| OS | CI testing on master |
|---|---|
 |
|
 |
|
Visit docs.quiltdata.com. Or browse the docs on GitHub.
Quilt provides versioned, reusable building blocks for analysis in the form of data packages. A data package may contain data of any type or size. In spirit, Quilt does for data what package managers and Docker registries do for code: provide a centralized, collaborative store of record.
- Reproducibility - Imagine source code without versions. Ouch. Why live with un-versioned data? Versioned data makes analysis reproducible by creating unambiguous references to potentially complex data dependencies.
- Collaboration and transparency - Data likes to be shared. Quilt offers a centralized data warehouse for finding and sharing data.
- Auditing - the registry tracks all reads and writes so that admins know when data are accessed or changed
- Less data prep - the registry abstracts away network, storage, and file format so that users can focus on what they wish to do with the data.
- Deduplication - Data fragments are hashed with
SHA256. Duplicate data fragments are written to disk once globally per user. As a result, large, repeated data fragments consume less disk and network bandwidth. - Faster analysis - Serialized data loads 5 to 20 times faster than files. Moreover, specialized storage formats like Apache Parquet minimize I/O bottlenecks so that tools like Presto DB and Hive run faster.
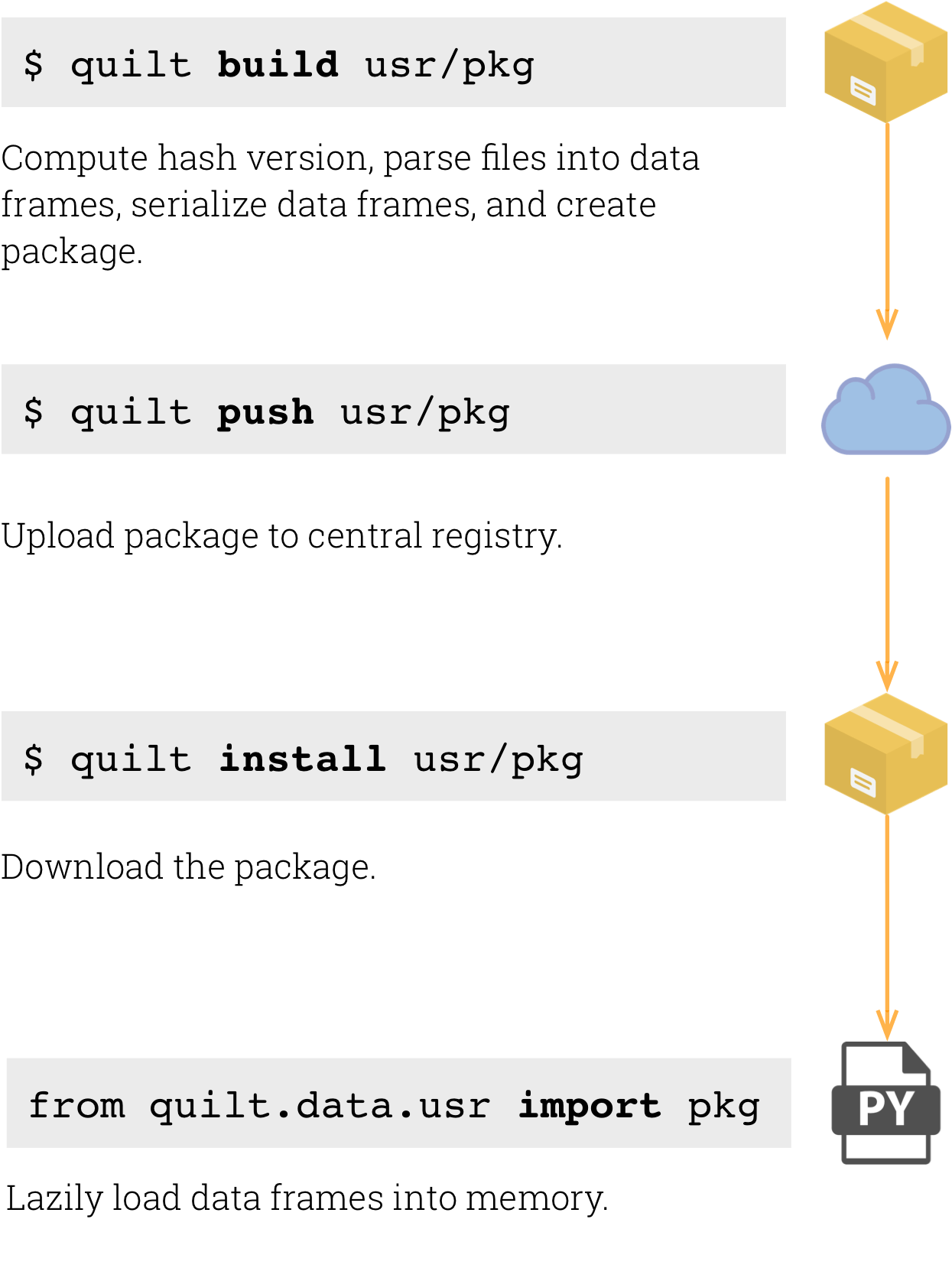
Here are the basic Quilt commands:
Quilt is offered as a managed service at quiltdata.com.
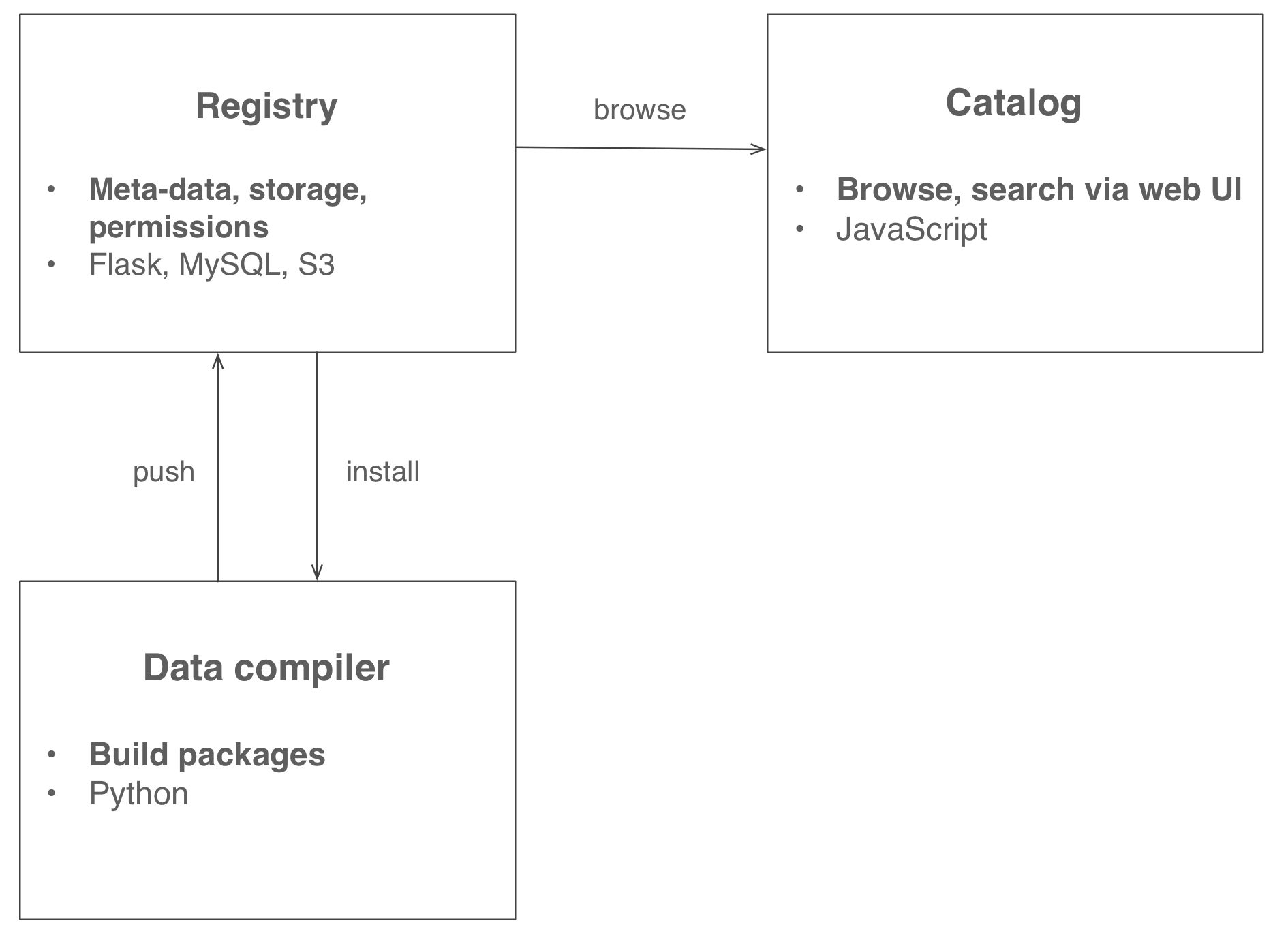
Quilt consists of three source-level components:
-
- Displays package meta-data in HTML
- Implemented with JavaScript with redux, sagas
-
- Controls permissions
- Stores package fragments in blob storage
- Stores package meta-data
- De-duplicates repeated data fragments
- Implemented in Python with Flask and PostgreSQL
-
- Serializes tabular data to Apache Parquet
- Transforms and parses files
builds packages locallypushes packages to the registrypulls packages from the registry- Implemented in Python with pandas and PyArrow