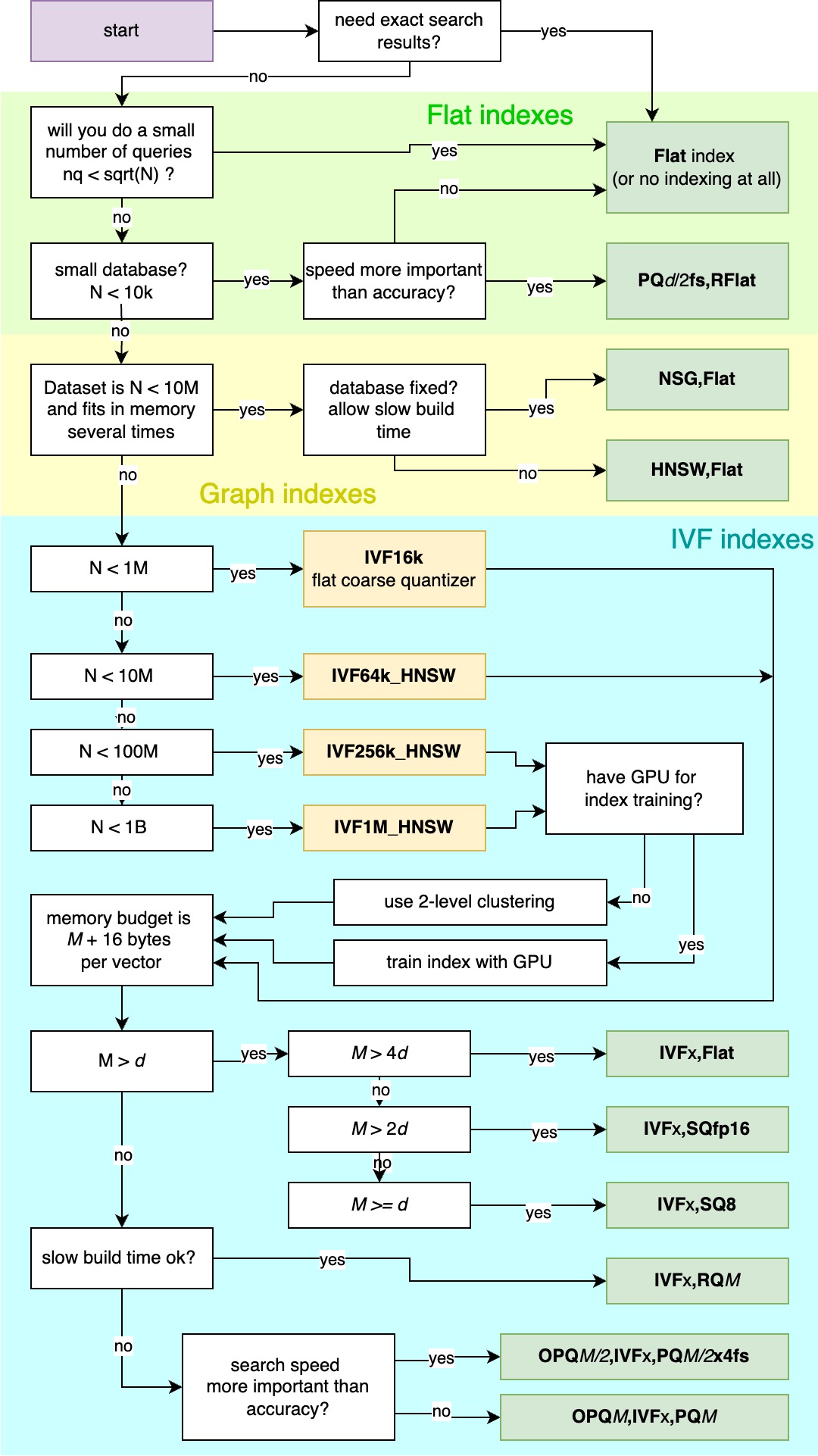
Guidelines to choose an index
Choosing an index is not obvious, so here are a few essential questions that can help in the choice of an index. They are mainly applicable for L2 distances. We indicate:
-
the
index_factorystring for each of them. -
if there are parameters, we indicate them as the corresponding
ParameterSpaceargument.
See the bottom of the page for a summary decision tree.
If you plan to perform only a few searches (say 1000-10000), the index building time will not be amortized by the search time. Then direct computation is the most efficient option.
This is done via a "Flat" index. If the whole dataset does not fit in RAM, you can build small indexes one after another, and combine the search results (see Combining results of several searches on how to do this) .
The only index that can guarantee exact results is the IndexFlatL2 or IndexFlatIP. It provides the baseline for results for the other indexes. It does not compress the vectors, but does not add overhead on top of them. It does not support adding with ids (add_with_ids), only sequential adds, so if you need add_with_ids, use "IDMap,Flat". The flat index does not require training and does not have parameters.
Supported on GPU: yes
Keep in mind that all Faiss indexes are stored in RAM. The following considers that if exact results are not required, RAM is the limiting factor, and that within memory constraints we optimize the precision-speed tradeoff.
If you have a lots of RAM or the dataset is small, HNSW is the best option, it is a very fast and accurate index. The 4 <= M <= 64 is the number of links per vector, higher is more accurate but uses more RAM. The speed-accuracy tradeoff is set via the efSearch parameter. The memory usage is (d * 4 + M * 2 * 4) bytes per vector.
HNSW does only support sequential adds (not add_with_ids) so here again, prefix with IDMap if needed. HNSW does not require training and does not support removing vectors from the index.
The second option is faster than HNSW.
However it requires a re-ranking stage and thus there are two parameters to adjust: the k_factor of reranking and the nprobe of the IVF.
Supported on GPU: no
"..." means a clustering of the dataset has to be performed beforehand (read below). After clustering, "Flat" just organizes the vectors into buckets, so it does not compress them, the storage size is the same as that of the original dataset. The tradeoff between speed and accuracy is set via the nprobe parameter.
Supported on GPU: yes (but see below, the clustering method must be supported as well)
If storing the whole vectors is too expensive, this performs two operations:
-
an OPQ transform to dimension D to reduce the dimension
-
a PQ quantization of the vectors into M 4-bit codes.
Therefore the total storage is M/2 bytes per vector.
Supported on GPU: yes
PQM compresses the vectors using a product quantizer that outputs M-byte codes. M is typically <= 64, for larger codes SQ is usually as accurate and faster. OPQ is a linear transformation of the vectors to make them easier to compress. D is a dimension such that:
- D is a multiple of M (required)
- D <= d, with d the dimension of the input vectors (preferable)
- D = 4*M (preferable)
Supported on GPU: yes (note: the OPQ transform is done on CPU, but it is not performance critical)
This question is used to fill in the clustering options (the ... above). The dataset is clustered into buckets and at search time, only a fraction of the buckets are visited (nprobe buckets). The clustering is performed on a representative sample of the dataset vectors, typically a sample of the dataset. We indicate the optimal size for this sample.
Where K is 4*sqrt(N) to 16*sqrt(N), with N the size of the dataset. This just clusters the vectors with k-means. You will need between 30*K and 256*K vectors for training (the more the better).
Supported on GPU: yes
IVF in combination with HNSW uses HNSW to do the cluster assignment. You will need between 30 * 65536 and 256 * 65536 vectors for training.
Supported on GPU: no (on GPU, use IVF as above)
Same as above, replace 65536 with 262144 (2^18).
Note that training is going to be slow, to avoid this, there are two options:
-
do just the training on GPU, everything else running on CPU, see train_ivf_with_gpu.ipynb.
-
do a two-level clustering, see demo_two_level_clustering.ipynb
Same as above, replace 65536 with 1048576 (2^20). Training will be even slower!