sync: Mutex performance collapses with high concurrency #33747
Comments
|
CC @dvyukov |
|
(Thanks for the fantastic bug report, as usual :) Just a few quick points of clarification to make sure I'm interpreting the graphs right:
The output of |
|
(Thanks for pointing me in the right direction!) On (1), yes, that's my understanding of the hardware. On (2), it has two NUMA nodes. I've included the output of If those are confounding factors, I can also try to reproduce the result on one NUMA node with hyper-threading disabled. This hardware reflects a typical deployment of our services, which often run on "the largest possible instance". Here it's a c5.24xlarge with Amazon Linux 2. I've seen the problem I'm trying to describe on c4.8xlarge and c5.9xlarge instances (36 vCPUs), and on dual-socket machines (with 2 NUMA nodes) on premises that have between 20 and 40 hyper-threads. On (3), I'm not doing anything special with CPU affinity. The charts are based on the output of Go 1.9 raw data from 43–51 workers
|
|
I wonder: Is it a coincidence that the cutoff is right around the number of physical cores? Do you have source handy for this benchmark? [... yes, it's in the post, i didn't know Github had those little expandy-arrow things.] It might be instructive to try it on different hardware. For instance, if it started happening around 30ish goroutines on a 32-core platform... Although it seems really unlikely that a performance degradation that severe would happen around 8 concurrent workers on a typical laptop, without someone noticing it. Update: On my laptop (Xeon of some sort, 4 physical cores, 8 "CPUs"): ~570us at concurrency=1, drops to about 144us at concurrency=5, does not degrade even at concurrency and GOMAXPROCS of 80+. So I think I actually don't hit whatever's causing this. Speculation: CPU hardware feature that changes behavior for some N. |
|
According to the change description for https://golang.org/cl/34310, “Unfair wait time is now limited to 1ms.” Your collapse appears to begin at around 28 workers. At a quick calculation, 1ms / 28 workers ≈ 35.7 μs / worker. You note that a collapsed lock takes “about 60–70μs” per handoff, which is well above that 35.7μs threshold: certainly enough to keep a lock that is already in “starvation mode” stuck there in the steady state. Moreover, driving such a lock back into the unfair regime would require dropping to only ~17 workers — which roughly corresponds to the start of the nonlinear part of your reported performance curve. So here's my (untested) hypothesis: at 28 workers, you're close enough to the unfair-wait threshold that some interruption — perhaps an unusually long GC pause, or perhaps an OS scheduling event — drives the lock into starvation mode, and the increased cost is sufficient to keep it there until load decreases well below the initial breakdown threshold. |
|
Would it make sense to have the |
|
In the benchmark there is the following line: "workers := 4 *
runtime.GOMAXPROCS(0)" line. Doesn't this end up putting 4 goroutines
on each proc which seems contradictory to the prose which indicates 1
per proc. Am I missing something or is it just a cut paste fumble
finger problem?
suite := func(newLock func() sync.Locker) func(b *testing.B) {
return func(b *testing.B) {
workers := 4 * runtime.GOMAXPROCS(0) <<<<<<<<<<<<
cost, ratio := *cost, *ratio
var concurrencies []int
…On Thu, Aug 22, 2019 at 12:29 AM Carlo Alberto Ferraris < ***@***.***> wrote:
Would it make sense to have the Unlock slow path directly yield its P to
start running the next G that was waiting to acquire the mutex?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#33747?email_source=notifications&email_token=AAHNNH76XE7UHRLRJ6CDWRDQFYI3RA5CNFSM4IN67ZL2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4324QQ#issuecomment-523742786>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAHNNH5KX6PD3JDR5XERV3DQFYI3RANCNFSM4IN67ZLQ>
.
|
|
@RLH the work is split into 4xGOMAXPROCS pieces, but the number of goroutines that are allowed to concurrently execute that work is controlled by a semaphore ( |
|
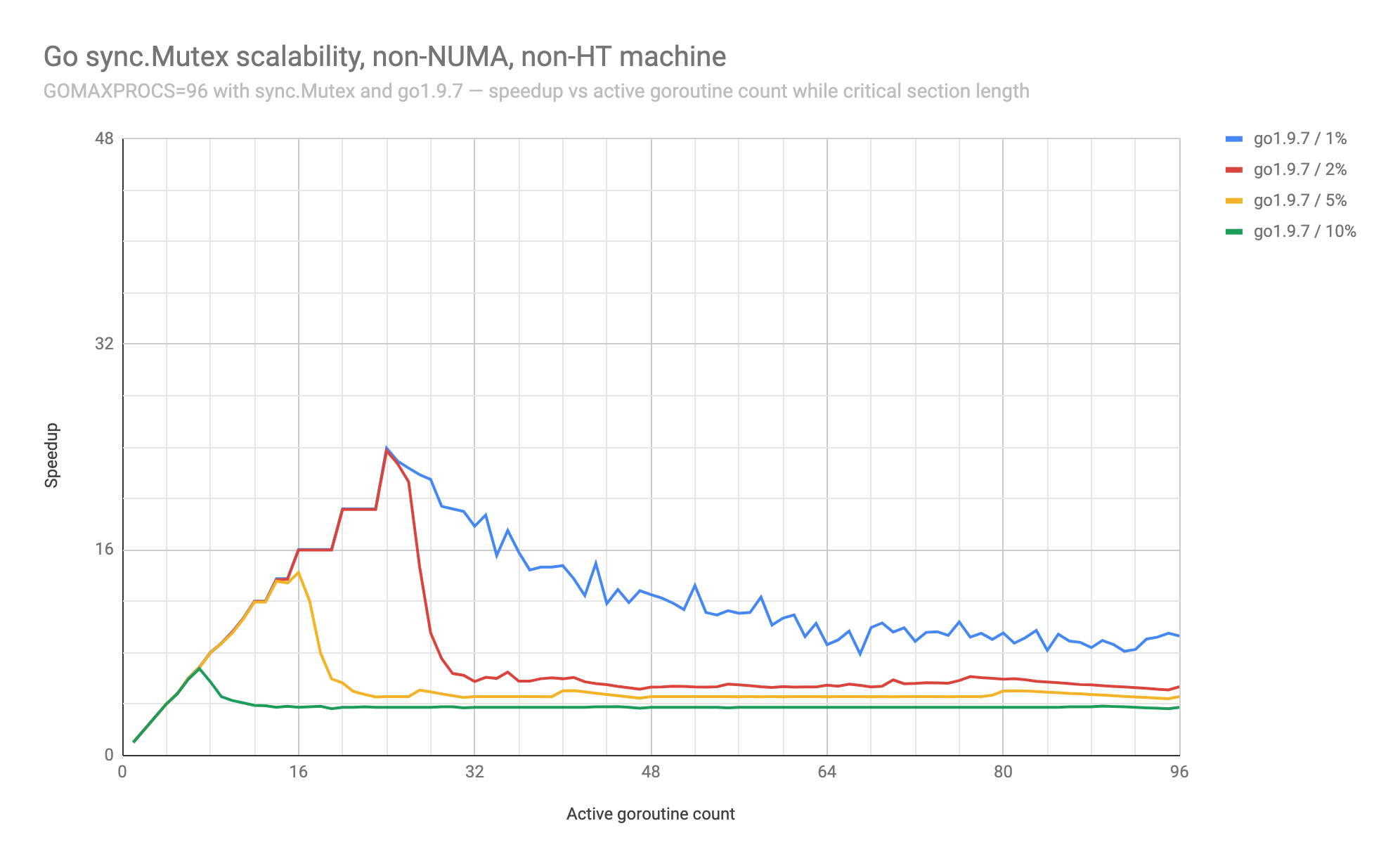
@seebs the point of collapse is based on the tuning of the benchmark (via the With 10% of execution taking place in the critical section, the performance gets to about 7x before falling back to 4x. There's no dramatic collapse if it's not preceded by good optimal performance. It's hard to see that with only 8 cores on a laptop. On a machine with two NUMA nodes, each with 24 physical cores with two hyper-threads each, totaling 96 logical cores (c5.24xlarge):
|


|
Huh, that's interesting. I think I was expecting that the collapse would look something like going to half the previous performance or lower, but actually, it looks like it's pretty steady at dropping to about 4-6x performance. So if your hardware really only got 4-6x in the first place, it doesn't look like much of anything happening. I do see a noticeable difference between Gosched and non-GoSched performance at higher ratios, but it's never particularly large; it might be 10% at most. I think I was assuming that, on the smaller machine, performance would collapse to something more like 1x-2x, but it doesn't seem to. |
When we have already assigned the semaphore ticket to a specific waiter, we want to get the waiter running as fast as possible since no other G waiting on the semaphore can acquire it optimistically. The net effect is that, when a sync.Mutex is contented, the code in the critical section guarded by the Mutex gets a priority boost. Fixes golang#33747 Change-Id: I9967f0f763c25504010651bdd7f944ee0189cd45
When we have already assigned the semaphore ticket to a specific waiter, we want to get the waiter running as fast as possible since no other G waiting on the semaphore can acquire it optimistically. The net effect is that, when a sync.Mutex is contented, the code in the critical section guarded by the Mutex gets a priority boost. Fixes golang#33747 Change-Id: I9967f0f763c25504010651bdd7f944ee0189cd45
|
Change https://golang.org/cl/200577 mentions this issue: |
|
@rhysh would you be able to test https://golang.org/cl/200577 and see if it improves things for you as welll? |
|
Thanks @CAFxX , CL 200577 at PS 7 looks like it fixes the collapse. I re-ran the benchmark with the current tip (f6c624a / The code looks well focused to the problem, and the results LGTM. Thanks again! Folks with +2 votes / release discretion: are there blockers or risks that would keep this out of Go 1.14?
benchstatname old time/op new time/op delta Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=1/basic-96 354µs ± 0% 356µs ± 1% +0.64% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=2/basic-96 178µs ± 1% 180µs ± 1% +0.66% (p=0.015 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=3/basic-96 121µs ± 1% 122µs ± 1% ~ (p=0.203 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=4/basic-96 92.3µs ± 2% 92.4µs ± 1% ~ (p=0.529 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=5/basic-96 75.1µs ± 2% 75.8µs ± 3% ~ (p=0.247 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=6/basic-96 63.0µs ± 2% 63.1µs ± 2% ~ (p=0.912 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=7/basic-96 54.1µs ± 0% 54.1µs ± 1% ~ (p=0.758 n=7+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=8/basic-96 47.4µs ± 0% 47.9µs ± 2% +1.04% (p=0.027 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=9/basic-96 42.4µs ± 0% 42.7µs ± 1% +0.65% (p=0.000 n=9+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=10/basic-96 38.5µs ± 1% 38.6µs ± 1% ~ (p=0.139 n=9+8) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=11/basic-96 35.2µs ± 3% 35.2µs ± 1% ~ (p=0.579 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=12/basic-96 32.4µs ± 3% 32.1µs ± 2% ~ (p=0.436 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=13/basic-96 30.2µs ± 2% 30.0µs ± 2% ~ (p=0.353 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=14/basic-96 27.7µs ± 0% 27.9µs ± 1% +0.67% (p=0.000 n=7+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=15/basic-96 26.0µs ± 2% 26.1µs ± 3% ~ (p=0.325 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=16/basic-96 24.7µs ± 0% 24.3µs ± 3% ~ (p=0.573 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=17/basic-96 23.0µs ± 3% 22.9µs ± 1% ~ (p=0.156 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=18/basic-96 22.2µs ± 4% 22.1µs ± 3% ~ (p=0.631 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=19/basic-96 20.8µs ± 0% 20.9µs ± 1% +0.50% (p=0.001 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=20/basic-96 20.0µs ± 3% 20.1µs ± 2% ~ (p=0.436 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=21/basic-96 19.1µs ± 2% 18.9µs ± 0% ~ (p=0.535 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=22/basic-96 18.1µs ± 2% 18.0µs ± 2% ~ (p=0.863 n=9+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=23/basic-96 17.6µs ± 2% 17.2µs ± 1% -2.37% (p=0.000 n=8+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=24/basic-96 17.2µs ± 6% 16.6µs ± 4% -3.56% (p=0.013 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=25/basic-96 16.3µs ± 3% 16.1µs ± 2% -1.72% (p=0.028 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=26/basic-96 15.6µs ± 7% 15.5µs ± 5% ~ (p=0.796 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=27/basic-96 15.4µs ± 6% 15.0µs ± 1% -2.17% (p=0.021 n=9+8) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=28/basic-96 15.6µs ± 7% 14.1µs ± 1% -9.71% (p=0.000 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=29/basic-96 15.0µs ±12% 14.0µs ± 0% -6.87% (p=0.000 n=10+8) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=30/basic-96 14.4µs ± 6% 13.7µs ±11% -5.24% (p=0.023 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=31/basic-96 14.8µs ±13% 13.7µs ±11% -7.37% (p=0.023 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=32/basic-96 13.8µs ± 7% 13.0µs ± 2% -5.34% (p=0.002 n=9+8) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=33/basic-96 14.5µs ±10% 12.3µs ± 4% -15.12% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=34/basic-96 17.0µs ±33% 12.2µs ± 2% -28.46% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=35/basic-96 17.2µs ±44% 11.6µs ± 6% -33.00% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=36/basic-96 20.2µs ±27% 11.4µs ± 7% -43.38% (p=0.000 n=8+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=37/basic-96 23.0µs ±49% 11.1µs ± 1% -51.51% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=38/basic-96 39.1µs ±57% 11.1µs ± 2% -71.58% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=39/basic-96 39.5µs ±21% 10.7µs ± 6% -72.88% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=40/basic-96 52.3µs ±40% 10.5µs ± 4% -79.84% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=41/basic-96 57.8µs ±25% 10.2µs ± 2% -82.28% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=42/basic-96 61.4µs ±19% 10.5µs ± 4% -82.91% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=43/basic-96 61.0µs ±26% 9.5µs ± 5% -84.44% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=44/basic-96 66.2µs ± 6% 9.6µs ±15% -85.42% (p=0.000 n=9+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=45/basic-96 66.8µs ± 4% 10.7µs ±11% -84.00% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=46/basic-96 64.9µs ± 5% 9.9µs ± 6% -84.74% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=47/basic-96 66.4µs ±12% 10.1µs ± 8% -84.73% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=48/basic-96 66.3µs ±11% 10.0µs ± 9% -84.89% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=49/basic-96 67.8µs ± 5% 10.1µs ±10% -85.14% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=50/basic-96 67.4µs ± 5% 10.1µs ± 6% -85.05% (p=0.000 n=9+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=51/basic-96 66.9µs ± 6% 9.9µs ± 5% -85.19% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=52/basic-96 67.9µs ± 4% 10.1µs ± 3% -85.15% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=53/basic-96 67.2µs ± 5% 11.3µs ±10% -83.10% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=54/basic-96 67.4µs ± 5% 11.0µs ±15% -83.70% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=55/basic-96 65.5µs ± 7% 10.0µs ± 2% -84.77% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=56/basic-96 67.1µs ± 8% 11.6µs ±11% -82.66% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=57/basic-96 68.6µs ± 4% 11.8µs ± 7% -82.80% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=58/basic-96 68.1µs ± 5% 10.5µs ± 7% -84.57% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=59/basic-96 68.1µs ± 6% 10.9µs ± 9% -83.95% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=60/basic-96 66.3µs ± 6% 13.4µs ± 3% -79.77% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=61/basic-96 66.0µs ± 8% 12.7µs ±13% -80.76% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=62/basic-96 66.1µs ± 5% 13.0µs ± 7% -80.35% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=63/basic-96 67.5µs ± 5% 13.1µs ± 9% -80.56% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=64/basic-96 68.0µs ± 5% 12.1µs ± 4% -82.15% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=65/basic-96 67.4µs ± 8% 12.2µs ± 7% -81.87% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=66/basic-96 68.5µs ± 4% 11.7µs ± 6% -82.95% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=67/basic-96 67.3µs ± 7% 11.9µs ± 8% -82.38% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=68/basic-96 67.7µs ± 6% 11.5µs ±10% -82.97% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=69/basic-96 68.1µs ± 4% 10.8µs ± 9% -84.16% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=70/basic-96 67.2µs ± 4% 10.5µs ± 5% -84.43% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=71/basic-96 67.2µs ± 5% 11.0µs ± 9% -83.70% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=72/basic-96 68.2µs ± 4% 11.9µs ± 9% -82.62% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=73/basic-96 66.4µs ± 7% 11.2µs ±11% -83.08% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=74/basic-96 67.7µs ± 6% 10.9µs ± 6% -83.93% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=75/basic-96 67.5µs ± 6% 11.6µs ± 7% -82.86% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=76/basic-96 69.8µs ± 3% 12.6µs ± 5% -81.93% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=77/basic-96 69.0µs ± 5% 11.7µs ± 9% -83.07% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=78/basic-96 68.5µs ± 3% 11.1µs ± 6% -83.83% (p=0.000 n=10+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=79/basic-96 68.6µs ± 5% 10.5µs ± 8% -84.65% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=80/basic-96 68.8µs ± 7% 11.0µs ±13% -83.95% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=81/basic-96 66.8µs ± 5% 10.7µs ± 6% -84.01% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=82/basic-96 69.2µs ± 7% 11.1µs ± 9% -83.90% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=83/basic-96 67.0µs ± 6% 11.4µs ±12% -83.05% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=84/basic-96 67.1µs ± 5% 10.8µs ± 7% -83.90% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=85/basic-96 67.9µs ± 7% 10.8µs ± 9% -84.13% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=86/basic-96 66.9µs ± 5% 10.7µs ± 5% -84.08% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=87/basic-96 69.3µs ± 3% 10.6µs ± 4% -84.70% (p=0.000 n=9+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=88/basic-96 67.5µs ± 7% 11.0µs ± 6% -83.72% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=89/basic-96 66.6µs ± 6% 11.5µs ± 9% -82.76% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=90/basic-96 67.4µs ± 6% 11.1µs ± 6% -83.55% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=91/basic-96 68.4µs ± 4% 11.1µs ± 5% -83.80% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=92/basic-96 66.8µs ± 3% 10.9µs ± 4% -83.74% (p=0.000 n=9+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=93/basic-96 68.1µs ± 2% 10.9µs ± 4% -83.95% (p=0.000 n=7+9) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=94/basic-96 66.5µs ± 6% 11.0µs ± 2% -83.45% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=95/basic-96 67.6µs ± 5% 11.1µs ± 1% -83.62% (p=0.000 n=10+10) Lock/sync.Mutex/cost=1000,ratio=0.010,concurrency=96/basic-96 68.9µs ± 5% 10.5µs ± 3% -84.83% (p=0.000 n=10+10) |

|
Thanks @rhysh for the confirmation!
We haven't given this a run through the builders yet, but I'm hopeful. |
When we have already assigned the semaphore ticket to a specific waiter, we want to get the waiter running as fast as possible since no other G waiting on the semaphore can acquire it optimistically. The net effect is that, when a sync.Mutex is contented, the code in the critical section guarded by the Mutex gets a priority boost. Fixes golang#33747 Change-Id: I9967f0f763c25504010651bdd7f944ee0189cd45
When we have already assigned the semaphore ticket to a specific waiter, we want to get the waiter running as fast as possible since no other G waiting on the semaphore can acquire it optimistically. The net effect is that, when a sync.Mutex is contented, the code in the critical section guarded by the Mutex gets a priority boost. Fixes golang#33747 Change-Id: I9967f0f763c25504010651bdd7f944ee0189cd45
|
Change https://golang.org/cl/205817 mentions this issue: |
|
Should this be re-opened given that the change was reverted? |
|
The revert is not merged yet, but yes, it should be re-opened. |
This reverts CL 200577. Reason for revert: broke linux-arm64-packet and solaris-amd64-oraclerel builders Fixes #35424 Updates #33747 Change-Id: I2575fd84d37995d458183caae54704f15d8b8426 Reviewed-on: https://go-review.googlesource.com/c/go/+/205817 Run-TryBot: Bryan C. Mills <bcmills@google.com> Reviewed-by: Brad Fitzpatrick <bradfitz@golang.org>
|
All the failures I've looked at in detail come from I have a linux / arm64 machine for testing, but it only occasionally reproduces the failure (with After adding a check of |
|
Change https://golang.org/cl/206180 mentions this issue: |
Some of the Go services I work with run on large machines, often with
runtime.NumCPUreporting around 20–40 logical CPUs. They typically leave GOMAXPROCS at its default (high) value, so a single server process can use the entire machine.The services handle inbound HTTP requests. For each inbound request, the services make some number outbound calls, wait for the responses, do calculations, and possibly make additional outbound calls. In these services, GOMAXPROCS is constant, the arrival rate of requests is subject to external forces, and the resulting concurrency—how many requests is the process handling at this moment—is controlled by how quickly the process responds to each request. (This sets them apart from worker-style programs that might poll a queue for new jobs.)
Starting with the Go 1.9 release, I've seen this type of service occasionally encounter sudden and severe lock contention.
I suspect this is related to the "starvation" mode added in Go 1.9, described in the release notes as "Mutex is now more fair". Just as Go 1.9's "starvation mode" change traded raw performance for more consistent behavior (fixing cases of pathological tail latency), our services need more consistent performance here. The applications sometimes use third-party packages that use
sync.Mutexto protect internal state, and our options for responding to sudden contention there are limited.This looks a bit different from what's described in Non-scalable locks are dangerous since
sync.Mutexonly briefly spins before registering with a runtime semaphore. Those semaphores appear to be sharded, and to be protected by MCS locks.When the microbenchmark's performance collapses, the execution trace shows that handing off the lock (from when the call to
Unlockstarts through to when the next goroutine's call toLockis about to return) takes about 60–70µs.CC @aclements
What version of Go are you using (
go version)?I've run the benchmark with go1.8.7, go1.9.7, go1.12.7, and go1.13beta1 on linux/amd64.
Does this issue reproduce with the latest release?
Yes
What operating system and processor architecture are you using (
go env)?The benchmark data is from an amd64 / x86_64 machine running Linux 4.14.
What did you do?
I built a micro-benchmark that is parallelizable except for a specific critical section. The default parameters of this benchmark are for each task to take about 350µs and to hold the shared lock for 1% of that time, about 3.5µs.
I ran the benchmark on a machine with 96 logical cores. I left GOMAXPROCS at the default of 96, and I varied the number of worker goroutines from 1 to 96. This mirrors the behavior of our RPC services, where the program is allowed to use all available hardware but the effective concurrency varies as the program runs.
What did you expect to see?
Since the critical section is short (1% of task cost), I expect that two goroutines will be able to process work at nearly double the speed of a single worker, and that 10 goroutines will have nearly 10x performance. (A speedup of 9x or 8x would also be acceptable.) I expect that adding worker goroutines will have diminishing returns, particularly once there's a goroutine per physical core (48 in this case) or when the rate at which the whole process completes tasks gets close to the length of the critical section. I expect that adding a worker goroutine won't significantly decrease the aggregate processing speed.
What did you see instead?
The following chart shows the results of running the test with a few versions of Go, each normalized so the performance of the single-goroutine case is defined as 1.
Go 1.8 has nearly linear performance up to 41 workers, finishing work at about 35x the rate of a single goroutine. After that, performance ranges from 28x to 37x.
The behavior of Go 1.9 is very different. It has nearly linear performance up to 45 workers (38x baseline), but with 46 workers its performance plummets to 12x baseline. At 51 workers it's at about 6x baseline, and after that its performance is about 5x baseline.
For Go 1.12 and Go 1.13 (beta), the benchmark includes user annotations via the runtime/trace package. Their performance is nearly linear until 28 workers (24x baseline), and have a more gradual fall back to 5x baseline with 44 workers.
The behavior of Go 1.8 is what I expect. With Go 1.9 and later, this sort of performance collapse means that a temporary increase in concurrency to a server can lead to a significant decrease in its performance, which causes a more permanent increase in concurrency.
(The parameters I used for the benchmark demonstrated collapse around concurrency of 32 to 48, but they can be tuned to show collapse at other points.)
This next image shows additional results.
Using a channel as a lock and building a scalable / non-collapsing MCS lock both have poor but consistent performance. They show linear increase until concurrency and speedup are both at 5 or 6, and then continue to have speedup of 5 up through concurrency of 96.
However, adding an explicit call to
runtime.Goschedwhen releasing the lock results in consistent and good performance (similar to Go 1.8's behavior described above) for all lock types:sync.Mutex, channel, and MCS.$ cat ./lock_test.go$ cat ./lock_trace_go111_test.goThe text was updated successfully, but these errors were encountered: