Fix issue with multiple code branches in hooks linter #14661
Conversation
|
Thank you for your pull request and welcome to our community. We require contributors to sign our Contributor License Agreement, and we don't seem to have you on file. In order for us to review and merge your code, please sign up at https://code.facebook.com/cla. If you are contributing on behalf of someone else (eg your employer), the individual CLA may not be sufficient and your employer may need the corporate CLA signed. If you have received this in error or have any questions, please contact us at cla@fb.com. Thanks! |
| `; | ||
|
|
||
| exports[`ReactDebugFiberPerf supports portals 1`] = ` | ||
| exports[`ReactDebugFiberPerf supports memo 1`] = ` |
There was a problem hiding this comment.
I'm not really sure why this changed, as I just run the tests, and didn't ask for snapshot updating at any time.
| return 0; | ||
| } | ||
| function countPathsFromStart(segment, visited = new Set()) { | ||
| if (codePath.thrownSegments.includes(segment)) { |
There was a problem hiding this comment.
Is it okay includes method without polyfill?
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/includes
There was a problem hiding this comment.
I guess so, since the linter always runs in a node environmemt.
There was a problem hiding this comment.
Also, IIRC, thrownSegments isn’t an array here, it’s just array-like.
There was a problem hiding this comment.
Assuming this is an eslint@5 plugin, then yes as it's supported since node 6.
(Unless there are specific rules against it here?)
There was a problem hiding this comment.
Since it is a direct extract from the original code, this shouldn't really be an issue.
|
Thank you for signing our Contributor License Agreement. We can now accept your code for this (and any) Facebook open source project. Thanks! |
| */ | ||
|
|
||
| function countPathsFromStart(segment) { | ||
| const {cache} = countPathsFromStart; |
There was a problem hiding this comment.
Hi 👋
I’m the original author of this ESLint rule popping in for a review.
The reason I used a cache here is that in complex components, time complexity can really start to spike up. Consider:
function MyComponent() {
if (a) {} else {}
if (b) {} else {}
if (c) {} else {}
useHook();
}Here we have 23 = 8 paths from useHook() to the start of MyComponent. Representing the following combinations of a, b, and c.
| a | b | c |
|---|---|---|
| true | true | true |
| false | true | true |
| true | false | true |
| false | true | false |
| true | false | false |
| false | true | false |
| false | false | true |
| false | false | false |
So we have a 2n exponential relationship, fun. Now remember that every && and || (in the future perhaps also ??) introduces a condition since false && expensive() will not execute expensive().
Let’s say we have a complex component that has 5 conditions placed in the component before 6 hooks all in the same segment. Without a cache we have to call countPathsFromStart() on 25 paths 6 times. With a cache, we only need to call countPathsFromStart() on 2 × 5 segments because we cache the value for every segment so we only need to visit each segment once.
In big-O notation where “n” is the number of conditions and “h” is the number of hooks, we have O(2n) time complexity with a cache and O(2n × h) without a cache.
To see what I mean in practice try adding the following component to the test suite. On this branch, I became impatient after waiting about 10s for the test to finish. When I switched back to master the entire ESLint test suite finished in about 3s.
It’s up to the React team (cc @gaearon) to determine whether or not this performance regression is acceptable. 20 conditions and 10 hooks were fine for me on this branch, but 40 conditions and 10 hooks were not. If this performance regression is not acceptable then I recommend adding the below component to the test suite.
function MyComponent() {
// 40 conditions
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
if (c) {} else {}
// 10 hooks
useHook();
useHook();
useHook();
useHook();
useHook();
useHook();
useHook();
useHook();
useHook();
useHook();
}There was a problem hiding this comment.
Hi! Thanks for the chime in, explaining the original rationale behind this piece of code, that was really enlightening.
Unfortunately, I'm not sure there's a way to work around this performance regression. Using the cache as it is proved itself faulty and could lead to false negatives, as issue proved.
I could just remove the item from the cache once we finished visiting it, but the complexity of the overall algorithm would be the same.
I guess the complexity of the problem of finding the number of paths between two nodes on a graph can't really be reduced here.
I'll think about how we could improve it for the case of multiple hooks, so the complexity is not so high.
There was a problem hiding this comment.
I added some comments below with a possible solution and the rationale behind that solution. TL;DR when countPathsFromStart() breaks a cycle it gives a temporary result of 0 to avoid looping forever.
|
@Yurickh I found a fix for the problem that does not involve removing the cache. In paths += countPathsFromStart(prevSegment);
}
}
- cache.set(segment.id, paths);
+ // If our segment is reachable then there should be at least one path
+ // to it from the start of our code path.
+ if (segment.reachable && paths === 0) {
+ cache.delete(segment.id);
+ } else {
+ cache.set(segment.id, paths);
+ }
return paths;
}If you choose to use this fix, I encourage you to think about why this is the correct solution. In theory, Perhaps there is a more principled fix in the If you choose to use this fix I also recommend adding the test case I included above to prevent future performance regressions. |
|
A more in-depth look at this problem. To debug I added to the top of the console.log(' '.repeat(i) + segment.id);That gives us: @LosYear’s diagram from #14362 is really helpful for understanding this output, so I’ll include it:
Adding some annotations to the log: Our first call to So that’s why we delete the result when |
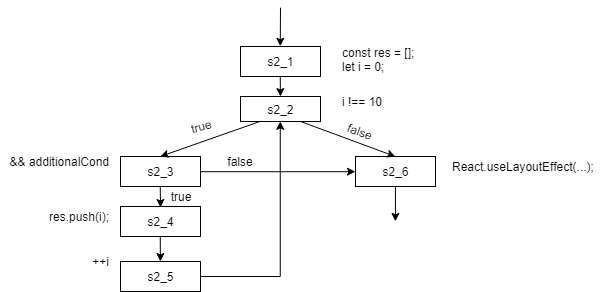
|
Looks like this really solves the problem for good, without significant performance loss. Thank you so much for the insight! This turned out being a great solution after all. |
|
I apologize in advance for the off-topic irrelevance of my question to this PR; there is no true "code review" feature of arbitrary piece of code at arbitrary time in GitHub yet, only "diff review". I was curious and looked around the code of the eslint rule, and found this comment which raised a question in me: and then: I reviewed the In particular, I may write a function component this way, using an anonymous function: Would it become a problem that the anonymous function inside a call argument is meant to be a React function component, but it's not annotated to be that? Is this a rule now to not use anonymous functions to define React function components? |
|
Hi, @sompylasar. In fact, you'll find an issue about your discoveries on #14404 (comment) |
|
@Yurickh Thanks! It's exactly that. I searched for eslint hooks issues but missed this one (oh I realized I might have had is:pr in the filters). |
|
Thank you! |
* Fix issue with multiple code branches * Add solution by @calebmer * Add performance test * Undo unrelated change
I changed the algorithm to a simple DFS so we can find the correct number of possible paths from the hook to the start of the function.
I'm not sure I should change the other (similar) functions as I couldn't think of a breaking example for them.
Fixes #14362