6. Architecture
The design and development of ChronoKeeper and ChronoGrapher components follow the distributed Story Pipeline Data Model
Story is a time-series data set that is composed of individual log events that the client processes running on various HPC nodes generate over time and assign to the story of their choice. Every log event is identified by the StoryId of the story it belongs to, the ClientId of the application that generated it and the timestamp that ChronoLog Client library generates at the moment it takes ownership of the log event (we also augment the timestamp with the client specific index to handle the case of the same timestamp being generated on different threads of client application). As the time goes on the event travels through the different tiers of the ChronoLog data collection pipeline: ChronoKeeper processes running on the compute nodes being the first tier, ChronoGrapher processes running on the storage nodes - the second tier, and eventually makes it to the third tier represented by the permanent storage layer. Each process involved in collection of the events for the specific story assumes ownership of the events for some duration of time and while it has the ownership it does its best to group events by StoryId and timestamp into appropriate StoryChunks.
StoryChunk is a set of events for the same story that fall into the time range [start_time, end_time) including the start_time and excluding the end_time, events within the StoryChunk are ordered by the event_sequence=(timestamp + ClientId + index).
StoryPipeline is the set of StoryChunks ordered by their start_time values. For any Story with active contributors and/or consumers segments of the StroyPipeline can be distributed over several processes, nodes, and tiers at any moment in time (see the Story Pipeline Model illustration below).

ChronoKeeper retains ownership of the specific StoryChunk for the duration of a configurable acceptance window to accommodate for the network delays in event arrival time, and when the window expires it sends the StoryChunk to the ChronoGrapher. Because each client application can send log events to multiple ChronoKeepers, each ChronoKeeper involved in the same story recording can only have the subset of the story events for the same time range. When the ChronoGrapher process receives these partial StoryChunks for the same Story it takes responsibility for merging the partial StoryChunks into its StoryPipeline. StoryChunks in the ChronoGrapher segment of the StoryPipeline are likely to have longer time ranges (granularity) and longer acceptance window as the ChronoGraphers. When the acceptance window period for the merged StoryChunk under ChronoGrapher responsibility expires the ChronoGrapher extracts it into a persistent storage format and records it into the persistent storage layer.
Using a group of ChronoKeepers running on different HPC nodes to record individual events from multiple clients for the same Story allows us to distribute the immediate indigestion of events and parallelize early sequencing of the events into partial StoryChunks over different HPC nodes. Moving of the events in presorted batches that the StoryChunks are instead of moving individual events between the compute and storage nodes providers for higher overall throughput of event data across the network.
ChronoVisor is the orchestrating component of ChronoLog system. There’s only one ChronoVisor process in the ChronoLog system deployment, usually installed on its own node.
ChronoVisor acts as the client-facing portal managing the client connections and data access requests and it also maintains the registry of active recording processes and distributes the load of data recording between the recording process groups.
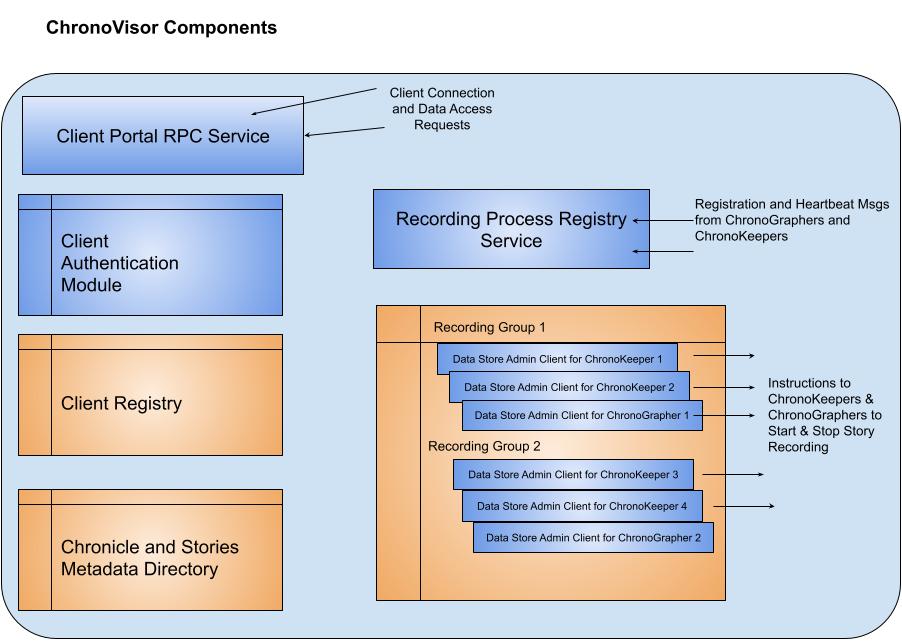
- Client Portal RPC Service manages communication sessions between the client applications and ChronoVisor using a multithreaded engine for efficient concurrent connections.
- Client Authentication Module authenticates the clients before they are granted access to data. We are using the operating system's authentication in the 1st ChronoLog release. We plan to implement role-based authentication in later releases.
- Client Registry keeps track of all active client connections and clients’ data acquisition requests for Chronicle and Stories.
- RecordingProcessRegistryService listens to RPC Registration and Heartbeat/Statistics messages coming from ChronoKeeper and ChronoGrapher processes and passes these messages to the Recording Group Registry to act upon.
- Recording Group Registry monitors and manages the Recording Groups process composition and activity status. ChronoVisor uses this information to distribute the load of data recording and management by assigning the newly acquired story to the specific recording group using uniform distribution algorithm. Recording Group Registry maintains DataStoreAdminClient connection to all the registered ChronoKeepers and ChronoGraphers and uses them to issue RPC notifications about the start and stop of the specific story recording to all the recording processes involved.
- Chronicle and Story Meta Directory manages the Chronicle and Story metadata for the ChronoLog system, coordinating with Client Registry to keep track of client data acquisition sessions for the specific Chronicles and Stories and with the RecordingGroup Registry for distributing data access tasks between the recording process groups.
ChronoKeeper is the component responsible for fast ingestion of the log events coming from the client processes, efficiently grouping them into partial StoryChunks and moving them down to the lower tier of ChronoLog system.
Most ChronoLog deployments would have ChronoKeeper processes installed on the majority of the compute nodes and each Recording Group is expected to have multiple ChronoKeeper processes.

- Keeper Data Store is the main ChronoKeeper module. Keeper Data Store is the collection of Story Pipelines for all the actively recorded stories for the Recording Group that this ChronoKeeper process is part of. Keeper Data Store instantiates the Story Pipeline for the specific Story when the ChronoKeeper receives StartStoryRecording notification for this Story and dismantles the Story Pipeline shortly after being notified to StropStoryRecording. The Keeper Data Store sequencing threads are responsible for sequencing the ingested log events and grouping them into the time-range bound StoryChunks. (See ChronoLog Story Pipeline Data Model for reference)
- Keeper Recording Service listens to the incoming streams of log events from the client applications and passes the events to the Ingestion Queue module for processing.
- Ingestion Queue module is a collection of IngestionHandles for actively recorded stories the ChronoKeeper is expecting the events for. Ingestion Queue gets the log events from the Keeper Recording Service and attributes them to the appropriate Story Ingestion Handles. Story Ingestion Handle is part of the Story Pipeline object that is exposed to the Ingestion Queue at the time of Story Pipeline instantiation.
- StoryChunk Extraction Queue is a mutex-protected deque of StoryChunk pointers, serving as the communication boundary between Keeper Data Store and StoryChunk Extractor modules.
- StoryChunk Extractors ChronoKeeper has two types of StoryChunk Extractors currently implemented: CSVFileStoryChunkExtractor writes retired StoryChunks to a configurable local POSIX directory. StoryChunkExtractorRDMA drains retired StoryChunks to the ChronoGrapher over an RDMA communication channel. The StoryChunk Extractors can be chained if needed.
- KeeperRegistryClient is the client side of RPC communication between the ChronoKeeper process and ChronoVisor’s Recording Process Registry Service. KeeperRegistryClient sends out Register/Unregister and Heartbeat/Statistics messages to the ChronoVisor.
- DataStoreAdminService is the service listening to the Start/Stop Story recording notifications from the ChronoVisor, these notifications trigger instantiation or dismantling of the appropriate StoryPipelines based on the clients data access requests.
ChronoGrapher is the component that continues the job of sequencing and merging of the partial StoryChunks created by the ChronoKeepers on the first tier, assembling the complete time-range bound StoryChunks out of them, and archiving the complete StoryChunks into the persistent storage tier.
The ChronoGrapher design follows the StoryPipeline Data Model and mirrors the design of the ChronoKeeper. The ChronoLog deployment allows for only one ChronoGrapher process within the RecordingGroup, and it’s usually deployed on the storage node.

- Recording Process Registry Client is the client side of RPC communication between the ChronoGrapher process and ChronoVisor’s RecordingProcessRegistryService. RecordingProcessRegistryClient is used to send Register/Unregister and periodic Heartbeat/Statistics messages to the ChronoVisor.
- DataStore Admin Service is the service listening to the Start/Stop Story recording notifications from the ChronoVisor, these notifications trigger instantiation or dismantling of the appropriate StoryPipelines based on the clients data access requests.
- Grapher Recording Service in the RPC service that receives partial StoryChunks from ChronoKeeper processes, using Thallium RDMA communication.
- StoryChunk Ingestion Queue ensures thread-safe communication between the ingestion threads of the Recording Service and the sequencing threads of the Grapher Data Store. Each active StoryPipeline has a pair of active and passive StoryChunkIngestionHandles to manage StoryChunk processing efficiently.
- Grapher Data Store maintains a StoryPipeline for each active story, merging the ingested partial StoryChunks into complete time-range bound StoryChunks and retiring the complete StoryChunks to the Story Chunk Extraction Queue.
- StoryChunk Extraction Queue facilitates thread safe communication boundary between the Grapher Data Store and the Extractor modules as the retired StoryChunks leave their StoryPipelines and wait in the Queue for being picked up by the extractor.
- StoryChunk Archiving Extractor handles the serialization and archiving of StoryChunks from the Story Chunk Extraction Queue to persistent storage.