Introducing Magma Core
Having outlined an approach to achieving data model consistency by adopting a Top Level Data Model (TLDM) there is an obvious question that can now be tackled:
How can we implement a system that is based on this integrated data concept?
Magma Core is a research prototype and test-bed for several technologies and techniques to satisfy many of the requirements listed above. It could form the basis of a full system to satisfy all of the requirements, but at present it focusses on some of the more difficult technical problems.
The prototype:
- Is based on a data modelling framework called HQDM, from the book High Quality Data Modelling by Matthew West, which models real world objects and their relationships.
- Uses the inheritance structures of the data model framework to rigorously represent what is needed.
- Uses the Apache Jena framework and TDB triplestore for storing and querying data as RDF triples.
- Can be queried using the SPARQL query language as well as having built-in queries to allow the knowledge to be navigated.
Keeping track of what relevant information has been derived from which specific sources of information, is both hard to do and is not currently supported by any tools used within the information management community. It is becoming increasingly important to keep track of this, both to inform organisational activities and to allow the right policy management around the data, at the same time that the range and quantity of intelligence data is increasing beyond any team's ability to keep track of it. This is frequently called Knowledge Management, for which there is little expertise in the community (and possibly the world), but it also needs to fit into a wider picture of Information Management that is up to dealing with this mix of needs.
Other industries like public administration, systems engineering, systems analysis and research etc. have their own information management challenges driven by the same underlying data quality issues. If the information community is to use information in digital form to keep track of organisational ‘knowledge’ then there is scope to do far more with it than is currently achieved, ultimately including:
- Improving the analytic output of contributing teams throughout the information lifecycle by any authorised analyst and/or team member that needs the information.
- Records of what information material has, and could, contribute to the Operational Knowledge.
- Improved records to allow audit of who has had access to what (and what information was available to support organisational decisions)
In summary, Magma Core aims to demonstrate that it is possible to address these needs in a way that that enables the information management community to “Know what information has been obtained and used to derive the right information for the right people at the right time, so that they can make the right decisions with the confidence that it is sufficiently understood by those who need it.”
We needed some way to encode the model in a suitable data format. There aren't many suitable formats available but it does need to be one that is compatible with a database technology - it would defeat our purpose of making a data-driven system if we couldn't store the data somewhere suitable! After some consideration we chose Linked Data based on the current RDF, RDFS and OWL2 specifications. Pease ask the authors for more information on why the decision was made to use Linked Data and what role the specifications played as the pros and cons of the decision are something that are worth learning from.
By choosing Linked Data the first challenge was to have a version of Dr. West's TLDM in the Web Ontology Language. As the name suggests it is aimed at "Ontology" construction but what it provides is 'just' a notation framework based on Description Logic. However, there are many 'flavours' of Description Logic and it is possible to construct any number of "ontologies" with them. In addition, we had a data model that is available in a book and, fortunately, electronically as an EXPRESS data model file... but not in OWL2. The small team decided to learn the hard way and manually transcribed the High Quality Data Model from hqdm.exp (EXPRESS) to hqdm.owl (OWL2 DL).
Lesson in Data Quality: Manual model transcription, while tedious, was a great way to learn OWL in detail... but not great for absolute adherence to the original model. We discovered a few translation issues once we had started to use it!
Having a representation in OWL2 DL was a minor feat but it turned out to be unsatisfactory for composing software because Description Logic only permits some of the necessary context to be encoded and tools based on the Linked Data standards aren't intended for the strict model compliance that the team were after. After all, the Semantic Web came about to help people to make logical statements about anything so that a machine could accept them (roughly speaking within a defined domain of interest). Consistency between domains was not a major consideration for the Semantic `web standards. The consequence is that the standards allow anyone to say pretty much anything using simple predicate "logic" statements and this, unsurprisingly, leads to datasets that are missing a lot of the information required for unambiguous interpretation (the very goal that we set at the start). It also makes it very difficult to populate a data model fully as OWL doesn't easily support the specification of model patterns (for example, where more than one data object is required to represent something). These issues are not really anything to do with the RDF, RDFS and OWL specifications, but how they are used, the software available to support the use of them and the requirements that the Magma Core team faced.
Having a means to represent our model in data doesn't mean that we can actually use it. As we were trying something new it was clear that that handling a complex model that was intended to be dynamically extensible placed some unusual demands on the implementation architecture of our prototype. While there are some potentially useful things that can be done with data that is expressed using the Resource Description Framework and complies with an OWL ontology, such as reasoning, this doesn't really help us to find, in the data, the sorts of things that the software would need to be able to faithfully query and create data objects that were compliant with the TLDM. Reasoning can also be expensive both computationally and in memory. It can also give misleading results unless the reasoner and the model have been through a high degree of assurance and finding the source of a reasoning error/contradiction can be notoriously difficult.
What we primarily needed was a software 'framework' that matched the TLDM model 'framework' strictly. It was decided that something that would allow the developers to faithfully handle the data would be an object model that matched the entities in the TLDM, including the relationships and (multiple) inheritance that the TLDM specified. This would ensure that data objects in the software applications using the data model could create, and populate from data-base queries, the exact records required of each type of object. If this couldn't be done, for whatever reason (e.g. incomplete data on disk or coding errors) then an exception could be raised and addressed. However, the goal was to exploit this feature so that there were no incomplete datasets or coding errors (at least coding errors that related to the adherence to the TLDM!). The data on disk was taken as the authoritative records, given its persistence, and so care was taken with multiple users of the system to ensure that updates were done in a reliable way (approximating to desirable Atomicity, Consistency, Isolation and Durability - ACID principles).
Before introducing a diagram of the way the data is represented some care needs to be taken when looking at implementation details and differences between the use of common terms to programming, description logic, set theory, TLO and other communities. An example of this is the use of the term "class". Each of these communities have accepted and powerful ways of using the term "class". Within each particular domain these uses can become established, but they certainly aren't equivalent even if they seem similar.
We will proceed with due caution and keep in mind the goal to achieve consistent treatment of all the concepts that we draw upon despite this terminological minefield. See A terminological minefield for a illustration of how established terms can clash if taken in different contexts.
Before introducing the data model itself it is worth putting our intended use of data into context. The figure below indicates a number of extents of consistency that we are trying to achieve. In the widest sense we are trying to ensure that the things that are (or could be) of interest in the 'real' world are faithfully represented in data to serve some organisational purpose. The obvious challenge with this is there isn't a direct 'connection' between what is of interest in the 'real' world and the data that is intended to represent it. Based on the introduction to Magma Core we have set the goal to be able to consistently represent anything that is, or could be, in the 'real' world including possibilities in the past, present and future. This is a vast coverage (in concept, at least) but the things we really want to represent through the use of data will be a small subset af all the things we could attempt to. We can call those things our Total Realm of Interest. Before committing to the creation of data there needs to be a method available to allow the translation of what is of interest to a consistent (and faithful) representation in data. This method is analysis. The use of a TLO (and sufficient understanding of the commitments in it) provides an analytic framework that can be applied consistently by independent parties. Dr West's book states that the analytic goal is to ensure that, if carefully applied, the results will be recognisably similar from independent teams. This can be called the Analytic Realm.
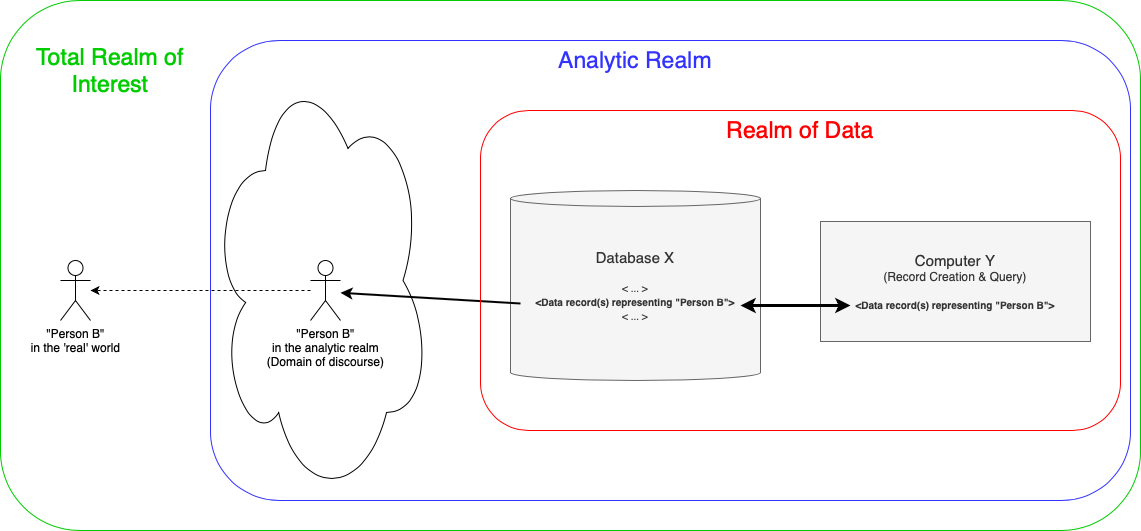
After analysis of the requirement to hold data about something of interest, in this case the representation of "Person B" (possibly an Employee/Supplier/Friend/...), can be translated to a suitable form for storage in a database and subsequent computational work. We have finally reached the Realm of Data but it should be noted that the aim is to be sufficiently consistent across all these Realms. This initial analysis has allowed us to create records in the Realm of Data that includes both stored data and data that is used in computational tasks - for example, to conduct automated tasks or to enable further analysis. The end result should be information operations that are consistent, at the required quality and that the data can be used in any suitable application without the need to re-model the data (of course, it may need to be mapped to a different binary format but that becomes trivial if there is an unambiguous way of representing what is needed).
It is worth considering at this point why the need for consistency spans these realms and where the greatest challenges are. It can be argued that, while the technical activities within the realm of data are where interest in data lies and are complex in themselves, the benefits resulting from the use of these techniques are intended to be real and that the greatest challenges in the use of any data to inform our organisational decisions is in the analytic realm, to support activity that involves decisions* relating to the 'real' things that are represented by the data.
The next page introduces the structure of the TLDM and the approach that was taken to achieve consistency in both database(s) and during processing by computers.
Next: Top Level Data Structure
* As Dr West introduces in his book, the primary role of information (as data) in organisations is to support decisions. The quality of the data has a bearing on the quality of the decisions it supports.