Add visual-question-answering docs
#382
Conversation
 merveenoyan
left a comment
merveenoyan
left a comment
There was a problem hiding this comment.
Thanks a lot for working on this, left minor comments 🙂 overall it's very good!
(also got it on my local, it looks nice! 🙂)

| ], | ||
| models: [ | ||
| { | ||
| description: "Vision-and-Language Transformer (ViLT) model fine-tuned on VQAv2", |
There was a problem hiding this comment.
Can you simplify this explanation? We try to put ourselves in the shoes of a person that doesn't know machine learning.
Something along the lines of "Robust model trained on visual question answering task."
There was a problem hiding this comment.
You are totally right!
| score: 0.009, | ||
| }, | ||
| { | ||
| label: "1", |
There was a problem hiding this comment.
The probabilities don't add up to one? 😅 also maybe for simplicity we could keep it to yes and no only, what do you think? 🙂
There was a problem hiding this comment.
The probabilities don't have to add up to 1 since they are not mutually exclusive for more complex questions, such as "what is on top of ...".
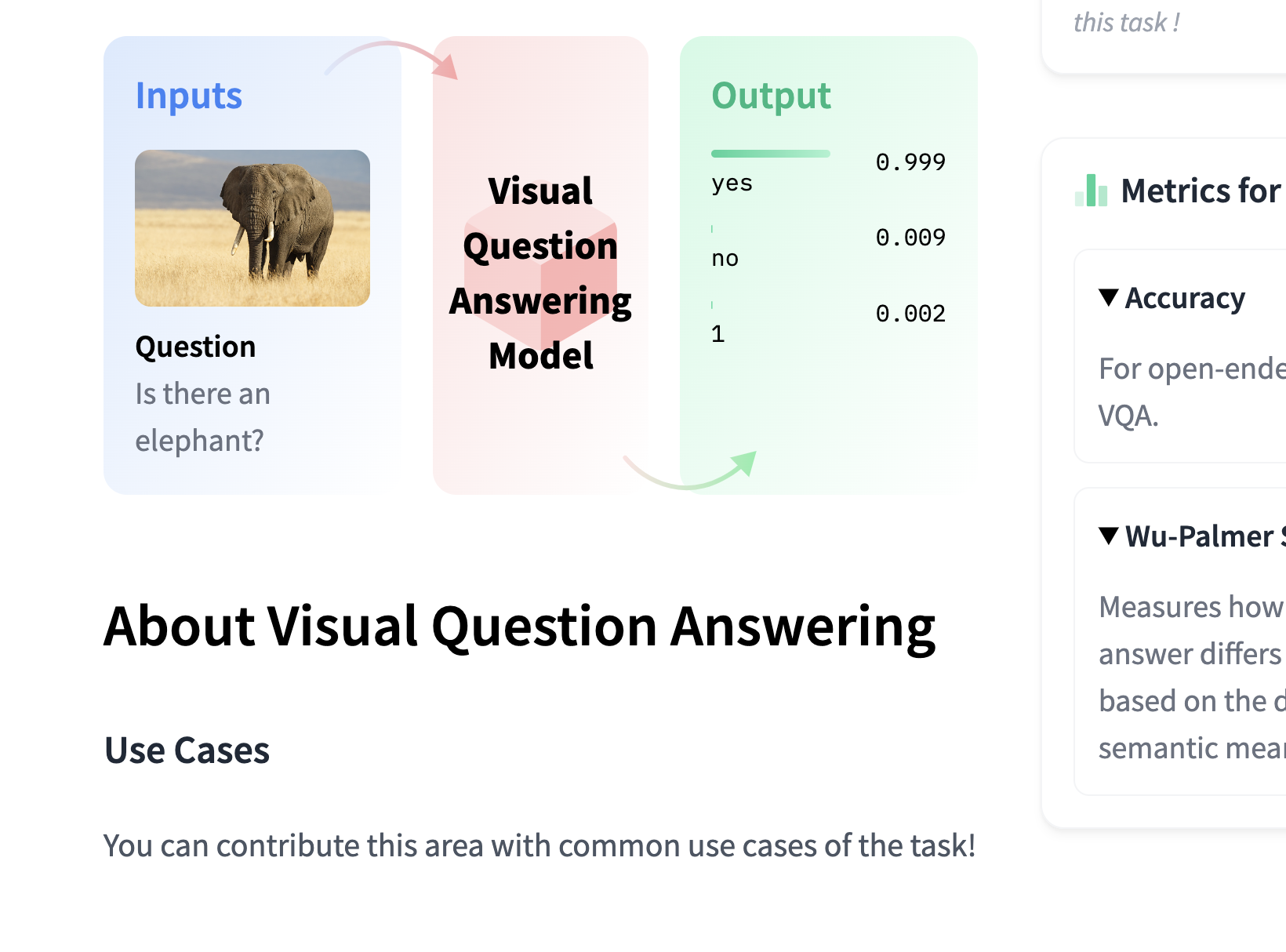
Here's the output of the specific model:
>>> image = Image.open("assets/elephant.jpeg")
>>> question = "Is there an elephant?"
>>> vqa_pipeline(image, question, top_k=3)
[{'score': 0.9998154044151306, 'answer': 'yes'},
{'score': 0.009802112355828285, 'answer': 'no'},
{'score': 0.0020384755916893482, 'answer': '1'}]Do you think it would make it more clear if we increase the number of outputs top_k to make the sum go way over 1 so this is not confusing?
I thought about removing the "1" label too, but decided to keep it because it kind of showed that VQA's outputs are not just binary. Maybe we could show this better by asking a different question, such as "where is the elephant?".
There was a problem hiding this comment.
@jlondonob sure, you can also include a better input not asking for a yes/no question but something more like "What's in this image?" Thanks a lot for the explanation!
| metrics: [ | ||
| { | ||
| description: "For open-ended and multiple-choice VQA.", | ||
| id: "Accuracy", |
There was a problem hiding this comment.
you can simply write accuracy and leave it like that, as they get retrieved from https://huggingface.co/metrics if the metric exists there.
Improved redaction of use cases Co-authored-by: Merve Noyan <merveenoyan@gmail.com>
merveenoyan
left a comment
There was a problem hiding this comment.
I only left two comments, will be happy to merge once we discuss & address it 🤗 thanks a lot for the great work!
| ## Use Cases | ||
|
|
||
| ### Automatic Medical Diagnostic | ||
| Visual Question Answering (VQA) models can be used to help clinical staff diagnose conditions. For example, a doctor could input an MRI scan to the model and ask "what does this MRI scan show?" and get the answer to their question. |
There was a problem hiding this comment.
We discussed with @meg-huggingface about this (given she studied ethical side of VQA task) it's better if we don't include this (the model can pick up spurious cues and might answer questions wrongly in life critical situations)
| VQA models can be used to reduce visual barriers for visually impaired individuals by allowing them to get information about images from the web and the real world. | ||
|
|
||
| ### Unattended Surveillance | ||
| Video Question Answering can be used to quickly extract valuable information from surveillance recordings. |
There was a problem hiding this comment.
For this one, I think a basic activity detection model would be enough and VQA is too overkill.
|
@jlondonob do you need help on this? 🤗 |
|
@merveenoyan sorry for the delay, I'm on vacation and forgot to complete these changes. I'll get them done today. |
|
@jlondonob ah didn't want to make you feel in a rush or anything, sometimes contributors want help but are too shy to ask for it so I thought I'd ask you if you need one 😅 |
|
@merveenoyan Thanks for your constant help 🚀! I removed the Do you think the PR is ready to be merged? |
merveenoyan
left a comment
There was a problem hiding this comment.
Let's get this merged!
|
@jlondonob what is your HF user name? I will add your name at the end to give you credits before we deploy it 🤗 congratulations on the merger!!! ✨ |
|
@merveenoyan thanks a lot! My HF username is |
Summary
Added
about.mdanddata.tsto thevisual-question-answeringdocumentation. This PR partially fixes #362.Questions
I wrote the Use Cases section as "this model can be used to..." instead of "this model is used to..." since use cases for Visual Question Answering are still somewhat experimental. Would you like to use the later as most of the other tasks do?