[Performance On Large clusters] Reduce updates on large services #4720
Conversation
…when really modified to avoid too many updates on very large clusters In a large cluster, when having a few thousands of nodes, the anti-entropy mechanism performs lots of changes (several per seconds) while there is no real change. This patch wants to improve this in order to increase Consul scalability when using many blocking requests on health for instance.
…vice is really modified
…is really modified
|
@banks this modification might greatly enhance the performance of your cache implementation in progress for large clusters with services having many instances |
|
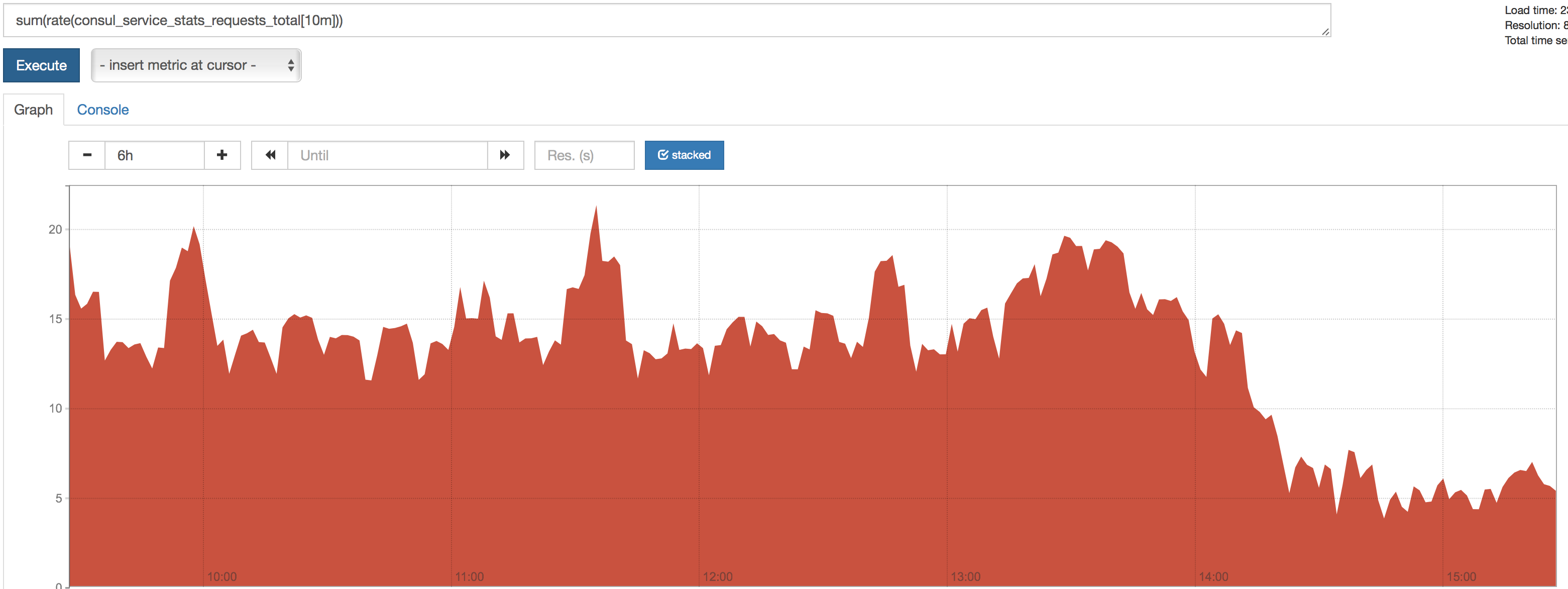
@banks @mkeeler @pearkes We applied this patch on a middle size cluster of ours (3400 nodes, 1300 kind of services). It more than divided by 2 the network bandwidth needed on our servers! We also tested it on our preprod clusters with nice changes, similar to this, but the improvement increase quite a lot with the number of nodes! On a large cluster, this is a game changer, as index per service was a very important change for scalability. This patch basically allow services not changing much to avoid changing for nothing and notifies clients only when real changes occur. Here are our result... Rate of Changes with wait=10m on a stable ServiceThis shows the number of updates on a stable service with 32 instances (means that anti-entropy does not change the service unless really needed). It means that if your use One single small service (32 instances) watched by many apps, rate per 10m:
On all services at the same time, here is the result (rate per 10m)
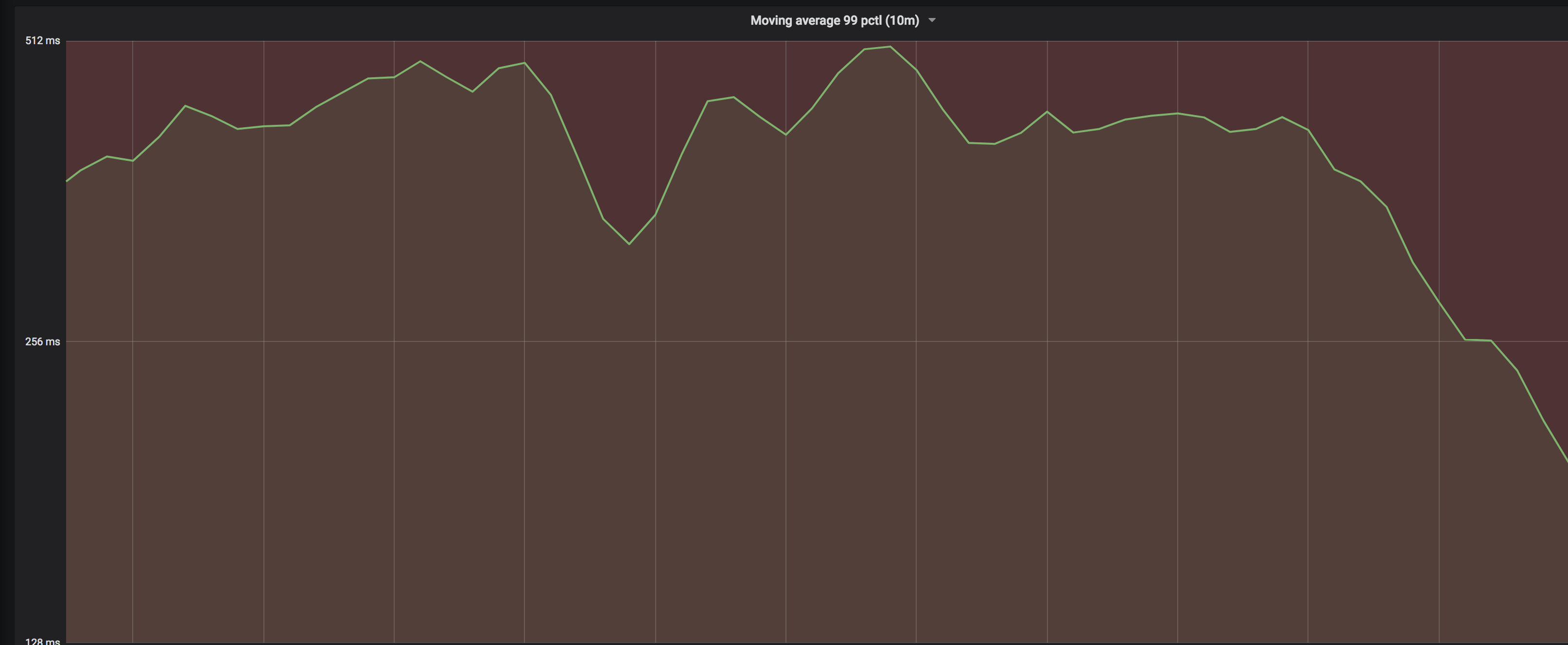
Real Life impact on this DatacenterOk, this was theoretical, here are the raw results 99th percentile on Read Stale delayWhile we used to have up to 1s of latency on this DC, the latency did drop to less than 256ms
Load Average / CPU LoadDecreasing really nicely on the servers Network bandwidth on serverDivided by more than 2... On 7 days (last bar on right is new version with this patch)Req/s on a single serviceReq/sec on server for services shown above (32 nodes). Some missing points before the MEP because of temp breakage of our metric system.
Various Consul Metrics for 7 days (last bar is the MEP with this patch)
ConclusionThis patch has a real impact on large clusters. I am also gonna test it tomorrow on larger DCs (up to 7k nodes), we expect even larger improvements. With this patch, this is the first time in weeks we do succeed to be below the SLA we provide to our internal clients, so I really think this is a very important optimization (and not that big or intrusive). Could you please have a look? Kind regards |





|
Thanks @pierresouchay this looks like some great investigative work and the benefits seem awesome 😄. Sorry we haven't had a chance to review in detail yet but we will likely come back around after a release we're leading up to in the next week or so (1.3). |
|
Thank you very much @pearkes, I get it, perfectly fine. However, would it be possible to have a look to #3551 which was kind of ready for a while with all fixes provided and that we need to backport, update all conflicts whith each release for almost 1 year. This one is almost without any risk since it does not touch anything to servers nor modify any kind of API... Kind regards |
There was a problem hiding this comment.
@pierresouchay This looks really good.
Is it safe to say the performance gains are due to not waking anything up blocking on the catalog due to not reinserting data when its the same. Or inversely the performance benefit is not mostly due to the overhead of reindexing within memdb.
Marking this as "Requesting Changes" because I have a few questions and requests for an additional code comment or 2 but the actual code looks ready to me.
agent/consul/state/catalog.go
Outdated
| entry.CreateIndex = serviceNode.CreateIndex | ||
| entry.ModifyIndex = serviceNode.ModifyIndex | ||
| if entry.IsSame(serviceNode) { | ||
| modified = false |
There was a problem hiding this comment.
I assume there is a reason why we cannot just return here like you did for the IsSame check on the node. If so it would be good to have a comment indicating why you can't, why the node needs to still be Inserted but why the "index" table doesn't require updating.
There was a problem hiding this comment.
Not really, was just to avoid to change too many tests.
Another possible reason was adding into Consul some values in DB, for instance pre-filled values from ToServiceNodes(), for instance Weights.
While semantics to not change, we are sure we are keeping the same kind of data before and after the patch (while upgrade semantics stays untouched).
Added comments in next patch
There was a problem hiding this comment.
As for the default values coming from ToServiceNode, that call happens prior to the IsSame check so if any of the defaults change then IsSame should return false and cause reinsertion.
As for the other reason of wanting to return ErrMissingNode, why can't we just move the node check block to before the ToServiceNode call?
There was a problem hiding this comment.
You are right, I wanted to have a change as small as possible, but you are definitely right, changing that...
|
@mkeeler I added the comment and made contract for IsSame() a no-brainer for future user of function. |
|
@pierresouchay Looks like GitHub isn't showing the updated comment at the bottom of this page so I will ask it here again to make sure its easily visible. I am not certain we can't return early when the IsSame check for services returns true. As for wanting to keep backwards compatibility with returning ErrMissingNode I think you are right. But the next question becomes why not move that whole check to before the ToServiceNode call. As for the other reason of ensuring default values get inserted shouldn't the IsSame check pick up those changes and ensure that the reinsertion happens? |
|
@mkeeler I am also a bit lost with thread handling on GitHub :-) You are right, my last patch fixes it, I removed the modfied attribute, so I think you will be happy. I wanted to change as few lines as possible, but your approach is more reasonnable. |
a1ed401 to
aab2d16
Compare
…ces_when_not_needed
…est coverage of IsSameService
|
@pierresouchay That travis failure is legit. I think you need to update the ServiceNode.IsSame check. The f-envoy branch which just got merged adds a couple new fields to the ServiceNode which you will need to check for in that function as well. |
|
@mkeeler @banks I have a very strange error. On my Mac Laptop, I cannot reproduce the same error as Travis: I have: I have no clue about the reason why (spent 3 hours on it)... The weird thing is that I have the same exact failure on master with So either my version of Golang 1.11 (I also tried with same result on Go 1.10.3) is completely broken (I just installed it a few hours ago), either something really weird has changed in the tests. I'll try tomorrow from a Linux machine, but I have no clue of the reason of this weirdness. Does any of you have an idea? |
|
@pierresouchay I suspect it's because you are running API tests without using make file. API tests run the This is really gross and we should be able to fix it, but you either need to The API test reliance on the consul binary in path is a sad thing that has caught most Consul devs out at least once... |
|
I checked out your branch and it passes locally for me - CI is green too now 🎉 thanks for the time spent! |
Well spotted, I had the exact same issue while trying to implement api/agent in #3551 (I spent so much time trying to figure out why my changes were not taken into account) |
Checks do update services/nodes only when really modified to avoid too many updates on very large clusters.
In a large cluster, when having a few thousands of nodes, the anti-entropy mechanism performs lots of changes (several per seconds) while there is no real change. This patch wants to improve this in order to increase Consul scalability when using many blocking requests on health for instance.
For the record, we are having anti-entropy running every 6-7 minutes, just this change does around more than 15 changes in catalog/nodes, but in our large services (around 1k nodes, that's still a lot) even in stable services.
What it means is that our large services are constantly updated and all health watcher being notified.
This has huge impact on load on Consul server and completely break performance.
This optimization reduces the load on Consul servers since all watchers will not being notified for nothing when Anti-Antropy or any request not changing the content or a node/service/check is being performed.
We have lots of performance issues those days, we would really appreciate a quick review.
Thank you very much