Experiments (Masha)
All the source and target domain data were used for training. In the pictures below there are training curves of DANN with different hyperparameters averaged over 3 launches of training (half of the target domain data is used for validation).
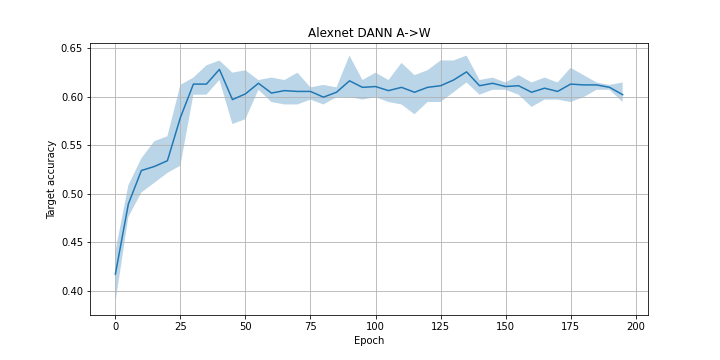
The maximal score achieved with the described architecture on the task A->W:
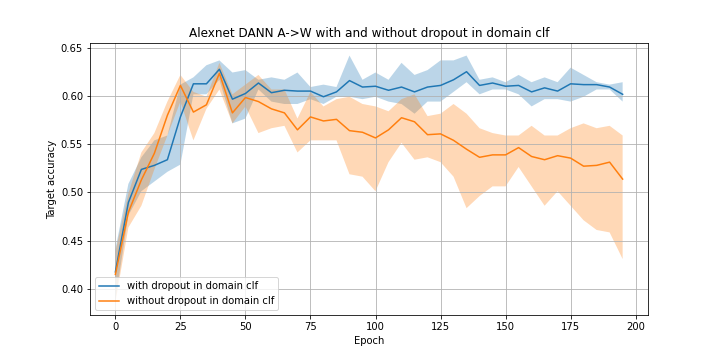
Comparison of the architectures with and without dropout in the domain classifier:
Comparison of the architectures with bottleneck size 256 (from the paper) and bottleneck size 2048:

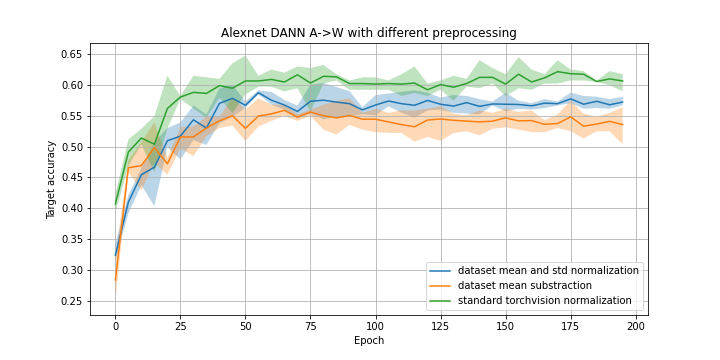
Comparison of the different input normalizations:
Summary (final accuracy score averaged by 3 launches):
| Results | DANN | Source-Only | Target-Only |
|---|---|---|---|
| Ours | 0.605 | 0.4748 | 0.9875 |
| Paper | 0.73 | 0.642 | - |
| Results | DANN | Source-Only | Target-Only |
|---|---|---|---|
| Ours | 0.9231 | 0.9214 | 0.9875 |
| Paper | 0.964 | 0.961 | - |
| Results | DANN | Source-Only | Target-Only |
|---|---|---|---|
| Ours | 0.9625 | 0.9652 | 0.9934 |
| Paper | 0.992 | 0.978 | - |
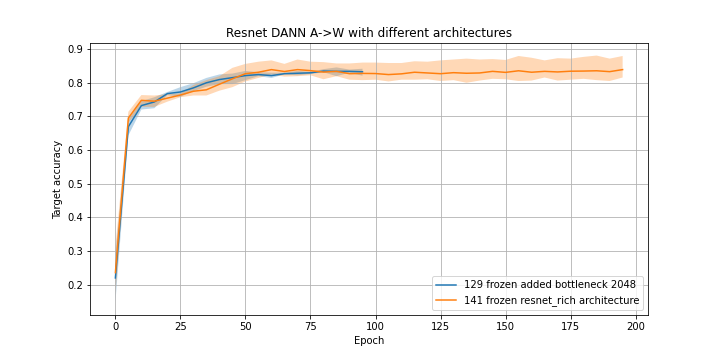
The result achieved by Resnet-50 with FREEZE_LEVEL=129, BOTTLENECK_SIZE=2048 and DOMAIN_HEAD = "dropout_dann" in dann_config.py on the task A->W:
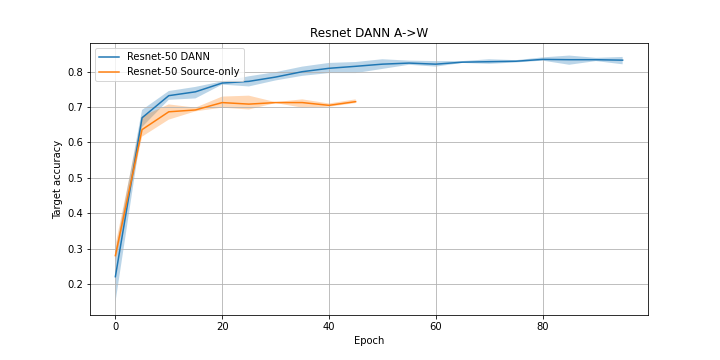
Final accuracy score averaged by 3 launches:
| DANN | Source-Only | Target-Only |
|---|---|---|
| 0.8307 | 0.712 | 0.987 |
Comparison of the architecture described above with the final Resnet-50 architecture (resnet_rich):