-
|
Is your feature request related to a problem? Please describe. Describe the solution you'd like | id | Human_description | and so on, now append these values to the Case example. Next step is a user would like to extract any INVALID records from the Describe alternatives you've considered Additional context |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments
-
|
My second question to the new structure is why have you chosen to delete the That I don't understand.... as it as i see it at first will increase the share size of the DB with unnecessary 100's of megabytes. |
Beta Was this translation helpful? Give feedback.
-
|
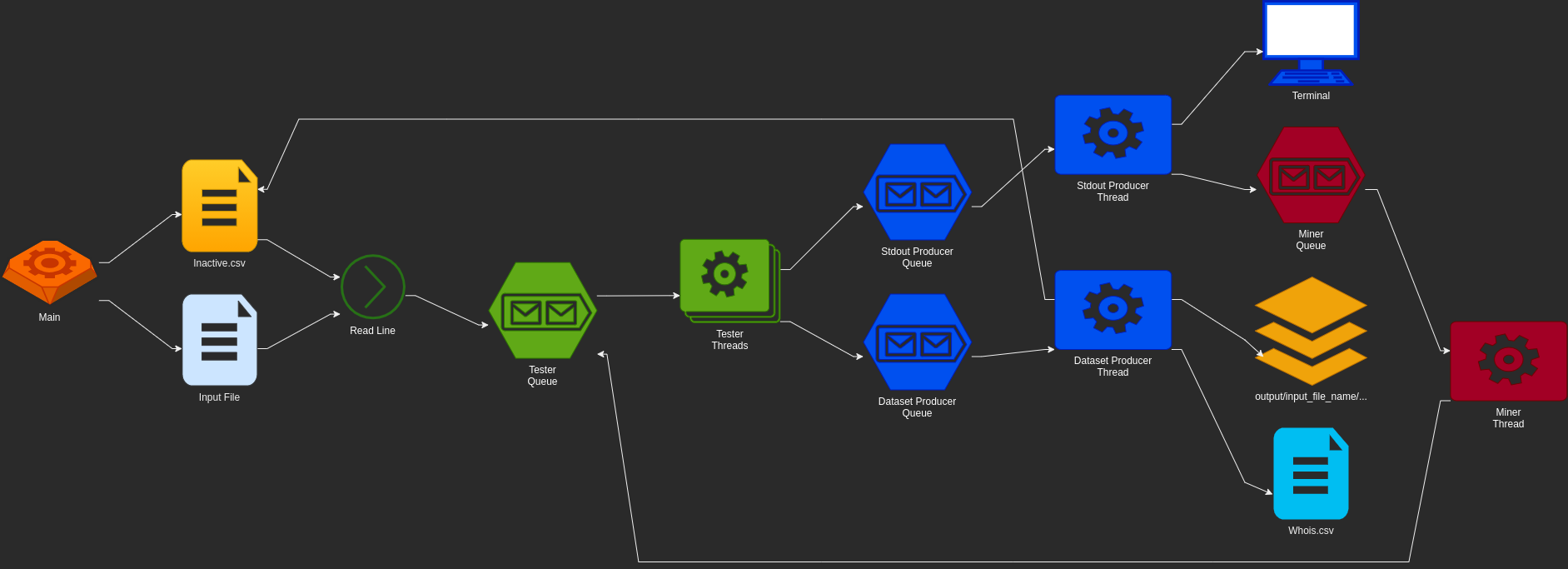
The Keep in mind that the data that are stored in there are not meant for usage outside of PyFunceble itself. In the past, because of a bad design, I choose to store all those data, so that I could generate the files at the real end (once I finished the tests of everything). That means that in the past, you could theoretically, sneak in the database and read and do your thing as long as it is working. With our new thread model for the CLI tests, the file writing is done almost instantly without any trick or hack like I used to do in the past. In the past, because of the unsafety (while writing files) behind the parallel process, I chose not to write immediately into the output files. That's why most of us know through the Right now, when the testing task is done, it submits the result (itself) to the producer queue, which then (in parallel) generates the files in a sequential and safe mater. So, the reason I had such tables in the past, was because I was doing everything regarding the file generation under the multiprocessing mode, at the real end. Meaning that I had to store the data somewhere until the testing session was complete. With our new model, it's done in the background by a dedicated thread that is just waiting for new data. Just look at it: PyFunceble/PyFunceble/cli/threads/producer.py Lines 351 to 403 in f557b0d We have to think about your proposition of changing the status to a number. But you'll have to convince me because I'm not ready to make the source code over complicated over this. Right now, the source code related to the dataset matches and use the dataset that is generated/produced by each checker. I unified every checker status so that I could manipulate the data without having to compute anything. Meaning that when the tester threads send their results to the producer threads, the data is directly transferred to one of the dataset handlers which then works directly without any huge conversion. In other words, the dataset handlers are understanding information and directory work with them without any substantial non-human conversion. But you may be right about the storage size. I'm open for discussion though. About the
|
{kind=link}
Beta Was this translation helpful? Give feedback.
-
This is regarding to the DB optimization, as reusing a value, are 1. faster, 2. use less space = less I/O.
Again a Huge DB optimization possibility: Only hold the domain/URI, the record and it's status don't care about how or where the records are coming from, and next time you are testing the source; maybe even same file, from are different path(URI), the same data are stored over and over again. leading to tons of data waste. This is about Skip the source ref, or at least reverse it, to be the source that links to the records, but in my universe, skip it entirely. Also as you mention
Short, when you starting a new test, link the source to the records for this test, and drop the contents after the test is stopped(incl completed) This will also improve the , as you reuse the record data from previous test of same record, as the previous test are no longer fixed to s specified source, and your match for skip will be like: COMPARISON_FIELDS: List[str] = [
"idna_subject",
"checker_type",
] Way faster and smaller DB table = faster search and rebuild on changes.
Oh yeah, as mentioned a couple of times over the years, a DB is source for stored results(data) to be:
Any of these methods for data sharing should always be OPT-in as PyFunceble are easily used to test private zones
Yep, this issue are also 4 years old 😏
Good, it was only fill ❤️ and the status should be store with its record( which for performance are a ref to a third table with status) See also: #383 |
Beta Was this translation helpful? Give feedback.
The
pyfunceble_filetable was in my mind useless. Thepyfunceble_continueandpyfunceble_inactiveare sufficient for PyFunceble (itself). In fact, I'm convinced that the JOIN I had to systematically to get the right dataset was slowing down PyFunceble (among other things in the past design).Keep in mind that the data that are stored in there are not meant for usage outside of PyFunceble itself. In the past, because of a bad design, I choose to store all those data, so that I could generate the files at the real end (once I finished the tests of everything). That means that in the past, you could theoretically, sneak in the database and read and do your thing as long as it is working. Wit…