Questions on combined attention mask structure for Jacobi iteration #44
Comments
|
For the simplest Jacobi decoding mask (like below), xformers support such a (BTW, the |

|
A further question, crucial for inference deployment, is how the merged lookahead computation can make use of paged/blocked KV cache. It needs a paged attention kernel that allows However, vLLM's paged attention kernel seems limited to This new |
|
Once again, not one of the authors, but here's my answer:
I think the part you need to understand is that
|
|
Thanks for the explanation but I think some points are not correct...
No, Blue 0+Orange 1234 can be viewed as either:
The two views are equivalent. If the 5 tokens are perfect guess, it also means that the Jacobi iteration has converges to true solution. Such computation is not the regular autoregressive decoding. The token state y(t) is computed concurrently (in sequence dimension) from the previous state y(t-1), not sequentially token-by-token. 
Still, my question is -- why green-5 must depends on {green-5, orange-4,3,2,1, blue-0}, but not {green-5,4,3,2,1, blue-0}, or {green-5,4,3,2, orange-1, blue0}, or other combinations from green/orange states (as long as the position spans over 543210)?
I know, thus I mentioned the Triton version that takes additive mask... The CUDA version doesn't support mask input.
Yes, my question is exactly -- when I have the
Yes, thanks for confirmation. I think this is why lookahead decoding is able to use more FLOPs than normal decoding, as the "query" length is longer and the malmul shape is more "square". |
With iterative lookahead decoding, we do:
Refer to Figure 4 from the blog for details. With lookahead decoding, you do
That's what I meant by in parallel. The following answers from the lead author may also help.
Edit: Ah, I noticed that I claimed earlier that blue+orange was part of the regular decoding, as opposed to the first Jacobi step. Whoops. Only blue is part of the regular decoding. (b): Blue-orange= Step 1: Parallel decode You can check that the tokens that are paid attention to match those from sequential lookahead decoding without verification.
I wouldn't mind helping to get LADE working with FA2, but FA support is already on the roadmap (#13 (comment)) (well, we have FA1 but not FA2 support yet) and the blog mentioned that CUDA kernels are coming. I don't really want to work on something that's already in progress, as it feels like wasted effort, but I'm not sure what their current progress on their FA-compatible CUDA kernels is like.
Even without a KV cache for autoregressive decoding in a single pass, multiply-add operations are still done over masked parts of the tensors. |
|
It should also be noted that whether LADE can use more FLOPs to achieve a speedup depends on how powerful the GPU is. The authors only tested on A100 GPUs.
yhyu13 noticed a slowdown using the default parameters when running a 13B model on a V100. By adjusting the parameters, there was a speedup, but it was small. Joao Gante from the Huggingface transformers team also noticed a 33% slowdown with the default parameters for a 7B LLM on a 3090 (huggingface/transformers#27649 (comment)). It took some manual hyperparameter adjustments to get a 25% speedup. |
Thanks for the pointer! The question here #28 (comment) is exactly my question. The author commented:
Indeed, here red-6 attends to {green-5, orange-4,3,2,1, blue-0}. Even if it shouldn't attend to red-5, it could also attends to any of the following choices:
Those are all valid cross-iteration tokens that spans over position 5,4,3,2,1,0. Is any one fundamentally better? |
|
The author comment #14 (comment) is a very good illustration. I do see the need of spanning-over-iterations in the "n-gram collection phase" -- otherwise, if staying within the same iteration (same color, all red / all green / all orange), then there is no creation of new "n-grams", and the algorithm falls back to the original Jacobi decoding paper However, the "n-gram collection phase" is done out side of the attention layer computation, right? I can see the entire lookahead decoding algorithm as two-phases:
For phase (2), I totally understand why red-6 is grouped with {green-5, orange-4} but not grouped with {red-5, red-4} -- we need the cross-iteration "trajectory" here. But the attention mask pattern is used in phase (1), and even if restricting to in-iteration tokens (red-6 attends to red-6,5,3,2), the model.forward computation is still performing meaningful Jacobi iterations to improve the guess. |
hello, bro, I'm also confused about the mask design, have you understand this problem? I wonder if you can help to make it clear hhhh, thanks |
As for the other options, you could try them, but then it would no longer be Lookahead decoding, but a derivative method. As for whether it's better or not, my guess is that the difference wouldn't be huge, but as always, someone would need to run experiments to assess the performance difference across a variety of prompts and models. Basically, we don't know until we try. It's also important to remember how the orange, green, and red tokens are chosen when being passed to the model. With lookahead decoding, the orange tokens are randomly selected from the vocabulary and the green and red tokens are taken from previous passes through the model using lookahead decoding. This affects how we interpret the method. |
What exactly is unclear to you? |
What's the definition of "sequential lookahead decoding", and how exactly is it different from the original Jacobi decoding? I thought that everything within From the lookahead branch section of the blog:
The "Jacobi iteration", if we use the original definition in the Jacobi decoding paper, is computed within a single time step (i.e. only using information from step t-1, so all red tokens; or only using information from step t-2, so all green tokens...). So the word "Jacobi iteration" is the blog must have a modified meaning... |
That's the random initialization for Jacobi iteration, right?
Is "using lookahead decoding" here equivalent to "using Jacobi decoding" (i.e. the same algorithm as described in the Santilli 2023 paper)? My reference is those sentences from the blog:
I thought "Jacobi iteration" should be defined as: 
However, if defined in this way, the dependent token is restrictedly within step |
yes, I think the procedure in blog's Figure 4 is clear, but I can't make the connections between this procedure and Figure 5's mask, I am also confused why we need to attend tokens that are in step t-3, step t-2. |

{kind=link}
{kind=link}
"Lookahead decoding takes advantage of Jacobi decoding's ability by collecting and caching n-grams generated from Jacobi iteration trajectories." That's the main difference. Jacobi iteration checks for the longest matching prefix from the previous iteration/the current input, whereas sequential lookahead decoding looks for N-gram matches generated from the previous Jacobi iteration trajectories. |
Yes.
As mentioned in the previous comment, the biggest difference is how verification is done. i.e. With N-grams instead of the longest matching prefix.
Not really? That just shows why red-5 must depend on green-4 and not orange-4 or red-4 and similarly, why red-4 must depend on green-3 and not orange-3 or red-3. Previous iterations would be subsumed into the term on the right. |
The step t-3, step t-2, etc. tokens are the green tokens in the input. You'll start seeing green tokens in the input in Figure 4 in Steps 2 and later. |
Yes, I can see that. Could you please provide further help to answer the following questions? |
Yeah, pretty much, even though it may not look like it at a first glance (i.e. the mask isn't lower triangular). Note that using a normal lower triangular mask for the verification branch will not give you parallel verification, but I think you understand that.
For lookahead decoding, it's better to use the mask described in the blog. It's a special mask. |
That Jacobi iteration formula indicates that I am not arguing that we should not use such multi-step iterative scheme. I can conduct numerical experiments (testing different mask designs like #44 (comment)) to see whether this improves convergence compared to single-step formulation. I just think that any modified schemes should not be called "Jacobi iteration" anymore, to avoid confusing the reader... In analogy, for ODE solvers, multi-step methods have their own names. Note: the above discussion has nothing to do with n-gram collection yet -- I am only talking about the |
It looks at several sequences in parallel because lookahead decoding focuses more on the left hand side of the parallel decoding. Please refer to Figure 3/4 from the blog and pay attention to the border between the green (accepted) and yellow (guess) tokens. i.e. In step n, where n Now, you might ask, why keep several orange tokens then? Because I just said that the green-orange progression comes from looking at the accepted tokens from previous steps? The answer is because we are doing several lookahead steps in parallel. i.e. We pretend that several orange guess tokens have been accepted already even though they actually haven't. Thus, in the equations you are referencing, those orange tokens would be indexed as As you noted, there is a difference in the methodology. But I think it's between sequential lookahead decoding and parallel lookahead decoding (i.e. full lookahead decoding) rather than between Jacobi decoding and sequential lookahead decoding. |
This is a good explanation! I get the idea that this gives an extra degree of parallelism along the "lookahead step" dimension (
Now I do get the motivation of multi-step iteration formula, but I will not call the method in the blog "Jacobi iteration" anymore😅In analogy to ODE solver, two-step formula is different from one-step Euler, despite being more accurate. |
|
Sounds good! 🤗 |
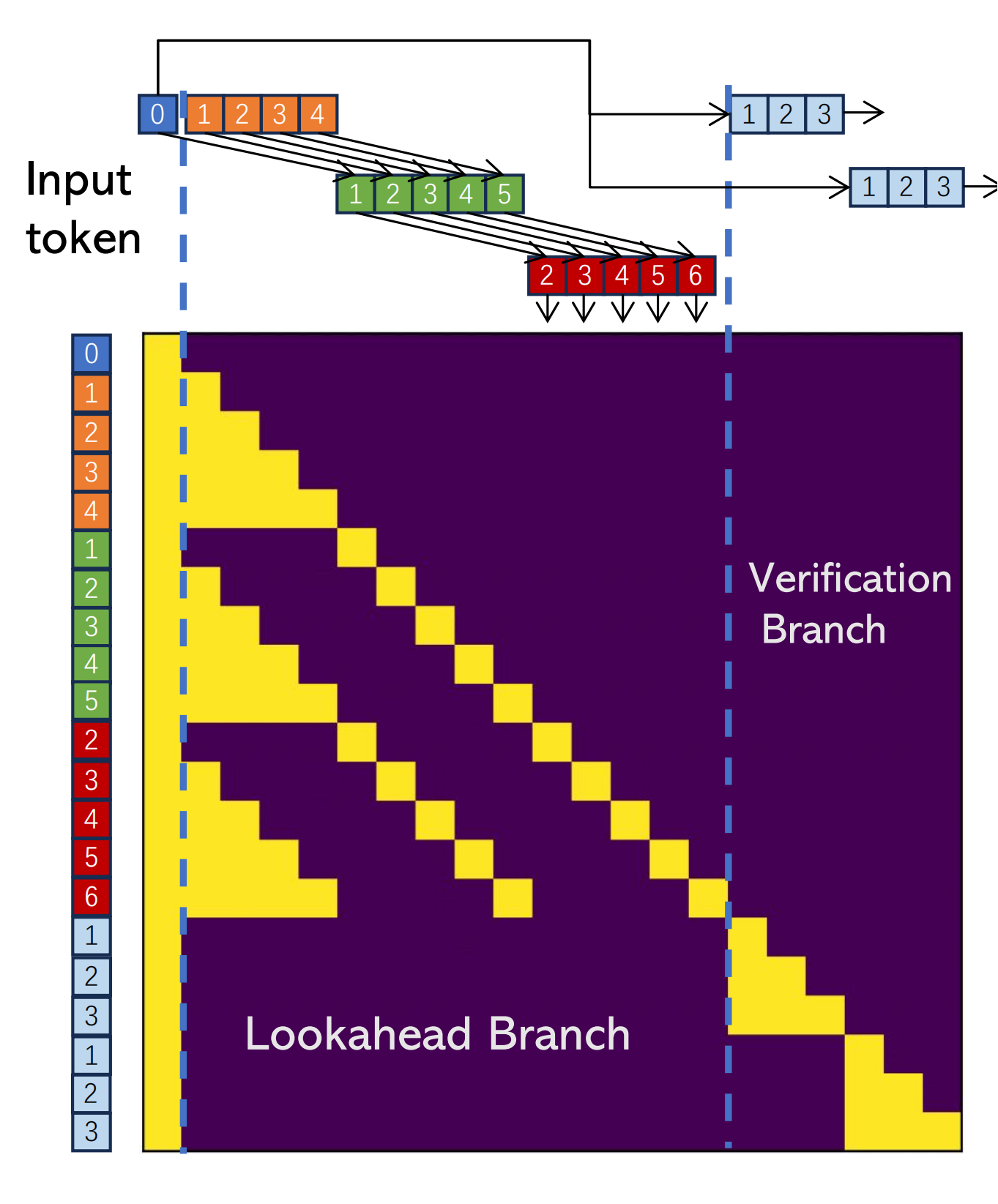
I have some questions about the structure of custom mask for lookahead and verify branches as described in the blog.
Related code
The
combined_attention_maskcreated byj_prepare_decoder_attention_mask():LookaheadDecoding/lade/models/llama.py
Lines 201 to 203 in b756db3
Such attention mask is then sent to the decode layer, in order to compute all branches in a single
model.forwardcall:LookaheadDecoding/lade/models/llama.py
Lines 234 to 236 in b756db3
1. Token dependency in lookahead branches
For the upper-left corner (blue-0 and orange-1,2,3,4):
I can understand that it is the Jacobi iteration (screenshot from this paper):
where each token in the current guess is updated concurrently, based on the current values. The input is a 5-token guess (in this figure), and the output is the updated 5-token guess. The input-output dependency is a normal triangular (casual) mask.
What I don't fully understand, is the green and red branches:
For example:
So why does each output token depend more on cross-iteration tokens, not in-iteration tokens? For example:
This is only about the model.forward computation part, not yet touching the N-gram cache management logic (that is in the
greedy_search()level, above themodel.forward()level). Thus this part should fall within the Jacobi decoding framework -- which shouldn't have cross iteration dependencies? (step-t state is computed from step t-1, but not t-2 or earlier)2. Past tokens (KV cache) and ways to call fused operators
The blog's mask omits the past token history. The actual, full attention mask sent to
LlamaAttention.forward()should look like this?The middle yellow block has KV-cache available (
past_key_values). The left padding block is the optional left-padding if used in static batching settings, to pad to the longest prompt length. The right block (shown in the original blog) deals with the newly-constructed queries (concats all branches), and no KV cache available.So what would be the proper way to call fused FlashAttention operator for such a mask pattern? The triton version of FlashAttention supports custom attention bias -- setting bias to
-infaccording to the mask pattern should have the desired mask effect? Has anyone checked the performance gain?The text was updated successfully, but these errors were encountered: