This repository is for an analysis of the effect of ET on agriculture as witnessed by differences in ECOSTRESS ET estimates over land cover and crop types. See report from JPL 2021 internship: https://docs.google.com/document/d/1xOjTGxKnkD_1tZrXiKZeYXzrA0Pmw3cboQdNA6kfm3U/edit?usp=sharing
This repository is organized into two folders. The data folder contains raw and intermediate datasets, as well as final datasets used in the analysis. The code folder consists of code to (1) download data, (2) process the data into the intermediate and final datasets, (3) conduct analyses on the final data. The code folder is numbered in order of folders that are completed sequentially, and the numbers listed next to the data folders and data files correspond to the number of the code file used to create it.
-
data (1,0) : all data is listed in the .gitignore and is thus not stored on github. To retrieve data in its final form without using the given code to direct the raw data from its original source, please refer to this drive folder
-
raw (1,0): all raw data, found at given urls and/or retrieved using scripts in
code/download_data- shapefiles (1,1): folder of shapefiles used to make APPEEARS requests for ECOSTRESS data (https://www.census.gov/geographies/mapping-files/time-series/geo/carto-boundary-file.html)
- counties_5m (1,1): (https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_nation_5m.zip)
- county_shapefiles (1,1): Single county shapefiles
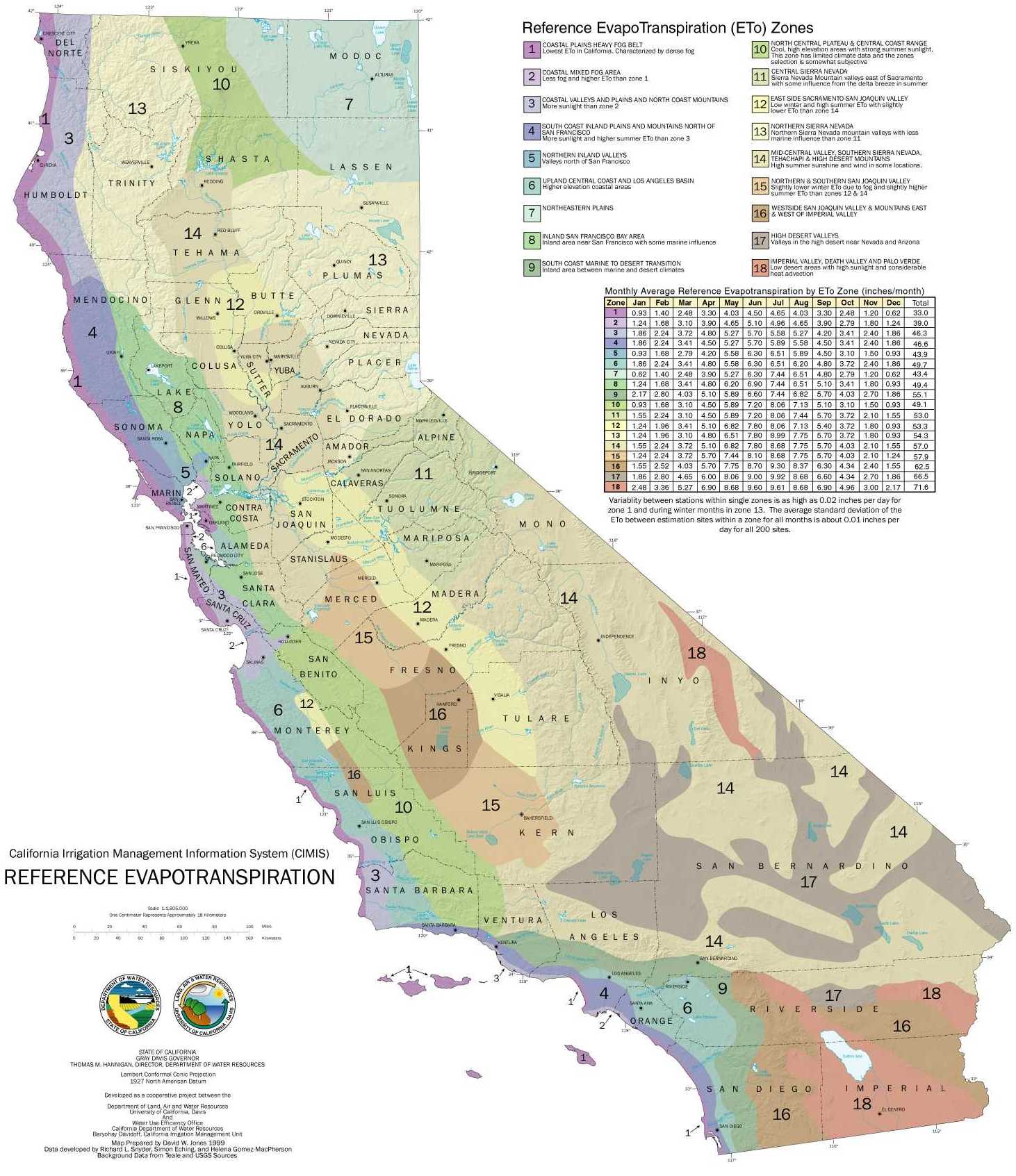
- CIMIS_ETo: boundaries of ETo regions as described https://cimis.water.ca.gov/App_Themes/images/etozonemap.jpg. Obtained through personal correspondance with Ricardo.Trezza@water.ca.gov and DWRCIMISPublicContact@water.ca.gov.
- Hydrologic_Regions: California hydrologic regions accessed at https://atlas-dwr.opendata.arcgis.com/datasets/2a572a181e094020bdaeb5203162de15_0/explore?location=36.394054%2C-119.270000%2C6.70
- Groundwater_basins: from https://gis.data.ca.gov/datasets/b5325164abf94d5cbeb48bb542fa616e_0/explore
- ECOSTRESS (1,2): ECOSTRESS images obtained using the Appeears tool (https://lpdaacsvc.cr.usgs.gov/appeears/task/area). In order to obtain these files, a request is first made on appears using the county shapefiles (code folder 1_2_1). In order to easily download the data into appropriate county level folders once they are ready, either use the appeears interface or code 1_2 in the code folder.
- CDL (1,3)
- CDL* (1,3): the CDL layer for every year needed (2019 and 2020)
- code_dictionary_noncrop: manually pulled from https://www.nass.usda.gov/Research_and_Science/Cropland/metadata/2020_cultivated_layer_metadata.htm
- code_dictionary_crops: manually pulled from https://www.nass.usda.gov/Research_and_Science/Cropland/metadata/2020_cultivated_layer_metadata.htm
- USGS_waterdata
- 2015: https://waterdata.usgs.gov/ca/nwis/water_use?wu_year=2015&wu_area=County&wu_county=ALL&wu_category=IC&submitted_form=introduction&wu_county_nms=--ALL+Counties--&wu_category_nms=Irrigation%2C+Crop
- 2010: https://waterdata.usgs.gov/ca/nwis/water_use?wu_year=2010&wu_area=County&wu_county=ALL&wu_category=IC&submitted_form=introduction&wu_county_nms=--ALL+Counties--&wu_category_nms=Irrigation%2C+Crop
- DWR_crop (1,5): https://data.cnra.ca.gov/dataset/statewide-crop-mapping
- NED: National Elevations Datatset from USGS; 30m resolution. Downloaded from the geospatial data gateway by selecting California as the study area. https://gdg.sc.egov.usda.gov
- DEM: 90m resolution western US elevation data. https://www.sciencebase.gov/catalog/item/542aebf9e4b057766eed286a
- CA_storie: CA storie revised index from gSSURGO and STATSGO2 resampled to the grid of gNATSGO. Obtained through personal correspondence with the CA State Soil Scientist Campbell, Steve - FPAC-NRCS, Portland, OR steve.campbell@usda.gov
- FVEG: CalFire FRAP statewide vegetation data -- 2015 (https://frap.fire.ca.gov/mapping/gis-data/)
- PET: manually pulled from https://data.bris.ac.uk/data/dataset/qb8ujazzda0s2aykkv0oq0ctp
- shapefiles (1,1): folder of shapefiles used to make APPEEARS requests for ECOSTRESS data (https://www.census.gov/geographies/mapping-files/time-series/geo/carto-boundary-file.html)
-
intermediate (1,0)
- CDL_code_dictionary.csv (2,1,x): code dictionary decoding what land cover the CDL raster values stand for. Also contains some binning and grouping of land cover types.
- topography (2,1,4)
- elevation.tif
- aspect.tif
- slope.tif
- CA_storie (2,1,5)
- gNATSGO_storie.tif (2,1,5): 10m resolution CA revised storie index following the gNATSGO grid
- CA_storie.tif (2,1,5): CA_Storie resampled to my constant grid
- PET (2,1,6)
- PETbrick_OGres.tif (2,1,6): a rasterbrick of the raw PET data
- PET_rolling_avg_OGres.tif (2,1,6.5): PET brick aggregated to the desired timesteps
- PET_rolling_avg.tif (2,1,6.5): PET brick aggregated to the desired timesteps and resampled to the consisted CA grid. The start dates are saved as start_dates.pkl
- PET_yeargourped_avg (2,1,6.5): PET brick for two-month intervals starting on Jan 15. The start dates for these intervals are also stored as start_dates_yeargrouped.pkl
- CA_grid.tif (2,1,1): consistent 70m grid to resample all data to.
- agriculture (2,1,2)
- agriculture_shapefile (2,1,2): a flat shapefile for all the ag in California
- ag_indicator.tif (2,1,2): the consistent grid with NA where there is no ag and 1 where there is
- counterf (2,1,3)
- counterf_indicator.tif (2,1,3): the consistent grid ith NA where the land does not work as a counterfactual and 1 where it does
- ECOSTRESS
- dates.csv (2,1,7): every date where instantaneous ET information are available (metadata for ETinst_OGunits.tif)
- ETinst_OGunits.tif (2,1,7): a resampled rasterbrick of all the instantaneous ET measurements. Note that the units have not yet been converted to mm.
- start_dates_yeargrouped.pkl and start_dates.pkl (2,1,6.5): The metadata for the PET rolling average. data.
-
for_analysis (1,0)
- full_grid_time_invariant.csv (2,2,1): The full grid with time invariant variables
- ag_count_time_invariant.csv (2,2,1): Only ag and counterfactual pixels with time invariant variables
- full_grid_no_ET.csv (2,2,1.25): full grid with time invariant variables and PET
- cv_fold_stats_1x1.csv (2,2,2)
- full_cv_outputs_1x1.csv (2,2,2)
-
-
code: all code for data download, processing, and analysis.
-
1_download_data:download data found in
data/raw/- 0_repo_structure.R: create the basic repository structure
- 1_download_shapefiles.R: Download county shapefile and create the required individual county shapefiles
- 2_ECOSTRESS
- 0_repo_structure.R: create the basic repository structure of data/raw/ECOSTRESS
- 1_APPEEARS_requests: documentation on the appeears (https://lpdaacsvc.cr.usgs.gov/appeears/task/area) requests which can be copied to make the requests again
- 2_download_links: links provided by appeears that need to be downloaded
- 3_download_scripts:
- generic-download.sh: template to download the links listed in 2_download_links. Replace all instances of "https://..." with the correct links. Note to position oneself in the correct download folder when running these scripts (ex cd data/raw/ECOSTRESS) and then calling something like "bash ../../../code/1_download_data/2_ECOSTRESS/3_download_scripts/by_request/California-inst-PT-JPL-2-19-5-19.sh". Appeears account and password is needed.
- by_request: a folder of scripts to download for each request
- 3_CDL.R: Download years 2018-2020 of the Cropland Data Layer
- 4_USGS_waterdata.R: Supposed to download the county level California irrigation data from the USGS. SCRIPT NOT FUNCTIONAL: DOWNLOAD MANUALLY and then break up into metadata (first few lines of data) and data
- 5_DWR_crop.R: Download the 2018 crop map shapefile of California in 18 from the Department of Water Resources
-
2_build_dataset: create data in
data/intermediateanddata/for_analysis- 1_intermediate: create data in
data/intermediate- x_CDL_code_dictionary.R: create the code dictionary for crop types
- 1_consistent_grid.R: create one consistent 70m grid for all data to be resampled to.
- 2_agriculture.R: create a shapefile and raster of agriculture based on DWR data
- 3_vegetation.R: create a shapefile and raster of the natural vegetation counterfacutal
- 4_elevation_aspect_slope.R: create rasters of elevation, aspect, and slope from NED sampled to the consistent grid.
- 5_soils.R: create a raster for the storie index resampled to the consistent grid
- 6_PET.R: create a geotif rasterbrick of all the available PET data
- 6.5_PET.py: take the output of 6_PET.R and resample it temporally to aggregate to necessary timesteps. Resample it to the common CA grid from 3_consistent_grid.R
- 6.75_PET_grouped_avg.ipynb: average the output of 6.5_PET_yeargrouped.py across years such that you end up with a stack of only 6 images
- 7_ECOSTRESS_resample.R: resample each ET tif and its corresponding uncertainties to the CA_grid. Remove all data that don't have uncertainties.
- 7.5_ECOSTRESS_subyears.R: similar to 6.5_PET_yeargrouped_average.py, this takes the average of all tifs in a given time period.
- 7_ECOSTRESS_scratch: I ended up trying to process the ECOSTRESS data in so many different ways that I created a scratch folder for the ways that didn't work out.
- 7_ECOSTRESS.R: This file takes the ECOSTRESS data, resamples it to the consistent CA grid, and stacks it. It also creates an accompanying brick of uncertainties. If the uncertainties are missing, then that layer is simply NA. Note that this file can error out because it uses a lot of compute and memory, so I ended up running it in pieces as shown in the 7_ECOSTRESS folder.
- 7.5_ECOSTRESS.py:take the output of 7_ECOSTRESS.R and resample it temporally to aggregate to necessary timesteps. Resample it to the common CA grid from 3_consistent_grid.R
- 7_ECOSTRESS_OGmethod.R: This file generates a csv from all the ECOSTRESS data
- 2_for_analysis: create data in
data/for_analysis- 1_combine_intermediate.py: This script combines all the scripts created in 2,1 to make a dataset of the full grid for all time invariant data (not ET and PET)
- 1.25_combine_intermediate_PET.py: This adds the time varrying PET column
- 1.5_combine_intermediate_ET.py: This adds the time varrying ET column
- 2_random_forest.py: This script uses sklearn random forest with 100 trees to predict ET for each of our timesteps. We validate the model both with a simple 20% test set and a spatial crossvalidation on 1x1 coordianate degree cells. We then apply the model to generate agriculture_sklearn_RF.csv.
- 1_intermediate: create data in
-
3_analysis: conduct analyses on final dataset(s)
- 0_scratch: figures and tests done along the way that do not make it into the final results
- 1_USGS_county_irrigation.Rmd: make some maps of the USGS county irrigation data
- 2_CDL_DWR_USGS_crop_compare.Rmd: compare different land use data
- 1_final: final results for the resulting paper. Written in Rmd; datasets used listed,
- 0_scratch: figures and tests done along the way that do not make it into the final results
-
{kind=link}