{kind=link}
{kind=link}
Naive parallel Floyd-Warshall algorithm (all-pairs shortest path on dense weighted graphs) using OpenMP.
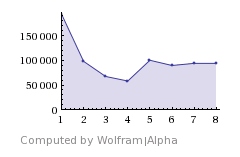
Plot above is time (us) vs number of threads (on a machine with 4 cores as you can guess),
for a 1000x1000 matrix of random floats.
The multi-threaded version is up to 3.6x faster than single-threaded on 4 cores,
which is pretty good for a memory-bound algorithm.
However, it's still a O(n^3) algorithm.
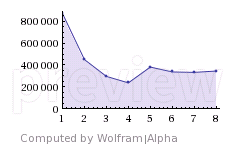
Additionally enabling auto-vectorization in gcc 5.4.0 (-march=native -ftree-vectorize) results in
a total of up to 14x speedup on a 4-core Intel i5-3570 (sse4.2), see plot below: