Node+React小爬虫:从开发到部署 #6
Description
我一般都喜欢去一些技术类博客社区或者 UGC 社区浏览文章,相信与我同类的你应该也有这爱好。为了方便自己的阅读,而不用一个一个打开目标网站的地址,就基于 Node+React 写了一个小爬虫: Tech-Read,用于抓取常去的 UGC 社区的文章摘要。目前的版本大概样子如下:
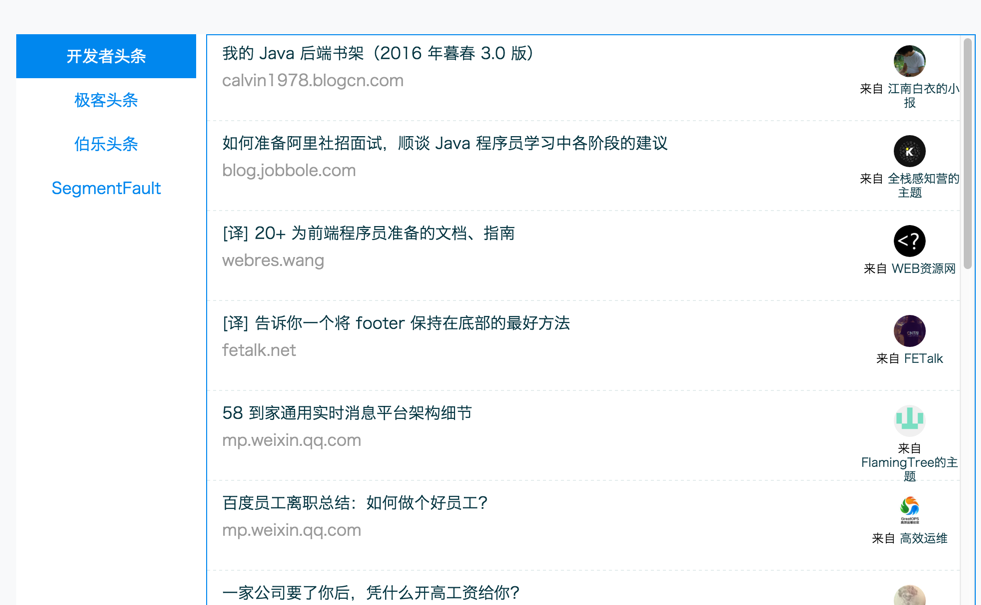
在线地址:Tech-Read
github 地址:tech-read
开发
Tech-Read 是个人的一个业余项目,初衷是方便自己阅读,实在是懒于去社区网站阅读,其次用于练手喽,毕竟最近在学点新东西。
在工作上,接触的技术栈是 Node + React,所以 TR 也采用了 Node + React 的技术栈。React 用于前端界面渲染,Node 用于抓取网页,并将解析后的 DOM 数据返回给前端调用。
前端的请求是用 fetch 发起的,由于部分社区做了跨域设置,So 用 Node 能帮我解决一些跨域的问题:

以及在 fetch 中解析 DOM 时碰到的诸如 Uncaught (in promise) TypeError: unexpected token <... 等杂七杂八的错误。
并且 Node 端提供了直接操作 DOM 节点的 cheerio,它是 jQuery 的一个子集实现,能非常方便的操作 DOM 元素。所以,目前我把 DOM 解析放在了 Node 端,前端只负责渲染。
所以,现在的处理流程如下:
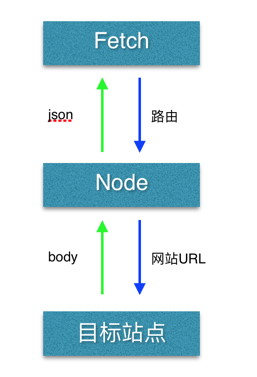
由于目前业务比较简单,前端的状态管理就用 Flux。Node 使用 Koa,匹配到 fetch 发起的路由后,通过 request 向目标网站发起请求,然后通过 cheerio 解析 body,获取 DOM 元素数据,以 json 形式返回给前端进行展示。
request 发起的异步请求的返回对象不带 Promise/Generator 等特性,所以不能同步写,但利用 Promise 简单封装下:
exports.parseBody = function (url) {
return new Promise(function (resolve, reject) {
request(url, (error, res, body) => {
if(!error && res.statusCode === 200) {
resolve(body);
} else {
reject(error);
}
});
});
};
就能同步的来写异步请求了:
let resBody = yield lib.parseBody('http://toutiao.io/').then((body) => {
return body;
});
另外一个选择是,利用 co-request,基于 generator 的一个网络请求库。
我个人很喜欢开发者头条,所以第一个抓取的也是开发者头条。由于我想在 TR 上直接看原文,就像这样子:
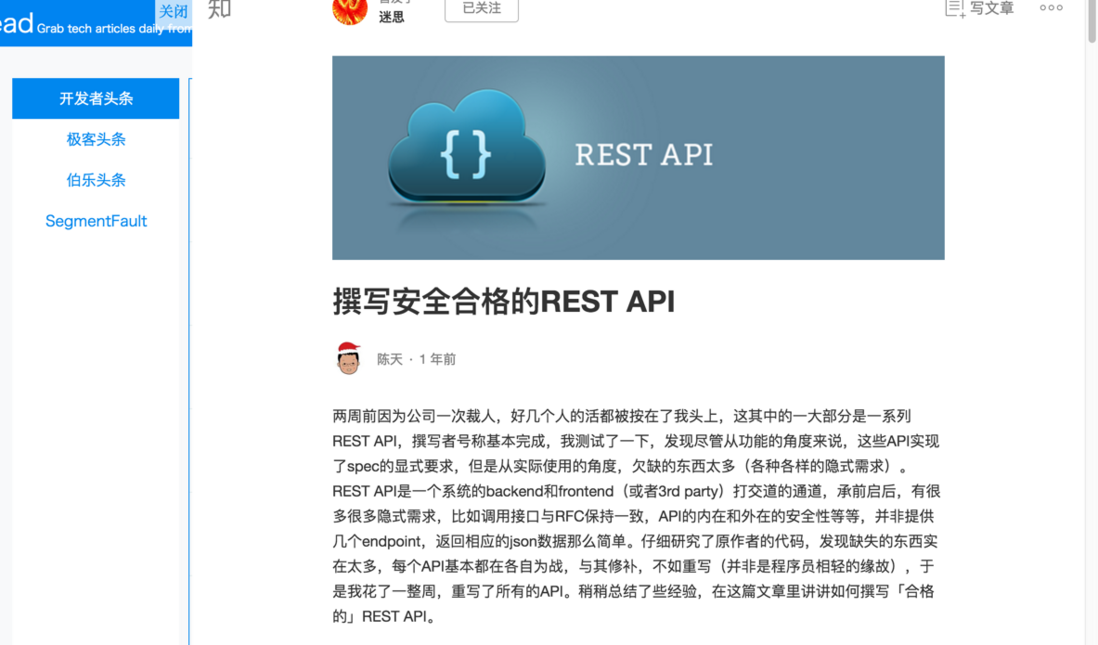
所以我需要拿到原文链接,插入到 Iframe 里面去。抓取其它社区时,能在抓取首页时顺便拿到原文链接,但是抓取开发者头条的时候,并不能,因为它的 DOM 结构是这样的:

这个 a 的 href 属性并不是原文的链接,要想拿到原文链接,还需要再向 http://toutiao.io/r/b04ku7/r/b04ku7 发起一次 get 请求:
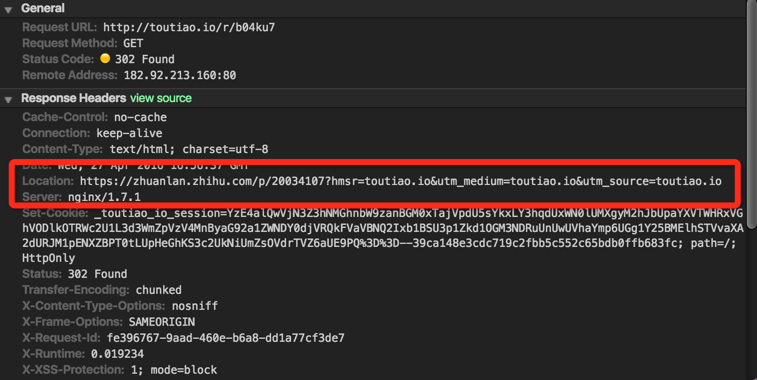
但这个 Location 是不能直接拿到的,因为返回的状态码是 302,页面会被直接跳转到了 Location 指向的页面。但是,request 发起请求后的 response 中则包含了 host 和 path 信息:
req.on('response', (res) => {
if(res.statusCode === 200) {
urlPath = res.client._httpMessage._headers.host + res.client._httpMessage.path;
resolve(urlPath);
}
});
将二者拼接,就能得到原文的 URL 了。
开发者头条部分实现了无限加载:
let contents = document.getElementsByClassName('toutiao-contents')[0];
let contentsHeight = contents.getBoundingClientRect().height;
contents.addEventListener('scroll', (e) => {
let triggerNextMinHeight = e.target.scrollHeight - e.target.scrollTop - contentsHeight;
if(triggerNextMinHeight < 22) {
//fetch data & update component state
}
},false);
无限加载调用的接口是:
http://toutiao.io/prev/date //date 形如 2016-04-26
部署
前文以抓取开发者头条为例,简单讲述了爬虫的实现思路,接下来就简单说说怎么部署 Node 服务。
由于服务器上已经跑了自己的博客,端口 80 已经被Apache 监听了,所以,你看到的 TR 的线上端口就是奇怪的 8080 了,这是 Nginx 监听的,然后被代理到本地的 9000 端口,这也是开发用的端口。
部署之前,先安装下 Node(系统是 CentOS 6.5 64bit)。
1、安装nvm
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash
或者:
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bash
建议使用 nvm 安装 Node,因为 nvm 会安装到用户的目录,而 n 会安装到全局的 /usr/ 目录下去。
2、安装 Node
nvm install 4.4.2
如果安装了多版本,则可以将默认的 Node 版本设置成 4.4.2:
nvm alias default 4.4.2
3、安装Nginx
切换到 /etc/yum.repos.d/ 创建文件 nginx.repo ,将下面的粘贴到文件中:
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
然后安装 Nginx:
yum install nginx
另一种安装方式是开启 epel-source( epel.repo 中需要有这个配置项)。
首先切换到 /etc/yum.repos.d,运行 cat epel.repo:
// ...
[epel]
// ...
enabled=1
// ...
[epel-source]
// ...
enabled=0
// ...
// ...[epel] 里面的 enabled 是 1(如果是0要改为1), [epel-source] 里面的 enabled 是 0,将其改为1,退出保存。
运行 yum repolist 查看是否添加了 epel-source:
// ...
epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 12299
epel-source Extra Packages for Enterprise Linux 7 - x86_64 - Source 0然后运行 yum install -y nginx 安装 nginx,安装完成之后可运行 nginx -v 查看 nginx 的版本。
EPEL的全称叫 Extra Packages for Enterprise Linux 。EPEL是由 Fedora 社区打造,为 RHEL 及衍生发行版如 CentOS、Scientific Linux 等提供高质量软件包的项目
Nginx 的相关配置:
/etc/init.d/nginx start/restart # 启动/重启Nginx服务
/etc/init.d/nginx stop # 停止Nginx服务
/etc/nginx/nginx.conf # Nginx配置文件位置
4、配置 Nginx
切换到 /etc/nginx/conf.d ,复制 default.conf 文件,按照需要配置新的 conf 文件:
techread.conf 配置文件如下:
listen: 监听的线上端口
server_name: 访问的域名
root: 根目录
index: 默认访问的文件
nginx 可以有多个虚拟主机,每个虚拟主机一个对应的server配置项。
红框部分是 Nginx 的反向代理配置,常见的配置项如下:
location / {
# 被代理的服务器IP
proxy_pass http://10.0.0.137; # 必需 也可以是本机上的一个 node 服务地址,如127.0.0.1
# 以下是一些反向代理的配置(非必需)
proxy_redirect off;
# 后端的Web服务器可以通过 X-Forwarded-For 获取用户真实IP
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 允许客户端请求的最大单文件字节数
client_max_body_size 10m;
# 缓冲区代理缓冲用户端请求的最大字节数
client_body_buffer_size 128k;
# nginx跟后端服务器连接超时时间(代理连接超时)
proxy_connect_timeout 300;
# 后端服务器数据回传时间(代理发送超时)
proxy_send_timeout 300;
# 连接成功后,后端服务器响应时间(代理接收超时)
proxy_read_timeout 300;
# 设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffer_size 4k;
#proxy_buffers缓冲区,网页平均在32k以下的话,这样设置
proxy_buffers 4 32k;
#高负荷下缓冲大小(proxy_buffers*2)
proxy_busy_buffers_size 64k;
#设定缓存文件夹大小,大于这个值,将从upstream服务器传
proxy_temp_file_write_size 64k;
}
proxy_pass 是必备项,表示要被代理的服务地址,其它可有可无。
安利一份关于解读 Nginx 源码的资源:Nginx 福利
启动 Nginx 时,默认是读取 default.conf,现在需要将其更改为读取 techread.conf。 回到 /etc/nginx 下,修改 nginx.conf 文件, 将 include 的引用改为新建的文件:techread.conf:
重启 nginx,线上部署就 OK 了。