v3.5 Performance
-
Testing
1.1. Environment
1.2. Regression
1.2.1. Max Throughput
1.2.2. Bandwidth
1.2.3. Distributed Mode Scalability
1.2.4. Recycle Mode
1.3. New Functionality
1.3.1. Actual Concurrency
- Tuning
- 5 VMs each equivalent to system having Xeon CPU E5 (2.9 GHz, 8 cores)
- In distributed mode tests:
- 1 host is used for load controller instance
- 4 hosts are used for storage driver service instances
- 10 GBit network
- 256 GB of shared memory
In the regression tests below the Mongoose versions 3.4.2 and 3.5.0 have been compared.
Conditions:
- Using dummy storage driver allows to test the Mongoose engine internal performance avoiding storage driver operations.
- The max throughput test is done using the distributed mode.
- Run the test for 5 minutes to see the stabilized rate
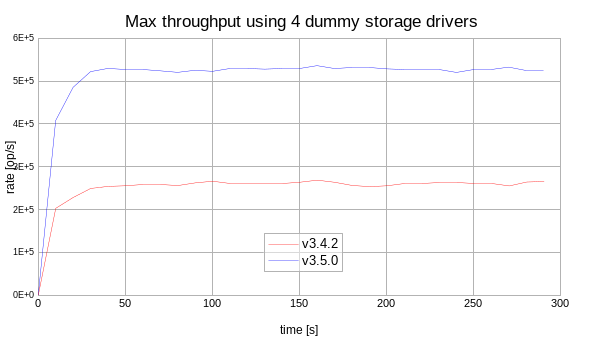
In the new version the sustained throughput is nearly twice higher than in the previous version.
Conditions:
- Creating 100 MB objects on the single remote HTTP storage mock
- Any HTTP-based storage driver may be used (
s3is used by default) - Concurrency level limit: 100
- Run the test for 10 minutes to see the stabilized rate
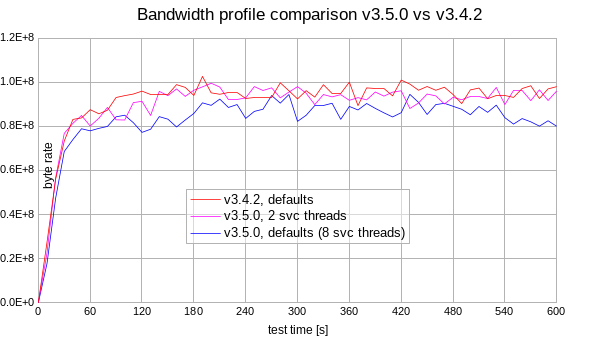
Mongoose v3.5 should be tuned to produce the same bandwidth performance as Mongoose v3.4.2. If using defaults v3.5 shows slightly worse (5-10 %) bandwidth. See tuning details.
Conditions:
- Using dummy storage driver allows to test the Mongoose engine internal performance avoiding storage driver operations.
- The scalability test is done using the distributed mode with different remote storage drivers count (1-4).
- Run each test for 5 minutes to see the stabilized total/summary rate

v3.5 is much better scalable than v3.4.2, however the v3.5 scalability is not linear.
Conditions:
- Using dummy storage driver allows to test the Mongoose engine internal performance avoiding storage driver operations.
- The recycle mode test is done using the distributed mode.
- Read 10K objects using the prepared items input file.
- Recycle mode is enabled with default options.
- Run each test for 10 minutes to see the stabilized rate.
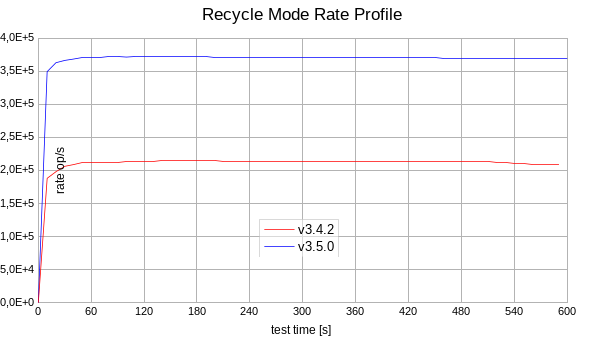
+75% rate increase observed in the recycle mode for v3.5 than for v3.4.2.
Conditions:
- Creating the objects on the single remote HTTP storage mock with different sizes (10KB, 100KB, ...).
- Concurrency level is unlimited.
- Run each test for 20 minutes to see the stable actual concurrency.
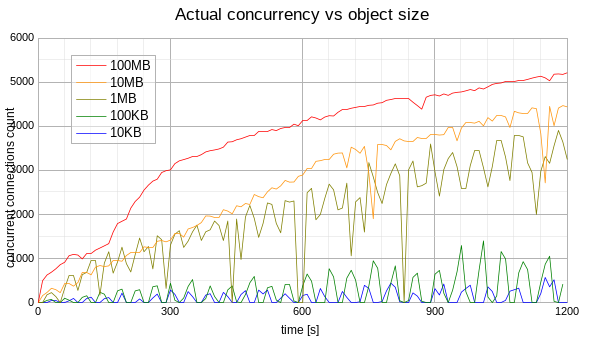
Unfortunately, no stable measurements of the actual concurrency had been observed. The actual concurrency is growing while writing large objects (10MB, 100MB). The actual concurrency is very unstable while writing small objects(10KB, 100KB). These observations mean that measuring the actual concurrency without specific rate limit doesn't make much sense.
Mongoose uses fixed thread count to perform its work. Some threads may be used to perform the necessary calculations (load generation, etc) while the other threads are used to perform the interaction with a storage (I/O load). Using more threads for "calculations" causes higher throughput (operations count per unit of time), higher responsiveness (e.g. lower latency). However using more threads for I/O causes higher observable bandwidth (transferred bytes count per unit of time), which is especially obvious while performing I/O on the large data items.
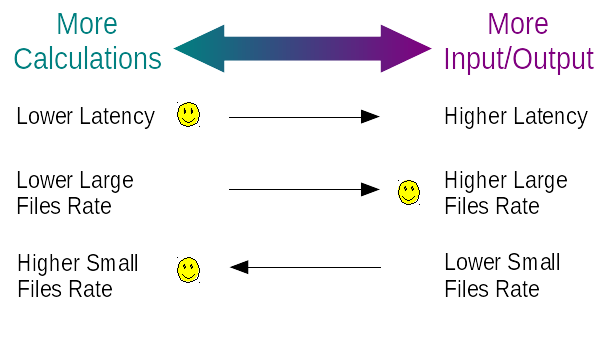
By default Mongoose v3.5 uses the same thread count for the
"calculations" and I/O which is good enough to sustain high throughput
and low latency. The count of the "calculation" threads is controlled by
the load-service-threads configuration option. The concrete behavior
depends on the storage driver type used:
-
NIO-based storage driver type (
fsonly currently):The total count of the threads used for execution is calculated as the count of the CPU cores available. Any of these threads may be used for the I/O. The count of simultaneously executed I/O tasks is limited by
storage-driver-threadsconfiguration option value which is equal to the CPU cores count also by default. -
Netty-based storage driver type (
s3,atmos,emcs3,swift):Netty has its own internal worker threads pool. The default count of the Netty's worker threads is equal to CPU cores count, so the total count of the worker threads is twice more than CPU cores count. As mentioned before, this is good for high throughput and low latency. For high bandwidth tests it's better to set the "calculation" threads count to a lower value than the default. It should be done using
load-service-threadsconfiguration option. For higher bandwidth in the test above the count of the "calculation" threads was set to 2 instead of default (8).