This repository offers sources to gain an understanding of Natural Language Supervision and CLIP. Here you can find:
- Annonotated papers about Natural Language Supervision
- Notebooks with demos for:
- Linking text to images: CLIP
- Zero-shot text generation: DALL-E (mini), BigSleep, CLIP-GLASS
- Natural Language Video Search: CLIP in youtube videos
- A presentation on the topic in two formats (short, long)
Below you will find a summary of the CLIP paper, my notes on the most relevant information and "spin-offs" such as DALL-E, CLIP Glass.
This survey has been presented for the seminar "Learning with limited labeled data", organized by the Explainable Machine Learning group at the University of Tübingen.
Introduction & Background
- Natural language supervision: SL, USL, SSL + motivations
- Previous works benchmark
Experimental Setup
- Task learning and CLIP
- The Dataset
- Methodologies: prompt engineering & ensembling
- The architectures + training setting
- Scaling the model
Performance & Comparison
- Zero shot vs. supervised baseline
- Data efficiency performance
- Zero shot vs. few shot CLIP
- Representation Learning
- Robustness to natural Distribution Shift
- Comparison to human performance
- Data overlap analysis
Overall evaluation
- Limitations
- Broader Impacts
- Bias
- Surveillance
- Tasks:
- Image and Text retrieval
- Optical Character Recognition
- Action recognition in videos
- Geopositioning
- Robustness to distribution shift
- Future Work
Spin-offs:
- Multi-modal neurons
- DALL-E
- Self-supervised learning of visual features through embedding images into text topic spaces (SELF-SUPERVISED):
- Text → Latent Dirichlect Annotation (bayensian) → topic probabilities
- image → CNN → topic probabilities supervised by LDA topics
- Trained on: Wikipedia CLEF, MS-COCO
- Evaluated on : MS-COCO (55.4%), STL-10 (76.51%)
- Zero-Shot Learning Through Cross-Modal Transfer (Sochet et al. Google) (SUPERVISED):
- wikipedia text → fixed vocabulary size, d-dimentional vectors (d=50)
- CIFAR-100 (slightly modified): 100 seen classes, test on 6 unseen classes
- A Novelty detector distinguishes the images from seen and unseen.
- Inference:
- seen: standard classifier based on probability (bayesian)
- unseen: consider a context set of points, compute probabilistic set distance (euclidean), then compute local outlier factor as measure of outlierness. Normalize over all contexts, compute gaussian error and we obtain the outlierness/probability of being outlier.
- Training:
- Image → 2 layer network → word vector
- loss: actual word vector and predicted text embedding
- ZS-score on 6 new classes (CIFAR-100): 52.7%
- DeViSE: A Deep Visual-Semantic Embedding Model (From et al., Google) (SUPERVISED):
- Pre-train a language model → semantic word vectors
- Pre-train Visual Object Recognition model
- Fine-tuning Visual Obj. Rec. model → add projection layer, remove softmax → predict semantic vector for image label, supervised by the language model for that label
- Trained on: ILSVRC ImageNet 1K (winning model)
- Evaluated on (ZS): ILSVRC ImageNet dataset, various size (table 2, best 36.4%)
- Learning Visual N-Grams from Web Data (FAIR) (SUPERVISED):
- Fine-tune a CNN to predict probability for each n-gram of all possible in the vocabulary (~100k+ n-grams or "comments" from over extracted 30M english comments)
- We have images and their comments
- ImageNet trained → fine-tune to predict soft-max over all possible n-grams (multiple n-grams are contained in a comment)
- Two loss functions:
- Naise n-gram loss: p_obs is observational likelihood of n-gram given the img encoding. Loss = sum of all negative log p_obs for n-grams present in the dictionary and in the comment for that image. Others are ignored.
- Jelinek-Mercer loss: we consider all the possible n-grams, not only ones in the comment. Given embedding n-gram matrix E (dim: embedding length x vocab.size) → consider out-of-distribution n-grams. Loss = negative sum of log probability of each comment word given previous predicted ones → averaged on comment length it's called "perplexity" for an image.
- Trained on: YFCC10M
- Evaluated on: COCO-5K, Flickr-30K
- Zero-shot transfer: ImageNet-1k (35.2%), SUN (34.7%), Yahoo (88.9%)
- VirTex: Learning Visual Representations from Textual Annotations (Desai et al.) (SUPERVISED):
- "Pre-training task", ResNet50 + transformer (from scratch!): img encoder → cross attention in the transformer decoder (double decoder for bi-directional token prediction)
- Trained on: train2017 split of COCO-Captions (118k images x 5 captions each)
- Evaluated on (ZS?): PASCAL-VOC07 (88.7%), ImageNet-1k (53.8%) image classification
- Fine-tuning comparison downstream tasks (table 3) → how VirTex transfers with reduced dataset size compared to other models (outperforms all the other models)
- Exploring the Limits of Weakly Supervised Pretraining (Facebook) (SUPERVISED):
- ResNext-101 layers trained on Instagram Dataset and ImageNet1K with different label sizes. The networks reach billions of parameters.
- Objective → understanding limits of supervised learning
- Findings:
- careful label design is much better than increasing dataset size
- Increasing network size combined with increasing data → better performance gain
- Pre-training on web-data without manual label annotation works even with wild data
- Trained on: ImageNet-1K, Instagram (1.5k, 8.5k, 17k)
- Evaluation: ImageNet-1K (
85%), ImageNet-5k (55%), ImageNet-9k (~45%) - Fine-tuning tasks: COCO Detection Box AP (45.2%), COCO Det.B.AP@50 (68.3%)
- Learning Visual Features from Large Weakly Supervised Data (WEAKLY SUPERVISED)
- Contrastive Learning of Medical Visual Representations from Paired Images and Text (Stanford): contrastive objective (bi-directional), pre-training task and then downstream classification → base for CLIP (UNSUPERVISED)
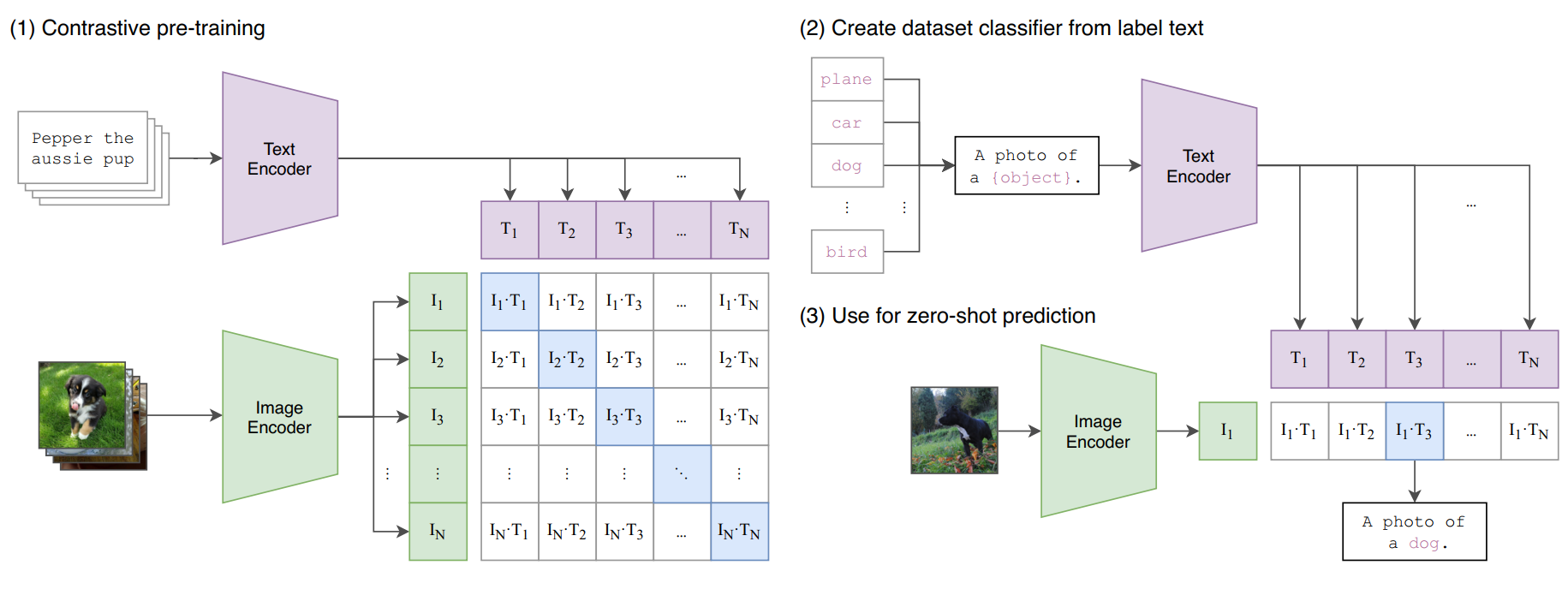
Clip is a model aiming to learn visual representations with natural language supervision (predicting text). From an image: predict related words out of a random set of text snippets.
- Novel tasks can be taught, data generalization is task-agnostic
- Efficiency in data computation with Vision Transformers
- Efficiency in scaling up with the data with contrastive pre-training, compared to image-to-text
- Key idea: measuring the task learning capabilities of ML systems
- Only the FAIR paper (Visual N-grams) has generic pre-training with natural language supervision and tests zero-shot transfer to standard classification datasets
- Why task learning? GPT-1: pre-training and supervised fine-tuning, but zero-shot transfer performances grew steadily with pre-training → focus on task-learning
- Core of CLIP: image encoder → features + text encoder → weights
- Comparison with visual N-grams:
- ImageNet classification: CLIP (zero-shot, 76,2%), Visual-N (zero-shot, 11,5%), ResNet50 (supervised, around same as clip)
- Pre-training in a contrastive way to pair text with images
- A prompt is fed into the network to ask CLIP what to describe (prompt engineering). i.e: "a photo of {...}" → classification task
- The model predicts the class
- New tasks can be taught, such as object counting, object comparison, geolocation, concept visualization
- Neurons in higher layers are similar to human multimodal neurons: specialized neurons react to data in various forms (image, text) and represent them in general ideas and concepts
- Dataset:
- Available options: MS-COCO, Visual Genome (small), YFCC100M (non qualitative)
- Custom Dataset: "WIT" 400M (text, image) pairs. Raw data:
- 500,000 text queries: words occurring > 100 times on English wikipedia, augmented with bi-grams (two word sentences)
- Class balance: up to 20,000 (image, text) per query (cap limit)
- Training:
- VirTex-like: CNN + Transformer, but difficulties in scaling (Figure 2). Predicting the same words is a problem: varying descriptions
- Contrastive objective + bag of words: better scaling up. N pairs, NxN possible combinations, N real pairs maximize cosine similarity + N^2-N pairs minimize cosine similarity → symmetric cross-entropy loss
- No over-fitting: very large datasets and the captions are not as detailed as Zhang et al.
- Train from scratch, no weight initialization
- Only linear projections to map into the multi-modal embedding space. No difference with non-linear maps and speculated may be co-adapted in SSL methods.
- Augmentation: random square crop.
- Softmax temperature parameter is directly optimized as log-parametrized multiplicative scalar
- Loss and transformations:
- Difference with Zhang et al.: Image X_v is transformed just with random crop into X_tilde_v. For X_u, the text is NOT transformed into X_tilde_u since there's no text to sample from, they're already single sentences.
- X_v is encoded into a high-dimensional vector h_v
- H_v is transformed with non-linear mapping to v
- same for the text-pair X_u
- Contrastive loss v→u + contrastive loss u→v = averaged both on positive pairs
- Architecture:
- Image Encoder:
- ResNet + ResNet-D improvements + antialiased-2 blur pooling + attention pooling (specify)
- ViT + more layer norm
- Text Encoder:
- Transformer: 63-M parameters, 12 layers x 512, 8 attention heads
- Text: Byte Pair encoding, vocabulary size 49,152. Max sequence Len: 76
- Scaling:
- Image encoder: width, depth, resolution
- Text encoder: width proportional to image encoder, NO DEPTH
- Network architectures & techniques:
- ResNet: ResNet50, ResNet101
- Efficient-Net: RN50x4, RN50x16, RN50x64 (50 layers, K blocks for each layer, each block contains convolutions, BN, activations)
- Vision Transformer: ViT-B/32, ViT-B/16, ViT-L/14 (336 pixel for one epoch → "CLIP")
- Optimizer: Adam, decoupled weight-decay regularization, learning rate decay cosine schedule
- Mini batch size: 32,768
- Image Encoder:
- Prompt engineering: "polysemy". Multiple meanings of the same word without a context, thus there are multiple labels for the same word! Prompt engineering improves performance when specifying the type of object or photo for datasets ("a type of pet", "a type of aircraft", "a satellite photo")
- Data Overlap Analysis: overall gain of at most 0.6% accuracy in Birdsnap dataset (12.5% detected overlap of data), average 3.2% of data overlap training-eval. BUT they use a duplicate detector: nearest neighbors in learned embedding space with threshold. Data contamination accuracy = All - clean (accuracy on subsets splits)
- Ensembling: over the embedding space, averaged embedding representations → cost of a single classifier. For each embedding: different context prompts. ImageNet: 80 context prompts → +3.5% respectively to single default text. Overall prompt engineering + ensembling: +5%
- Linear probing: evaluating representation learning with linear classifiers instead of end-to-end fine tuning (expensive, many params, masks failures). Comparison with supervised models: CLIP is always more computationally efficient → best gain with scaling. Moreover, supervision models may collapse intra-class details → worse performance.
- Scaling: 44x increase in compute (5 versions of ResNet), CLIP follows a similar trend to GPT → the error decreases smoothly
- Data efficiency in Zero-shot learning vs. few shot (Figure 7)
- StanfordCars, STL10: SoTA performance on datasets with few label examples and a lot of unlabeled data.
- Kinetics700, UCF101: NLS → better context with verbs, improved action recognition
- EuroSAT, PatchCamelyon: weak performance on specialized datasets since labeled examples are necessary, zero-shot transfer is not much effective
- Zero-shot CLIP vs. linear probe, supervised CLIP still underperforms → there is still room for improvement for ZSL
- Distribution shifts: supervised models appear to exploit spurious correlations for a specific distribution. Zero-shot models cannot, thus they tend to learn higher abstract concepts → large improvements with natural distribution shifts, much more robustness
- Effective robustness: label dis-alignment between datasets → clip zero-shot classifier can adapt to the classes of each dataset → 5% avg. improvement (rather than pooling predictions of similar classes). Also few-shot improves but is less robust than zero-shot.
- ImageNet Adaptation: adapting CLIP to ImageNet results in +9.2% accuracy (3 SOTA years improvement) → uncertain whether in-distribution patterns are learned or spurious correlations. Major gain for fully supervised CLIP.
- Human Performance Comparison: zero-shot clip outperforms human performance overall. However, humans reveal a consistent gap in performance between zero-shot and one-shot learning because they use base knowledge to update priors on what's uncertain. This could be replicated in CLIP. Hard problems for CLIP revealed hard for humans as well.
- Computational cost: 1000x scaling required to reach SOTA performance
- Poor task-learning generalization: random performance (distance to nearest car)
- Poor performance on fine-grained tasks: count objects, aircraft model classification etc.
- "Brittle"/"fragile" data generalization. CLIP assumes all data will be in-distribution: but out of distribution it performs poorly (MNIST handwritten vs. logistic regression)
- CLIP does not address data efficiency: CLIP does not address the issue, it just has a very large source of supervision → ideal self supervision + self-training
- Unfiltered pairs and social biases
- Complex tasks not describable with text, inefficient few-shot learning compared to human performance
- Fallacies in abstraction: typography attack, biases in the data
- Poor generalization out of the pre-training dataset
- Poor performance on highly-detailed tasks such as vehicle model classification
- Struggles in abstract novel tasks such as object counting
- Roll your own classifier without re-training, zero-shot generalization
- Surveillance: facial emotion recognition, face recognition, image retrieval, action-recognition, geo-localization
- Denigration harm: 4.9% of 10k images from FairFace misclassified as non-human objects (thief, criminal, orangutan, gorilla...)
- Crime categories predicted for people of certain ages (and races) → class design influences the denigration harm distribution across ages → label design can be crucial for the behavior of the model
- CLIP well predicts sex given images of men/females with various occupations → lower threshold of chi-square test results lower quality of labels (figure 18)
Source: https://openai.com/blog/multimodal-neurons/
- In the brain there are neurons firing to abstract concepts regardless their modalities
- Likewise, in CLIP → neurons in last layers work on loose abstract representations of ideas, regardless the modality
- Techniques:
- Feature visualization: optimizing from random noise the inputs to obtain the desired prediction with gradient-based methods → visualize learned representations
- Maximal activating images in the dataset
- How CLIP classifies: composition of abstract concepts in an algebric way (sparse linear probe): similarly to word2vec, the learned concepts are combined linearly
- Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search (Galatolo et al.): combining a GAN with CLIP to generate images that minimize the distance text-img calculated by CLIP. A genetic algorithm aims to minimize the discrimination loss and pick the optimal noise image from a defined noise distribution.
- W&B Article (DALL-E mini)
- Differences with DALL-E:
- DALL-E mini feed image tokens to the transformer decoder only
- BART is used for DALL-E mini, a bi-directional model
- DALL-E standard trained on 250 million text-image pairs
- Parameters:
- vocab. size: 16,384 vs 8192
- token_len: 256 vs 1024
- Architecture
- Training:
- img → VQVAE encoder → img_encoding
- text → Transformer Encoder → txt_encoding
- txt_encoding + img_encoding → Transformer Decoder → pred_img_token_1 (in loop)
- softmax cross-entropy(img_encoding, pred_img_tokens)
- Inference:
- txt → Transformer Encoder → txt_encoding
- txt_encoding + → Transformer Decoder → img_token_1 (continue in loop)
- img_tokens → VQVAE Decoder → image
- CLIP used to select the best matching images (multiple images can be inferred depending on size
- Training:
@misc{
Calanzone2021,
title={Halixness/Understanding-CLIP: Repo from the "learning with limited labeled data" Seminar @ uni of tuebingen. A collection of notes, notebooks and slideshows to understand clip and natural language supervision.},
url={https://github.com/halixness/understanding-CLIP},
journal={GitHub},
author={Calanzone, Diego}
}