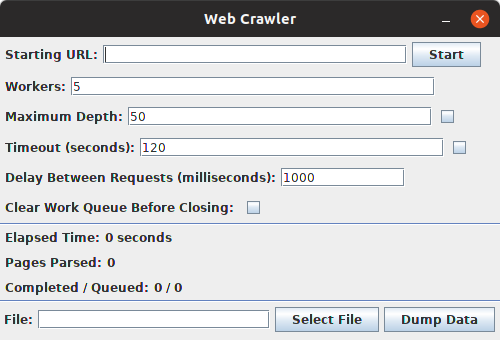
Breadth first search web scraper written in Java using the JavaFX toolkit.
- Breadth first search from a starting URL
- Customizable parsing settings
- Number of parallel threads
- Maximum link traversal depth
- Crawler timeout (lifetime)
- Delay between requests
- Optional to clear parsing queue before finishing
- This will take a long time
- Keep track of parsing status with simple statistics
- Total crawling time
- Number of unique pages saved
- Number of pages visited / number of pages queued
- Output scraped data to a JSON file
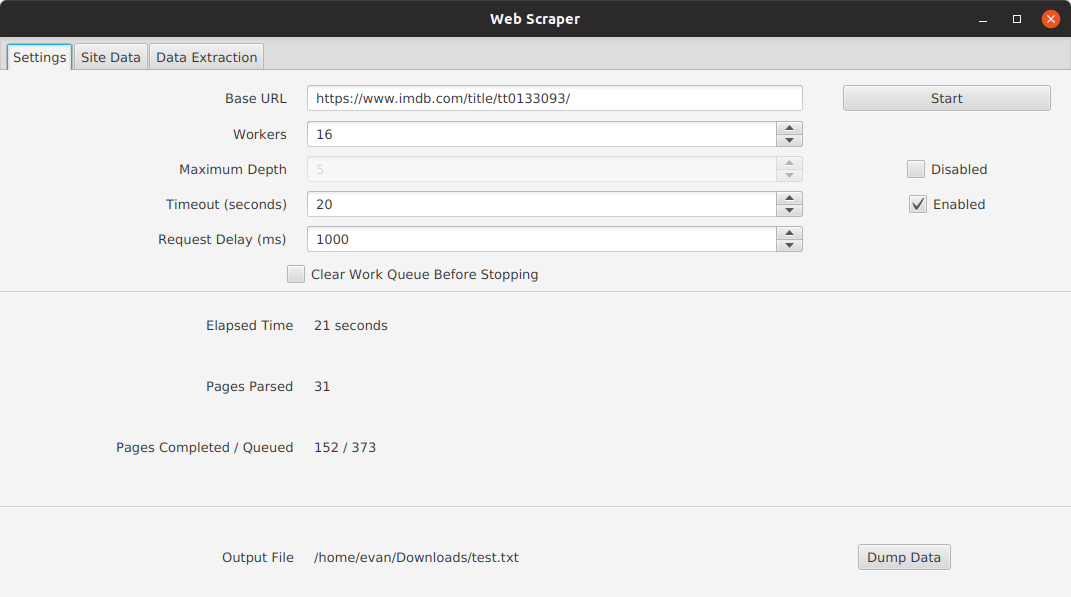
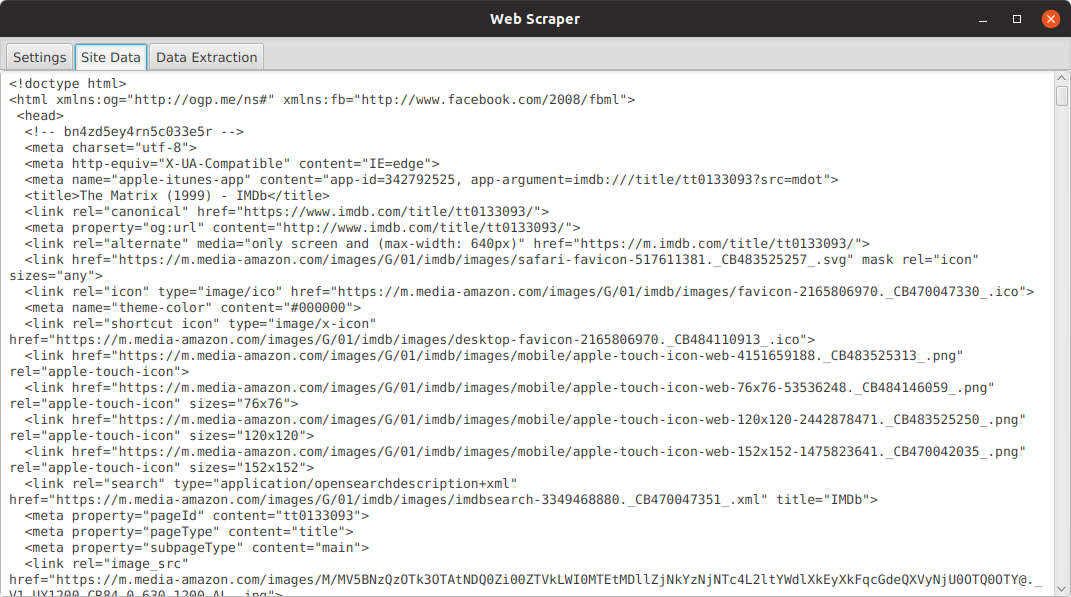
- View base url's HTML code to determine selectors
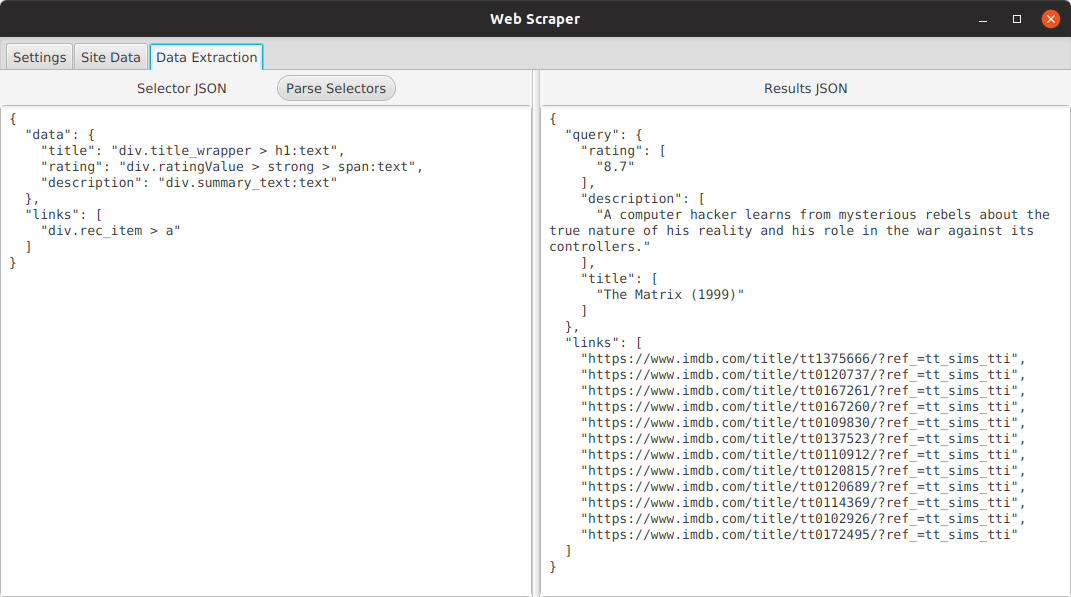
- Selector view
- Set the JSON output format by settings variable names and CSS selectors
- Interactively test your selectors before starting the crawl
- Graph View
- Get a deep understanding of the path the crawler took in a visual format
- Click any node to see the URL and data scraped from it
- Entertaining to watch
- Special Selectors
[type]title- get the page's titleurl- get the page`s url
- Data Selectors
[css selector]:[type]- CSS Selectors
- Use css syntax to select elements
div.class_name > h1selects an h1 with a parent div of classclass_name
- Types
text- get all text between the given element<p>Hello <e>World!</e></p>->Hello World!
owntext- get only the text between the given element<p>Hello <e>World!</e></p>->Hello
href- get link contained inhref=attribute
- CSS Selectors
- The selector should be a valid JSON object. It must have a
dataandlinkstag. - Each data element you want to extract has a unique title to identify it
- The links tag is an array of selectors pointing to anchor tags
- The crawler will use these links'
hrefattribute to traverse from page to page. - If you do not care what links you are selecting just use
ato follow any anchor tag link.
- The crawler will use these links'
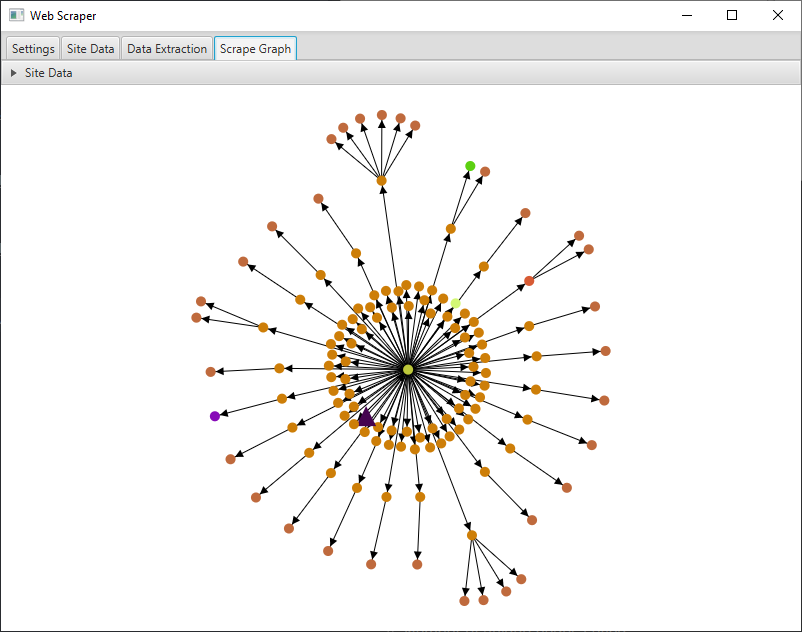
- Nodes are added to the graph in real time and in the order they are traversed
- Select a node to view the URL and data associated with it in the dropdown
- Nodes are colored according to depth. Nodes of the same color were found at the same depth
- Gradle
- JSoup
- Guava
- Lombok
- Gson
- JavaFX
- GraphStream
- SLF4J / Logback
- The project uses the Gradle build system. Simply import the project into any IDE and run the "application -> run" task
- Download a prebuilt binary to run on any platform with 0 dependencies
java -jar [jarfile].jar