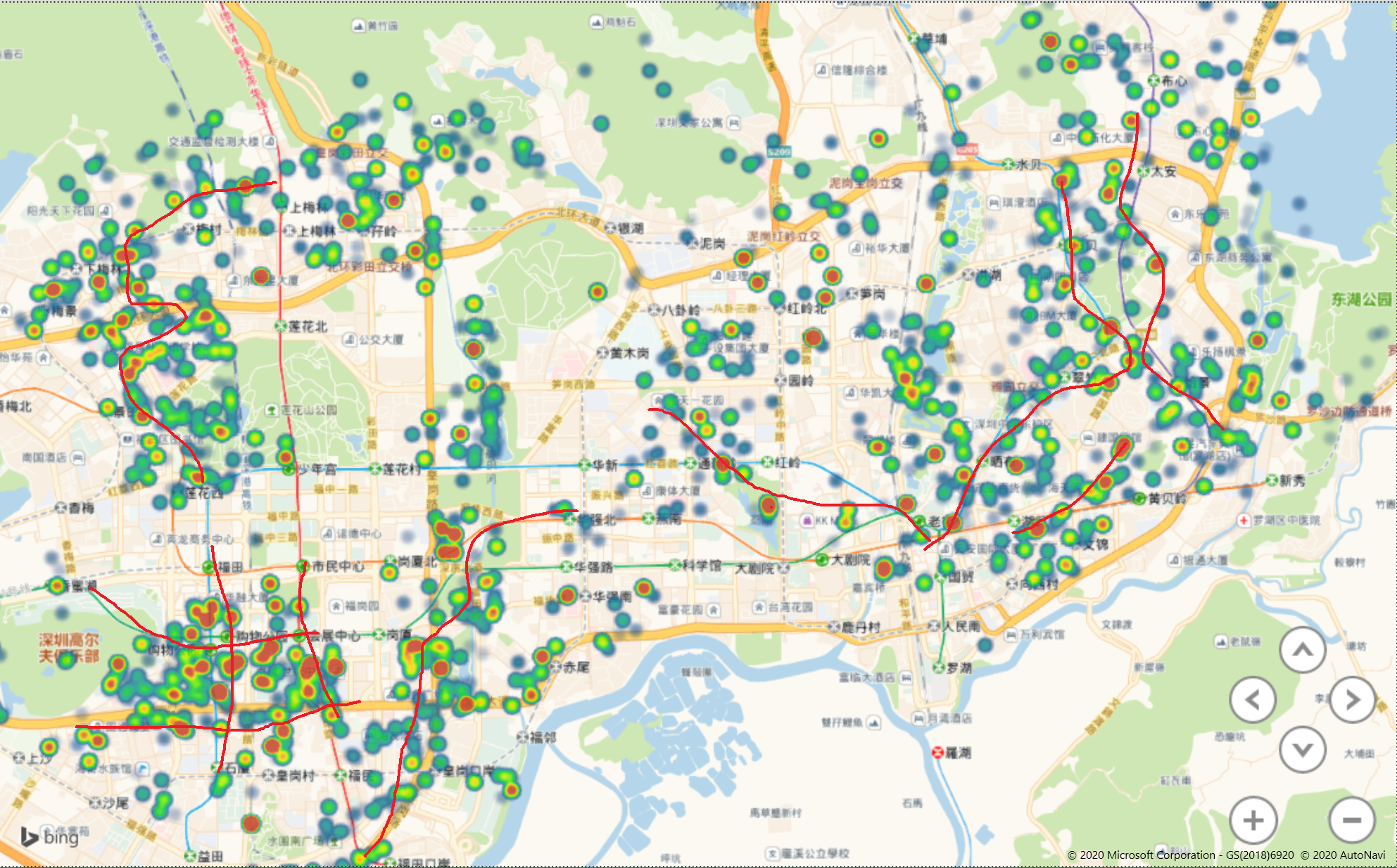
嗯,好像、似乎、可能、大概有点和地铁图对不上
很不情愿的承认这个想法失败了
那有没有改进方法呢?
小一想了几个思路,有兴趣的同学可以探索一下:
- 利用房屋标签中的近地铁字段
- 设置房租上限,降低较大值的影响
- 深圳的地铁太密集了,要不换个城市?(手动狗头)
来看一下这一部分的小总结:
- 通过区域的房源数量和价格分布确定了优选区域
- 通过探索确定了每个优选区域的价值洼地,并给出了地图展示
- 探索深圳的地铁路线图
本文详细描述了深圳市租房数据的分析过程,具体从问题思考、问题提出、数据预处理、可视化探索四个步骤进行展开。
在分析过程中,需要注意几个细节::
- 围绕问题有针对性、目的性的展开分析
- 数据清洗过程中,对于主要字段用正确的方式区填充,而不是删除
- 数据可视化可以再次验证数据的异常值
本次项目中,还存在以下问题待改进:
- 对于整租、合租的异常数据处理需要更详细的方法
- 数据量较少,需要定期爬取数据进行更新
- 针对区域进行聚类,比如住宅区、商业区,进行网络针对性优化(开头提出的第三个问题)
同样的,针对本次项目,我们还可以在后期探索以下问题:
- 对比一线城市深圳,猜想二线城市的数据分布应该是什么样的?
- 如果对房租进行预测,如何选择特征,怎么去建模?