Scrape the web easily -> no need to be a coding expert. Arachnida is providing a simple web interface to pilot powerful crawlers (running Headless Chrome)
open a terminal, and run:
git clone https://github.com/guillim/Arachnida.git arachnida && cd arachnida && meteor
Finished !
Now open google chrome (or any browser) and follow this link: http://localhost:3000
You will be able to add a crawler, configure it, and run it in seconds !
First give it a name, and leave the function empty (except if you know what you're doing)
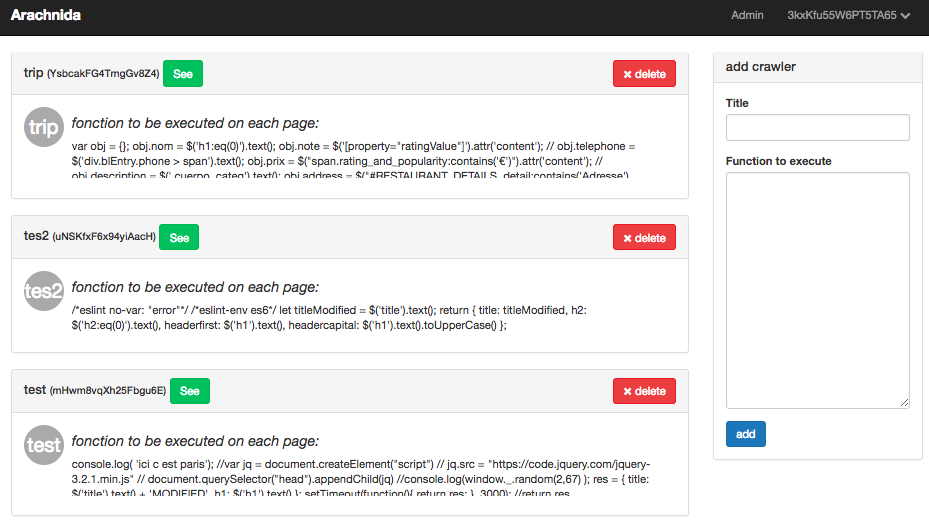
This is the only moment when a bit of coding knowledge is helpful. In the main part, you need to write a JavaScript function that will be executed on every page scraped by the crawler.
For instance, to extract the title of each page, write:
return {
title: $('title').text(),
};
Yes, jquery is already set up. You simply need to provide the selectors (id, class...)
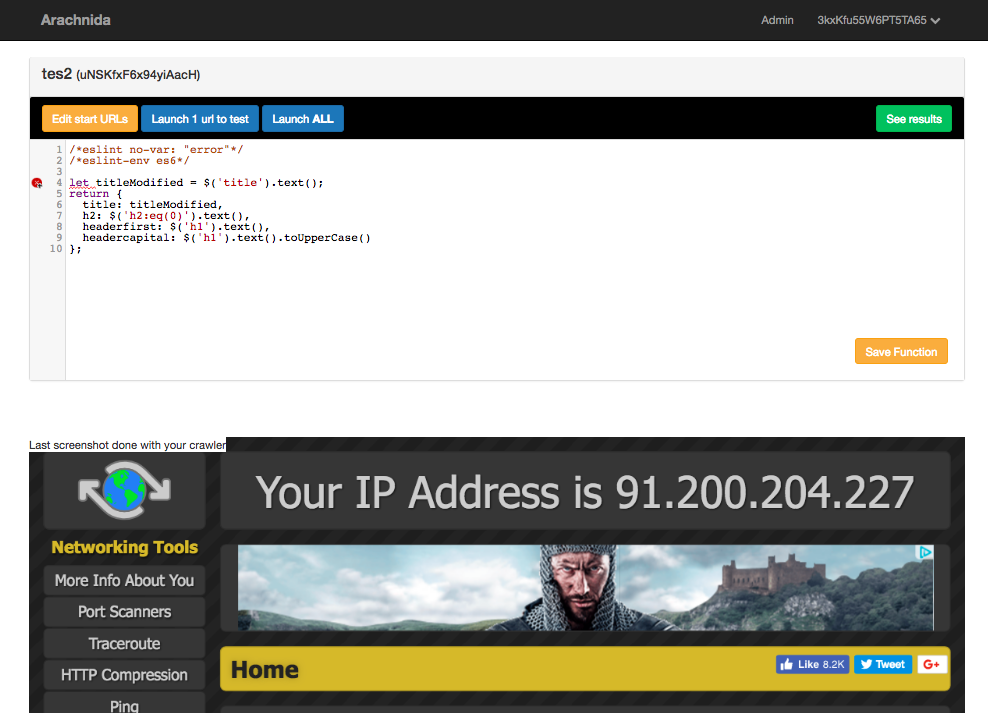
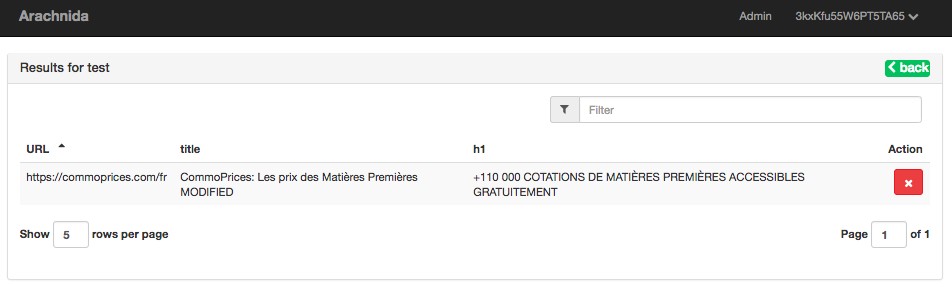
- See screenshot of your running crawler
- Manually add URL to be scraped, or upload a CSV
- Sign in / Sign up
- Account management: Profile Page, Username, Change password, Delete account...
- Admin for the webmaster: go to
/admin - Router
- MongoDB as database
I am looking for people to make pull requests to improve Arachnida. Please do it :)
TO DO:
- Setup live queue of url to be scraped (ex: at the moment, you can't click straight on a link and scrape it)
- Live Log from the server brought to the interface to help debugging
- Results export functionality (CSV & Json)
Boilerplate: yogiben.
HeadlessChrome layer: yujiosaka