Description
What version of Go are you using (go version)?
go version go1.9.3 darwin/amd64
Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (go env)?
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/<redacted>/Dev/go"
GORACE=""
GOROOT="/usr/local/go"
GOTOOLDIR="/usr/local/go/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/cd/_7rcv5812531s2lswhn6kp680000gp/T/go-build436968147=/tmp/go-build -gno-record-gcc-switches -fno-common"
CXX="clang++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
Also happened on linux/amd64, see below.
What did you do?
A bug in production showed an http2 client hanging more than 250 seconds without respect to the request context which was set to timeout after 5 sec.
All possible timeouts are set on connection and TLS handshake and I didn't see many dials (they are monitored).
Latency graph in ms:
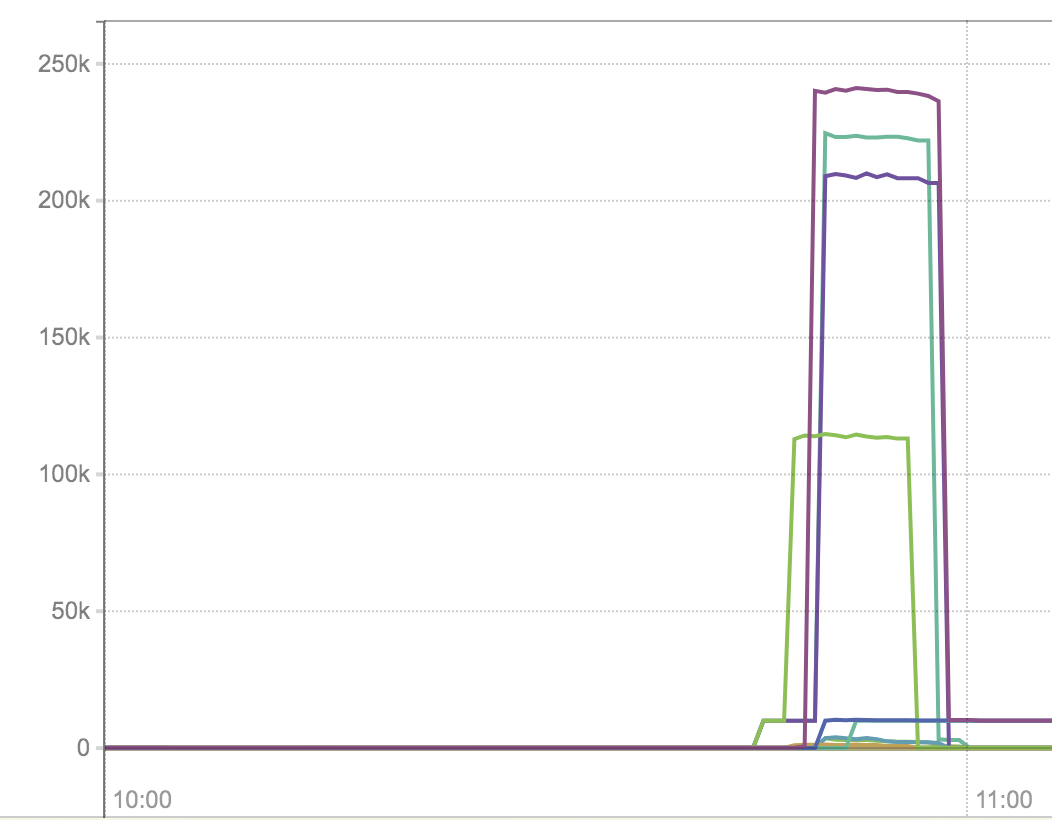
Clients are using net/http2.Transport directly.
What did you expect to see?
The requests should have timed out after 5s.
What did you see instead?
No or very long timeouts (I believe the server has reset the connection or TCP timed out).
The synchronous write cc.writeHeaders to the connection in ClientConn.roundTrip does not set any deadline on the connection which can block forever (or being timed out by TCP) if the server or network hangs:
https://github.com/golang/net/blob/0ed95abb35c445290478a5348a7b38bb154135fd/http2/transport.go#L833
I wrote a test that demonstrates this:
gwik/net@e4c191a
// TestTransportTimeoutServerHangs demonstrates that client can hang forever
// when the server hangs and the headers exceed the conn buffer size (forcing a
// flush). Without respect to the context's deadline.
func TestTransportTimeoutServerHangs(t *testing.T) {
clientDone := make(chan struct{})
ct := newClientTester(t)
ct.client = func() error {
defer ct.cc.(*net.TCPConn).CloseWrite()
defer close(clientDone)
buf := make([]byte, 1<<19)
_, err := rand.Read(buf)
if err != nil {
t.Fatal("fail to gen random data")
}
headerVal := hex.EncodeToString(buf)
req, err := http.NewRequest("PUT", "https://dummy.tld/", nil)
if err != nil {
return err
}
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
req = req.WithContext(ctx)
req.Header.Add("Authorization", headerVal)
_, err = ct.tr.RoundTrip(req)
if err == nil {
return errors.New("error should not be nil")
}
if ne, ok := err.(net.Error); !ok || !ne.Timeout() {
return fmt.Errorf("error should be a net error timeout was: +%v", err)
}
return nil
}
ct.server = func() error {
ct.greet()
select {
case <-time.After(5 * time.Second):
case <-clientDone:
}
return nil
}
ct.run()
}Setting the write deadline fixes the test:
gwik/net@052de95
It seems to fail when the header value exceeds 1MB. I might miss something here, the default buffer size of bufio.Writer is 4096 bytes, I had expected to see it fail around that value, maybe compression and/or TCP buffers...
Also I don't think it sent 1MB headers when it failed in production something else must have fill the buffer.
The buffer is on the connection and shared among streams the buffer can be filled by other requests on the same connection.
Besides this particular call which is synchronous, no write nor read to the connection has a deadline set. Can't this lead to goroutine leaks and http2 streams being stuck in the background ?