Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving [NeurIPS 2024]
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, Junxian He
📝 Paper@arXiv | 🤗 Datasets&Models@HF | 🐱 Code@GitHub | 💡 Slides | 🏆 Published@NeurIPS 2024
🐦 Thread@X(Twitter) | 🐶 中文博客@知乎 | 📊 Leaderboard@PapersWithCode | 📑 BibTeX
Important
🔥 News!!!
- [2024/09/25] 🎉 DART-Math is accepted to NeurIPS 2024!
- [2024/07/21] Excited to find our
DART-Math-DSMath-7B(Prop2Diff) comparable to the AIMO winner NuminaMath-7B on CoT, but based solely on MATH & GSM8K prompt set, leaving much room to improve! Besides, ourDARTmethod is also fully compatible with tool-integrated reasoning. Join the discussion under this X thread!
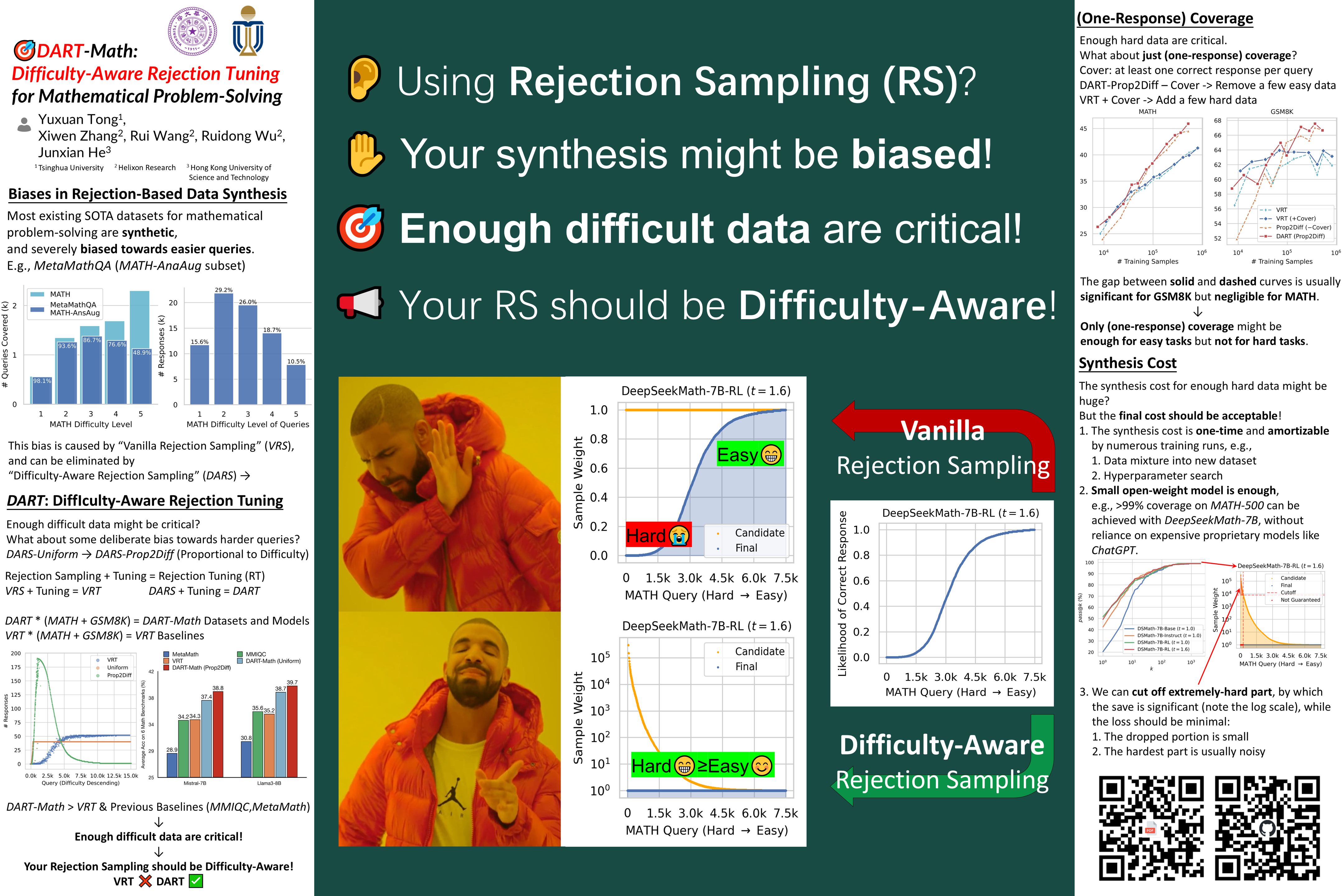
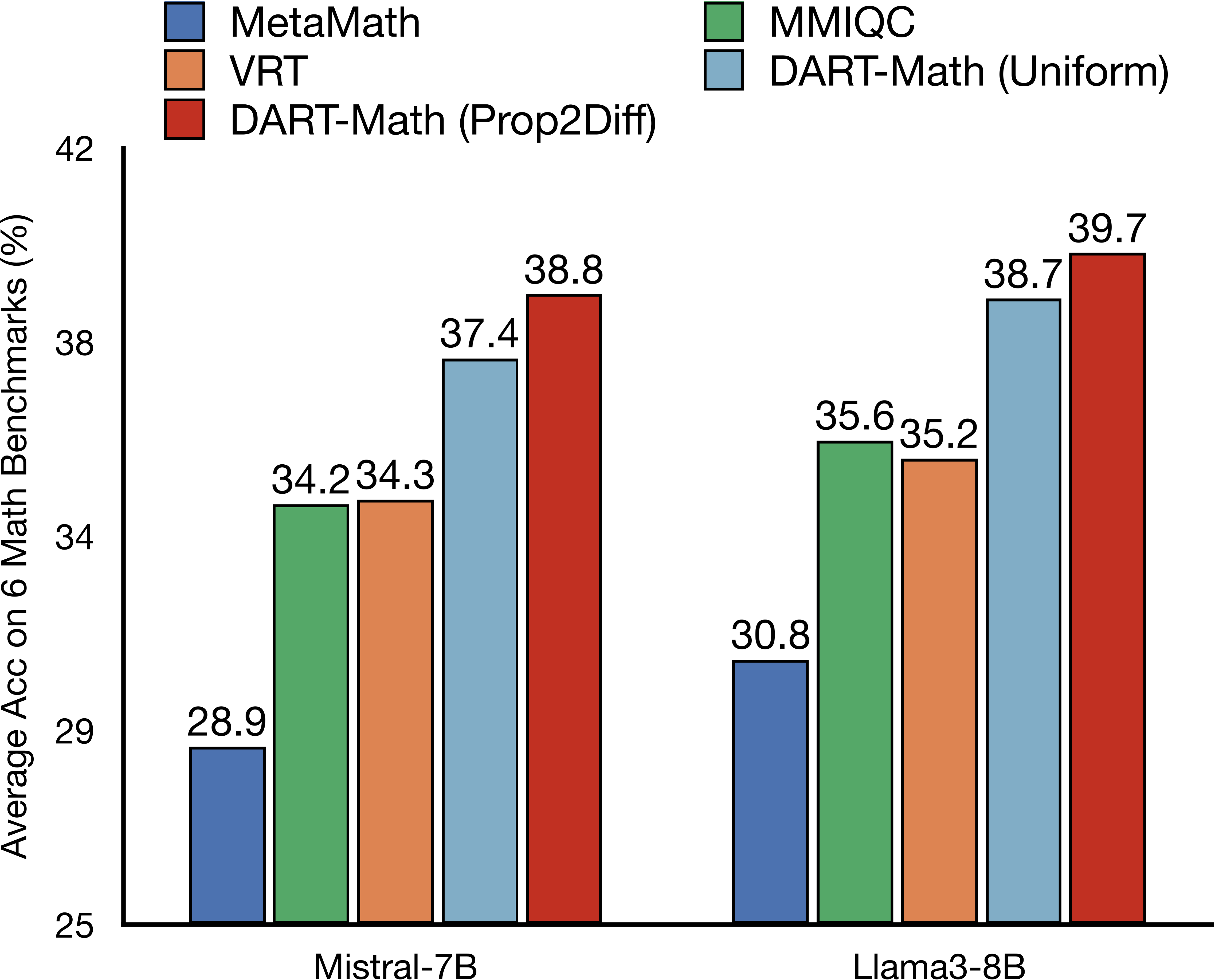
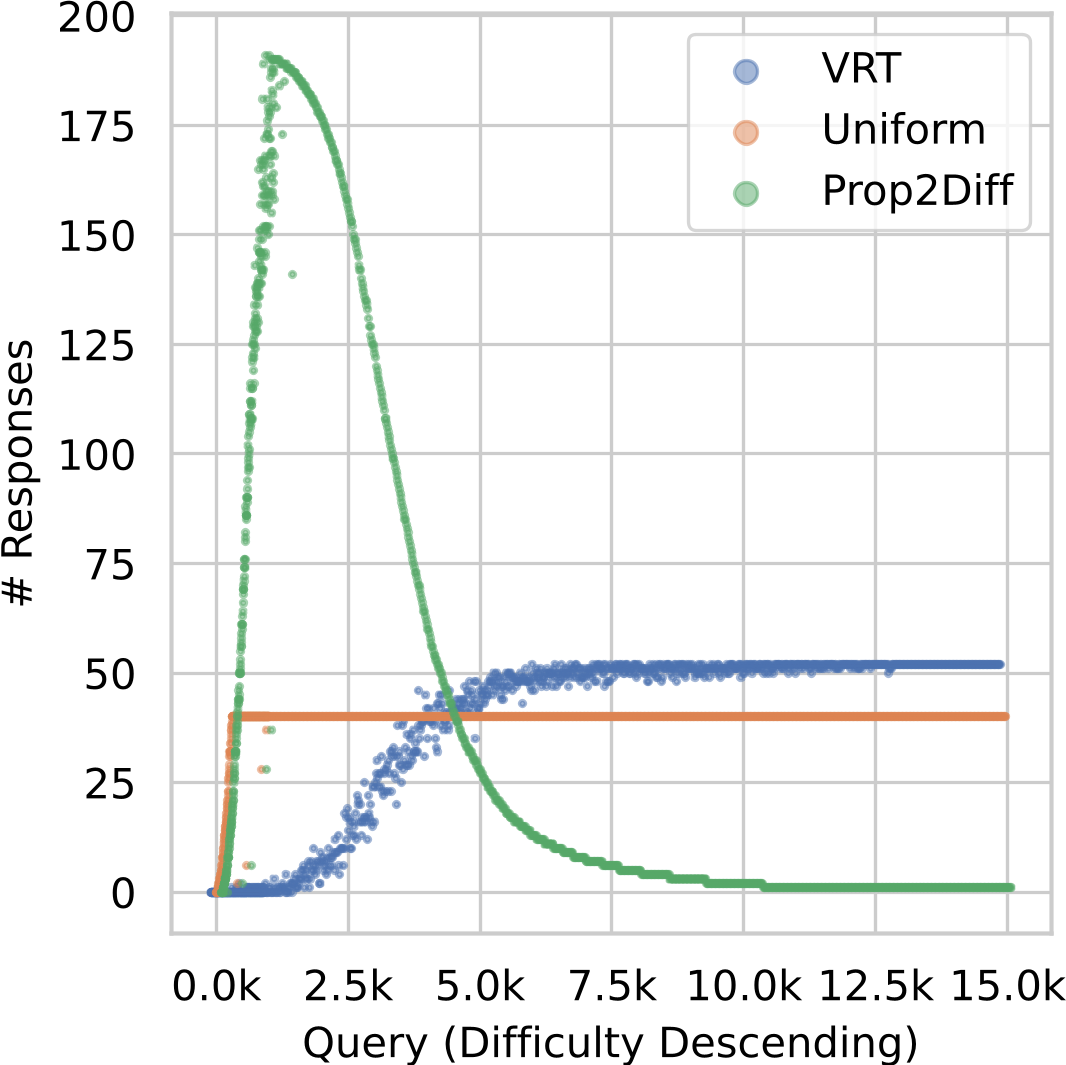
Figure 1: Left: Average accuracy on 6 mathematical benchmarks. We compare with models fine-tuned on the best, public instruction tuning datasets for mathematical problem-solving: MetaMath (Yu et al., 2024) with 395K examples, MMIQC (Liu et al., 2024a) with 2.3 million examples, as well as vanilla rejection tuning (VRT) with 590K examples. Both DART-Math (Uniform) and DART-Math (Prop2Diff) use 590K training examples. Right: Number of responses for each query descending by difficulty across 3 synthesis strategies. Queries are from the MATH training split (Hendrycks et al., 2021). VRT is the baseline biased towards easy queries, while Uniform and Prop2Diff are proposed in this work to balance and bias towards difficult queries respectively. Points are slightly shifted and downsampled for clarity.
| Dataset | Setting | # of Samples | MATH | GSM8K | College | Download |
|---|---|---|---|---|---|---|
DART-Math-Uniform |
Unifrom | 591k | 52.9 | 88.2 | 40.1 | 🤗 HuggingFace |
DART-Math-Hard |
Prop2Diff | 585k | 53.6 | 86.8 | 40.7 | 🤗 HuggingFace |
DART-Math-Pool-MATH |
– | 1615k | – | – | – | 🤗 HuggingFace |
DART-Math-Pool-GSM8K |
– | 2739k | – | – | – | 🤗 HuggingFace |
MATH and GSM8K are in-domain, while College(Math) is
out-of-domain. Performance here are of DART-Math models fine-tuned
from
DeepSeekMath-7B.
Bold means the best score on the respective base model here.
| Model | MATH | GSM8K | CollegeMath | Download |
|---|---|---|---|---|
DART-Math-Llama3-70B (Uniform) |
54.9 | 90.4 | 38.5 | 🤗 HuggingFace |
DART-Math-Llama3-70B (Prop2Diff) |
56.1 | 89.6 | 37.9 | 🤗 HuggingFace |
DART-Math-DSMath-7B (Uniform) |
52.9 | 88.2 | 40.1 | 🤗 HuggingFace |
DART-Math-DSMath-7B (Prop2Diff) |
53.6 | 86.8 | 40.7 | 🤗 HuggingFace |
DART-Math-Mistral-7B (Uniform) |
43.5 | 82.6 | 26.9 | 🤗 HuggingFace |
DART-Math-Mistral-7B (Prop2Diff) |
45.5 | 81.1 | 29.4 | 🤗 HuggingFace |
DART-Math-Llama3-8B (Uniform) |
45.3 | 82.5 | 27.1 | 🤗 HuggingFace |
DART-Math-Llama3-8B (Prop2Diff) |
46.6 | 81.1 | 28.8 | 🤗 HuggingFace |
MATH and GSM8K are in-domain, while CollegeMath is out-of-domain. Bold means the best score on the respective base model here.
DART-Math models achieve performance superior or competitive to
previous SOTAs on 2 in-domain and 4 challenging out-of-domain
mathematical reasoning benchmarks, despite using much smaller
datasets and no proprietary model like GPT-4.
| Model | MATH | GSM8K | College | DM | Olympiad | Theorem | AVG |
|---|---|---|---|---|---|---|---|
| GPT-4 (0314) | 52.6 | 94.7 | 24.4 | – | – | – | – |
| Llama3-70B-MetaMath | 44.9 | 88.0 | 31.9 | 53.2 | 11.6 | 21.9 | 41.9 |
DART-Math-Llama3-70B |
56.1 | 89.6 | 37.9 | 64.1 | 20.0 | 28.2 | 49.3 |
| DeepSeekMath-7B-MetaMath | 43.7 | 81.8 | 33.7 | 53.0 | 13.6 | 23.2 | 41.5 |
| DeepSeekMath-7B-RL | 53.1 | 88.4 | 41.3 | 58.3 | 18.7 | 35.9 | 49.3 |
DART-Math-DSMath-7B |
53.6 | 86.8 | 40.7 | 61.6 | 21.7 | 32.2 | 49.4 |
| Mistral-7B-MetaMath | 29.8 | 76.5 | 19.3 | 28.0 | 5.9 | 14.0 | 28.9 |
DART-Math-Mistral-7B |
45.5 | 81.1 | 29.4 | 45.1 | 14.7 | 17.0 | 38.8 |
| Llama3-8B-MetaMath | 32.5 | 77.3 | 20.6 | 35.0 | 5.5 | 13.8 | 30.8 |
DART-Math-Llama3-8B |
46.6 | 81.1 | 28.8 | 48.0 | 14.5 | 19.4 | 39.7 |
Abbreviations: College (CollegeMath), DM (DeepMind
Mathematics), Olympiad (OlympiadBench-Math), Theorem (TheoremQA).
Bold means the best score by SFT on the respective base model here.
DART-Math models here are fine-tuned on the DART-Math-Hard
dataset.
DART-Math are the state-of-the-art and data-efficient
open-source instruction tuning datasets for mathematical reasoning.
Most of previous datasets are constructed with ChatGPT, and many of them are not open-source, especially for ones of the best performance.
| Math SFT Dataset | # of Samples | MATH | GSM8K | College | Synthesis Agent(s) | Open-Source |
|---|---|---|---|---|---|---|
| WizardMath | 96k | 32.3 | 80.4 | 23.1 | GPT-4 | ✗ |
| MetaMathQA | 395k | 29.8 | 76.5 | 19.3 | GPT-3.5 | ✓ |
| MMIQC | 2294k | 37.4 | 75.4 | 28.5 | GPT-4+GPT-3.5+Human | ✓ |
| Orca-Math | 200k | – | – | – | GPT-4 | ✓ |
| Xwin-Math-V1.1 | 1440k | 45.5 | 84.9 | 27.6 | GPT-4 | ✗ |
| KPMath-Plus | 1576k | 46.8 | 82.1 | – | GPT-4 | ✗ |
| MathScaleQA | 2021k | 35.2 | 74.8 | 21.8 | GPT-3.5+Human | ✗ |
DART-Math-Uniform |
591k | 43.5 | 82.6 | 26.9 | DeepSeekMath-7B-RL | ✓ |
DART-Math-Hard |
585k | 45.5 | 81.1 | 29.4 | DeepSeekMath-7B-RL | ✓ |
MATH and GSM8K are in-domain, while College(Math) is out-of-domain. Performance here are of models fine-tuned from Mistral-7B, except for Xwin-Math-V1.1 based on Llama2-7B. Bold/Italic means the best/second best score here.
Our analysis of previous datasets reveals severe biases towards easy queries, with frequent failures to generate any correct response for the most challenging queries.
This primarily arises from their constuction method, vanilla rejection sampling, where the same number of responses are sampled for each query, yet the likelihood of obtaining correct responses for difficult queries is significantly lower, sometimes even zero.
Motivated by the observation above and the intuitive that difficult
samples are critical for learning complexing reasoning, we propose
Difficulty-Aware Rejection Sampling (DARS) to eliminate the bias
towards easy queries. Specifically, we introduce two strategies to
increase the number of correct responses for difficult queries:
-
Uniform, which involves sampling responses for each query until
each query accumulates
correct responses, where is a preset hyperparameter determined by the desired size of the synthetic dataset; -
Prop2Diff, where we continue sampling responses until the number
of correct responses for each query is proportional to its
difficulty score. The most challenging queries will receive
responses and kp is a hyperparameter. This method introduces a deliberate bias in the opposite direction to vanilla rejection sampling, towards more difficult queries, inspired by previous works that demonstrate difficult samples can be more effective to enhance model capabilities (Sorscher et al., 2022; Liu et al., 2024b).
See Figure 1
(Right)
for examples of DART-Math-Uniform by DARS-Uniform and
DART-Math-Hard by DARS-Prop2Diff.
We recommend using Conda and pip to manage your environment. Run the following commands to setup your environment:
git clone https://github.com/hkust-nlp/dart-math.git && cd dart-math
conda create --name dart-math --yes python=3.11
conda activate dart-math
pip install -r requirements.txt
pip install flash-attn --no-build-isolationFor common users/developers, please just run the following command the
install the dart-math package:
pip install -e "."For intended contributors, we recommend installing the package with the
dev extras:
pip install -e ".[dev]"
pre-commit install
conda install quarto -c conda-forge # for building the documentationWe implement an efficient training pipeline utilizing various techniques. Notably, sequence packing accelerates training by 6-8x in our setting and possibly more in other settings. (See how to integrate sequence packing in 4 lines of code.)
Please refer to
- the training Python
script
for code of training based on the HuggingFace
Trainerand utilizing sequence packing. - the
single-node/multi-node
training
bashscript for code of training based on HuggingFaceaccelerateanddeepspeed
Here, we provide some example commands as well as reproduction instructions for our work:
For example, to reproduce training DART-Math-Llama3-8B-Prop2Diff on a
node of 8 A100 GPUs, please run the following command:
bash scripts/train-single-node.sh \
--data_path "hkust-nlp/dart-math-hard" \
--model_path "meta-llama/Meta-Llama-3-8B" \
--lr "5e-5" --bs 64 --n_grad_acc_steps 1 --n_epochs 1 \
--gpu_ids "0,1,2,3,4,5,6,7" \
--output_dir "models/dart-math-llama3-8b-prop2diff"To reproduce other training settings, just refer to the paper and modify
the --data_path, --model_path, --lr, --n_grad_acc_steps,
--n_epochs and --output_dir arguments accordingly.
To reproduce training DART-Math-Llama3-70B-Prop2Diff on 4 nodes of 8
A100 GPUs, please first edit the cfgs/deepspeed/hostfile according to
your enviroment and then run the following command:
bash scripts/train-multi-node.sh \
--data_path "hkust-nlp/dart-math-hard" \
--model_path "meta-llama/Meta-Llama-3-70B" \
--lr "2e-5" --bs 64 --n_grad_acc_steps 1 --n_epochs 1 \
--n_nodes 4 \
--output_dir "models/dart-math-llama3-70b-prop2diff"To reproduce training DART-Math-Llama3-70B-Uniform on 4 nodes of 8
A100 GPUs, just change --data_path to "hkust-nlp/dart-math-uniform".
The off-the-shelf command to train DART-Math-Llama3-70B-Uniform
DART-Math-Llama3-70B-Uniformbash scripts/train-multi-node.sh \
--data_path "hkust-nlp/dart-math-uniform" \
--model_path "meta-llama/Meta-Llama-3-70B" \
--lr "2e-5" --bs 64 --n_grad_acc_steps 1 --n_epochs 1 \
--n_nodes 4 \
--output_dir "models/dart-math-llama3-70b-prop2diff"We utilize vLLM to accelerate inference and an elaborate answer extraction and correctness judgement pipeline based on regular expressions and SymPy symbolic calculation, which is able to correctly process
- most mathematical objects such as matrices (vectors), intervals, symbols besides numbers,
- as well as some special texts like bool expressions, dates and times.
For example, to reproduce one pass of greedy decoding with
DART-Math-Mistral-7B-Prop2Diff on the 6 benchmarks in Table 2 on GPU
0, please run the following command:
CUDA_VISIBLE_DEVICES="0" python pipeline/gen.py \
--gen_save_path "data/res/dart-math-mistral-7b-prop2diff.jsonl" \
--model_name_or_path "hkust-nlp/dart-math-mistral-7b-prop2diff" \
--datasets "math/test" "gsm8k/test" "mwpbench/college-math/test" "deepmind-mathematics" \
"olympiadbench/OE_TO_maths_en_COMP" "theoremqa" \
--max_new_toks 2048 --temperature 0 \
--prompt_template "cot" --n_shots -1 \
--inf_seed -1 \
--max_n_trials 1To reproduce other inference settings, just refer to the paper and
modify the --model_name_or_path and --gen_save_path arguments
accordingly.
- We observed that Llama-3-8B(-Base) tends to decode EoS immediately
sometimes. Try use
--ignore_eosas a workaround.
For other general inference settings, please modify the command or directly modify the script.
- To test base models, please add the corresponding ID to
BASE_MODEL_IDSfrom dart_math.utils. - To test instruct models, please add the corresponding prompt
template to
PROMPT_TEMPLATE_ID2DICTfrom dart_math.utils and specify with--prompt_template.
You can also add the --gen_only option to only generate responses
without evaluation and use the
EvaluatorMathBatch
to grade the generations by yourself. Please check the grading
script for example.
Our data synthesis pipeline is compatible with the evaluation pipeline,
please modify the --min_n_corrects and --max_n_trials arguments
to meet your needs.
For example, to reproduce the synthesis of DART-Math-Uniform,
amortizing the workload to multiple GPUs, please run the following
command:
gpu_ids_list=("0" "1" "2" "3" "4" "5" "6" "7")
min_n_corrects=40
min_n_corrects_per_gpu=$((min_n_corrects / ${#gpu_ids_list[@]})) # 5 here
mkdir -p logs
for gpu_ids in "${gpu_ids_list[@]}"; do
exp_name="dart-math-uniform-gpu${gpu_ids}"
CUDA_VISIBLE_DEVICES="${gpu_ids}" python pipeline/gen.py \
--gen_save_path "data/res/${exp_name}.jsonl" \
--model_name_or_path "deepseek-ai/deepseek-math-7b-rl" \
--datasets "math/train" "gsm8k-fix/train" \
--max_new_toks 2048 --temperature 1.6 --top_p 0.95 \
--prompt_template "deepseekmath" --n_shots 0 \
--inf_seed -1 \
--min_n_corrects "${min_n_corrects_per_gpu}" --max_n_trials 0 \
>"logs/${exp_name}.log" 2>&1 &
# NOTE: `--max_n_trials 0` means possible infinite trials, kill the job manually when needed
doneNOTE: Some erroneous labels exist in the GSM8K dataset, so we
tried to fix them and produced
gsm8k-fix.
To reproduce the data synthesis of the Vanilla Rejection Tuning (VRT)
baseline in the paper, just set
--max_n_trials 52 --min_n_corrects 0.
The off-the-shelf command to reproduce the synthesis of the Vanilla
Rejection Tuning (VRT) baseline in the paper
CUDA_VISIBLE_DEVICES="0" python pipeline/gen.py \
--gen_save_path "data/res/dart-math-uniform.jsonl" \
--model_name_or_path "deepseek-ai/deepseek-math-7b-rl" \
--datasets "math/train" "gsm8k-fix/train" \
--max_new_tokens 2048 --temperature 1.6 --top_p 0.95 \
--prompt_template "cot" --n_shots 0 \
--inf_seed -1 \
--max_n_trials 52 --min_n_corrects 0 # no requirement for correct responses
So sorry that it still need some manual efforts to reproduce the data
synthesis of DART-Math-Prop2Diff. For now, please follow the
instructions in the paper
DART-Math-Prop2Diff. For now, please follow the
instructions in the paper- Calculate “fail rate” (
1-pass_rate) for each query in MATH and GSM8K training sets (see thepass_ratefield of query information in MATH and GSM8K). - Calculate the target number of correct responses for each query in
the final training set. Note that we try to ensure at least one
correct response for each query in the
DART-Mathdatasets, which you could implement by rounding up when calculating the response number for each query. - Sample responses for each query until the target number of correct ones is met (thus proportional to its “fail rate”).
After the synthesis, you can use the curation script to curate the final dataset.
dart-math Package: Efficient and Flexible Training & Inference & Evaluation Pipelines
We package our code of effcient and flexible training & inference &
evaluation pipelines into dart-math and document it at this
website.
The dart-math package provides the following useful features besides
ones mentioned above:
Example command to evaluate DeepSeekMath-7B-RL with tool-integrated reasoning (following the DeepSeekMath offical setting):
CUDA_VISIBLE_DEVICES="0" python pipeline/gen.py \
--gen_save_path "data/res/dsmath-7b-rl-tool-math-test.jsonl" \
--model_name_or_path "deepseek-ai/deepseek-math-7b-rl" \
--datasets "math-test" \
--max_new_toks 2048 --temperature 0 \
--prompt_template "deepseekmath-tool" --n_shots 0 \
--max_n_calls 1 --trunc_len 50 50 \
--inf_seed -1 \
--max_n_trials 1
# Reproduced performance (with our evaluator): 56.08%
# (58.8% reported originally with DeepSeekMath evaluator)For other general inference settings, please modify the options related
to the Generator.code_exec_cfg
attribute
in the command or the
script.
dart-math
├── data
├── cfgs # Configurations
├── utils # Repository utilities
├── dart_math # Package code for common utilities
├── nbs # Notebooks and other files to run tests and generate documentation with https://nbdev.fast.ai
├── pipeline # Reusable (Python / Shell) scripts or notebooks
└── scripts # Setting-specific scripts
Run the prepare-commit.sh to clean the
notebooks and export scripts for pipeline notebooks, generate
documentation, run tests, render README if needed:
bash utils/prepare-commit.shPlease refer to the comments in the script for how it works.
- Add
if __name__ == "__main__":to scripts that might use vLLM tensor parallelism
Thanks to:
nbdevfor generating the wonderful documentation website,stanford_alpacafor reference code about training,functionaryfor reference code about sequence packing.- @HYZ17 for extensive tests and helpful suggestions.
If you find our data, model or code useful for your work, please kindly cite our paper:
@article{tong2024dartmath,
title={DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving},
author={Yuxuan Tong and Xiwen Zhang and Rui Wang and Ruidong Wu and Junxian He},
year={2024},
eprint={2407.13690},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.13690},
}