
Quite intimidating when you look for the meaning of convolution. The idea behind this article is to make this idea of convolutional neural networks (CNN) simple as possible. A convolutional neural network is simply a neural network (NN) with a convolutional network on top of it. The application area of CNNs aims mainly in image recognition for 2-dimensional images. The basic idea is just to print new images with stamps, which are often called filters or even better kernels.

The animation shows all the magic of convolution. In this case, a 3 x 3 filter is initialized with randomly selected weights. During training, these weights are formed according to the direction of the network target, extracting features that allow these networks to achieve much higher accuracy.
The convolution is often followed by the pooling step. Actually, pooling is not necessary, but since a convolutional network creates many of these feature maps, the computational effort is so enormous that it is common practice to reduce the resolution of the outputs. In addition to the max pooling shown in the animation, there is also average pooling and other types of pooling that can be used.
Unlike the common practice, however, I do not use a pooling technique here. Instead, a stride of 2 is used in the convolution, which produces the same output map.
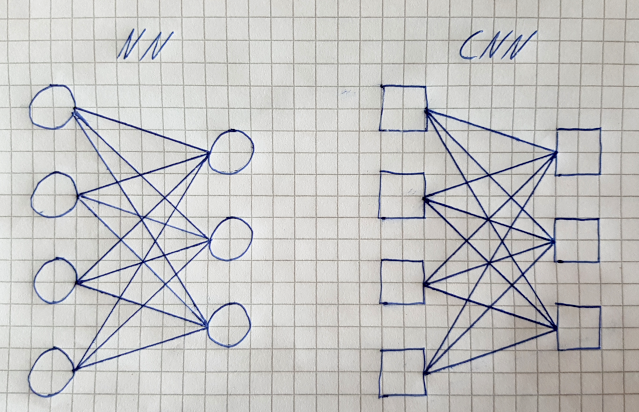
In my mind, neural networks and convolutional networks are quite similar. The NN has an input neuron on the left with its weight connected to an output neuron on the right. The CNN follows the same "fully connected" pattern. Only that it is a whole map of neurons that are connected with a kernel filter consisting of several weights to generate the output map.
To run the demo program, you must have VisualStudio2022 installed on your machine. Then just start a console application with DotNet 6, copy the code and change from debug to release mode and run the demo. MNIST data and network are then managed by the code. This line AutoData d = new(@"C:_mnist\"); specifies where the MNIST dataset is stored. To do this, the data is simply loaded from my github on first use. On future starts the data will be loaded from the directory where it was saved.

Lets take a look at the demo. The CNN in its current form has 3 hyperparameters: Convolution, Filter, Stride. The convolution describes the maps used for each layer. The first layer creates 8 new output maps from the input map through 8 kernel filters. For this a 5 x 5 kernel is used. Additionally a stride of 2 is used to reduce the map size. Each of the eight maps has a dimension of 12 and a resolution of 144 pixels.
These 8 feature maps build on the next layer the input maps which now form with 8 * 16 kernels with a filter size of 3 x 3 to create 16 output maps. Each of the 8 * 144 input maps are now "fully connected" with one kernel to one output map. Thus, 16 new output maps are created with a dimension of 10 and a resolution of 100. The output layer thus has 1600 neurons, which are then sent to the neural network.
You may wonder why I built the network this way. Actually, the reason is essentially due to performance reasons.
The larger 5 x 5 kernel on layer 1 worked very well, but is relatively expensive to compute. The stride of 2 cuts this calculation massively and also reduces the output resolution. Only 8 kernels are used here. The 8 input maps that generate 16 output maps already use 128 filters. Since the size of the filter reduces the calculation time, I have reduced the size here, the stride remains 1.
After the network is ready to start, the training for 20 epochs begins. This means that the entire MNIST dataset of 60,000 examples is simply trained 20 times. After every epoch the learning and momentum rate is decreased by a factor. All this happens on my system in 5 minutes. However, it could take a little longer depending on the computer or laptop used, but it should be possible to estimate this due to the epoch-by-epoch output.
Of course, other network designs are possible, but the one presented worked best among those I tested. Alternatively, I could have used a stride 2 on layer 2 to create more output maps. However, my demo might have ended up at 99.1% or taken 10 minutes.

My CNN approach may be slightly different from the common practice, since usually the dimensions are co-determined, and thus also the size of the last layer that passes its signal to the neural network. For me it makes more sense to do all this automatically during initialization. That is why the first layer of the neural network is also adjusted with every CNN initialization.
With isCNN = false; you only switch off the convolutional network. That means with the first layer and 784 neurons the network now works as a neural network. This is pretty cool I think and 98.5% accuracy is pretty decent when it is only one NN.

If only the neural network in net = { 784, 16, 16, 10 } is trained at only one epoch, this is what comes out. Not spectacular, but exactly the result I have already achieved in 2020. Although this work is completely different in its construction from the one 2 years ago, it was always beneficial to take the old result in order to hopefully assess my current work correctly.
// 4.1 cnn ff
static void ConvolutionForward(int[] cnn, int[] dim, int[] cs, int[] filter, int[] kstep, int[] stride, float[] conv, float[] kernel)
{
for (int i = 0; i < cnn.Length - 1; i++)
{
int left = cnn[i], right = cnn[i + 1], lDim = dim[i], rDim = dim[i + 1], lStep = cs[i + 0], rStep = cs[i + 1],
kd = filter[i], ks = kstep[i], st = stride[i], lMap = lDim * lDim, rMap = rDim * rDim, kMap = kd * kd, sDim = st * lDim;
// convolution
for (int l = 0, ls = lStep; l < left; l++, ls += lMap) // input channel feature map
for (int r = 0, rs = rStep; r < right; r++, rs += rMap) // output channel feature map
{
int k = rs; // output map position
for (int y = 0, w = ks + (l * right + r) * kMap; y < rDim; y++) // conv dim y
for (int x = 0; x < rDim; x++, k++) // conv dim x
{
float sum = 0;
int j = ls + y * sDim + x * st; // input map position for kernel operation
for (int col = 0, fid = 0; col < kd; col++) // filter dim y
for (int row = col * lDim, len = row + kd; row < len; row++, fid++) // filter dim x
sum += conv[j + row] * kernel[w + fid];
conv[k] += sum;
}
}
// relu activation
for (int r = 0, kN = rStep; r < right; r++, kN += rMap) // output maps
for (int k = kN, K = k + rMap; k < K; k++) // conv map
{
float sum = conv[k];
conv[k] = sum > 0 ? sum * left : 0; // relu activation for each neuron
}
}
}My old approach to running through neural networks was always perceptron wise. My thinking was also kind of gradual. Which was not necessarily advantageous. But all the small steps probably overwhelmed me at first, looking back.
This is probably the biggest trick that made this work possible in first place. The forward process was still an idea for me at the time. In the meantime it has changed and I divide the process into 2 basic steps. First, the perceptron wise way was changed into the layer wise computation. In addition, all positions (input map, kernel, outputmap) are needed. An army of arrays is used for this.
Then it is always the same, the algorithm starts with the input layer, 784 neurons in our case and then calculates with the respective kernel the desired output map number. After that all outmap neurons are activated. If another layer follows during the forward pass, these output maps become input maps and then calculate the next output map with additional kernels.
Actually, now the really hard work begins, the backpropagation. Forward is often considered hard, but backwards is still harder. But not for us, we are almost done with the backpropagation. Let me explain.
To make a huge trick we have to step back. NN ~== CNN means we can take a lot of steps from the neural network to realize the idea of a CNN. You should take a look at this idea here for feed forward and feed backward, it is similiar to what I use here.
Here is the code for the forward pass, we cut out the forward stuff:
for (int i = 0; i < cnn.Length - 1; i++)
{
int left = cnn[i], right = cnn[i + 1], lDim = dim[i], rDim = dim[i + 1], lStep = cs[i + 0], rStep = cs[i + 1],
kd = filter[i], ks = kstep[i], st = stride[i], lMap = lDim * lDim, rMap = rDim * rDim, kMap = kd * kd, sDim = st * lDim;
// convolution
for (int l = 0, ls = lStep; l < left; l++, ls += lMap) // input channel feature map
for (int r = 0, rs = rStep; r < right; r++, rs += rMap) // output channel feature map
{
// CNN specific operations
}
}Change the first loop to, so we go back:
for (int i = cnn.Length - 2; i >= 0; i--)Now we need to respect the ReLU derivative and end up with:
// convolution backwards
for (int i = cnn.Length - 2; i >= 0; i--)
for (int left = cnn[i], right = cnn[i + 1], lDim = dim[i], rDim = dim[i + 1], lStep = cs[i + 0], rStep = cs[i + 1],
kd = filter[i], ks = kstep[i], st = stride[i], lMap = lDim * lDim, rMap = rDim * rDim, kMap = kd * kd, sDim = st * lDim, l = 0, ls = lStep
; l < left; l++, ls += lMap) // input channel feature map
for (int r = 0, rs = rStep; r < right; r++, rs += rMap) // output channel feature map
for (int y = 0, k = rs, w = ks + (l * right + r) * kMap; y < rDim; y++) // conv dim y
for (int x = 0; x < rDim; x++, k++) // conv dim x
if (conv[k] > 0) // relu derivative
{
// CNN specific operations
}And now we are ready to get the gradients:
// convolution gradient
for (int i = cnn.Length - 2; i >= 1; i--)
for (int left = cnn[i], right = cnn[i + 1], lDim = dim[i], rDim = dim[i + 1], lStep = cs[i + 0], rStep = cs[i + 1],
kd = filter[i], ks = kstep[i], st = stride[i], lMap = lDim * lDim, rMap = rDim * rDim, kMap = kd * kd, sDim = st * lDim, l = 0, ls = lStep
; l < left; l++, ls += lMap) // input channel feature map
for (int r = 0, rs = rStep; r < right; r++, rs += rMap) // output channel feature map
for (int y = 0, k = rs, w = ks + (l * right + r) * kMap; y < rDim; y++) // conv dim y
for (int x = 0; x < rDim; x++, k++) // conv dim x
if (conv[k] > 0) // relu derivative
{
float gra = cGradient[k];
int j = ls + y * sDim + x * st; // input map position
for (int col = 0, fid = 0; col < kd; col++) // filter dim y cols
for (int row = col * lDim, len = row + kd; row < len; row++, fid++) // filter dim x rows
cGradient[j + row] += kernel[w + fid] * gra;
}The Delta step is used like this:
// kernel delta with kernel weights update
for (int i = cnn.Length - 2; i >= 0; i--)
for (int left = cnn[i], right = cnn[i + 1], lDim = dim[i], rDim = dim[i + 1], lStep = cs[i + 0], rStep = cs[i + 1],
kd = filter[i], ks = kstep[i], st = stride[i], lMap = lDim * lDim, rMap = rDim * rDim, kMap = kd * kd, sDim = st * lDim, l = 0, ls = lStep;
l < left; l++, ls += lMap) // input channel feature map
for (int r = 0, rs = rStep; r < right; r++, rs += rMap) // output channel feature map
for (int y = 0, k = rs, w = ks + (l * right + r) * kMap; y < rDim; y++) // conv dim y
for (int x = 0; x < rDim; x++, k++) // conv dim x
if (conv[k] > 0) // relu derivative
{
float gra = cGradient[k];
int j = ls + y * sDim + x * st; // input map position
for (int col = 0, fid = 0; col < kd; col++) // filter dim y cols
for (int row = col * lDim, len = row + kd; row < len; row++, fid++) // filter dim x rows
kernel[w + fid] += conv[j + row] * gra * 0.005f;// * 0.5f;
}And now the magic is real! The trick is simpel, you need to grok the mechanic behind neural networks, then you build your recipe and with that you can build your CNN or maybe a system you cannot imagine today.
The construction how to calculate through your system plus a way to let your system learn:
Forwards:
neuronOutputRight += neuronInputLeft * weight
Backwards:
gradientInputLeft += weight * gradientOutputRight
Update:
weight += neuronInputLeft * gradientOutputRight
Brings a basic CNN to life.
You have seen here a very powerful CNN in action. Not big, but with very high accuracy. In practice, the network is ranked 60th in the benchmark for now, which is quite good for such a small network without any special techniques. Feel free to play around with it, it should be possible to achieve even better rankings without increasing the effort too much.
But the term convolutional neural network is maybe not quite correct. Here I have taken the shortest path that was possible to me. This includes not only missing pooling, but also the kernel flip. The addition of the bias, batch support and including delta learning step (as I have already done for the neural network) and other techniques such as dropout, padding, normalization so that with all the stuff it becomes very complex. So I stop here and hope you can enjoy the demo like I did.
If you want to get even better with building CNNs, it might be worth to taking a look at Kaggle to see how the pros build. Cheers!