Welcome to the Arctic Frenz Data Repository - a specialized resource aimed at enriching Frenz with in-depth NFT analytics. Our repository provides comprehensive data on factors such as the duration of asset ownership, the quantity of ownership, and the rarity of NFTs. It is open-sourced to ensure complete transparency, enabling community owners, managers, and members to easily access enhanced metadata at no cost. Furthermore, this repository enables collections to use these insights to foster and strengthen community engagement.
Refer to the instructional README, or interact with the data by directly messaging the bot at: https://bot.arcticfrenz.com.

|
|
|
- Part 1: Retrieve NFT Metadata
- Part 2: Calculating Rarity Scores
- Part 3: Enhancing the Metadata
- Part 4: Data Processing Pipeline
- Part 5: Pretty-Printing
- Part 6: Ranking Holders
- Part 7: Data Visualization
| 1. Visit Magic Eden and select an NFT from the collection you are interested in. |
2. Navigate to the NFT's detail page and locate its Mint Address, then proceed to Solscan
CLICK TO EXPAND Screenshot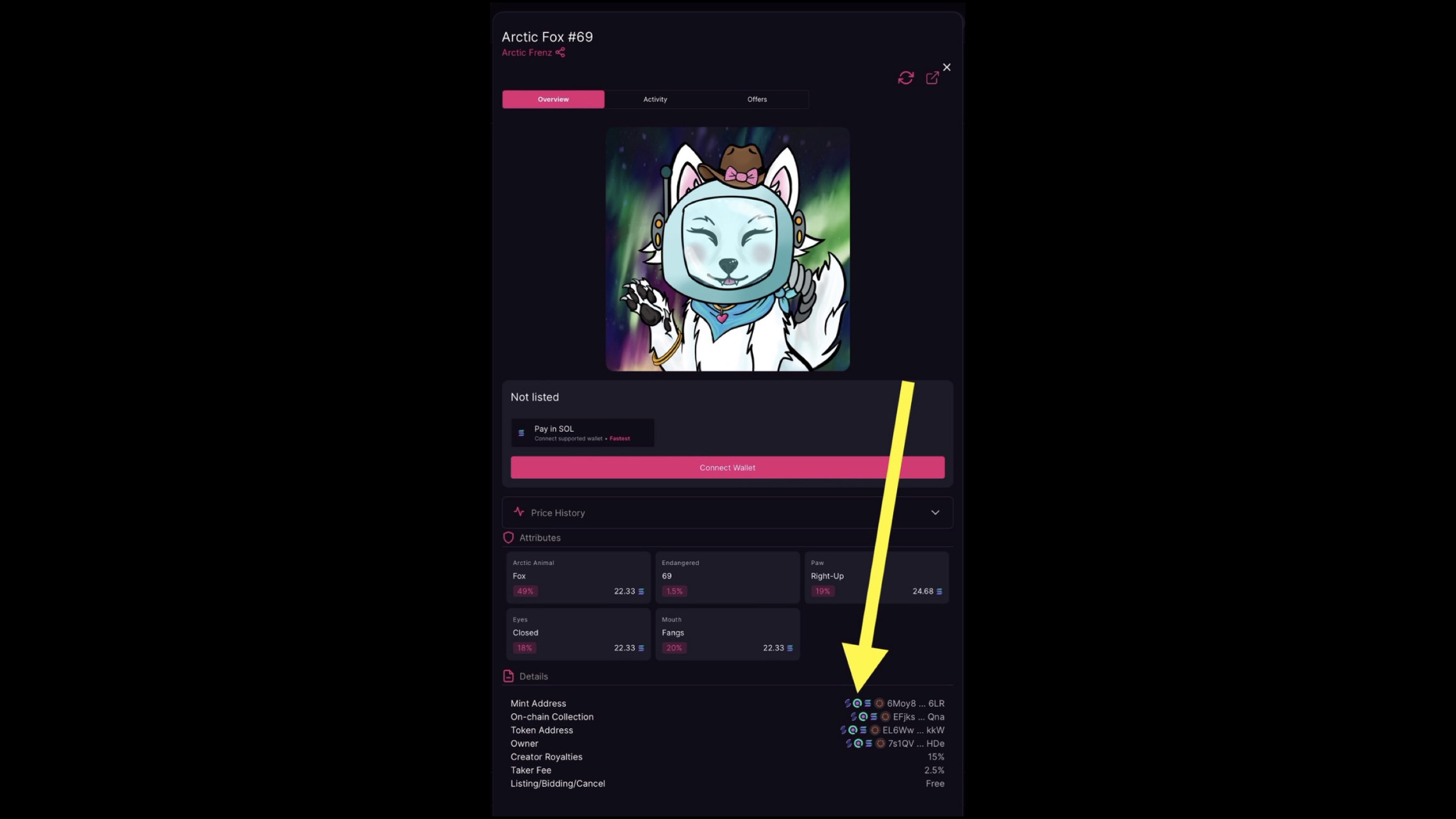
|
3. In Solscan, click on the "Creators" tab. Look for the first listed address that shows a 0% share and is marked with a blue tick.
CLICK TO EXPAND Screenshot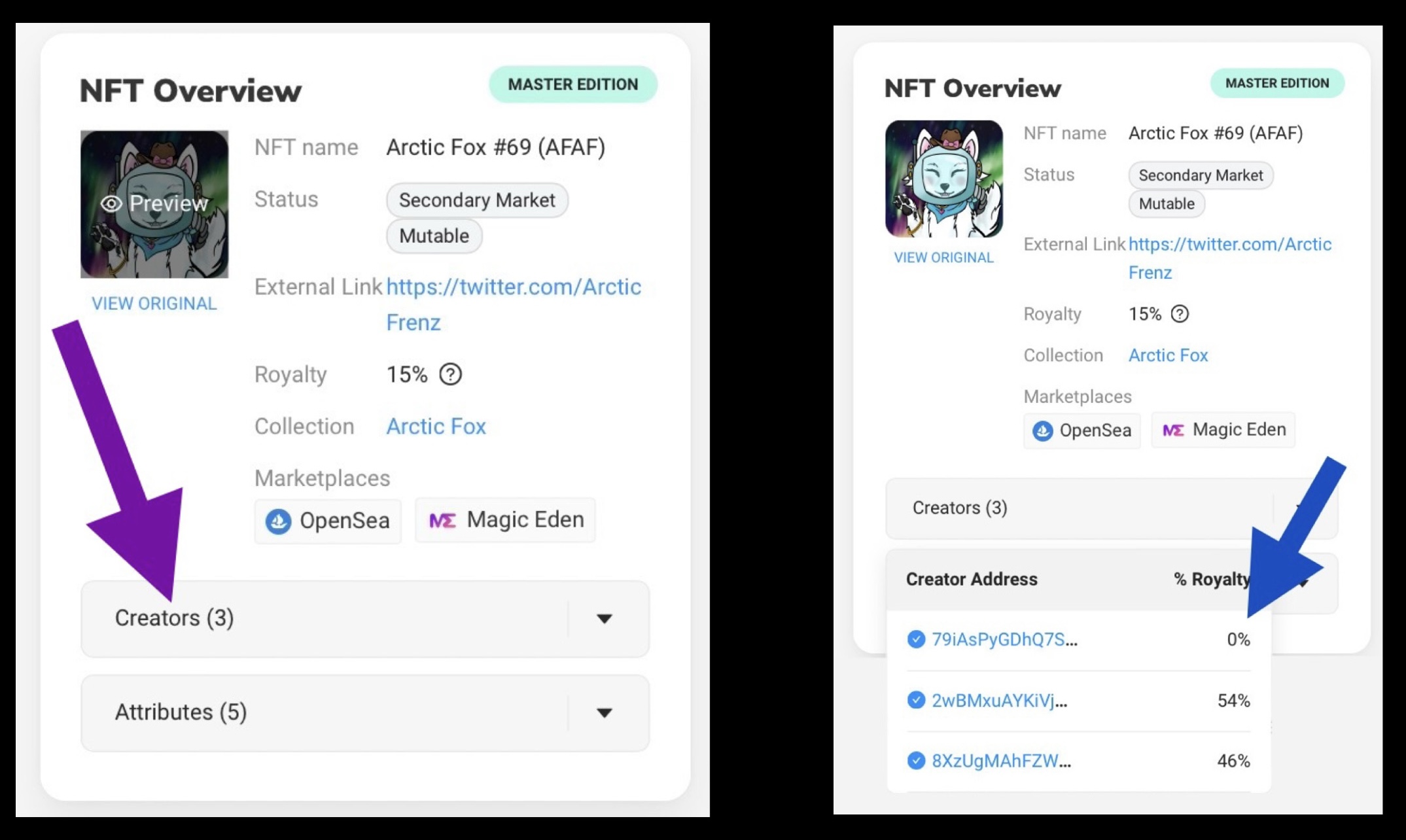
|
4. Copy this Creator Address.
CLICK TO EXPAND Screenshot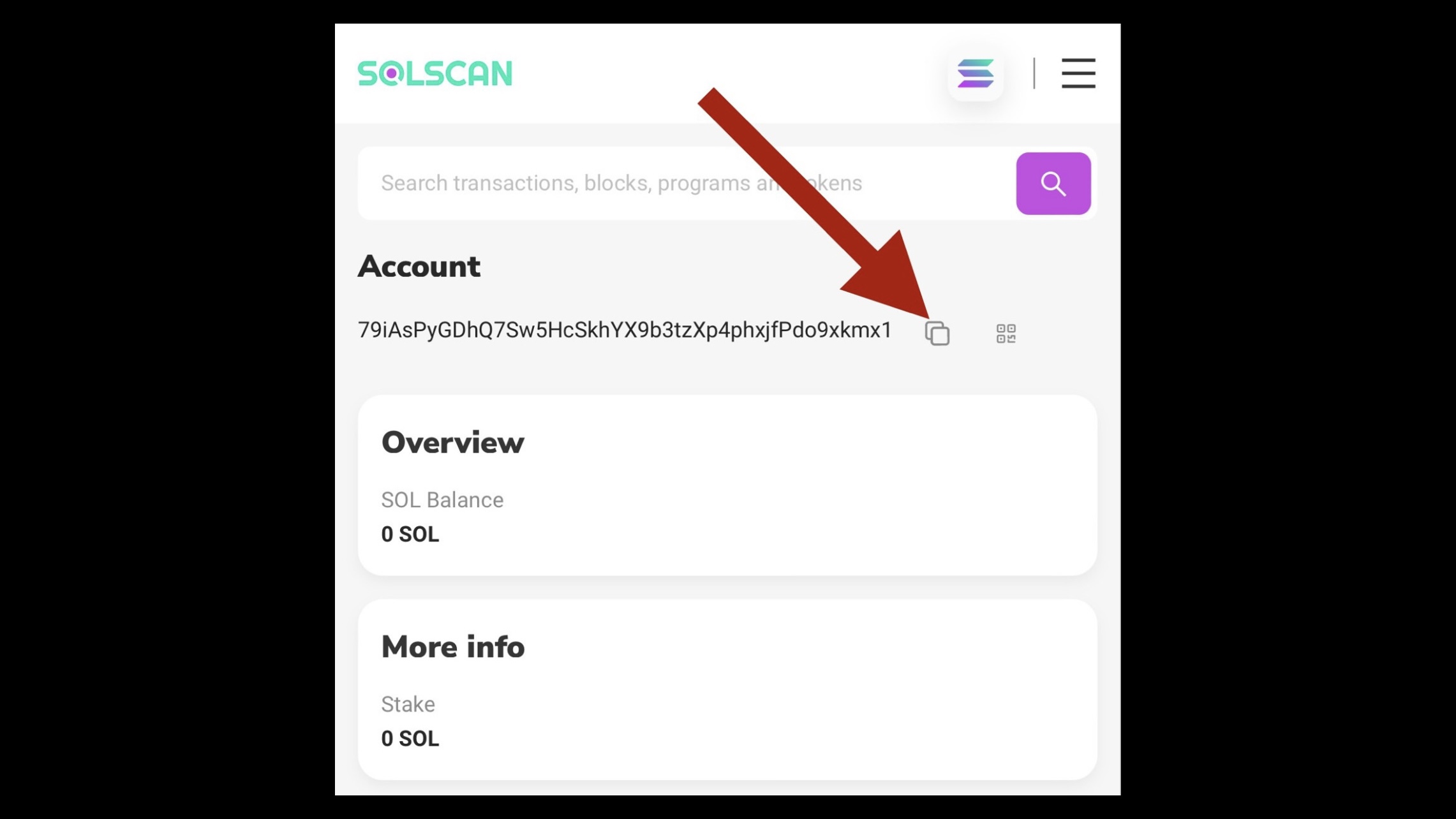
|
- Visit Smithii or Magic Eden's Hash List Finder, tools for retrieving a Hash List on the Solana blockchain.
- Paste the Creator Address obtained from Step 1 into the provided field.
- Click 'Get hash list' to generate the list.
- Please be patient, as generating the hash list may take a few minutes.
- Once the list is available, copy or save the list for Part 1, Step 4.
Choose one of the following environments for your Python development needs:
- Google Colab: Utilize Google Colab for a cloud-based Jupyter notebook experience that does not require any local setup.
- JupyterLab: For a more advanced setup, JupyterLab provides a comprehensive development environment to work with notebooks, code, and data.
- Local Environment: Set up your development environment locally on various operating systems:
Open your development environment and create a variable named nft_addresses for a Python list. Paste your hash list from Part 1, Step 2 into the Python list.
nft_addresses = [
# PASTE HASH LIST HERE
]| 1. Visit Helius, a platform for Solana RPC nodes, APIs, webhooks, and infrastructure. |
| 2. Sign-in to Helius |
3. Copy your free API key for Step 6.
CLICK TO EXPAND Screenshot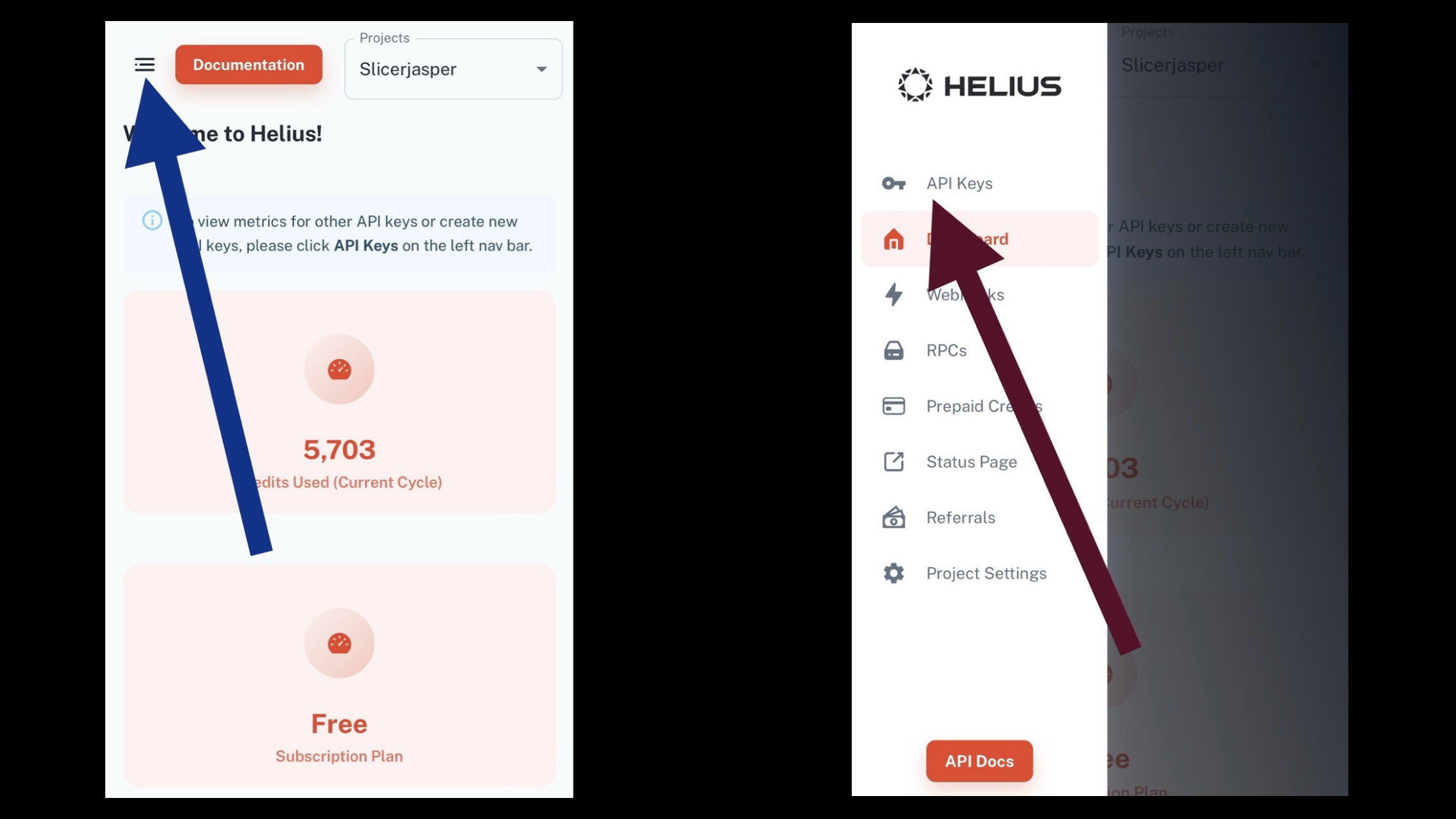
|
Open your development environment, create a variable named apikey. Paste your API Key from Part 1, Step 5 into the variable
apikey = "INSERT YOUR API KEY BETWEEN THESE QUOTATION MARKS"Below is the complete code. Execute it to generate a file named 'nft_metadata.json' that will include the metadata each NFT in the collection.
CLICK TO EXPAND Python Script
import requests
import json
nft_addresses = [
# PASTE HASH LIST HERE
]
apikey = "INSERT YOUR API KEY BETWEEN THESE QUOTATION MARKS"
url = f"https://api.helius.xyz/v0/token-metadata?api-key={apikey}"
def get_metadata(nft_addresses):
batch_size = 80
all_data = []
for i in range(0, len(nft_addresses), batch_size):
batch_addresses = nft_addresses[i:i + batch_size]
payload = {
"mintAccounts": batch_addresses,
"includeOffChain": True,
"disableCache": False
}
headers = {
'Content-Type': 'application/json',
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
batch_data = response.json()
all_data.extend(batch_data)
print(f"Batch {i // batch_size + 1} successfully retrieved.")
else:
print(f"Failed to retrieve metadata for batch {i // batch_size + 1}: {response.status_code}")
print("Error message:", response.text)
with open('nft_metadata.json', 'w') as file:
json.dump(all_data, file, indent=4)
print("All metadata written to nft_metadata.json")
get_metadata(nft_addresses)The example JSON below is truncated for illustrative purposes; the 'nft_metadata' output file will encompass all NFTs in the collection.
CLICK TO EXPAND JSON Example
[
{
"account": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"onChainAccountInfo": {
"accountInfo": {
"key": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"isSigner": false,
"isWritable": false,
"lamports": 1461600,
"data": {
"parsed": {
"info": {
"decimals": 0,
"freezeAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"isInitialized": true,
"mintAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"supply": "1"
},
"type": "mint"
},
"program": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"space": 82
},
"owner": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"executable": false,
"rentEpoch": 361
},
"error": ""
},
"onChainMetadata": {
"metadata": {
"tokenStandard": "NonFungible",
"key": "MetadataV1",
"updateAuthority": "6DMG9hv3eR8BXKH79sXGyQtfRSxXfNrkHEdc6nCsEjVK",
"mint": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"data": {
"name": "Arctic Fox #41",
"symbol": "AFAF",
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"sellerFeeBasisPoints": 1500,
"creators": [
{
"address": "79iAsPyGDhQ7Sw5HcSkhYX9b3tzXp4phxjfPdo9xkmx1",
"verified": true,
"share": 0
},
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"verified": true,
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"verified": true,
"share": 46
}
]
},
"primarySaleHappened": true,
"isMutable": true,
"editionNonce": 255,
"uses": {
"useMethod": "",
"remaining": 0,
"total": 0
},
"collection": {
"key": "EFjksSb2b897hvxuHXrnVoE2y66iufiJxtDSgFJZYQna",
"verified": true
},
"collectionDetails": null
},
"error": ""
},
"offChainMetadata": {
"metadata": {
"attributes": [
{
"traitType": "Arctic Animal",
"value": "Fox"
},
{
"traitType": "Endangered",
"value": "No"
},
{
"traitType": "Paw",
"value": "Left-Up"
},
{
"traitType": "Eyes",
"value": "Heterochromia"
},
{
"traitType": "Mouth",
"value": "Blep"
}
],
"description": "An exclusive family, 69 #SolanaNFTs per collection. Liquidity adding for rewarding #ArcticFrenz.",
"image": "https://arweave.net/p5C032iu3UQ4Lpr5cTNlcW8bVDrcVd872QChc3z8J-4?ext=png",
"name": "Arctic Fox #41",
"properties": {
"category": null,
"creators": [
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"share": 46
}
],
"files": [
{
"type": "image/png",
"uri": "40.png"
}
]
},
"sellerFeeBasisPoints": 1500,
"symbol": "AFAF"
},
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"error": ""
},
"legacyMetadata": null
},
{
"_comment": "The file has been truncated for this example; the output JSON file nft_metadata will contain all NFTs in the collection",
}
]The concept of rarity, in the context of NFTs, relates to the uniqueness and scarcity of specific traits within a collection. Rarity scores play a crucial role in shaping the perceived value and desirability of individual NFTs. This section details two distinct methods for calculating these scores:
- Process A: Calculation of rarity scores using off-chain metadata associated with each NFT.
- Process B: Utilization of rarity rankings provided by HowRare.is for the collection.
Steps to Calculate Rarity Scores
-
List Traits: Enumerate all distinct traits and their possible values from the
offChainMetadatawithin the NFT dataset. -
Count Traits: Tally the frequency of each trait value across the collection to determine how common or rare each trait is.
-
Calculate Rarity Scores: Assign a rarity score to each NFT by summing the inverse frequencies of its trait values. This score quantifies the rarity, with higher scores indicating rarer traits.
Rarity Score Implications
A lower frequency of a trait value indicates rarity, and hence, it contributes more significantly to the rarity score. The scoring system is designed such that the sum of the inverses of the trait frequencies for an NFT's traits yields its total rarity score. The end result is a comprehensive dataset where each NFT entry is supplemented with a rarity_score field, reflecting its uniqueness within the collection.
Mathematical Formulation
The rarity score is calculated by summing the inverse frequencies of all the trait values for the NFT. This means that rarer traits will contribute more significantly to the rarity score than more common traits.
CLICK TO EXPAND Math
The rarity score for an NFT can be mathematically expressed as:
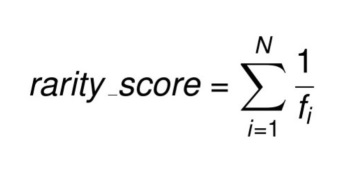
|
where:
rarity_scoreis the rarity score of the NFTNis the total number of traits for the NFTfᵢis the frequency of theith trait value for the NFT
Handling Missing or Undefined Attributes
In rarity score calculations, NFTs with missing or undefined attributes are assigned a default score of 0. This ensures each NFT has a defined rarity score for the JSON file, maintaining dataset consistency and enabling meaningful NFT comparisons. This method also avoids potential data processing and analysis errors caused by undefined or missing values.
Rarity Script
CLICK TO EXPAND Python Script
import json
import pandas as pd
def calculate_rarity_score(attributes, trait_counts_df):
score = sum(1 / trait_counts_df[(trait_counts_df['trait_type'] == attr['trait_type']) &
(trait_counts_df['value'] == attr['value'])]['count'].values[0]
for attr in attributes if len(trait_counts_df[(trait_counts_df['trait_type'] == attr['trait_type']) &
(trait_counts_df['value'] == attr['value'])]) > 0)
return score
file_path = 'nft_metadata.json'
with open(file_path, 'r') as file:
nft_metadata = json.load(file)
nft_df = pd.json_normalize(nft_metadata)
attributes_list = nft_df.dropna(subset=['offChainMetadata.metadata.attributes'])['offChainMetadata.metadata.attributes'].tolist()
attributes_flat_list = [attr for sublist in attributes_list for attr in sublist]
attributes_df = pd.DataFrame(attributes_flat_list)
trait_counts = attributes_df.groupby(['trait_type', 'value']).size().reset_index(name='count')
nft_df['rarity_score'] = nft_df['offChainMetadata.metadata.attributes'].apply(
lambda attrs: calculate_rarity_score(attrs, trait_counts) if isinstance(attrs, list) else None
)
for i, record in enumerate(nft_metadata):
rarity_score = nft_df.loc[i, 'rarity_score']
record['rarity_score'] = rarity_score if pd.notnull(rarity_score) else 0
updated_file_path = 'nft_metadata_with_rarity.json'
with open(updated_file_path, 'w') as file:
json.dump(nft_metadata, file, indent=4)
print(f"Awesome! The updated JSON file with rarity scores is saved to {updated_file_path}.")Example Output
The output is an updated JSON file, nft_metadata_with_rarity.json, where each NFT entry now includes a rarity_score. Below is a truncated example of what an NFT entry might look like with an appended rarity score:
CLICK TO EXPAND JSON Example
[
{
"account": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"onChainAccountInfo": {
"accountInfo": {
"key": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"isSigner": false,
"isWritable": false,
"lamports": 1461600,
"data": {
"parsed": {
"info": {
"decimals": 0,
"freezeAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"isInitialized": true,
"mintAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"supply": "1"
},
"type": "mint"
},
"program": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"space": 82
},
"owner": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"executable": false,
"rentEpoch": 361
},
"error": ""
},
"onChainMetadata": {
"metadata": {
"tokenStandard": "NonFungible",
"key": "MetadataV1",
"updateAuthority": "6DMG9hv3eR8BXKH79sXGyQtfRSxXfNrkHEdc6nCsEjVK",
"mint": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"data": {
"name": "Arctic Fox #41",
"symbol": "AFAF",
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"sellerFeeBasisPoints": 1500,
"creators": [
{
"address": "79iAsPyGDhQ7Sw5HcSkhYX9b3tzXp4phxjfPdo9xkmx1",
"verified": true,
"share": 0
},
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"verified": true,
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"verified": true,
"share": 46
}
]
},
"primarySaleHappened": true,
"isMutable": true,
"editionNonce": 255,
"uses": {
"useMethod": "",
"remaining": 0,
"total": 0
},
"collection": {
"key": "EFjksSb2b897hvxuHXrnVoE2y66iufiJxtDSgFJZYQna",
"verified": true
},
"collectionDetails": null
},
"error": ""
},
"offChainMetadata": {
"metadata": {
"attributes": [
{
"traitType": "Arctic Animal",
"value": "Fox"
},
{
"traitType": "Endangered",
"value": "No"
},
{
"traitType": "Paw",
"value": "Left-Up"
},
{
"traitType": "Eyes",
"value": "Heterochromia"
},
{
"traitType": "Mouth",
"value": "Blep"
}
],
"description": "An exclusive family, 69 #SolanaNFTs per collection. Liquidity adding for rewarding #ArcticFrenz.",
"image": "https://arweave.net/p5C032iu3UQ4Lpr5cTNlcW8bVDrcVd872QChc3z8J-4?ext=png",
"name": "Arctic Fox #41",
"properties": {
"category": null,
"creators": [
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"share": 46
}
],
"files": [
{
"type": "image/png",
"uri": "40.png"
}
]
},
"sellerFeeBasisPoints": 1500,
"symbol": "AFAF"
},
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"error": ""
},
"legacyMetadata": null,
"rarity_score": 0.1473389390210555
},
{
"_comment": "The file has been truncated for this example; the output JSON file nft_metadata_with_rarity will contain all NFTs in the collection with their rarity_score",
}
]
HowRare.is does not offer rarity rankings for all NFT collections. The following steps are intended for collections listed on HowRare.is. For those not listed, please use Process A.
- Navigate to the desired collection on HowRare.is.
- Select "Download ranking".
- Save the file as 'howrare.json'.
- Execute the script provided below.
CLICK TO EXPAND Python Script
import json
file_path_nft_metadata = 'nft_metadata.json'
file_path_howrare = 'howrare.json'
with open(file_path_nft_metadata, 'r') as file:
nft_metadata = json.load(file)
with open(file_path_howrare, 'r') as file:
howrare_data = json.load(file)['result']['data']['items']
howrare_dict = {item['mint']: item for item in howrare_data}
accounts_without_rarity = []
max_rank = max(item.get('rank', 0) for item in howrare_data)
for item in nft_metadata:
account = item.get('account')
if account in howrare_dict:
normalized_rank = 1 - (howrare_dict[account].get('rank') / max_rank)
item['rarity_score'] = max(normalized_rank, 0.001)
else:
accounts_without_rarity.append(account)
new_file = 'with-HowRare.json'
with open(new_file, 'w') as file:
json.dump(nft_metadata, file, indent=4)
if not accounts_without_rarity:
print("Success, all items received a HowRare value")
else:
print("The following accounts did not receive a HowRare value:")
for account in accounts_without_rarity:
print(account)Refer to Part 1, Step 3 for the setup instructions.
This script utilizes Selenium WebDriver to automate web browser interactions and gather additional metadata about NFTs. It targets a website to extract data about NFT holders and associated timestamps. This information is then incorporated into a JSON file.
The Python script provided is formatted for use in a Google Colab environment, allowing for manual testing and inspection of the script.
CLICK TO EXPAND Python Script
!apt update
!apt install chromium-chromedriver
!pip install selenium
!wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb && apt install ./google-chrome-stable_current_amd64.deb!Service('/usr/bin/chromedriver')import json
import random
import time
import logging
import sys
import os
from datetime import datetime
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, ElementClickInterceptedException
from selenium.webdriver.common.action_chains import ActionChains
import psutil
LOG_FILE = 'logfile.log'
FILE_ADDRESS = 'address.html'
FILE_TIME = 'time.html'
def setup_logger(log_file_path, logger_name='MyAppLogger'):
logger = logging.getLogger(logger_name)
logger.handlers = []
logger.setLevel(logging.INFO)
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler(log_file_path)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(logging.INFO)
stream_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(stream_handler)
return logger
def kill_chrome_and_chromedriver(logger):
for proc in psutil.process_iter():
if 'chrome' in proc.name().lower() or 'chromedriver' in proc.name().lower():
try:
proc.kill()
except (psutil.NoSuchProcess, psutil.AccessDenied, psutil.ZombieProcess):
pass
def driversetup(logger):
options = webdriver.ChromeOptions()
options.add_argument("user-data-dir=selenium")
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--disable-gpu")
options.add_argument("--remote-debugging-port=9222")
options.add_argument("lang=en-US")
options.add_argument("location=US")
options.add_argument(f"--window-size={1920},{1080}")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
options.add_argument("--incognito")
options.add_argument("--disable-blink-features=AutomationControlled")
options.page_load_strategy = 'normal'
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
]
selected_user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={selected_user_agent}")
caps = webdriver.DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'browser': 'ALL'}
service = webdriver.chrome.service.Service('/usr/bin/chromedriver')
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Network.clearBrowserCookies", {})
driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": {"Referer": "https://www.google.com/"}})
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined});")
return driver
def random_sleep(min_seconds, max_seconds):
time.sleep(random.uniform(min_seconds, max_seconds))
def simulate_human_interaction(driver, logger):
action = ActionChains(driver)
body_element = driver.find_element(By.TAG_NAME, 'body')
for _ in range(random.randint(1, 3)):
action.send_keys_to_element(body_element, Keys.PAGE_DOWN).perform()
random_sleep(0.5, 1.0)
action.send_keys_to_element(body_element, Keys.PAGE_UP).perform()
random_sleep(0.5, 1.0)
action.move_to_element(body_element).perform()
random_sleep(0.5, 1.0)
action.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
random_sleep(0.5, 1.0)
def extract_owner_address_from_file(file_path, logger):
try:
with open(FILE_ADDRESS, 'r') as file:
html_content = file.read()
soup = BeautifulSoup(html_content, 'html.parser')
tables = soup.find_all("table")
for table in tables:
if table.find("th", {"title": "Owner"}):
visible_rows = table.select("tbody tr:not(.ant-table-measure-row)")
if visible_rows:
owner_address_element = visible_rows[0].select_one("td:nth-of-type(2) a")
if owner_address_element:
address = owner_address_element.text.strip()
logger.info(f"Owner address found: {address}")
return address
else:
logger.info("Owner address not found in the table.")
return "Address not found"
else:
logger.info("No visible rows found in the owner table.")
return "No rows in table"
except Exception as e:
logger.info(f"Error while extracting owner address: {e}")
return f"Error: {e}"
def extract_time_from_file(file_path, logger):
try:
with open(file_path, 'r') as file:
html_content = file.read()
logger.info(f"Successfully read HTML content from '{file_path}'.")
soup = BeautifulSoup(html_content, 'html.parser')
time_column_index = 4
table = soup.select_one("#rc-tabs-0-panel-txs table")
if not table:
logger.info("The specific table with ID 'rc-tabs-0-panel-txs' was not found.")
return "Table not found"
time_cell = table.select_one("tbody tr:nth-of-type(2) td:nth-of-type(4)")
if not time_cell:
logger.info("Time cell not found in the specified row and column.")
return "Time cell not found"
hold_time = time_cell.text.strip()
logger.info(f"Time successfully extracted: {hold_time}")
return hold_time
except Exception as e:
logger.info(f"An unexpected error occurred while extracting time from '{file_path}': {e}")
return f"Error: {e}"
def getholderaddress(url_holder, driver, logger):
try:
driver.get(url_holder)
wait = WebDriverWait(driver, timeout=30)
root = driver.find_element(By.ID, 'root')
body = driver.find_element(By.TAG_NAME, 'body')
wait.until(lambda d: driver.execute_script('return document.readyState') == 'complete')
wait.until(lambda d: root.is_displayed())
wait.until(lambda d: body.is_displayed())
random_sleep(7, 8)
simulate_human_interaction(driver, logger)
root_html = driver.find_element(By.ID, 'root').get_attribute('outerHTML')
with open(FILE_ADDRESS, 'w') as file:
file.write(root_html)
solana_address = extract_owner_address_from_file(FILE_ADDRESS, logger)
logger.info(f"Holder Address: {solana_address}")
except TimeoutException:
logger.error("Timed out waiting for page to load")
solana_address = "Error: Page did not load properly"
except Exception as e:
logger.error(f"An error occurred: {e}")
solana_address = "Error: Unexpected issue occurred"
return solana_address
def get_hold_time(url_time, driver, logger):
try:
driver.get(url_time)
wait = WebDriverWait(driver, timeout=30)
root = driver.find_element(By.ID, 'root')
body = driver.find_element(By.TAG_NAME, 'body')
wait.until(lambda d: driver.execute_script('return document.readyState') == 'complete')
wait.until(lambda d: root.is_displayed())
wait.until(lambda d: body.is_displayed())
random_sleep(8, 9)
simulate_human_interaction(driver, logger)
javascript = """
const clickAndCheck = async () => {
const clockIconElement = document.querySelector(".ant-space.ant-space-vertical.sc-cwSeag.jTZqgO > div > div > div > div > div > div > div > table > thead > tr > th:nth-child(4) > span");
if (!clockIconElement) {
console.warn('Unable to find clock icon element');
return;
}
let retries = 5;
while (clockIconElement.querySelector('svg') && retries > 0) {
await clockIconElement.click();
console.log('Clicking clock icon, remaining retries:', retries);
retries--;
await new Promise(resolve => setTimeout(resolve, 1000));
}
if (retries === 0) {
console.warn('Max retries reached for clock icon click');
} else {
console.log('Clicking successful - clock icon disappeared');
}
};
clickAndCheck();
"""
try:
driver.execute_script(javascript)
except Exception as e:
logger.error(f"An error occurred: {e}")
time.sleep(2)
body_html = driver.find_element(By.TAG_NAME, 'body').get_attribute('outerHTML')
with open(FILE_TIME, 'w') as file:
file.write(body_html)
hold_time = extract_time_from_file(FILE_TIME, logger)
logger.info(f"Hold time extracted: {hold_time}")
except TimeoutException as e:
logger.info(f"TimeoutException encountered: {e}. The website might be unresponsive or the element locators might be incorrect.")
hold_time = "Error: Timed out"
except Exception as e:
logger.info(f"Unexpected error encountered: {e}. Review the stack trace for details and check the website's structure.")
hold_time = "Error: Unexpected issue occurred"
finally:
logger.info("Closing the web driver...")
driver.close()
logger.info("Web driver closed for time.")
return hold_time
def process_item(item, driver, logger):
account = item.get('account')
if not account:
logger.info("Account information not found in the item.")
return
time.sleep(1)
url_holder = f"https://solscan.io/token/{account}#holders"
logger.info(f"https://solscan.io/token/{account}#holders")
time.sleep(1)
url_time = f"https://solscan.io/token/{account}#txs"
logger.info(f"https://solscan.io/token/{account}#txs")
time.sleep(1)
try:
solana_address = getholderaddress(url_holder, driver, logger)
hold_time = get_hold_time(url_time, driver, logger)
update_json_data(item, solana_address, hold_time, logger)
logger.info(f"Successfully processed account {account}.")
except Exception as e:
logger.error(f"Error processing {account}: {e}")
def update_json_data(item, solana_address, hold_time_str, logger):
hold_time_format = "%m-%d-%Y %H:%M:%S"
hold_time = datetime.strptime(hold_time_str, hold_time_format)
current_time = datetime.now()
hold_time_unix = int(hold_time.timestamp())
current_time_unix = int(current_time.timestamp())
item['holder data'] = [
{"holder": solana_address},
{"when acquired": hold_time_unix},
{"time checked": current_time_unix}
]
def find_start_index(nft_metadata, processed_indices, logger):
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' not in item:
logger.info(f"Starting from index {index}: No 'holder data' field found.")
return index
logger.info("All items have 'holder data'. Moving to the next priority.")
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
holder = item['holder data'][0]['holder']
if holder is None:
logger.info(f"Starting from index {index}: Found invalid 'holder' value.")
return index
if len(holder) not in range(32, 45) and holder != "Magic Eden V2 Authority":
logger.info(f"Starting from index {index}: Found invalid 'holder' value.")
return index
logger.info("All items have valid 'holder' values. Moving to the next priority.")
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
when_acquired = item['holder data'][1]['when acquired']
if not isinstance(when_acquired, int):
logger.info(f"Starting from index {index}: 'when acquired' is not a Unix epoch timestamp.")
return index
logger.info("All items have valid 'when acquired' timestamps. Moving to the next priority.")
oldest_index = None
oldest_time = float('inf')
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
time_checked = item['holder data'][2]['time checked']
if time_checked < oldest_time:
oldest_time = time_checked
oldest_index = index
if oldest_index is not None:
logger.info(f"Starting from index {oldest_index}: It has the oldest 'time checked'.")
return oldest_index
else:
logger.info("No items to prioritize based on 'time checked'.")
return len(nft_metadata)
def get_next_item_index(nft_metadata, logger):
return find_start_index(nft_metadata, logger)
def main():
logger = setup_logger(LOG_FILE)
logger.info("Starting new run. Appending to the existing logfile.")
kill_chrome_and_chromedriver(logger)
processed_data_file = 'nft_metadata_with_rarity_and_holder_data.json'
if os.path.exists(processed_data_file):
try:
with open(processed_data_file, 'r') as file:
nft_metadata = json.load(file)
logger.info("Continuing from previously saved progress.")
except Exception as e:
logger.error(f"Error loading processed data: {e}")
return
else:
try:
with open('nft_metadata_with_rarity.json', 'r') as file:
nft_metadata = json.load(file)
logger.info("Starting from the beginning as no progress file found.")
except Exception as e:
logger.error(f"Error loading initial data: {e}")
return
processed_count = 0
processed_indices = set()
while processed_count < 100:
next_index = find_start_index(nft_metadata, processed_indices, logger)
if next_index >= len(nft_metadata):
logger.info("All items have been processed or no more items to prioritize.")
break
item = nft_metadata[next_index]
logger.info(f"Processing item {processed_count + 1}/100 with account: {item.get('account', 'Unknown')} (Global index: {next_index + 1}/{len(nft_metadata)})")
driver = driversetup(logger)
try:
process_item(item, driver, logger)
processed_count += 1
processed_indices.add(next_index)
except Exception as e:
logger.error(f"Error processing item with account {item.get('account', 'Unknown')}: {e}")
finally:
driver.quit()
logger.info(f"WebDriver closed for item {next_index + 1}")
try:
with open(processed_data_file, 'w') as file:
json.dump(nft_metadata, file, indent=4)
logger.info("Progress saved after processing 100 items.")
except Exception as e:
logger.error(f"An error occurred while saving the progress: {e}")
if __name__ == '__main__':
main()CLICK TO EXPAND JSON Output
[
{
"account": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"onChainAccountInfo": {
"accountInfo": {
"key": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"isSigner": false,
"isWritable": false,
"lamports": 1461600,
"data": {
"parsed": {
"info": {
"decimals": 0,
"freezeAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"isInitialized": true,
"mintAuthority": "62q7i8DMds7SAPSjnShQKHjacZd29421XH4qnNad5xGK",
"supply": "1"
},
"type": "mint"
},
"program": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"space": 82
},
"owner": "TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA",
"executable": false,
"rentEpoch": 361
},
"error": ""
},
"onChainMetadata": {
"metadata": {
"tokenStandard": "NonFungible",
"key": "MetadataV1",
"updateAuthority": "6DMG9hv3eR8BXKH79sXGyQtfRSxXfNrkHEdc6nCsEjVK",
"mint": "DYTo4wYJDA2tRkD3kMzthDY3rrnyWMgSFrBc3TtiSjQq",
"data": {
"name": "Arctic Fox #41",
"symbol": "AFAF",
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"sellerFeeBasisPoints": 1500,
"creators": [
{
"address": "79iAsPyGDhQ7Sw5HcSkhYX9b3tzXp4phxjfPdo9xkmx1",
"verified": true,
"share": 0
},
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"verified": true,
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"verified": true,
"share": 46
}
]
},
"primarySaleHappened": true,
"isMutable": true,
"editionNonce": 255,
"uses": {
"useMethod": "",
"remaining": 0,
"total": 0
},
"collection": {
"key": "EFjksSb2b897hvxuHXrnVoE2y66iufiJxtDSgFJZYQna",
"verified": true
},
"collectionDetails": null
},
"error": ""
},
"offChainMetadata": {
"metadata": {
"attributes": [
{
"traitType": "Arctic Animal",
"value": "Fox"
},
{
"traitType": "Endangered",
"value": "No"
},
{
"traitType": "Paw",
"value": "Left-Up"
},
{
"traitType": "Eyes",
"value": "Heterochromia"
},
{
"traitType": "Mouth",
"value": "Blep"
}
],
"description": "An exclusive family, 69 #SolanaNFTs per collection. Liquidity adding for rewarding #ArcticFrenz.",
"image": "https://arweave.net/p5C032iu3UQ4Lpr5cTNlcW8bVDrcVd872QChc3z8J-4?ext=png",
"name": "Arctic Fox #41",
"properties": {
"category": null,
"creators": [
{
"address": "2wBMxuAYKiVjQFGB48bhHPexNRyeHcDN1aaYT4WYv5r5",
"share": 54
},
{
"address": "8XzUgMAhFZWERytRDNVBdL95LL5Ftox72EiSNzTu63QS",
"share": 46
}
],
"files": [
{
"type": "image/png",
"uri": "40.png"
}
]
},
"sellerFeeBasisPoints": 1500,
"symbol": "AFAF"
},
"uri": "https://m5brw73kei7uoysb7gxdomaxbdqobnz27j65nrq7ohbpgrktfjmq.arweave.net/Z0Mbf2oiP0diQfmuNzAXCODgtzr6fdbGH3HC80VTKlk",
"error": ""
},
"legacyMetadata": null,
"rarity_score": 0.1473389390210555,
"holder data": [
{
"holder": "Ar3Tqj2DVr2WoLmKmG5aFo17Quh33zKWcCMUibKzrgK3"
},
{
"when acquired": 1644640715
},
{
"time checked": 1700666552
}
]
},
{
"_comment": "The file has been truncated for this example. The output JSON file will include all NFTs in the collection along with the respective holder's public keys and the timestamp indicating when they acquired the NFT."
}
]Prerequisites:
- Before starting, upload the JSON file from Part 3, Step 2 and/or the JSON file from Part 2 to the specified directory.
- Manage action permissions in your GitHub repository by going to the “Settings” tab, selecting “Actions” from the sidebar, and choosing to allow either all actions or only local actions.
- Ensure code integrity by setting up branch protection rules in your repository settings.
- Anticipate that the GitHub Action workflow might take around an hour to complete. During this time, a new commit to the repository could occur. To handle this, consider including a force push in the workflow. Do this with caution, ensuring your branch protection rules allow or prevent this as needed.
- Create a Personal Access Token (PAT):
- Access your GitHub account, click on your profile picture, and select “Settings.” Then, navigate to “Developer settings” > “Personal access tokens” > “Generate new token.” Name your token, set an expiration, assign necessary scopes, and click “Generate token.” Copy and securely save the token, as it will not be visible again.
- Add the PAT to Your Repository Secrets:
- In your GitHub repository, click “Settings” > “Secrets” > “New repository secret.” Name your secret (e.g., MY_PAT) and paste your token in the value field. Finally, click “Add secret.”
CLICK TO EXPAND Repo Structure
├── .github
│ └── workflows
│ └── runner.yaml -> Github Action configuration
├── collection
│ ├── time.html -> Store webpage content for parsing and extracting
│ ├── address.html -> Store webpage content for parsing and extracting
│ ├── logfile.log -> Store log messages
│ ├── part2.json -> Output from Part-2
│ └── output.json -> Output from Part-3 Step-2 and from 'script.py'
├── environment.yml
├── script.py -> The Python script
├── README.md
└── .gitignore
YAML Configuration and Workflow:
- Workflow File: The workflow is defined in a
.ymlfile, located under.github/workflows/. A YAML file orchestrates the entire build, execution, and update process for a project. - Trigger Events: The workflow is triggered acutomatically, on a scheduled specified in
- cron:
CLICK TO EXPAND YAML
# .github/workflows/runner.yml
name: runner
on:
workflow_dispatch:
schedule:
- cron: '0 1-23/2 * * *'
permissions:
actions: write
checks: write
contents: write
deployments: write
id-token: write
issues: write
discussions: write
packages: write
pages: write
pull-requests: write
repository-projects: write
security-events: write
statuses: write
jobs:
build-linux:
runs-on: ubuntu-latest
strategy:
max-parallel: 5
steps:
- uses: actions/checkout@v3
- name: Set up Python 3.10
uses: actions/setup-python@v3
with:
python-version: '3.10'
- name: Add conda to system path
run: echo $CONDA/bin >> $GITHUB_PATH
- name: Install dependencies
run: conda env update --file environment_extraction.yml --name base
- name: Install Chrome
env:
DEBIAN_FRONTEND: noninteractive
run: |
sudo apt-get update
sudo apt-get install -y google-chrome-stable
- name: Set up Git identity
run: |
git config --global user.name 'USERNAME'
git config --global user.email 'EMAIL@EMAIL.com'
env:
GITHUB_TOKEN: ${{ secrets.MY_PAT }}
- name: Run script
run: python script.py
- name: Stash Changes
run: git stash --include-untracked
- name: Pull changes from Remote
run: git pull --rebase origin main
- name: Reapply Stashed Changes
run: git stash pop
- name: Add
run: |
git add collection/with-rarity-and-holder-data.json
git add collection/logfile.log
- name: Commit
run: git commit -m "Updated holders data"
- name: Attempt Normal Push
id: normal_push
run: git push origin main
env:
GITHUB_TOKEN: ${{ secrets.MY_PAT }}
continue-on-error: true
- name: Force Push Changes
if: steps.normal_push.outcome == 'failure'
run: git push --force origin main
env:
GITHUB_TOKEN: ${{ secrets.MY_PAT }}
- name: Cleanup
run: echo "Workflow completed."CLICK TO EXPAND Env
# environment.yml
dependencies:
- python=3.10
- pip
- numpy
- pandas
- flask
- pytest
- beautifulsoup4
- psutil
- pip:
- selenium>=4.0.0
- webdriver-managerCLICK TO EXPAND Python Script
# In the root of the repository
import json
import random
import time
import logging
import sys
import os
from datetime import datetime
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, ElementClickInterceptedException
from selenium.webdriver.common.action_chains import ActionChains
import psutil
LOG_FILE = 'collection/logfile.log'
FILE_ADDRESS = 'collection/address.html'
FILE_TIME = 'collection/time.html'
def setup_logger(log_file_path, logger_name='MyAppLogger'):
logger = logging.getLogger(logger_name)
logger.handlers = []
logger.setLevel(logging.INFO)
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler(log_file_path)
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(logging.INFO)
stream_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(stream_handler)
return logger
def kill_chrome_and_chromedriver(logger):
for proc in psutil.process_iter():
if 'chrome' in proc.name().lower() or 'chromedriver' in proc.name().lower():
try:
proc.kill()
except (psutil.NoSuchProcess, psutil.AccessDenied, psutil.ZombieProcess):
pass
def driversetup(logger):
options = webdriver.ChromeOptions()
options.add_argument("user-data-dir=selenium")
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--disable-gpu")
options.add_argument("--remote-debugging-port=9222")
options.add_argument("lang=en-US")
options.add_argument("location=US")
options.add_argument(f"--window-size={1920},{1080}")
options.add_argument("disable-infobars")
options.add_argument("--disable-extensions")
options.add_argument("--incognito")
options.add_argument("--disable-blink-features=AutomationControlled")
options.page_load_strategy = 'normal'
# options.binary_location = '/usr/bin/google-chrome'
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
]
selected_user_agent = random.choice(user_agents)
options.add_argument(f"user-agent={selected_user_agent}")
caps = webdriver.DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'browser': 'ALL'}
service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
driver.execute_cdp_cmd("Network.clearBrowserCookies", {})
driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": {"Referer": "https://www.google.com/"}})
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined});")
return driver
def random_sleep(min_seconds, max_seconds):
time.sleep(random.uniform(min_seconds, max_seconds))
def simulate_human_interaction(driver, logger):
action = ActionChains(driver)
body_element = driver.find_element(By.TAG_NAME, 'body')
for _ in range(random.randint(1, 3)):
action.send_keys_to_element(body_element, Keys.PAGE_DOWN).perform()
random_sleep(0.5, 1.0)
action.send_keys_to_element(body_element, Keys.PAGE_UP).perform()
random_sleep(0.5, 1.0)
action.move_to_element(body_element).perform()
random_sleep(0.5, 1.0)
action.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
random_sleep(0.5, 1.0)
def extract_owner_address_from_file(file_path, logger):
try:
with open(FILE_ADDRESS, 'r') as file:
html_content = file.read()
soup = BeautifulSoup(html_content, 'html.parser')
tables = soup.find_all("table")
for table in tables:
if table.find("th", {"title": "Owner"}):
visible_rows = table.select("tbody tr:not(.ant-table-measure-row)")
if visible_rows:
owner_address_element = visible_rows[0].select_one("td:nth-of-type(2) a")
if owner_address_element:
address = owner_address_element.text.strip()
logger.info(f"Owner address found: {address}")
return address
else:
logger.info("Owner address not found in the table.")
return "Address not found"
else:
logger.info("No visible rows found in the owner table.")
return "No rows in table"
except Exception as e:
logger.info(f"Error while extracting owner address: {e}")
return f"Error: {e}"
def extract_time_from_file(file_path, logger):
try:
with open(file_path, 'r') as file:
html_content = file.read()
logger.info(f"Successfully read HTML content from '{file_path}'.")
soup = BeautifulSoup(html_content, 'html.parser')
time_column_index = 4
table = soup.select_one("#rc-tabs-0-panel-txs table")
if not table:
logger.info("The specific table with ID 'rc-tabs-0-panel-txs' was not found.")
return "Table not found"
time_cell = table.select_one("tbody tr:nth-of-type(2) td:nth-of-type(4)")
if not time_cell:
logger.info("Time cell not found in the specified row and column.")
return "Time cell not found"
hold_time = time_cell.text.strip()
logger.info(f"Time successfully extracted: {hold_time}")
return hold_time
except Exception as e:
logger.info(f"An unexpected error occurred while extracting time from '{file_path}': {e}")
return f"Error: {e}"
def getholderaddress(url_holder, driver, logger):
try:
driver.get(url_holder)
wait = WebDriverWait(driver, timeout=30)
root = driver.find_element(By.ID, 'root')
body = driver.find_element(By.TAG_NAME, 'body')
wait.until(lambda d: driver.execute_script('return document.readyState') == 'complete')
wait.until(lambda d: root.is_displayed())
wait.until(lambda d: body.is_displayed())
random_sleep(7, 8)
simulate_human_interaction(driver, logger)
root_html = driver.find_element(By.ID, 'root').get_attribute('outerHTML')
with open(FILE_ADDRESS, 'w') as file:
file.write(root_html)
solana_address = extract_owner_address_from_file(FILE_ADDRESS, logger)
logger.info(f"Holder Address: {solana_address}")
except TimeoutException:
logger.error("Timed out waiting for page to load")
solana_address = "Error: Page did not load properly"
except Exception as e:
logger.error(f"An error occurred: {e}")
solana_address = "Error: Unexpected issue occurred"
return solana_address
def get_hold_time(url_time, driver, logger):
try:
driver.get(url_time)
wait = WebDriverWait(driver, timeout=30)
root = driver.find_element(By.ID, 'root')
body = driver.find_element(By.TAG_NAME, 'body')
wait.until(lambda d: driver.execute_script('return document.readyState') == 'complete')
wait.until(lambda d: root.is_displayed())
wait.until(lambda d: body.is_displayed())
random_sleep(8, 9)
simulate_human_interaction(driver, logger)
javascript = """
const clickAndCheck = async () => {
const clockIconElement = document.querySelector(".ant-space.ant-space-vertical.sc-cwSeag.jTZqgO > div > div > div > div > div > div > div > table > thead > tr > th:nth-child(4) > span");
if (!clockIconElement) {
console.warn('Unable to find clock icon element');
return;
}
let retries = 5;
while (clockIconElement.querySelector('svg') && retries > 0) {
await clockIconElement.click();
console.log('Clicking clock icon, remaining retries:', retries);
retries--;
await new Promise(resolve => setTimeout(resolve, 1000));
}
if (retries === 0) {
console.warn('Max retries reached for clock icon click');
} else {
console.log('Clicking successful - clock icon disappeared');
}
};
clickAndCheck();
"""
try:
driver.execute_script(javascript)
except Exception as e:
logger.error(f"An error occurred: {e}")
time.sleep(2)
body_html = driver.find_element(By.TAG_NAME, 'body').get_attribute('outerHTML')
with open(FILE_TIME, 'w') as file:
file.write(body_html)
hold_time = extract_time_from_file(FILE_TIME, logger)
logger.info(f"Hold time extracted: {hold_time}")
except TimeoutException as e:
logger.info(f"TimeoutException encountered: {e}. The website might be unresponsive or the element locators might be incorrect.")
hold_time = "Error: Timed out"
except Exception as e:
logger.info(f"Unexpected error encountered: {e}. Review the stack trace for details and check the website's structure.")
hold_time = "Error: Unexpected issue occurred"
finally:
logger.info("Closing the web driver...")
driver.close()
logger.info("Web driver closed for time.")
return hold_time
def process_item(item, driver, logger):
account = item.get('account')
if not account:
logger.info("Account information not found in the item.")
return
time.sleep(1)
url_holder = f"https://solscan.io/token/{account}#holders"
logger.info(f"https://solscan.io/token/{account}#holders")
time.sleep(1)
url_time = f"https://solscan.io/token/{account}#txs"
logger.info(f"https://solscan.io/token/{account}#txs")
time.sleep(1)
try:
solana_address = getholderaddress(url_holder, driver, logger)
hold_time = get_hold_time(url_time, driver, logger)
update_json_data(item, solana_address, hold_time, logger)
logger.info(f"Successfully processed account {account}.")
except Exception as e:
logger.error(f"Error processing {account}: {e}")
def update_json_data(item, solana_address, hold_time_str, logger):
hold_time_format = "%m-%d-%Y %H:%M:%S"
hold_time = datetime.strptime(hold_time_str, hold_time_format)
current_time = datetime.now()
hold_time_unix = int(hold_time.timestamp())
current_time_unix = int(current_time.timestamp())
item['holder data'] = [
{"holder": solana_address},
{"when acquired": hold_time_unix},
{"time checked": current_time_unix}
]
def find_start_index(nft_metadata, processed_indices, logger):
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' not in item:
logger.info(f"Starting from index {index}: No 'holder data' field found.")
return index
logger.info("All items have 'holder data'. Moving to the next priority.")
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
holder = item['holder data'][0]['holder']
if holder is None:
logger.info(f"Starting from index {index}: Found invalid 'holder' value.")
return index
if len(holder) not in range(32, 45) and holder != "Magic Eden V2 Authority":
logger.info(f"Starting from index {index}: Found invalid 'holder' value.")
return index
logger.info("All items have valid 'holder' values. Moving to the next priority.")
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
when_acquired = item['holder data'][1]['when acquired']
if not isinstance(when_acquired, int):
logger.info(f"Starting from index {index}: 'when acquired' is not a Unix epoch timestamp.")
return index
logger.info("All items have valid 'when acquired' timestamps. Moving to the next priority.")
oldest_index = None
oldest_time = float('inf')
for index, item in enumerate(nft_metadata):
if index in processed_indices:
continue
if 'holder data' in item:
time_checked = item['holder data'][2]['time checked']
if time_checked < oldest_time:
oldest_time = time_checked
oldest_index = index
if oldest_index is not None:
logger.info(f"Starting from index {oldest_index}: It has the oldest 'time checked'.")
return oldest_index
else:
logger.info("No items to prioritize based on 'time checked'.")
return len(nft_metadata)
def get_next_item_index(nft_metadata, logger):
return find_start_index(nft_metadata, logger)
def main():
logger = setup_logger(LOG_FILE)
logger.info("Starting new run. Appending to the existing logfile.")
kill_chrome_and_chromedriver(logger)
processed_data_file = 'collection/with-rarity-and-holder-data.json'
if os.path.exists(processed_data_file):
try:
with open(processed_data_file, 'r') as file:
nft_metadata = json.load(file)
logger.info("Continuing from previously saved progress.")
except Exception as e:
logger.error(f"Error loading processed data: {e}")
return
else:
try:
with open('collection/with-rarity.json', 'r') as file:
nft_metadata = json.load(file)
logger.info("Starting from the beginning as no progress file found.")
except Exception as e:
logger.error(f"Error loading initial data: {e}")
return
processed_count = 0
processed_indices = set()
while processed_count < 100:
next_index = find_start_index(nft_metadata, processed_indices, logger)
if next_index >= len(nft_metadata):
logger.info("All items have been processed or no more items to prioritize.")
break
item = nft_metadata[next_index]
logger.info(f"Processing item {processed_count + 1}/100 with account: {item.get('account', 'Unknown')} (Global index: {next_index + 1}/{len(nft_metadata)})")
driver = driversetup(logger)
try:
process_item(item, driver, logger)
processed_count += 1
processed_indices.add(next_index)
except Exception as e:
logger.error(f"Error processing item with account {item.get('account', 'Unknown')}: {e}")
finally:
driver.quit()
logger.info(f"WebDriver closed for item {next_index + 1}")
try:
with open(processed_data_file, 'w') as file:
json.dump(nft_metadata, file, indent=4)
logger.info("Progress saved after processing 100 items.")
except Exception as e:
logger.error(f"An error occurred while saving the progress: {e}")
if __name__ == '__main__':
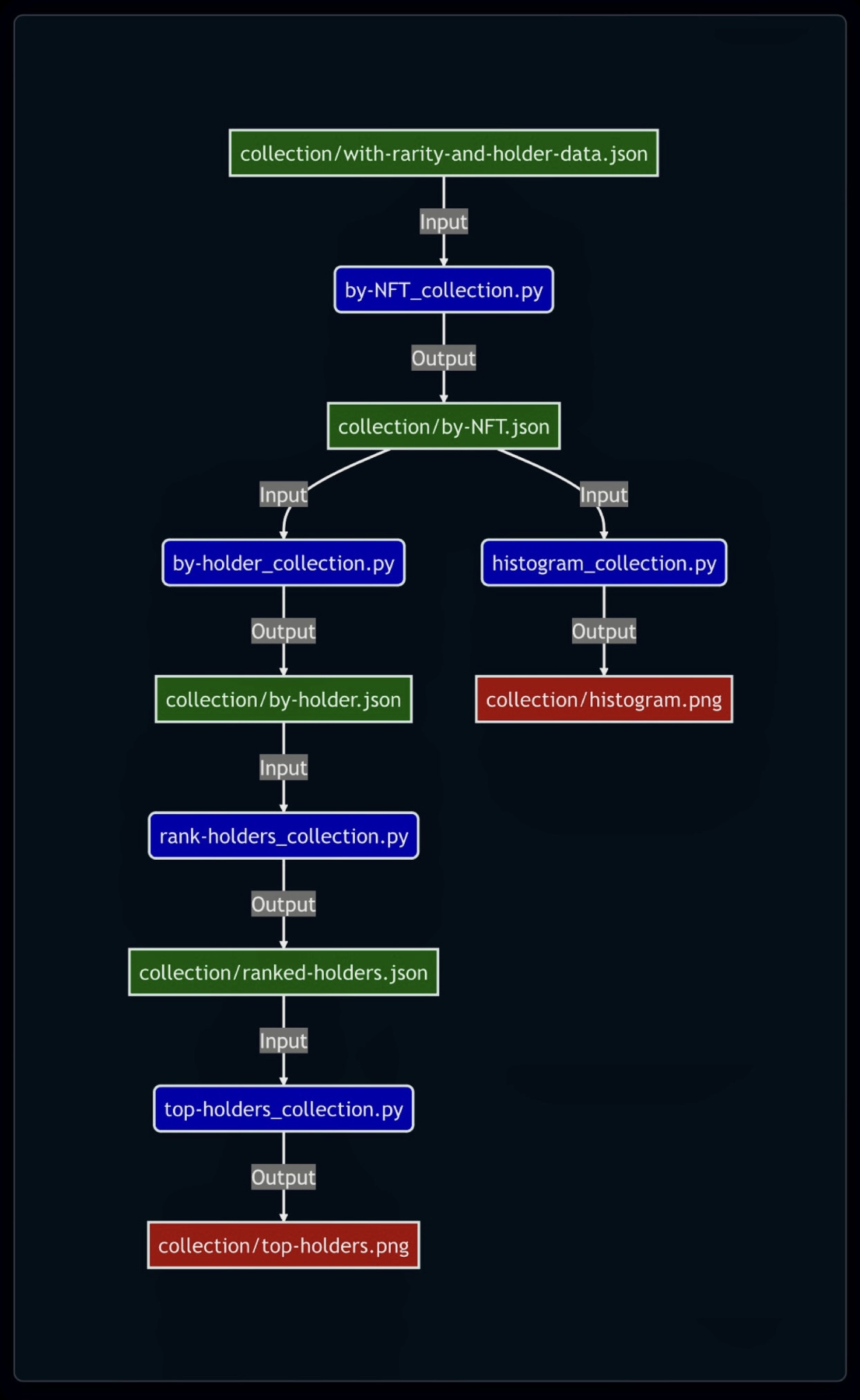
main()Below is a flowchart outlining the primary components of the processing pipeline from Part 5 to Part 7.
CLICK TO EXPAND Flowchart
|
Pretty-printing involves rearranging fields in a JSON file to enhance readability. This process includes structuring the data by organizing fields in a logical order and improving the overall presentation of the content.
This script reformats and enhances the data by performing the following tasks:
- Extracts NFT name.
- Extracts NFT address and rarity score.
- Extracts holder address, acquisition timestamp, and time this holder data was checked.
- Rewrites data into a new format.
- Orders NFTs alphabetically by base name and numerically by number within the name (if present).
CLICK TO EXPAND Input Description
- JSON file containing Arctic Frenz NFT metadata with the following key-value pairs:
onChainMetadata: Dictionary containing on-chain metadata.metadata: Dictionary containing NFT metadata.data: Dictionary with various NFT details, including name.
account: String representing the NFT address.rarity_score: Integer representing the NFT rarity score.holder data: List containing holder information if available.holder: String representing the holder address.when acquired: Unix timestamp indicating acquisition time.time checked: Unix timestamp indicating the last check for holder information.
CLICK TO EXPAND Python Script
import json
import re
def get_name(nft_name):
try:
return nft_name.rsplit(' ', 1)[0]
except IndexError:
return nft_name.split(' ', 1)[0]
def get_nft_number(nft_name):
match = re.search(r'#(\d+)', nft_name)
if match:
return int(match.group(1))
return 0
def rewrite_data(data):
rewritten_data = []
for item in data:
nft_name = item["onChainMetadata"]["metadata"]["data"]["name"]
nft_address = item["account"]
rarity_score = item["rarity_score"]
holder_data = {}
if "holder data" in item:
holder_data = {
"holderAddress": item["holder data"][0]["holder"],
"whenAcquired": item["holder data"][1]["when acquired"],
"timeChecked": item["holder data"][2]["time checked"]
}
rewritten_data.append({
"nftName": nft_name,
"nftAddress": nft_address,
"rarityScore": rarity_score,
"holderData": holder_data,
})
return rewritten_data
with open("collection/with-rarity-and-holder-data.json") as f:
data = json.load(f)
naming = set([get_name(x["onChainMetadata"]["metadata"]["data"]["name"]) for x in data])
naming_order = sorted(list(naming))
rewritten_data = rewrite_data(data)
rewritten_data = sorted(rewritten_data, key=lambda x: (naming_order.index(get_name(x["nftName"])), get_nft_number(x["nftName"])))
with open("collection/by-NFT.json", "w") as f:
json.dump(rewritten_data, f, indent=4)CLICK TO EXPAND Output Description
- New JSON file containing enhanced NFT data with the following key-value pairs:
nftName: String representing the base name of the NFT.nftAddress: String representing the NFT address.rarityScore: Integer representing the NFT rarity score.holderData: Dictionary containing holder information if available.
CLICK TO EXPAND Enhanced JSON
[
{
"nftName": "Arctic Fox #01",
"nftAddress": "3cTJaaDekCWbdRMcqLWuq4gniN5Nq3iUnC28fLoqdgci",
"rarityScore": 0.1764528675833024,
"holderData": {
"holderAddress": "6LgQvDQGKUSYZtUbmkFYBf7nusGPGeCEkBLkq4cXNy4C",
"whenAcquired": 1650854496,
"timeChecked": 1701719058
}
},
{
"nftName": "Arctic Fox #02",
"nftAddress": "3Qi7JrU7BUF7soqJDP55BXa5bYmhxP8kqMZDyjBG2MKU",
"rarityScore": 0.13524407637451114,
"holderData": {
"holderAddress": "GiWfd8qU2astb3UqSQeZ7KFEvTYiXjGTvxwk6zn3kzFw",
"whenAcquired": 1649993063,
"timeChecked": 1701719584
}
},
{
"_comment": "The file has been truncated for this example."
}
]This Python script preprocesses data about the holders of a collection's NFTs, producing a JSON file suitable for further analysis. The script performs the following tasks:
- Loads data: Reads the input JSON file containing information about each NFT and its holder.
- Identifies valid holder addresses: Filters out entries with invalid, missing holder addresses, or addresss that are NFT marketplaces.
- Aggregates information: Groups NFTs by holder address and combines their attributes.
- Calculates days held: Computes the number of days each NFT has been held by the owner.
- Sorts data: Orders holders by the total number of NFTs they hold, descending.
CLICK TO EXPAND Python Script
import json
import re
from datetime import datetime
with open('collection/by-NFT.json') as f:
data = json.load(f)
holders = {}
for nft in data:
holder_data = nft['holderData']
if holder_data is None:
continue
holder_address = holder_data.get('holderAddress') # Get the holderAddress
if holder_address in ["Magic Eden V2 Authority", "4zdNGgAtFsW1cQgHqkiWyRsxaAgxrSRRynnuunxzjxue", "1BWutmTvYPwDtmw9abTkS4Ssr8no61spGAvW1X6NDix"]:
continue
if holder_data:
holder_address = holder_data['holderAddress']
if isinstance(holder_address, str):
if not re.match(r'^[123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz]{32,44}$', holder_address):
continue
if holder_address not in holders:
holders[holder_address] = {
"holderAddress": holder_address,
"quantityNfts": 1,
"holdingNfts": [{
"nftAddress": nft['nftAddress'],
"rarityScore": nft['rarityScore'],
"daysHeld": (datetime.utcnow() - datetime.utcfromtimestamp(holder_data['whenAcquired'])).days
}]
}
else:
holders[holder_address]['quantityNfts'] += 1
holders[holder_address]['holdingNfts'].append({
"nftAddress": nft['nftAddress'],
"rarityScore": nft['rarityScore'],
"daysHeld": (datetime.utcnow() - datetime.utcfromtimestamp(holder_data['whenAcquired'])).days
})
result = sorted(holders.values(), key=lambda x: x["quantityNfts"], reverse=True)
with open('collection/by-holder.json', 'w') as f:
json.dump(result, f, indent=4)Notes:
- The script filters out holders with addresses belonging to "Magic Eden V2 Authority" and "Tensor" (platform wallets).
- The script validates holder addresses using a regular expression to ensure they conform to the expected format.
- The script calculates days held based on the current date and the acquisition timestamp.
CLICK TO EXPAND Enhanced JSON
[
{
"holderAddress": "69rBBg8rx4WzwBFyt18iRJZqLYzM8Q6omNXBHo7hWRL9",
"quantityNfts": 2,
"holdingNfts": [
{
"nftAddress": "DQjgTJMaW8j63F7Gu3mzTQcnf6GcGshskDkVA6224L8Y",
"rarityScore": 0.28691583054626535,
"daysHeld": 519
},
{
"nftAddress": "F1dYNFtNw1fTjTQV4ztrioYmpcg3JDBN1GGANxzxBHUN",
"rarityScore": 0.5152741805816168,
"daysHeld": 607
}
]
},
{
"holderAddress": "6LgQvDQGKUSYZtUbmkFYBf7nusGPGeCEkBLkq4cXNy4C",
"quantityNfts": 1,
"holdingNfts": [
{
"nftAddress": "3cTJaaDekCWbdRMcqLWuq4gniN5Nq3iUnC28fLoqdgci",
"rarityScore": 0.1764528675833024,
"daysHeld": 589
}
]
},
{
"_comment": "The file has been truncated for this example."
}
]This Python script calculates a score for each NFT holder based on three key factors. The calculated scores are then utilized to rank the holders.
- Quantity of NFTs held.
- Rarity score of NFTs held.
- Time each NFT has been held.
CLICK TO EXPAND Variable Descriptions
| Input | Description |
|---|---|
nfts |
NFT count per owner |
["rarityScore"] |
Rarity Score |
["daysHeld"] |
Days held NFT |
sum(["daysHeld"]) |
Sum of days held NFTs |
max_nfts |
The total number of NFTs owned by the individual with the largest NFT collection |
highest_rarity_average |
The average rarity score of the owner who possesses the highest average rarity score |
hold_door |
The total duration held by the owner possessing the maximum cumulative duration of all NFTs they own |
quantityNfts_weight |
Weight given to the number of NFTs held |
rarityScore_weight |
Weight given to rarity scores |
daysHeld_weight |
Weight given to days held scores |
daysHeld_decay_factor |
Factor controlling the decay of score based on days held |
CLICK TO EXPAND Example Data
| Input | Value |
|---|---|
nfts |
2 |
["rarityScore"] |
0.2869 |
["rarityScore"] |
0.4233 |
["daysHeld"] |
186 |
["daysHeld"] |
333 |
sum(["daysHeld"]) |
519 |
max_nfts |
50 |
highest_rarity_average |
0.5327 |
hold_door |
28296 |
quantityNfts_weight |
1 |
rarityScore_weight |
0.1 |
daysHeld_weight |
1 |
daysHeld_decay_factor |
0.1 |
Review each factor's average to consider adjustments to the weights assigned to the number of NFTs (quantityNfts_weight), rarity score (rarityScore_weight), and holding duration (daysHeld_weight). This evaluation will help in fine-tuning the scoring system for more accurate rankings.
CLICK TO EXPAND Example Averages
| Factor Averages | Scores |
|---|---|
average_nfts_weighted |
0.0861 |
average_rarity_score_weighted |
0.0640 |
average_days_held_weighted |
0.0753 |
The final score (scoreHold) is calculated as the sum of the scores for each factor:
scoreHold = nfts_weighted + rarity_score_weighted + days_held_weightedCLICK TO EXPAND Example Scores
| Factor | Scores |
|---|---|
nfts_weighted |
0.04 |
rarity_score_weighted |
0.0708 |
days_held_weighted |
0.0183 |
scoreHold |
0.1291 |
The comprehensive scoring system is shaped by three key metrics: the Quantity of NFTs, Rarity Score, and Holding Time.
CLICK TO EXPAND Analysis
1. Quantity of NFTs: The number of NFTs held by an individual serves as a key indicator of their engagement within the collection's community. This quantity contributes to the holder's score by reflecting the size of their NFT collection. Holding a larger number of NFTs suggests a more extensive portfolio and potentially a greater influence or presence within the NFT community. However, this factor is normalized against the maximum number of NFTs held by any single holder to ensure fairness and relativity in the scoring system. It is important to note that while quantity is a significant factor, it does not directly indicate the quality or value of the collection, which is where the other factors come into play.
2. Rarity Score: The Rarity Score of the NFTs a person holds is a vital element that enhances their overall score. This factor assesses the uniqueness or scarcity of each NFT in the holder’s collection. In the NFT market, rarity often drives value, with more rare pieces generally being more desirable and valuable. By calculating the average rarity score of a holder’s NFTs and normalizing this against the highest average rarity score in the dataset, the scoring system effectively recognizes those with particularly unique or scarce NFTs. This approach ensures a balance, shifting the focus from simply amassing a large quantity of NFTs to highlighting the quality and exclusivity of the collection.
3. Holding Time: The Holding Time factor measures how long each NFT has been kept by its holder, reflecting their commitment and belief in the long-term value of their NFTs. The longer an NFT is retained, the more it demonstrates the holder's sustained interest and engagement in that asset. However, to prevent this factor from disproportionately favoring long-term holders and to mirror the dynamic nature of the NFT market, a decay factor is applied. This decay gradually reduces the score over time, encouraging new acquisitions. This approach balances the value of long-term holding against the potential benefits of active trading or diversification.
CLICK TO EXPAND Python Script
import json
from datetime import date
import traceback
from math import exp
import numpy as np
try:
with open('collection/by-holder.json') as f:
data = json.load(f)
quantityNfts_weight = 1
rarityScore_weight = 0.1
daysHeld_weight = 1
daysHeld_decay_factor = 0.1
max_nfts = max([holder["quantityNfts"] for holder in data])
# print(f"The total number of NFTs owned by the individual with the largest NFT collection: {max_nfts}")
avg_rarity_per_holder = [(holder["holderAddress"], sum(subnft["rarityScore"] for subnft in holder["holdingNfts"]) / holder["quantityNfts"]) for holder in data]
rarity_sniper = max(avg_rarity_per_holder, key=lambda x: x[1])
highest_rarity_average = rarity_sniper[1]
# print(f"The average rarity score of the owner who possesses the highest average rarity score: {highest_rarity_average}")
days_held_per_holder = [(holder["holderAddress"], sum(subnft["daysHeld"] for subnft in holder["holdingNfts"])) for holder in data]
diamond_hands = max(days_held_per_holder, key=lambda x: x[1])
hold_door = diamond_hands[1]
# print(f"Th total duration held by the owner possessing the maximum cumulative duration of all NFTs they own : {hold_door}")
today = date.today()
def score_address(addr):
holder_data = [holder for holder in data if holder["holderAddress"] == addr]
if not holder_data:
return 0
holder_data = holder_data[0]
nfts = holder_data["quantityNfts"]
nfts_normalized = nfts / max_nfts
nfts_weighted = nfts_normalized * quantityNfts_weight
rarity_scores = [subnft["rarityScore"] for subnft in holder_data["holdingNfts"]]
rarity_scores_log = [np.log(score + 1) for score in rarity_scores]
rarity_score_average = sum(rarity_scores_log) / len(rarity_scores_log)
rarity_score_normalized = rarity_score_average / np.log(highest_rarity_average + 1)
rarity_score_weighted = rarity_score_normalized * rarityScore_weight
days_held = sum([subnft["daysHeld"] for subnft in holder_data["holdingNfts"]])
days_held_normalized = days_held / hold_door
decay_factor = exp(-days_held_normalized * daysHeld_decay_factor)
days_held_with_decay = days_held_normalized * decay_factor
days_held_weighted = days_held_with_decay * daysHeld_weight
# print(f"Address: {addr}, NFTs Weighted: {nfts_weighted}, Rarity Score Weighted: {rarity_score_weighted}, Days Held Weighted: {days_held_weighted}")
scoreHold = (nfts_weighted + rarity_score_weighted + days_held_weighted)
return scoreHold, # nfts_weighted, rarity_score_weighted, days_held_weighted
# Review the calculated averages to consider adjustments to the weights assigned to the number
# of NFTs (`quantityNfts_weight`), rarity score (`rarityScore_weight`), and holding duration
# (`daysHeld_weight`). This evaluation will help in fine-tuning the scoring system for more
# accurate assessments.
"""
sum_nfts_weighted = 0
sum_nfts_weighted = 0
sum_rarity_score_weighted = 0
sum_days_held_weighted = 0
for holder in data:
_, nfts_weighted, rarity_score_weighted, days_held_weighted = score_address(holder["holderAddress"])
sum_nfts_weighted += nfts_weighted
sum_rarity_score_weighted += rarity_score_weighted
sum_days_held_weighted += days_held_weighted
average_nfts_weighted = sum_nfts_weighted / len(data)
average_rarity_score_weighted = sum_rarity_score_weighted / len(data)
average_days_held_weighted = sum_days_held_weighted / len(data)
print(f"Average Score of Holder's NFTs Owned: {average_nfts_weighted}")
print(f"Average Score of Holder's Rarity: {average_rarity_score_weighted}")
print(f"Average Score of Holder's Days Held: {average_days_held_weighted}")
"""
scored = []
for holder in data:
score = score_address(holder["holderAddress"])
holder["holderScore"] = score
scored.append(holder)
ranked = sorted(scored, key=lambda x: x["holderScore"], reverse=True)
with open('collection/ranked-holders.json', 'w') as f:
json.dump(ranked, f, indent=4)
except Exception as e:
print(f"Error: {e}")
traceback.print_exc()CLICK TO EXPAND Example JSON
[
{
"holderAddress": "GhmfgNRNdGeBnG1F2zVKGaeubEyaYMKKHdtNSXxxX1y1",
"quantityNfts": 2,
"holdingNfts": [
{
"nftAddress": "5MtR9S2JvPTGRdGpr3KECj2vFpiM2bLyzRbsarSvSYbd",
"rarityScore": 0.28691583054626535,
"daysHeld": 186
},
{
"nftAddress": "2oKAffmpTmKCXYEtwCXYyu5Qr1YN2LBGzFhH4xNXhv4U",
"rarityScore": 0.423377470697102,
"daysHeld": 333
}
],
"holderScore": 1.0315465044376115
},
{
"holderAddress": "8YsZFwVQ8FVBNSYpLoBuD4Vx64tVY2ymKeRn9ji4JJ14",
"quantityNfts": 1,
"holdingNfts": [
{
"nftAddress": "4DrC8teNFSmWNWgj1ZAUDu8FShRE4cfeMWbtmBsa9NdH",
"rarityScore": 0.18776169520791947,
"daysHeld": 599
}
],
"holderScore": 0.939535991081045
},
{
"_comment": "The file has been truncated for this example."
}
]This Python script creates a bar chart showcasing the top holders of a NFT collection. Additionally, it reveals the important factors that influence a holder's ranking:
- Quantity of NFTs Owned: Number of NFTs held by the holder.
- Cumulative Rarity Score Across NFTs Owned: Sum of the rarity scores of all NFTs held by the holder.
- Cumulative Hold Duration in Days Across NFTs Owned: Sum of the number of days each NFT has been held by the holder.
Features:
- Custom logarithmic scale for the hold duration axis to better represent large differences.
- Human-readable formatting for large numbers on the hold duration axis.
- Legend for each metric category.
- Inverted y-axis for easier comparison of holders.
CLICK TO EXPAND Python Script
import json
import matplotlib.pyplot as plt
from matplotlib import ticker
import matplotlib.font_manager as fm
import numpy as np
import math
from datetime import datetime
def custom_formatter(x, pos):
if x >= 100:
exponent = int(math.log10(x))
mantissa = x / 10**exponent
return f"{mantissa:.0f}e{exponent}"
else:
return "%d" % x
with open('collection/ranked-holders.json') as f:
data = json.load(f)[:20]
data = [d for d in data if d is not None]
holders = []
for d in data:
address = d.get('holderAddress')
if address:
holders.append(address[:4] + "..." + address[-4:])
else:
holders.append("Unknown")
metrics = [
(d['quantityNfts'],
sum(nft['rarityScore'] for nft in d['holdingNfts']),
sum(nft['daysHeld'] for nft in d['holdingNfts']))
for d in data
]
font1 = fm.FontProperties(size=12)
plt.style.use('dark_background')
fig, ax = plt.subplots(figsize=(7, 8.4))
x = np.arange(len(holders))
width = 0.2
ticks = x + 0.9 * width
locator = ticker.FixedLocator(ticks)
ax.yaxis.set_major_locator(locator)
ax.set_yticklabels(holders, color='#ffffff', fontsize=10)
ax.set_ylabel('Holders', color='#E0E0E0', fontsize=16, fontweight=5)
ax.set_title('Collection Name\nTop Holders', fontsize=20, fontweight=5, color='#E0E0E0')
ax.tick_params(axis='y', color='#E0E0E0')
ax.tick_params(axis='x', which='both', bottom=False, top=False, labelbottom=False)
ax.invert_yaxis()
ax.text(0.5, 0.5, 'Arctic Frenz', fontsize=70, color='gray', alpha=0.2,
ha='center', va='center', rotation=30, transform=ax.transAxes)
ax1 = ax.twiny()
ax1.set_xscale('linear')
ax1.barh(x, [m[0] for m in metrics], width, color='#00e0ff', label='Quantity of NFTs Owned', edgecolor='#E0E0E0', alpha=0.8)
ax1.set_ylabel('Quantity of NFTs Owned', color='#00e0ff')
ax1.set_autoscalex_on(True)
ax1.xaxis.set_major_formatter(ticker.FormatStrFormatter('%d'))
ax1.tick_params(axis='y', labelcolor='#00e0ff')
ax1.tick_params(axis='x', which='both', labelcolor='#00e0ff', tickdir='in', direction='out', length=4, width=1, colors='#00e0ff', grid_color='#00e0ff', grid_alpha=0.5)
ax1.grid(axis='x', linestyle='--', alpha=0.5, color='#00e0ff')
ax1.yaxis.label.set_color('#00e0ff')
ax2 = ax.twiny()
ax2.set_xscale('linear')
ax2.barh(x + 1*width, [m[1] for m in metrics], width, color='#ff00a8', label='Cumulative Rarity Score\nAcross NFTs Owned', edgecolor='#E0E0E0', alpha=0.8)
ax2.set_ylabel('Cumulative Rarity Score\nAcross NFTs Owned', color='#ff00a8')
ax2.set_autoscalex_on(True)
ax2.xaxis.set_major_formatter(ticker.FormatStrFormatter('%d'))
ax2.tick_params(axis='y', labelcolor='#ff00a8')
ax2.tick_params(axis='x', labelcolor='#ff00a8', tickdir='out', direction='out', length=15, width=1, colors='#ff00a8', grid_color='#ff00a8', grid_alpha=0.5)
ax2.grid(axis='x', linestyle='--', alpha=0.5, color='#ff00a8')
ax2.yaxis.label.set_color('#ff00a8')
ax3 = ax.twiny()
ax3.set_xscale('log')
ax3.barh(x + 2*width, [m[2] for m in metrics], width, color='#fdff00', label='Cumulative Hold Duration\nin Days Across NFTs Owned', edgecolor='#E0E0E0', alpha=0.8)
ax3.set_ylabel('Cumulative Hold Duration\nin Days Across NFTs Owned', color='#fdff00')
ax3.set_autoscalex_on(True)
ax3.xaxis.set_major_formatter(custom_formatter)
ax3.tick_params(axis='y', labelcolor='#fdff00')
ax3.tick_params(axis='x', labelcolor='#fdff00', tickdir='out', direction='out', length=35, width=1, colors='#fdff00', grid_color='#fdff00', grid_alpha=0.5)
ax3.grid(axis='x', linestyle='--', alpha=0.5, color='#fdff00')
ax3.yaxis.label.set_color('#fdff00')
legend_handles = []
legend_labels = []
for ax in [ax1, ax2, ax3]:
handles, labels = ax.get_legend_handles_labels()
legend_handles.extend(handles)
legend_labels.extend(labels)
fig.legend(legend_handles, legend_labels, bbox_to_anchor=(0.98, 0.02), loc='lower right', title='Holders\' Stats', fontsize=10)
generation_time = datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S UTC")
footnote_text = f"Chart generated on:\n{generation_time}"
fig.text(-0.16, 1.17, footnote_text, fontsize=9, color='#E0E0E0', ha="left", va="top", transform=ax.transAxes, alpha=0.7)
fig.tight_layout()
plt.savefig('collection/top-holders.png', format='png', bbox_inches='tight')CLICK TO EXPAND Bar Chart
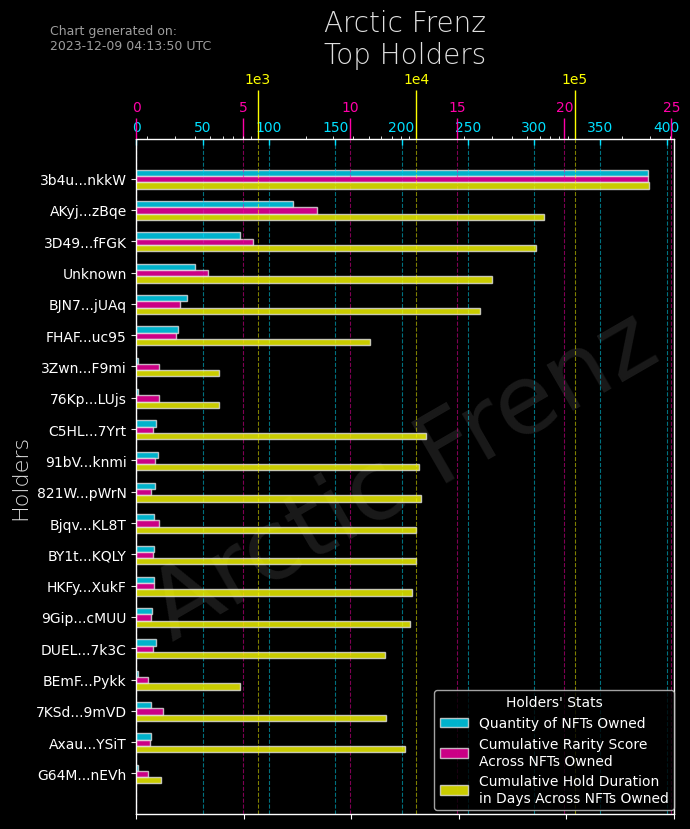
|
The provided Python script is tailored to examine and depict the distribution of ownership duration. It adeptly processes a dataset, constructs a histogram, and stores the resulting image. This functionality is crucial for gaining a deeper understanding of the holding patterns.
The histogram serves as a visual representation, making complex data more accessible and interpretable. The following provides a detailed breakdown of the script's main features and capabilities:
CLICK TO EXPAND Breakdown
-
Data Loading and Preprocessing:
- The script begins by loading NFT data from a JSON file (
collection/by-NFT.json). - It processes each NFT's data, focusing on the holder's address and the acquisition timestamp.
- The script begins by loading NFT data from a JSON file (
-
Ownership Duration Calculation:
- For each NFT, the script calculates the duration of ownership in days.
- It converts Unix timestamps to dates and computes the difference from the current date.
-
Data Filtering:
- NFTs held by specific addresses (like "Magic Eden V2 Authority" and "Tensor") are excluded from the analysis.
- Validity checks ensure that timestamps are correctly processed.
-
Histogram Generation:
- The script uses Matplotlib to create a histogram that visualizes the distribution of ownership durations.
- The histogram is styled with a dark background and custom colors for better readability.
-
Highlighting Key Data:
- The top three bins in the histogram are highlighted with distinct colors for emphasis.
-
Chart Customization:
- Custom titles, axis labels, and tick parameters enhance the chart's readability.
- A watermark ("Arctic Frenz") is added for branding and authenticity.
-
Generation Metadata and Saving:
- The chart includes a footnote with the generation date and time.
- The final histogram is saved as a PNG file (
collection/histogram.png).
CLICK TO EXPAND Python Script
import matplotlib.pyplot as plt
from datetime import datetime
import json
import numpy as np
file_path = 'collection/by-NFT.json'
with open(file_path, 'r') as file:
nft_data = json.load(file)
def plot_nft_ownership_histogram(nft_data, bins=30):
def calculate_ownership_duration(acquired_timestamp):
acquired_date = datetime.utcfromtimestamp(acquired_timestamp)
current_date = datetime.utcnow()
return (current_date - acquired_date).days
def is_valid_unix_timestamp(timestamp):
try:
_ = datetime.utcfromtimestamp(int(timestamp))
return True
except (ValueError, OverflowError, TypeError):
return False
ownership_durations = []
for nft in nft_data:
holder_data = nft.get('holderData', {})
holder = holder_data.get('holderAddress', "")
when_acquired = holder_data.get('whenAcquired', None)
if holder not in ["Magic Eden V2 Authority", "4zdNGgAtFsW1cQgHqkiWyRsxaAgxrSRRynnuunxzjxue", "1BWutmTvYPwDtmw9abTkS4Ssr8no61spGAvW1X6NDix"] and when_acquired and is_valid_unix_timestamp(when_acquired):
duration = calculate_ownership_duration(when_acquired)
if duration >= 0:
ownership_durations.append(duration)
plt.style.use('dark_background')
fig, ax = plt.subplots(figsize=(10, 8))
plt.subplots_adjust(bottom=0.25)
n, bins, patches_hist = ax.hist(ownership_durations, bins=bins, color='#0D47A1', edgecolor='#B3E5FC')
max_bin_indices = np.argsort(n)[-3:]
colors = ['#FFC71F', '#CC9A05', '#997304']
for i, index in enumerate(max_bin_indices[::-1]):
patches_hist[index].set_facecolor(colors[i])
ax.set_title('Collection Name\nDistribution of NFT Ownership Durations', fontsize=16, color='#E0E0E0')
ax.set_xlabel('Length of Ownership (Days)', fontsize=14, color='#E0E0E0')
ax.set_ylabel('Number of NFTs', fontsize=14, color='#E0E0E0')
ax.tick_params(axis='x', colors='#E0E0E0', labelsize=12)
ax.tick_params(axis='y', colors='#E0E0E0', labelsize=12)
ax.text(0.5, 0.5, 'Arctic Frenz', fontsize=70, color='gray', alpha=0.2,
ha='center', va='center', rotation=30, transform=ax.transAxes)
generation_time = datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S UTC")
footnote_text = f"Chart generated on: {generation_time}\nThis analysis did not include NFTs listed on Magic Eden and Tensor."
fig.text(0.05, 0.1, footnote_text, fontsize=10, color='#E0E0E0')
ax.grid(axis='y', alpha=0.65, color='#E0E0E0')
save_path = 'collection/histogram.png'
try:
plt.savefig(save_path, format='png', bbox_inches='tight')
plt.close(fig)
except Exception as e:
print(f"Error saving file: {e}")
plot_nft_ownership_histogram(nft_data)CLICK TO EXPAND Histogram
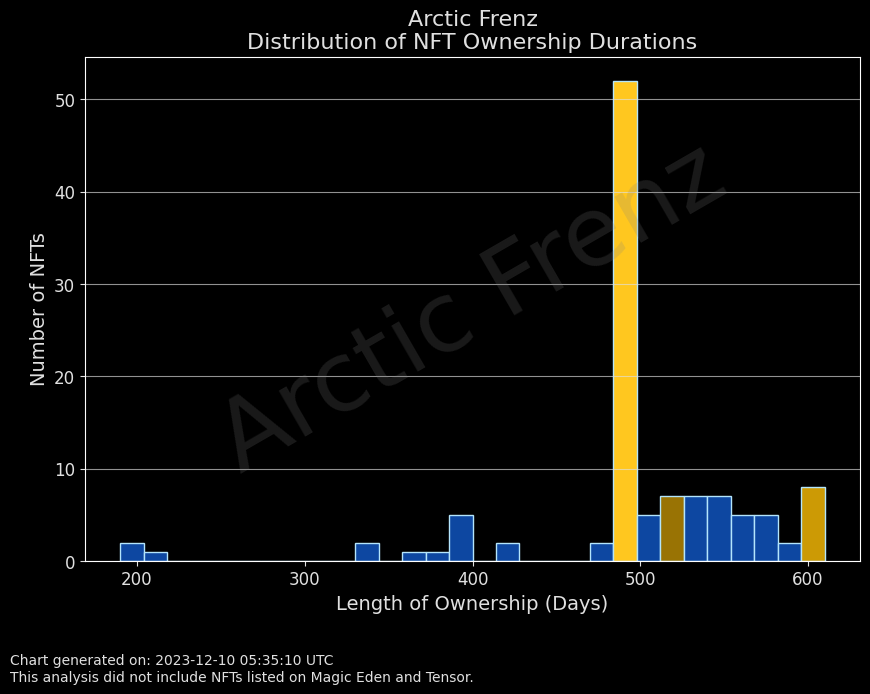
|