[docs] Doc sprint #3099
Merged
[docs] Doc sprint #3099
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
The docs for this PR live here. All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update. |
muellerzr
approved these changes
Sep 10, 2024
| # Utilities for Fully Sharded Data Parallelism | ||
| # Fully Sharded Data Parallel utilities | ||
|
|
||
| ## enable_fsdp_ram_efficient_loading |
There was a problem hiding this comment.
Wish we didn't have to do this everywhere but I suppose can't be helped :/
stevhliu
commented
Sep 11, 2024
|
|
||
| The general idea with pipeline parallelism is: say you have 4 GPUs and a model big enough it can be *split* on four GPUs using `device_map="auto"`. With this method you can send in 4 inputs at a time (for example here, any amount works) and each model chunk will work on an input, then receive the next input once the prior chunk finished, making it *much* more efficient **and faster** than the method described earlier. Here's a visual taken from the PyTorch repository: | ||
|
|
||
| 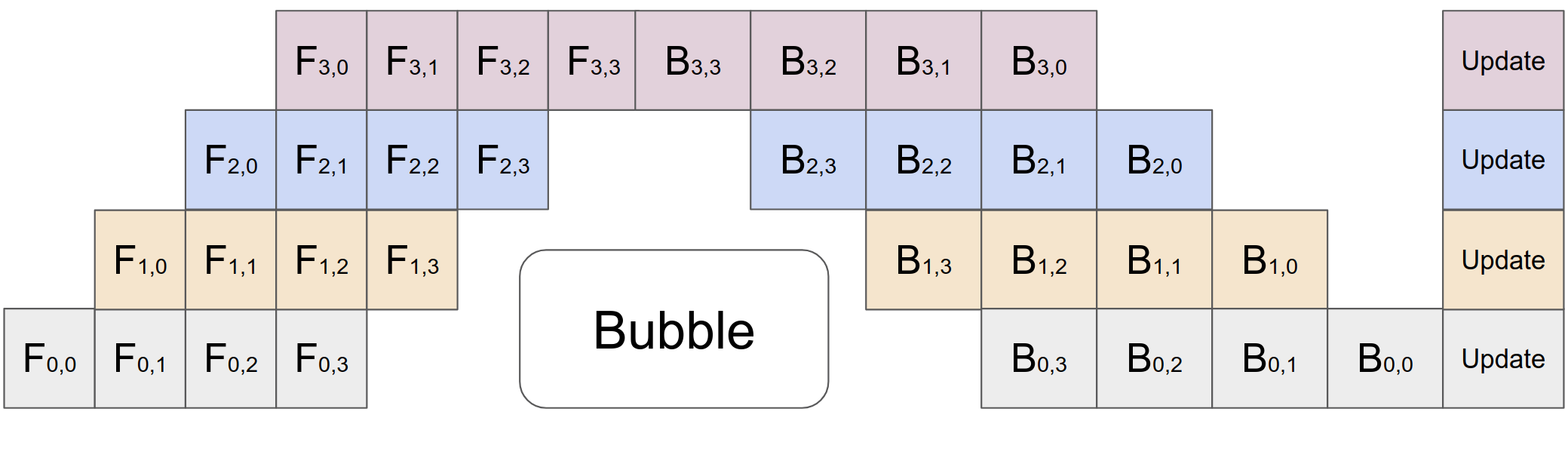 | ||
|
|
||
| To illustrate how you can use this with Accelerate, we have created an [example zoo](https://github.com/huggingface/accelerate/tree/main/examples/inference) showcasing a number of different models and situations. In this tutorial, we'll show this method for GPT2 across two GPUs. | ||
|
|
||
| Before you proceed, please make sure you have the latest pippy installed by running the following: | ||
| Before you proceed, please make sure you have the latest PyTorch version installed by running the following: |
There was a problem hiding this comment.
I also updated the installation instructions here, let me know if its incorrect!
There was a problem hiding this comment.
in a follow-up after this I'll fix the PiPPy example chunk so we don't have a merge conflict :)
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Addresses the docs improvements internally discussed:
<Note>tagstoctreewith the header referenced in the doc