![]()
(Framework for Adapting Representation Models)



FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built upon transformers and provides additional features to simplify the life of developers: Parallelized preprocessing, highly modular design, multi-task learning, experiment tracking, easy debugging and close integration with AWS SageMaker.
With FARM you can build fast proof-of-concepts for tasks like text classification, NER or question answering and transfer them easily into production.
- What is it?
- Core Features
- Resources
- Installation
- Basic Usage
- Advanced Usage
- Core Concepts
- FAQ
- Upcoming features
- Easy fine-tuning of language models to your task and domain language
- Speed: AMP optimizers (~35% faster) and parallel preprocessing (16 CPU cores => ~16x faster)
- Modular design of language models and prediction heads
- Switch between heads or combine them for multitask learning
- Full Compatibility with HuggingFace Transformers' models and model hub
- Smooth upgrading to newer language models
- Integration of custom datasets via Processor class
- Powerful experiment tracking & execution
- Checkpointing & Caching to resume training and reduce costs with spot instances
- Simple deployment and visualization to showcase your model
| Task | BERT | RoBERTa* | XLNet | ALBERT | DistilBERT | XLMRoBERTa | ELECTRA | MiniLM |
|---|---|---|---|---|---|---|---|---|
| Text classification | x | x | x | x | x | x | x | x |
| NER | x | x | x | x | x | x | x | x |
| Question Answering | x | x | x | x | x | x | x | x |
| Language Model Fine-tuning | x | |||||||
| Text Regression | x | x | x | x | x | x | x | x |
| Multilabel Text classif. | x | x | x | x | x | x | x | x |
| Extracting embeddings | x | x | x | x | x | x | x | x |
| LM from scratch (beta) | x | |||||||
| Text Pair Classification | x | x | x | x | x | x | x | x |
| Passage Ranking | x | x | x | x | x | x | x | x |
* including CamemBERT and UmBERTo
**NEW** Interested in doing Question Answering at scale? Checkout Haystack!
Docs
Tutorials
- Tutorial 1 (Overview of building blocks): Jupyter notebook 1 or Colab 1
- Tutorial 2 (How to use custom datasets): Jupyter notebook 2 or Colab 2
- Tutorial 3 (How to train and showcase your own QA model): Colab 3
- Example scripts for each task: FARM/examples/
Demo
Checkout https://demos.deepset.ai to play around with some models
More
- Intro to Transfer Learning (Blog)
- Intro to Transfer Learning & FARM (Video)
- Question Answering Systems Explained (Blog)
- GermanBERT (Blog)
- XLM-Roberta: The alternative for non-english NLP (Blog)
Recommended (because of active development):
git clone https://github.com/deepset-ai/FARM.git cd FARM pip install -r requirements.txt pip install --editable .
If problems occur, please do a git pull. The --editable flag will update changes immediately.
From PyPi:
pip install farm
Note: On windows you might need pip install farm -f https://download.pytorch.org/whl/torch_stable.html to install PyTorch correctly
FARM offers two modes for model training:
Option 1: Run experiment(s) from config

Use cases: Training your first model, hyperparameter optimization, evaluating a language model on multiple down-stream tasks.
Option 2: Stick together your own building blocks
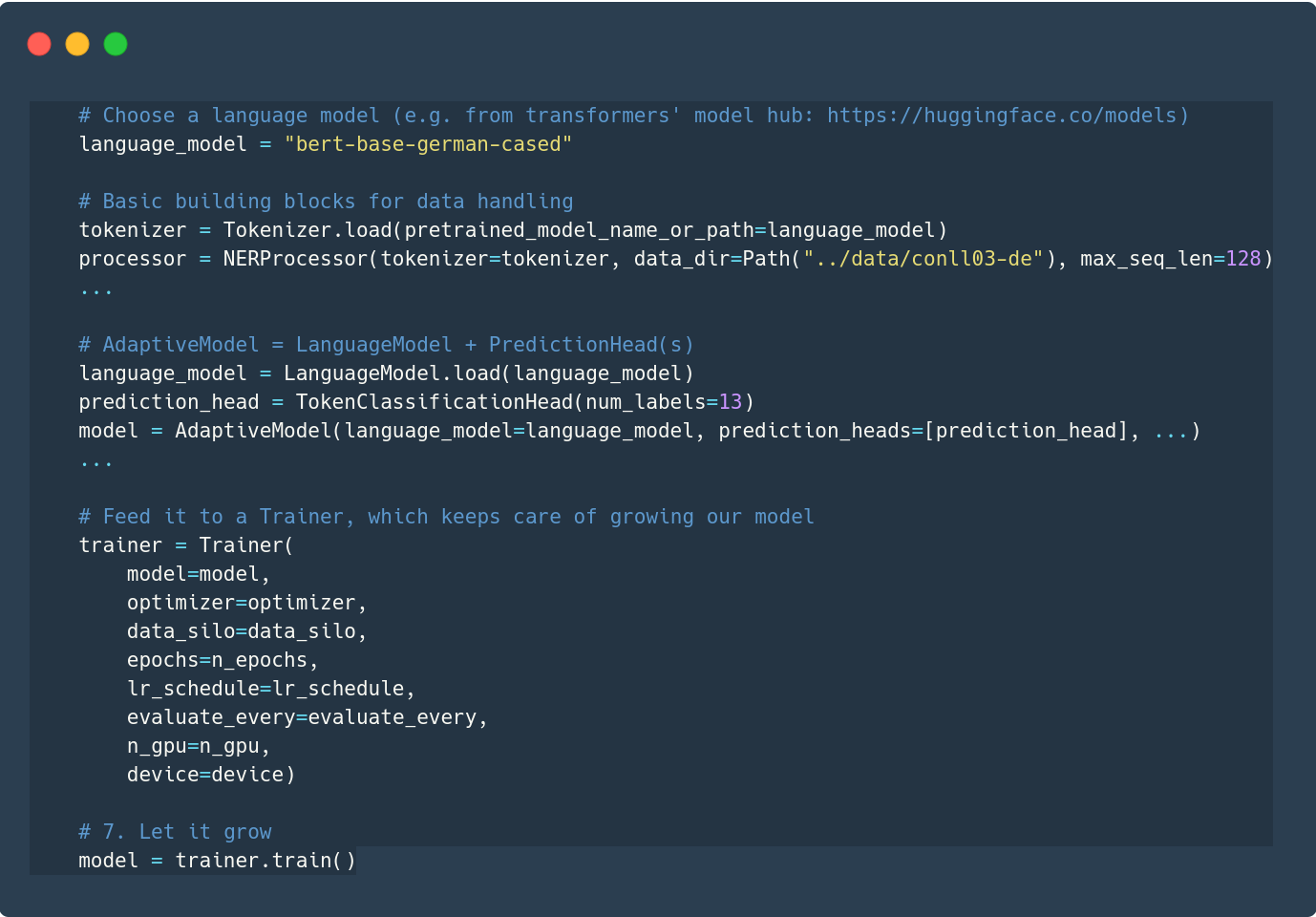
Usecases: Custom datasets, language models, prediction heads ...
Metrics and parameters of your model training get automatically logged via MLflow. We provide a public MLflow server for testing and learning purposes. Check it out to see your own experiment results! Just be aware: We will start deleting all experiments on a regular schedule to ensure decent server performance for everybody!
Use a public model or your own to get predictions:
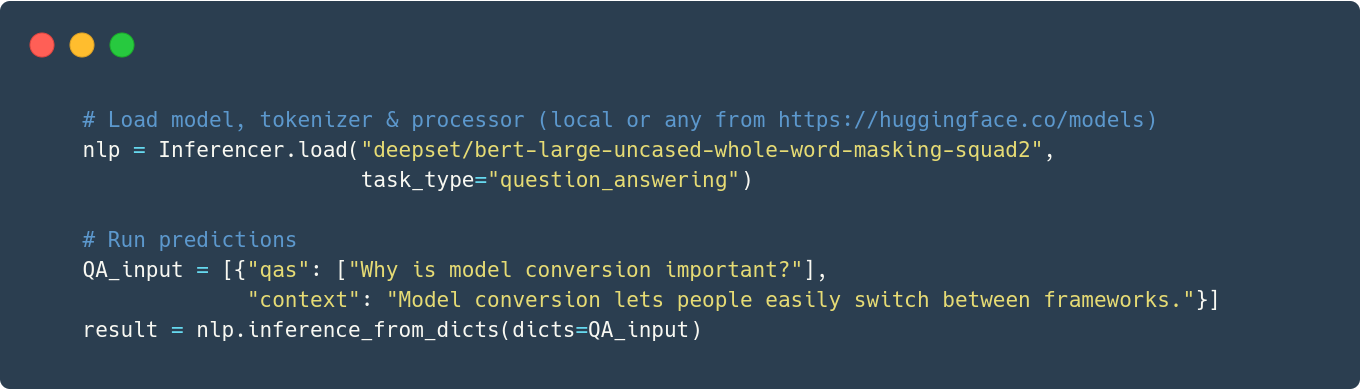
- Run
docker-compose up - Open http://localhost:3000 in your browser

One docker container exposes a REST API (localhost:5000) and another one runs a simple demo UI (localhost:3000). You can use both of them individually and mount your own models. Check out the docs for details.
Once you got started with FARM, there's plenty of options to customize your pipeline and boost your models. Let's highlight a few of them ...
While FARM provides decent defaults for both, you can easily configure many other optimizers & LR schedules:
- any optimizer from PyTorch, Apex or Transformers
- any learning rate schedule from PyTorch or Transformers
You can configure them by passing a dict to initialize_optimizer() (see example).
With early stopping, the run stops once a chosen metric is not improving any further and you take the best model up to this point. This helps prevent overfitting on small datasets and reduces training time if your model doesn't improve any further (see example).
If you do classification on imbalanced classes, consider using class weights. They change the loss function to down-weight frequent classes. You can set them when you init a prediction head:
prediction_head = TextClassificationHead( class_weights=data_silo.calculate_class_weights(task_name="text_classification"), num_labels=len(label_list))`
Get more reliable eval metrics on small datasets (see example)
Save time if you run similar pipelines (e.g. only experimenting with model params): Store your preprocessed dataset & load it next time from cache:
data_silo = DataSilo(processor=processor, batch_size=batch_size, caching=True)
Start & stop training by saving checkpoints of the trainer:
trainer = Trainer.create_or_load_checkpoint(
...
checkpoint_on_sigterm=True,
checkpoint_every=200,
checkpoint_root_dir=Path(“/opt/ml/checkpoints/training”),
resume_from_checkpoint=“latest”)
The checkpoints include the state of everything that matters (model, optimizer, lr_schedule ...) to resume training. This is particularly useful, if your training crashes (e.g. because your are using spot cloud instances). You can either save checkpoints every X steps or when a SIGTERM signal is received.
We are currently working a lot on simplifying large scale training and deployment. As a first step, we are adding support for training on AWS SageMaker. The interesting part here is the option to use Managed Spot Instances and save about 70% on costs compared to the regular EC2 instances. This is particularly relevant for training models from scratch, which we introduce in a basic version in this release and will improve over the next weeks. See this tutorial to get started with using SageMaker for training on down-stream tasks.
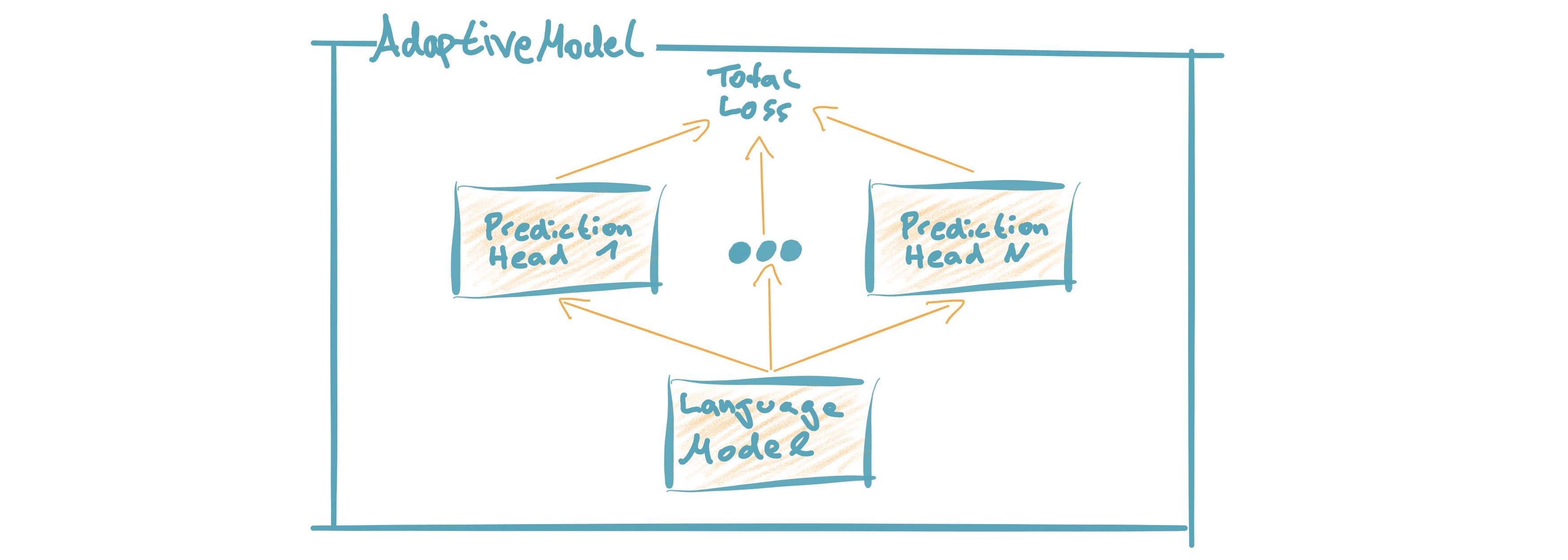
AdaptiveModel = Language Model + Prediction Head(s) With this modular approach you can easily add prediction heads (multitask learning) and re-use them for different types of language models. (Learn more)
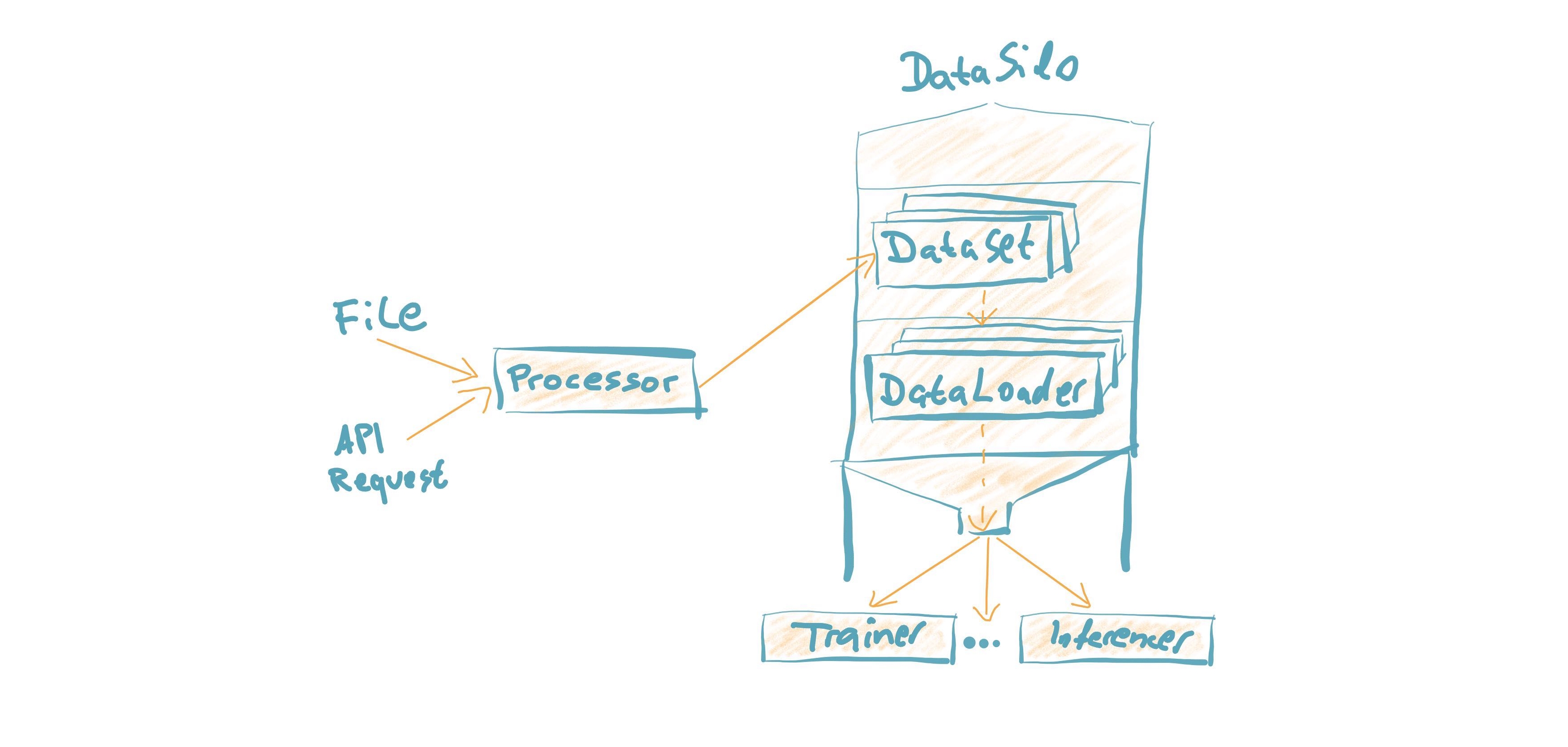
Custom Datasets can be loaded by customizing the Processor. It converts "raw data" into PyTorch Datasets. Much of the heavy lifting is then handled behind the scenes to make it fast & simple to debug. (Learn more)
FARM has a configurable test suite for benchmarking inference times with combinations of inference engine(PyTorch, ONNXRuntime), batch size, document length, maximum sequence length, and other parameters. Here is a benchmark for Question Answering inference with the current FARM version.
1. What language model shall I use for non-english NLP? If you’re working with German, French, Chinese, Japanese or Finnish you might be interested in trying out the pretrained BERT models in your language. You can see a list here of the available models hosted by our friends over at HuggingFace which can be directly accessed through FARM. If your language isn’t one of those (or even if it is), we’d encourage you to try out XLM-Roberta (https://arxiv.org/pdf/1911.02116.pdf) which supports 100 different languages and shows surprisingly strong performance compared to single language models.
2. Why do you have separate prediction heads? PredictionHeads are needed in order to adapt the general language understanding capabilities of the language model to a specific task. For example, the predictions of NER and document classification require very different output formats. Having separate PredictionHead classes means that it is a) very easy to re-use prediction heads on top of different language models and b) it simplifies multitask-learning. The latter allows you e.g. to add proxy tasks that facilitate learning of your "true objective". Example: You want to classify documents into classes and know that some document tags (e.g. author) already provide helpful information for this task. It might help to add additional tasks for classifying these meta tags.
3. When is adaptation of a language model to a domain corpus useful? Mostly when your domain language differs a lot to the one that the original model was trained on. Example: Your corpus is from the aerospace industry and contains a lot of engineering terminology. This is very different to Wikipedia text on in terms of vocab and semantics. We found that this can boost performance especially if your down-stream tasks are using rather small domain datasets. In contrast, if you have huge downstream datasets, the model can often adapt to the domain "on-the-fly" during downstream training.
4. How can I adapt a language model to a domain corpus?
There are two main methods: you can extend the vocabulary by Tokenizer.add_tokens(["term_a", "term_b"...]) or fine-tune your model on a domain text corpus (see example).
5. How can I convert from / to HuggingFace's models?
We support conversion in both directions (see example)
You can also load any language model from HuggingFace's model hub by just specifying the name, e.g. LanguageModel.load("deepset/bert-base-cased-squad2")
6. How can you scale Question Answering to larger collections of documents? It's currently most common to put a fast "retriever" in front of the QA model. Checkout haystack for such an implementation and more features you need to really run QA in production.
7. How can you tailor Question Answering to your own domain? We attained high performance by training a model first on public datasets (e.g. SQuAD, Natural Questions ...) and then fine-tuning it on a few custom QA labels from the domain. Even ~2000 domain labels can give you the essential performance boost you need. Checkout haystack for more details and a QA labeling tool.
8. My GPU runs out of memory. How can I train with decent batch sizes?
Use gradient accumulation! It combines multiple batches before applying backprop. In FARM, just set the param grad_acc_steps in initialize_optimizer() and Trainer() to the number of batches you want to combine (i.e. grad_acc_steps=2 and batch_size=16 results in an effective batch size of 32).
- FARM is built upon parts of the great Transformers repository from HuggingFace. It utilizes their implementations of models and tokenizers.
- FARM is a community effort! Essential pieces of it have been implemented by our FARMers out there. Thanks to all contributors!
- The original BERT model and paper was published by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
As of now there is no published paper on FARM. If you want to use or cite our framework, please include the link to this repository. If you are working with the German Bert model, you can link our blog post describing its training details and performance.