Fix Adafactor documentation (recommend correct settings) #10526
Conversation
Fix documentation to reflect optimal settings for Adafactor
|
Is this part correct?
In particular:
|
|
@sshleifer can you accept this documentation change? |
|
No but @stas00 can! |
|
@jsrozner, thank you for the PR. Reading #7789 it appears that the So if we are fixing this, in addition to changing the example the prose above it should be synced as well. I don't know where the original recommendation came from - do you by chance have a source we could point to for the corrected recommendation? If you know that is, if not, please don't worry. Thank you. |
|
I receive the following error when using this the "recommended way": Following this example in documentation: |
|
@alexvaca0, what was the command line you run when you received this error? HF Trainer doesn't set transformers/src/transformers/trainer.py Lines 649 to 651 in 21e86f9 It is possible that the whole conflict comes from misunderstanding how this optimizer has to be used?
which is what the Trainer does at the moment. and:
Is it possible that you are trying to use both an external and the internal scheduler at the same time? It'd help a lot of you could show us the code that breaks, (perhaps on colab?) and how you invoke it. Basically, help us reproduce it. Thank you. |
|
Hi, @stas00 , first thank you very much for looking into it so fast. I forgot to say it, but yes, I changed the code in Trainer because I was trying to use the recommended settings for training T5 (I mean, setting an external learning rate with warmup_init = True as in the documentation. |
|
OK, so first, as @jsrozner PR goes and others commented, the current recommendation appears to be invalid. So we want to gather all the different combinations that work and identify which of them provides the best outcome. I originally replied to this PR asking if someone knows of an authoritative paper we could copy the recommendation from - i.e. finding someone who already did the quality studies, so that we won't have it. So I'm all ears if any of you knows of such source. Now to your commentary, @alexvaca0, while HF trainer has Adam as the default it has For me personally I want to understand first the different combinations, what are the impacts and how many of those combinations should we expose through the Trainer. e.g. like apex optimization level, we could have named combos Would any of the current participants be interested in taking a lead on that? I'm asking you since you are already trying to get the best outcome with your data and so are best positioned to judge which combinations work the best for what situation. Once we compiled the data it'd be trivial to update the documented recommendation and potentially extend HF Trainer to support more than one setting for Adafactor. |
|
I only ported the
In retrospect, I shouldn't have ported the Adafactor option and it should have stayed just in the script using it. |
|
Thank you for your feedback, @sgugger. So let's leave the trainer as it is and let's then solve this for Adafactor as just an optimizer and then document the best combinations. |
|
Per my comment on #7789, I observed that
Given that relative_step and warmup_init must take on the same value, it seems like there is only one configuration that is working? But, this is also confusing (see my comment above): #10526 (comment)
|
|
I first validated that HF I then tried to find out the source of these recommendations and found:
If both found to be working, I propose we solve this conundrum by documenting this as following: https://discuss.huggingface.co/t/t5-finetuning-tips/684/22 Also highly recommends to turn And @jsrozner's correction in this PR is absolutely right to the point. Please let me know if my proposal makes sense, in particular I'd like your validation, @jsrozner, since I added your alternative proposal. And don't have any other voices to agree or disagree with it. Thank you! |
see my last comment - it depends on whether we use the external LR scheduler or not.
see my last comment - it depends on
this? |
|
I'm running some experiments, playing around with Adafactor parameters. I'll post here which configuration has best results. From T5 paper, they used the following parameters for fine-tuning: Adafactor with constant lr 1e-3, with batch size 128, if I understood the paper well. Therefore, I find it appropriate the documentation changes mentioned above, leaving the recommendations from the paper while mentioning other configs that have worked well for other users. In my case, for example, the configuration from the paper doesn't work very well and I quickly overfit. |
|
Finally, I'm trying to understand the confusing: As the paper explains these are 2 different types of clipping. Since the code is: this probably means that the default I can't find any mentioning of clip threshold in https://arxiv.org/abs/2004.14546 - is this a wrong paper? Perhaps it needed to link to the original paper https://arxiv.org/abs/1804.04235 where clipping is actually discussed? I think it's the param page 5 from https://arxiv.org/pdf/1804.04235:
So I will change the doc to a non-ambiguous:
|
|
OK, so here is the latest proposal. I re-organized the notes: I added these into this PR, please have a look. |
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
|
Let's just wait to hear from both @jsrozner and @alexvaca0 to ensure that my edits are valid before merging. |
|
I observed that And when I ran with Regarding clip_threshold - just confirming that the comment is correct that when using adafactor we should not have any other gradient clipping (e.g. Semi-related per @alexvaca0, regarding T5 paper's recommended batch_size: is the 128 recommendation agnostic to the length of input sequences? Or is there a target number of tokens per batch that would be optimal? (E.g. input sequences of max length 10 tokens vs input sequences of max length 100 tokens -- should we expect 128 to work optimally for both?) But most importantly, shouldn't we change the defaults so that a call to i.e, we default to what we suggest? |
Yes, please and thank you!
Thank you for validating this, @jsrozner Is the current incarnation of the doc clear wrt this subject matter or should we add an explicit example? One thing I'm concerned about is that the Trainer doesn't validate this and will happily run Might we need to add to: transformers/src/transformers/trainer.py Lines 649 to 651 in 9f8fa4e
Since we copied the code verbatim from fairseq, it might be a good idea to keep the defaults the same? I'm not attached to either way. @sgugger what do you think? edit: I don't think we can/should since it may break people's code that relies on the current defaults. |
Sorry, I didn't validate this. I wanted to confirm with you all that this is correct.
Alternative is to not provide defaults for these values and force the user to read documentation and decide what he/she wants. Can provide the default implementation as well as Adafactor's recommended settings |
@alexvaca0 |
I meant validating as in reading over and checking that it makes sense. So all is good. Thank you for extra clarification so we were on the same page, @jsrozner
as I appended to my initial comment, this would be a breaking change. So if it's crucial that we do that, this would need to happen in the next major release. |
|
Or maybe add a warning message that indicates that default params may not be optimal? It will be logged only a single time at optimizer init so not too annoying.
|
|
But we now changed it propose two different ways - which one is the recommended one? The one used by the Trainer? Since it's pretty clear that there is more than one way, surely the user will find their way to the doc if they aren't happy with the results. |
|
I ran my model under three different adafactor setups: optimizer = Adafactor(self.model.parameters(),
relative_step=True,
warmup_init=True)optimizer = Adafactor(self.model.parameters(),
relative_step=True,
warmup_init=True,
scale_parameter=False) optimizer = Adafactor(self.model.parameters(),
lr=1e-3,
relative_step=False,
warmup_init=False,
scale_parameter=False)I track exact match and NLL on the dev set. Epochs are tracked at the bottom. They start at 11 because of how I'm doing things. (i.e. x=11 => epoch=1) Note that I'm training a t5-small model on 80,000 examples, so maybe there's some variability with the sort of model we're training? (Image works if you navigate to the link, but seems not to appear?) purple is (1) In particular, it looks like scale_param should be True for the setting under " Others reported the following combination to work well::" On the other hand, it looks like for a t5-large model, (3) does better than (1) (although I also had substantially different batch sizes). |
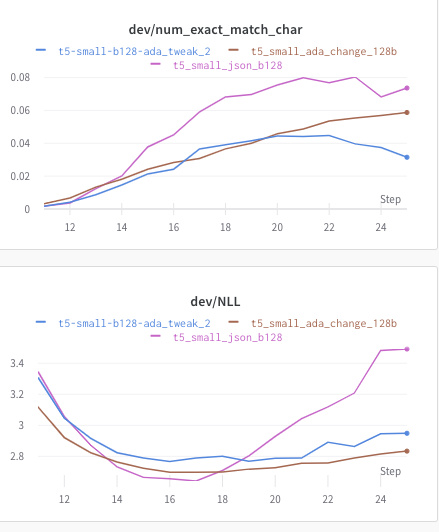
|
Thank you, @jsrozner, for running these experiments and the analysis. So basically we should adjust " Others reported the following combination to work well::" to Interestingly we end up with 2 almost total opposites. |
|
@jsrozner Batch size and learning rate configuration go hand in hand, therefore it's difficult to know about your last reflexion, as having different different batch sizes lead to different gradient estimations (in particular, the lower the batch size, the worse your gradient estimation is), the larger your batch size, the larger your learning rate can be without negatively affecting performance. |
|
OK, let's merge this and if we need to make updates for any new findings we will do it then. |
|
Although I didn't really run an experiment, I have found that my settings for adafactor (relative step, warmup, scale all true) do well when training t5-large, also. @alexvaca0 please post your results when you have them! |
* Add more metadata to the user agent (#10972)
* Add more metadata to the user agent
* Fix typo
* Use DISABLE_TELEMETRY
* Address review comments
* Use global env
* Add clean envs on circle CI
* Enforce string-formatting with f-strings (#10980)
* First third
* Styling and fix mistake
* Quality
* All the rest
* Treat %s and %d
* typo
* Missing )
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* add notebook (#10995)
* Merge trainers (#10975)
* Replace is_sagemaker_distributed_available
* Merge SageMakerTrainer into Trainer
* Test with shorter condition
* Put back deleted line
* Deprecate SageMakerTrainer and SageMakerTrainingArguments
* Apply suggestions from code review
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
* add blog to docs (#10997)
* Update training_args.py (#11000)
In the group by length documentation length is misspelled as legnth
* Add `examples/language_modeling/run_mlm_no_trainer.py` (#11001)
* Add initial script for finetuning MLM models with accelerate
* Add evaluation metric calculation
* Fix bugs
* Use no_grad on evaluation
* update script docstring
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* PR feedback
* Fix CI failure
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix Adafactor documentation (recommend correct settings) (#10526)
* Update optimization.py
Fix documentation to reflect optimal settings for Adafactor
* update and expand on the recommendations
* style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* flip scale_parameter to True for the 2nd recommendatoin
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Improve the speed of adding tokens from added_tokens.json (#10780)
* use bisect to add one token to unique_no_split_tokens
* fix style
* Add Vision Transformer and ViTFeatureExtractor (#10950)
* Squash all commits into one
* Update ViTFeatureExtractor to use image_utils instead of torchvision
* Remove torchvision and add Pillow
* Small docs improvement
* Address most comments by @sgugger
* Fix tests
* Clean up conversion script
* Pooler first draft
* Fix quality
* Improve conversion script
* Make style and quality
* Make fix-copies
* Minor docs improvements
* Should use fix-copies instead of manual handling
* Revert "Should use fix-copies instead of manual handling"
This reverts commit fd4e591bce4496d41406425c82606a8fdaf8a50b.
* Place ViT in alphabetical order
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* DebertaTokenizer Rework closes #10258 (#10703)
* closes #10258
* typo
* reworked deberta test
* implemented the comments from BigBird01 regarding sequence pair encoding of deberta
* Update style
* VOCAB_FILES_NAMES is now a oneliner as suggested by @sgugger
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* added #fmt: on as requested by @sgugger
* Style
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* minor typo fix
*negative* log-likelihood
* [doc] no more bucket
* added new notebook and merge of trainer (#11015)
* added new notebook and merge of trainer
* Update docs/source/sagemaker.md
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fixed typo: logging instead of logger (#11025)
* Add a script to check inits are consistent (#11024)
* s|Pretrained|PreTrained| (#11048)
* [doc] update code-block rendering (#11053)
double : prevents code-block section to be rendered, so made it single :
* Pin docutils (#11062)
* Pin docutils
* Versions table
* Remove unnecessary space (#11060)
* Some models have no tokenizers (#11064)
* Refactor AutoModel classes and add Flax Auto classes (#11027)
* Refactor AutoModel classes and add Flax Auto classes
* Add new objects to the init
* Fix hubconf and sort models
* Fix TF tests
* Missing coma
* Update src/transformers/models/auto/auto_factory.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Fix init
* Fix dummies
* Other init to fix
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Documentation about loading a fast tokenizer within Transformers (#11029)
* Documentation about loading a fast tokenizer within Transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add example for registering callbacks with trainers (#10928)
* Add example for callback registry
Resolves: #9036
* Update callback registry documentation
* Added comments for other ways to register callback
* Add `examples/language_modeling/run_clm_no_trainer.py` (#11026)
* Initial draft for clm no trainer
* Remove unwanted args
* Fix bug
* Update examples/language-modeling/run_clm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace pkg_resources with importlib_metadata (#11061)
* Replace pkg_resources with importlib_metadata
Fixes #10964. The other reason for this change is that pkg_resources has been [deprecated](https://github.com/pypa/setuptools/commit/8fe85c22cee7fde5e6af571b30f864bad156a010) in favor of importlib_metadata.
* Reduce to a single importlib_metadata import switch
* Trigger CI
Co-authored-by: Stas Bekman <stas@stason.org>
* Add center_crop to ImageFeatureExtractoMixin (#11066)
* Document common config attributes (#11070)
* Fix distributed gather for tuples of tensors of varying sizes (#11071)
* Make a base init in FeatureExtractionMixin (#11074)
* Add Readme for language modeling scripts with accelerate (#11073)
* HF emoji unicode doesn't work in console (#11081)
It doesn't look like using 🤗 is a great idea for printing to console. See attachment.
This PR proposes to replace 🤗 with "HuggingFace" for an exception message.
@LysandreJik
* Link to new blog
* added social thumbnail for docs (#11083)
* added new merged Trainer test (#11090)
* [WIP] GPT Neo cleanup (#10985)
* better names
* add attention mixin
* all slow tests in one class
* make helper methods static so we can test
* add local attention tests
* better names
* doc
* apply review suggestions
* Release v4.5.0
* Development on v4.6.0dev0
* [doc] gpt-neo (#11098)
make the example work
* Auto feature extractor (#11097)
* AutoFeatureExtractor
* Init and first tests
* Tests
* Damn you gitignore
* Quality
* Defensive test for when not all backends are here
* Use pattern for Speech2Text models
* accelerate question answering examples with no trainer (#11091)
* accelerate question answering examples with no trainer
* removed train and eval flags also fixed fill np array function
* Update examples/question-answering/run_qa_beam_search_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update examples/question-answering/run_qa_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Style
* dead link fixed (#11103)
* GPTNeo: handle padded wte (#11079)
* GPTNeo: handle padded wte
* Switch to config.vocab_size
* apply review suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* fix: The 'warn' method is deprecated (#11105)
* The 'warn' method is deprecated
* fix test
* [examples] fix white space (#11099)
these get concatenated without whitespace, so fix it
* Dummies multi backend (#11100)
* Replaces requires_xxx by one generic method
* Quality and update check_dummies
* Fix inits check
* Post-merge cleanup
* Some styling of the training table in Notebooks (#11118)
* Adds a note to resize the token embedding matrix when adding special … (#11120)
* Adds a note to resize the token embedding matrix when adding special tokens
* Remove superfluous space
* fix tests (#11109)
* [versions] handle version requirement ranges (#11110)
* handle version requirement ranges
* add mixed requirement test
* cleanup
* Adds use_auth_token with pipelines (#11123)
* added model_kwargs to infer_framework_from_model
* added model_kwargs to tokenizer
* added use_auth_token as named parameter
* added dynamic get for use_auth_token
* Fix and refactor check_repo (#11127)
* Fix typing error in Trainer class (prediction_step) (#11138)
* fix: docstrings in prediction_step
* ci: Satisfy line length requirements
* ci: character length requirements
* Typo fix of the name of BertLMHeadModel in BERT doc (#11133)
* [run_clm] clarify why we get the tokenizer warning on long input (#11145)
* clarify why we get the warning here
* Update examples/language-modeling/run_clm.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wording
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] ZeRO Stage 3 (#10753)
* synced gpus
* fix
* fix
* need to use t5-small for quality tests
* notes
* complete merge
* fix a disappearing std stream problem
* start zero3 tests
* wip
* tune params
* sorting out the pre-trained model loading
* reworking generate loop wip
* wip
* style
* fix tests
* split the tests
* refactor tests
* wip
* parameterized
* fix
* workout the resume from non-ds checkpoint pass + test
* cleanup
* remove no longer needed code
* split getter/setter functions
* complete the docs
* suggestions
* gpus and their compute capabilities link
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* style
* remove invalid paramgd
* automatically configure zero3 params that rely on hidden size
* make _get_resized_embeddings zero3-aware
* add test exercising resize_token_embeddings()
* add docstring
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Add nvidia megatron models (#10911)
* Add support for NVIDIA Megatron models
* Add support for NVIDIA Megatron GPT2 and BERT
Add the megatron_gpt2 model. That model reuses the existing GPT2 model. This
commit includes a script to convert a Megatron-GPT2 checkpoint downloaded
from NVIDIA GPU Cloud. See examples/megatron-models/README.md for details.
Add the megatron_bert model. That model is implemented as a modification of
the existing BERT model in Transformers. This commit includes a script to
convert a Megatron-BERT checkpoint downloaded from NVIDIA GPU Cloud. See
examples/megatron-models/README.md for details.
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Remove model.half in tests + add "# Copied ..."
Remove the model.half() instruction which makes tests fail on the CPU.
Add a comment "# Copied ..." before many classes in the model to enable automatic
tracking in CI between the new Megatron classes and the original Bert ones.
* Fix issues
* Fix Flax/TF tests
* Fix copyright
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update docs/source/model_doc/megatron_bert.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update docs/source/model_doc/megatron_gpt2.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/__init__.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Resolve most of 'sgugger' comments
* Fix conversion issue + Run make fix-copies/quality/docs
* Apply suggestions from code review
* Causal LM & merge
* Fix init
* Add CausalLM to last auto class
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [trainer] solve "scheduler before optimizer step" warning (#11144)
* solve "scheduler before optimizer step" warning
* style
* correct the state evaluation test
* Add fairscale and deepspeed back to the CI (#11147)
* Add fairscale and deepspeed back to the CI
* Add deepspeed to single GPU tests
* Updates SageMaker docs for updating DLCs (#11140)
* Don't duplicate logs in TensorBoard and handle --use_env (#11141)
* Run mlm pad to multiple for fp16 (#11128)
* Add mlm collator pad to multiple option (#10627)
* Use padding to 8x in run mlm (#10627)
* [tests] relocate core integration tests (#11146)
* relocate core integration tests
* add sys.path context manager
* cleanup
* try
* try2
* fix path
* doc
* style
* add dep
* add 2 more deps
* [setup] extras[docs] must include 'all' (#11148)
* extras[doc] must include 'all'
* fix
* better
* regroup
* Add support for multiple models for one config in auto classes (#11150)
* Add support for multiple models for one config in auto classes
* Use get_values everywhere
* Prettier doc
* [setup] make fairscale and deepspeed setup extras (#11151)
* make fairscale and deepspeed setup extras
* fix default
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* no reason not to ask for the good version
* update the CIs
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Skip Megatron tests for now
* typo (#11152)
* typo
* style
* [Community notebooks] Add Wav2Vec notebook for creating captions for YT Clips (#11142)
* Add Wav2Vec Inference notebook
* Update docs/source/community.md
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Fix LogitsProcessor documentation (#11130)
* Change duplicated LogitsProcessor to LogitsWarper in LogitsProcessorList document
* Write more detailed information about LogitsProcessor's scores argument
* apply suggestion from review
* style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Update README.md (#11161)
Corrected a typo ('Downlowd' to 'Download')
* Make `get_special_tokens_mask` consider all tokens (#11163)
* Add a special tokenizer for CPM model (#11068)
* Add a special tokenizer for CPM model
* make style
* fix
* Add docs
* styles
* cpm doc
* fix ci
* fix the overview
* add test
* make style
* typo
* Custom tokenizer flag
* Add REAMDE.md
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [examples/translation] support mBART-50 and M2M100 fine-tuning (#11170)
* keep a list of multilingual tokenizers
* add forced_bos_token argument
* [examples run_clm] fix _LazyModule hasher error (#11168)
* fix _LazyModule hasher error
* reword
* added json dump and extraction of train run time (#11167)
* added json dump and extraction of train run time
* make style happy
* Fix Typo
* Reactivate Megatron tests an use less workers
* Minor typos fixed (#11182)
* Fix style
* model_path should be ignored as the checkpoint path (#11157)
* model_path is refered as the path of the trainer, and should be ignored as the checkpoint path.
* Improved according to Sgugger's comment.
* Added documentation for data collator. (#10941)
* Added documentation for data collator.
* Update docs/source/data_collator.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Added documentation for data collator.
* Added documentation for the data collator.
* Merge branch 'doc_DataCollator' of C:\Users\mahii\PycharmProjects\transformers with conflicts.
* Update documentation for the data collator.
* Update documentation for the data collator.
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
* Fix typo (#11188)
* Add DeiT (PyTorch) (#11056)
* First draft of deit
* More improvements
* Remove DeiTTokenizerFast from init
* Conversion script works
* Add DeiT to ViT conversion script
* Add tests, add head model, add support for deit in vit conversion script
* Update model checkpoint names
* Update image_mean and image_std, set resample to bicubic
* Improve docs
* Docs improvements
* Add DeiTForImageClassificationWithTeacher to init
* Address comments by @sgugger
* Improve feature extractors
* Make fix-copies
* Minor fixes
* Address comments by @patil-suraj
* All models uploaded
* Fix tests
* Remove labels argument from DeiTForImageClassificationWithTeacher
* Fix-copies, style and quality
* Fix tests
* Fix typo
* Multiple docs improvements
* More docs fixes
* Replaced `which` with `who` (#11183)
* Import torch.utils.checkpoint in ProphetNet (#11214)
* Sagemaker test docs update for framework upgrade (#11206)
* increased train_runtime for model parallelism
* added documentation for framework upgrade
* Use MSELoss in (M)BartForSequenceClassification (#11178)
* wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model (#11041)
* add vocab while converting wav2vec2 original finetuned model
* check save directory exists
* return_attention_mask fix
* quality
* Add Matt as the TensorFlow reference (#11212)
* Fix GPT-2 warnings (#11213)
* Fix GPT-2 warnings
* Update src/transformers/models/gpt2/modeling_gpt2.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* fix docstrings (#11221)
* Add documentation for BertJapanese (#11219)
* Start writing BERT-Japanese doc
* Fix typo, Update toctree
* Modify model file to use comment for document, Add examples
* Clean bert_japanese by make style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Split a big code block into two
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add prefix >>> to all lines in code blocks
* Clean bert_japanese by make fixup
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace error by warning when loading an architecture in another (#11207)
* Replace error by warning when loading an architecture in another
* Style
* Style again
* Add a test
* Adapt old test
* Document v4.5.1
* Refactor GPT2 (#11225)
* refactor GPT2
* fix mlp and head pruning
* address Sylvains comments
* apply suggestion from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Doc check: a bit of clean up (#11224)
* added cache_dir=model_args.cache_dir to all example with cache_dir arg (#11220)
* Avoid using no_sync on SageMaker DP (#11229)
* Indent code block in the documentation (#11233)
* Indent code block
* Indent code blocks version 2
* Quality
* Run CI on deepspeed and fairscale (#11172)
* Run CI on deepspeed and fairscale
* Test it on this branch :)
* Rename
* Update the CI image
* [Deepspeed] zero3 tests band aid (#11235)
* temp band-aid
* style
* Save the Wav2Vec2 processor before training starts (#10910)
Co-authored-by: nithin19 <nithin@amberscript.com>
* make embeddings plural in warning message (#11228)
* Stale bot updated (#10562)
* Updated stale bot
* Specify issue number
* Remove particular handling of assignees
* Unleash the stalebot
* Remove debug branch
* Close open files to suppress ResourceWarning (#11240)
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
* Fix dimention misspellings. (#11238)
* Update modeling_gpt_neo.py
dimention -> dimension
* Update configuration_speech_to_text.py
dimention -> dimension
* Add prefix to examples in model_doc rst (#11226)
* Add prefix to examples in model_doc rst
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [troubleshooting] add 2 points of reference to the offline mode (#11236)
* add 2 points of reference to the offline mode
* link the new doc
* add error message
* Update src/transformers/modeling_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
* rename
* Trigger CI
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix #10128 (#11248)
* [deepspeed] test on one node 2 gpus max (#11237)
* test on one node 2 gpus max
* fix the other place
* refactor
* fix
* cleanup
* more exact version
* Trainer iterable dataset (#11254)
* IterableDatasetShard
* Test and integration in Trainer
* Update src/transformers/trainer_pt_utils.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Style
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding pipeline task aliases. (#11247)
* Adding task aliases and adding `token-classification` and
`text-classification` tasks.
* Cleaning docstring.
* Support for set_epoch (#11258)
* Tokenizer fast save (#11234)
* Save fast tokenizers in both formats
* Fix for HerBERT
* Proper fix
* Properly test new behavior
* update dependency_versions_table (#11273)
missed this updating when bumped the version.
* Workflow fixes (#11270)
* Enabling multilingual models for translation pipelines. (#10536)
* [WIP] Enabling multilingual models for translation pipelines.
* decoder_input_ids -> forced_bos_token_id
* Improve docstring.
* Rebase
* Fixing 2 bugs
- Type token_ids coming from `_parse_and_tokenize`
- Wrong index from tgt_lang.
* Fixing black version.
* Adding tests for _build_translation_inputs and add them for all
tokenizers.
* Mbart actually puts the lang code at the end.
* Fixing m2m100.
* Adding TF support to `deep_round`.
* Update src/transformers/pipelines/text2text_generation.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Adding one line comment.
* Fixing M2M100 `_build_translation_input_ids`, and fix the call site.
* Fixing tests + deep_round -> nested_simplify
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix failing workflows
* Trainer support for IterableDataset for evaluation and predict (#11286)
* Bulk of the work
* Polish and tests
* Update QA Trainer
* Avoid breaking the predict method
* Deprecation warnings
* Store real eval dataloder
* Get eval dataset reference before wrap
* move device statements outside if statements (#11292)
* modify double considering special tokens in `language_modeling.py` (#11275)
* Update language_modeling.py
in "class TextDatasetForNextSentencePrediction(Dataset)", double considering "self.tokenizer.num_special_tokens_to_add(pair=True)"
so, i remove self.block_size, and add parameter for "def create_examples_from_document". like "class LineByLineWithSOPTextDataset" do
* Update language_modeling.py
* [Trainer] fix the placement on device with fp16_full_eval (#11322)
* fix the placement on device with fp16_full_eval
* deepspeed never goes on device
* [Trainer] Add a progress bar for batches skipped (#11324)
* Load checkpoint without re-creating the model (#11318)
* Added translation example script (#11196)
* initial changes
* modified evaluation
* updated evaluation
* updated evaluation on text translation example script
* added translation example script
* Formatted translation example script
* Reformatted translation example
* Fixed evaluation bug and added support for other tokenisers
* Fixed evaluation bug and added support for other tokenisers
* Added translation example script
* Formatted summarization example script
* Removed typos from summarization example script
* [Generate] Remove outdated code (#11331)
* remove update function
* update
* refactor more
* refactor
* [GPTNeo] create local attention mask ones (#11335)
* create local attention mask ones
* remove old method, address patricks comment
* Update to use datasets remove_cloumns method (#11343)
* Update to use datasets remove_cloumns method
* Quality
* Add an error message that fires when Reformer is not in training mode, but one runs .backward() (#11117)
* Removed `max_length` from being mandatory within `generate`. (#11314)
* Removed `max_length` from being mandatory within `generate`.
- Moving on to fully using `StoppingCriteria` for `greedy` and `sample`
modes.
- `max_length` still used for `beam_search` and `group_beam_search`
(Follow up PR)
- Fixes a bug with MaxLengthStoppingCriteria (we should stop as soon a
we hit the max_length, the comparison needs to be or equal, that affects
the tests).
- Added options to use `logits_processor` and `stopping_criteria`
directly within `generate` function (so some users can define their own
`logits_processor` and `stopping_criteria`).
- Modified the backward compat tests to make sure we issue a warning.
* Fix `max_length` argument in `generate`.
* Moving validate to being functional.
- Renamed `smax_length` to `stoppping_max_length`.
* Removing `logits_processor` and `stopping_criteria` from `generate`
arguments.
* Deepcopy.
* Fix global variable name.
* Honor contributors to models (#11329)
* Honor contributors to models
* Fix typo
* Address review comments
* Add more authors
* [deepspeed] fix resume from checkpoint (#11352)
This PR fixes a bug that most likely somehow got exposed (not caused) by https://github.com/huggingface/transformers/pull/11318 - surprisingly the same test worked just fine before that other PR.
* Examples reorg (#11350)
* Base move
* Examples reorganization
* Update references
* Put back test data
* Move conftest
* More fixes
* Move test data to test fixtures
* Update path
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Address review comments and clean
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Extract metric_key_prefix during NotebookProgressCallback.on_evaluate (#11347)
* Pass metric_key_prefix as kwarg to on_evaluate
* Replace eval_loss with metric_key_prefix_loss
* Default to "eval" if metric_key_prefix not in kwargs
* Add kwargs to CallbackHandler.on_evaluate signature
* Revert "Add kwargs to CallbackHandler.on_evaluate signature"
This reverts commit 8d4c85ed512f558f7579d36771e907b3379947b7.
* Revert "Pass metric_key_prefix as kwarg to on_evaluate"
This reverts commit 7766bfe2718601230ae593d37b1317bd53cfc075.
* Extract metric_key_prefix from metrics
* [testing doc] bring doc up to date (#11359)
* bring doc up to date
* fix
* Merge new TF example script (#11360)
First of the new and more idiomatic TF examples!
* Remove boiler plate code (#11340)
* remove boiler plate code
* adapt roberta
* correct docs
* finish refactor
* Move old TF text classification script to legacy (#11361)
And update README to explain the work-in-progress!
* [contributing doc] explain/link to good first issue (#11346)
* explain/link to good first issue
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix token_type_ids error for big_bird model. (#11355)
* MOD: fit chinese wwm to new datasets
* MOD: move wwm to new folder
* MOD: formate code
* Styling
* MOD add param and recover trainer
* MOD: add token_type_ids method for big bird
* MOD: format code
* MOD: format code
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
* Add huggingface_hub dep for #11328
* Add in torchhub
* [Wav2Vec2] Fix special tokens for Wav2Vec2 tokenizer (#11349)
* fix wav2vec2 tok
* up
* [Flax] Correct typo (#11374)
* finish
* fix copy
* [run_translation.py] fix typo (#11372)
fix typo
Co-authored-by: johnson <johnson@github.com>
* Add space (#11373)
* Correctly cast num_train_epochs to int (#11379)
* Fix typo (#11369)
* Fix Trainer with remove_unused_columns=False (#11382)
* Fix Trainer with remove_unused_columns=False
* Typo
* [Flax] Big FlaxBert Refactor (#11364)
* improve flax
* refactor
* typos
* Update src/transformers/modeling_flax_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_flax_utils.py
* fix typo
* improve error tolerance
* typo
* correct nasty saving bug
* fix from pretrained
* correct tree map
* add note
* correct weight tying
* correct typo (#11393)
* correct conversion (#11394)
* Fix typo in text (#11396)
* fixed typos (#11391)
* make blenderbot test slow (#11395)
* Fixed trainer total_flos relaoding in distributed mode (#11383)
* Fixed trainer total_flos relaoding in distributed mode
* logging flos at the end of training
* Trainer push to hub (#11328)
* Initial support for upload to hub
* push -> upload
* Fixes + examples
* Fix torchhub test
* Torchhub test I hate you
* push_model_to_hub -> push_to_hub
* Apply mixin to other pretrained models
* Remove ABC inheritance
* Add tests
* Typo
* Run tests
* Install git-lfs
* Change approach
* Add push_to_hub to all
* Staging test suite
* Typo
* Maybe like this?
* More deps
* Cache
* Adapt name
* Quality
* MOAR tests
* Put it in testing_utils
* Docs + torchhub last hope
* Styling
* Wrong method
* Typos
* Update src/transformers/file_utils.py
Co-authored-by: Julien Chaumond <julien@huggingface.co>
* Address review comments
* Apply suggestions from code review
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* push (#11400)
* added support for exporting of t5 to onnx with past_key_values (#10651)
* Fixing bug in generation (#11297)
When passing `inputs_embeds` and not `input_ids=None` the generation function fails because `input_ids` is created but the function but it should not.
* Style
* Try to trigger failure more
* Wrong branch Sylvain...
* Fix cross-attention head mask for Torch encoder-decoder models (#10605)
* Fix cross-attention head mask for Torch BART models
* Fix head masking for cross-attention module for the following
models: BART, Blenderbot, Blenderbot_small, M2M_100, Marian, MBart,
Pegasus
* Enable test_headmasking for M2M_100 model
* Fix cross_head_mask for FSMT, LED and T5
* This commit fixes `head_mask` for cross-attention modules
in the following models: FSMT, LED, T5
* It also contains some smaller changes in doc so that
it is be perfectly clear the shape of `cross_head_mask`
is the same as of `decoder_head_mask`
* Update template
* Fix template for BartForCausalLM
* Fix cross_head_mask for Speech2Text models
* Fix cross_head_mask in templates
* Fix args order in BartForCausalLM template
* Fix doc in BART templates
* Make more explicit naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Fix doc
* make style quality
* Fix speech2text docstring
* Default to accuracy metric (#11405)
* Enable option for subword regularization in `XLMRobertaTokenizer` (#11149)
* enable subword regularization.
* fix tokenizer storage
* fix docstring formatting
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Stefan Schweter <stefan@schweter.it>
* fix docstring formatting
* add test for subword regularization tokenizer
* improve comments of test
* add sp_model_kwargs
* reformat docstring to match the style
* add some more documentation
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* improve docstring
* empty commit to trigger CI
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docstring formatting for sphinx
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Use 3 workers for torch tests
* documentation linked to the parent class PreTrainedTokenizerFast but it should be the slow tokenizer (#11410)
* Style
* Add head_mask, decoder_head_mask, cross_head_mask to ProphetNet (#9964)
* Add head_mask & decoder_head_mask + some corrections
* Fix head masking for N-grams
* Enable test_headmasking for encoder and decod
* Fix one typo regarding in modeling_propgetnet.py
* Enable test_headmasking for ProphetNetStandaloneDecoderModelTest
and ProphetNetStandaloneEncoderModelTest in test_modeling_prophetnet.py
* make style
* Fix cross_head_mask
* Fix attention head mask naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Still need to merge #10605 to master to pass the tests
* EncoderDecoderConfigs should not create new objects (#11300)
* removes the creation of separate config objects and uses the existing ones instead+overwrite resize_token_embeddings from parent class because it is not working for the EncoderDecoderModel
* rollback to current version of the huggingface master branch
* reworked version that ties the encoder and decoder config of the parent encoderdecoder instance
* overwrite of resize_token_embeddings throws an error now
* review comment suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* implemented warning in case encoderdecoder is created with differing configs of encoderdecoderconfig and decoderconfig or encoderconfig
* added test to avoid diverging configs of wrapper class and wrapped classes
* Update src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
* make style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* updating the checkpoint for GPT2ForSequence Classification to one with classification head (#11434)
* add pooling layer support (#11439)
* make style (#11442)
* Pin black to 20.8.b1
* With style
* Pin black to 21.4b0
* TF BART models - Add `cross_attentions` to model output and fix cross-attention head masking (#10699)
* Add cross_attn_head_mask to BART
* Fix cross_attentions in TFBart-like models
* This commit enables returning of `cross_attentions`
for TFBart-like models
* It also fixes attention head masking in cross-attenion module
* Update TF model templates
* Fix missing , in TF model templates
* Fix typo: congig -> config
* Add basic support for FP16 in SageMaker model parallelism (#11407)
* Add FP16 support for SageMaker MP
* Add print debugs
* Squeeze
* Remove debug statements
* Add defensive check
* Typo
* docs(examples): fix link to TPU launcher script (#11427)
* fix some typos in docs, comments, logging/errors (#11432)
* Pass along seed to DistributedSampler (#11406)
* Pass along seed to DistributedSampler
* Add seed to DistributedLengthGroupedSampler
* Clarify description of the is_split_into_words argument (#11449)
* Improve documentation for is_split_into_words argument
* Change description wording
* [docs] fix invalid class name (#11438)
* fix invalid class name
* proper ref
* proper ref
* make sure to test against the local checkout (#11437)
* Style
* Give each test a different repo name (#11453)
* [Examples] Fixes inconsistency around eval vs val and predict vs test (#11380)
* added changes for uniformity
* modified files
* corrected typo
* fixed qa scripts
* fix typos
* fixed predict typo in qa no trainer
* fixed test file
* reverted trainer changes
* reverted trainer changes in custom exmaples
* updated readme
* added changes in deepspeed test
* added changes for predict and eval
* Variable Correction for Consistency in Distillation Example (#11444)
As the error comes from the inconsistency of variable meaning number of gpus in parser and its actual usage in the train.py script, 'gpus' and 'n_gpu' respectively, the correction makes the example work
* [Deepspeed] ZeRO-Infinity integration plus config revamp (#11418)
* adding Z-inf
* revamp config process
* up version requirement
* wip
* massive rewrite
* cleanup
* cleanup
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* consistent json commas
* act on suggestions
* leave this feature for 0.3.16
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Remove max length beam scorer (#11378)
* removed max_len
* removed max_length from BeamSearchScorer
* correct max length
* finish
* del vim
* finish & add test
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* update QuickTour docs to reflect model output object (#11462)
* update docs to reflect model output object
* run make style`
* Finish Making Quick Tour respect the model object (#11467)
* finish quicktour
* fix import
* fix print
* explain config default better
* Update docs/source/quicktour.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docs for decoder_input_ids (#11466)
* fix docs for decoder_input_ids
* revert the changes for bart and mbart
* Update min versions in README and add Flax (#11472)
* Update min versions in README and add Flax
* Adapt index
* Update `PreTrainedTokenizerBase` to check/handle batch length for `text_pair` parameter (#11486)
* Update tokenization_utils_base.py
* add assertion
* check batch len
* Update src/transformers/tokenization_utils_base.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* add error message
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix #1149 (#11493)
* [Flax] Add docstrings & model outputs (#11498)
* add attentions & hidden states
* add model outputs + docs
* finish docs
* finish tests
* finish impl
* del @
* finish
* finish
* correct test
* apply sylvains suggestions
* Update src/transformers/models/bert/modeling_flax_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* simplify more
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Reformat to make code clearer in tokenizer call (#11497)
* Reformat to make code clearer
* Reformat to make code clearer
* solved coefficient issue for the TF version of gelu_fast (#11514)
Co-authored-by: Michael Benayoun <michael@huggingface.co>
* Split checkpoint from model_name_or_path in examples (#11492)
* Split checkpoint from model_name_or_path in examples
* Address review comments
* Address review comments
* Patch notification service
* Pin HuggingFace Hub dependency (#11502)
* correct the dimension comment of matrix multiplication (#11494)
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
* add sp_model_kwargs to unpickle of xlm roberta tok (#11430)
add test for pickle
simplify test
fix test code style
add missing pickle import
fix test
fix test
fix test
* make style (#11520)
* Update README.md (#11489)
Add link to code
* T5 Gradient Checkpointing (#11353)
* Implement gradient checkpoinging for T5Stack
* A bit more robust type checking
* Add `gradient_checkpointing` to T5Config
* Formatting
* Set requires_grad only when training
* None return value will only cause problems when training
* Change the output tuple according to `use_cache`
* Enable gradient checkpointing for the decoder
Squashed commit of the following:
commit 658bdd0bd1215353a8770f558bda2ea69a0ad0c7
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 14:08:17 2021 +0800
Only set `require_grad` for gradient checkpointing
commit acaeee6b2e675045fb28ce2176444c1d63e908bd
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 13:59:35 2021 +0800
Make gradient checkpointing work with the decoder
* Formatting
* Adding `AutomaticSpeechRecognitionPipeline`. (#11337)
* Adding `AutomaticSpeechRecognitionPipeline`.
- Because we added everything to enable this pipeline, we probably
should add it to `transformers`.
- This PR tries to limit the scope and focuses only on the pipeline part
(what should go in, and out).
- The tests are very specific for S2T and Wav2vec2 to make sure both
architectures are supported by the pipeline. We don't use the mixin for
tests right now, because that requires more work in the `pipeline`
function (will be done in a follow up PR).
- Unsure about the "helper" function `ffmpeg_read`. It makes a lot of
sense from a user perspective, it does not add any additional
dependencies (as in hard dependency, because users can always use their
own load mechanism). Meanwhile, it feels slightly clunky to have so much
optional preprocessing.
- The pipeline is not done to support streaming audio right now.
Future work:
- Add `automatic-speech-recognition` as a `task`. And add the
FeatureExtractor.from_pretrained within `pipeline` function.
- Add small models within tests
- Add the Mixin to tests.
- Make the logic between ForCTC vs ForConditionalGeneration better.
* Update tests/test_pipelines_automatic_speech_recognition.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding docs + main import + type checking + LICENSE.
* Doc style !.
* Fixing TYPE_HINT.
* Specifying waveform shape in the docs.
* Adding asserts + specify in the documentation the shape of the input
np.ndarray.
* Update src/transformers/pipelines/automatic_speech_recognition.py
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Adding require to tests + move the `feature_extractor` doc.
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Implement Fast Tokenization for Deberta (#11387)
* Accepts BatchEncoding in LengthSampler (#11431)
* Fix do_eval default value in training_args.py (#11511)
* Fix do_eval default value in training_args.py
* Update PULL_REQUEST_TEMPLATE.md
* Update TF text classification example (#11496)
Big refactor, fixes and multi-GPU/TPU support
* reszie token embeds (#11524)
* Run model templates on master (#11527)
* [Examples] Added support for test-file in QA examples with no trainer (#11510)
* added support for test-file
* fixed typo
* added suggested changes
* reformatted code
* modifed files
* fix post processing error
* Trigger CI
* removed extra lines
* Add Stas and Suraj as authors (#11526)
* Improve task summary docs (#11513)
* fix task summary docs
* refactor to use model.config.id2label instead of list
* fix nit
* Update docs/source/task_summary.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [debug utils] activation/weights underflow/overflow detector (#11274)
* sync
* add activation overflow debug utility
* cleanup
* document detect_overflow
* import torch
* add deprecation warning
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* convert to rst, add note
* add class
* fix docs
* improve the doc
* rework to dump a lot more info about each frame
* complete expansion
* cleanup
* format
* cleanup
* doesn't have to be transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wrap long line
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] fp32 support (#11499)
* prep for deepspeed==0.3.16
* new version
* too soon
* support and test fp32 mode
* troubleshooting doc start
* workaround no longer needed
* add fp32 doc
* style
* cleanup, add tf32 note
* clarify
* release was made
* Fixed docs for the shape of `scores` in `generate()` (#10057)
* Fixed the doc for the shape of return scores tuples in generation_utils.py.
* Fix the output shape of `scores` for `DecoderOnlyOutput`.
* style fix
* Fix examples in M2M100 docstrings (#11540)
Replaces `tok` with `tokenizer` so examples can run with copy-paste
* [Flax BERT/Roberta] few small fixes (#11558)
* small fixes
* style
* [Wav2Vec2] Fix convert (#11562)
* push
* small change
* correct other typo
* Remove `datasets` submodule. (#11563)
* fix the mlm longformer example by changing [MASK] to <mask> (#11559)
* Add LUKE (#11223)
* Rebase with master
* Minor bug fix in docs
* Copy files from adding_luke_v2 and improve docs
* change the default value of use_entity_aware_attention to True
* remove word_hidden_states
* fix head models
* fix tests
* fix the conversion script
* add integration tests for the pretrained large model
* improve docstring
* Improve docs, make style
* fix _init_weights for pytorch 1.8
* improve docs
* fix tokenizer to construct entity sequence with [MASK] entity when entities=None
* Make fix-copies
* Make style & quality
* Bug fixes
* Add LukeTokenizer to init
* Address most comments by @patil-suraj and @LysandreJik
* rename _compute_extended_attention_mask to get_extended_attention_mask
* add comments to LukeSelfAttention
* fix the documentation of the tokenizer
* address comments by @patil-suraj, @LysandreJik, and @sgugger
* improve docs
* Make style, quality and fix-copies
* Improve docs
* fix docs
* add "entity_span_classification" task
* update example code for LukeForEntitySpanClassification
* improve docs
* improve docs
* improve the code example in luke.rst
* rename the classification layer in LukeForEntityClassification from typing to classifier
* add bias to the classifier in LukeForEntitySpanClassification
* update docs to use fine-tuned hub models in code examples of the head models
* update the example sentences
* Make style & quality
* Add require_torch to tokenizer tests
* Add require_torch to tokenizer tests
* Address comments by @sgugger and add community notebooks
* Make fix-copies
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
* [Wav2vec2] Fixed tokenization mistakes while adding single-char tokens to tokenizer (#11538)
* Fixed tokenization mistakes while adding single-char tokens to tokenizer
* Added tests and Removed unnecessary comments.
* finalize wav2vec2 tok
* add more aggressive tests
* Apply suggestions from code review
* fix useless import
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Fix metric computation in `run_glue_no_trainer` (#11569)
* Fixes a useless warning. (#11566)
Fixes #11525
* Accumulate opt state dict on do_rank 0 (#11481)
* Update training tutorial (#11533)
* Update training tutorial
* Apply suggestions from code review
Co-authored-by: Hamel Husain <hamelsmu@github.com>
* Address review comments
* Update docs/source/training.rst
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* More review comments
* Last review comments
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fix resize_token_embeddings (#11572)
* Add multi-class, multi-label and regression to transformers (#11012)
* add to bert
* review comments
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* self.config.problem_type
* fix style
* fix
* fin
* fix
* update doc
* fix
* test
* Test more problem types
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix
* remove
* fix
* quality
* make fix-copies
* remove test
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* Enable added tokens (#11325)
* Fix tests
* Reorganize
* Update tests/test_modeling_mobilebert.py
* Remove unnecessary addition
* Make quality scripts work when one backend is missing. (#11573)
* Make quality scripts work when one backend is missing.
* Check env variable is properly set
* Add default
* With print statements
* Fix typo
* Set env variable
* Remove debug code
* [FlaxRoberta] Add FlaxRobertaModels & adapt run_mlm_flax.py (#11470)
* add flax roberta
* make style
* correct initialiazation
* modify model to save weights
* fix copied from
* fix copied from
* correct some more code
* add more roberta models
* Apply suggestions from code review
* merge from master
* finish
* finish docs
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
* Removes SageMakerTrainer code but keeps class as wrapper (#11587)
* removed all old code
* make quality
* [Flax] Add Electra models (#11426)
* add electra model to flax
* Remove Electra Next Sentence Prediction model added by mistake
* fix parameter sharing and loosen equality threshold
* fix styling issues
* add mistaken removen imports
* fix electra table
* Add FlaxElectra to automodels and fixe docs
* fix issues pointed out the PR
* fix flax electra to comply with latest changes
* remove stale class
* add copied from
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Reproducible checkpoint (#11582)
* Set generator in dataloader
* Use generator in all random samplers
* Checkpoint all RNG states
* Final version
* Quality
* Test
* Address review comments
* Quality
* Remove debug util
* Add python and numpy RNGs
* Split states in different files in distributed
* Quality
* local_rank for TPUs
* Only use generator when accepted
* Add test
* Set seed to avoid flakiness
* Make test less flaky
* Quality
* [trainer] document resume randomness (#11588)
* document resume randomness
* fix link
* reword
* fix
* reword
* style
* copies need to be fixed too (#11585)
* add importlib_metadata and huggingface_hub as dependency in the conda recipe (#11591)
* add importlib_metadata as dependency (#11490)
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* add huggingface_hub dependency
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* Skip Funnel test
* Pytorch - Lazy initialization of models (#11471)
* lazy_init_weights
* remove ipdb
* save int
* add necessary code
* remove unnecessary utils
* Update src/transformers/models/t5/modeling_t5.py
* clean
* add tests
* correct
* finish tests
* finish tests
* fix some more tests
* fix xlnet & transfo-xl
* fix more tests
* make sure tests are independent
* fix tests more
* finist tests
* final touches
* Update src/transformers/modeling_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* clean tests
* give arg positive name
* add more mock weights to xlnet
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Accept tensorflow-rocm package when checking TF availability (#11595)
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: JohnnyC08 <jcastaldo08@gmail.com>
Co-authored-by: Hemil Desai <hemil.desai10@gmail.com>
Co-authored-by: Josh <1113285+jsrozner@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: cchen-dialpad <47165889+cchen-dialpad@users.noreply.github.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: cronoik <johannes.schaffrath@mail.de>
Co-authored-by: Joe Davison <josephddavison@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: versis <versis791@gmail.com>
Co-authored-by: Eren Şahin <sahineren.09@gmail.com>
Co-authored-by: Amala Deshmukh <amala.d166@gmail.com>
Co-authored-by: konstin <konstin@mailbox.org>
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: SHYAM SUNDER KUMAR <beingprofess@gmail.com>
Co-authored-by: Leo Gao <54557097+leogao2@users.noreply.github.com>
Co-authored-by: Vasudev Gupta <7vasudevgupta@gmail.com>
Co-authored-by: Jannis Born <jannis.born@gmx.de>
Co-authored-by: Yusuke Mori <mori@mi.t.u-tokyo.ac.jp>
Co-authored-by: Julien Demouth <julien.demouth@gmail.com>
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Andrea Cappelli <ak314@users.noreply.github.com>
Co-authored-by: Niklas Muennighoff <62820084+Muennighoff@users.noreply.github.com>
Co-authored-by: Keisuke Hirota <tahiro.k.ad@gmail.com>
Co-authored-by: Saviour Owolabi <42647840+Seyviour@users.noreply.github.com>
Co-authored-by: Kevin Canwen Xu <canwenxu@126.com>
Co-authored-by: Masatoshi TSUCHIYA <tsuchm@users.noreply.github.com>
Co-authored-by: fghuman <f.z.ghuman@student.tudelft.nl>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
Co-authored-by: Takuya Makino <takuyamakino15@gmail.com>
Co-authored-by: calpt <calpt@mail.de>
Co-authored-by: Ceyda Cinarel <15624271+cceyda@users.noreply.github.com>
Co-authored-by: Nithin Holla <nithin.holla7@gmail.com>
Co-authored-by: nithin19 <nithin@amberscript.com>
Co-authored-by: Joel Stremmel <joelstremmel22@gmail.com>
Co-authored-by: Sudharsan S T <stsudharshan@gmail.com>
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
Co-authored-by: Thomas Wood <odell.wood@gmail.com>
Co-authored-by: Nicolas Patry <patry.nicolas@protonmail.com>
Co-authored-by: e <e_yi@foxmail.com>
Co-authored-by: TAE YOUNGDON <49802647+taepd@users.noreply.github.com>
Co-authored-by: rajvi-k <rajvi.kapadia01@gmail.com>
Co-authored-by: lewtun <lewis.c.tunstall@gmail.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: wlhgtc <hgtcwl@foxmail.com>
Co-authored-by: johnson7788 <linghuchongxajh@gmail.com>
Co-authored-by: johnson <johnson@github.com>
Co-authored-by: PenutChen <penut85420@gmail.com>
Co-authored-by: Max Del <max.del.edu@gmail.com>
Co-authored-by: Yoshitomo Matsubara <yoshitomo-matsubara@users.noreply.github.com>
Co-authored-by: Teven <teven.lescao@gmail.com>
Co-authored-by: Kiran R <kiranr8k@gmail.com>
Co-authored-by: Nicola De Cao <nicola.decao@gmail.com>
Co-authored-by: Daniel Stancl <46073029+stancld@users.noreply.github.com>
Co-authored-by: Philip May <philip@may.la>
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: abiolaTresor <48957493+abiolaTresor@users.noreply.github.com>
Co-authored-by: Amine Abdaoui <abdaoui@lirmm.fr>
Co-authored-by: LSinev <LSinev@users.noreply.github.com>
Co-authored-by: Kostas Stathoulopoulos <k.stathoylopoylos@gmail.com>
Co-authored-by: Bhadresh Savani <bhadreshpsavani@gmail.com>
Co-authored-by: Jaimeen Ahn <32367255+jaimeenahn@users.noreply.github.com>
Co-authored-by: Ashwin Geet D'Sa <win.12894@gmail.com>
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Hamel Husain <hamel.husain@gmail.com>
Co-authored-by: Michael Benayoun <mickbenayoun@gmail.com>
Co-authored-by: Michael Benayoun <michael@huggingface.co>
Co-authored-by: Frederik Bode <fredo.bode@gmail.com>
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
Co-authored-by: Manuel Romero <mrm8488@gmail.com>
Co-authored-by: CeShine Lee <ceshine@users.noreply.github.com>
Co-authored-by: Shubham Sanghavi <shubham.sanghavi@outlook.com>
Co-authored-by: bonniehyeon <50580028+bonniehyeon@users.noreply.github.com>
Co-authored-by: jingyihe <29100716+kylie-box@users.noreply.github.com>
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
Co-authored-by: Muktan <muktan123@gmail.com>
Co-authored-by: abhishek thakur <1183441+abhi1thakur@users.noreply.github.com>
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
Co-authored-by: Patrick Fernandes <pattuga@gmail.com>
Co-authored-by: Deepali <70963368+cdeepali@users.noreply.github.com>
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
Co-authored-by: Mats Sjöberg <mats.sjoberg@csc.fi>
* Add more metadata to the user agent (#10972)
* Add more metadata to the user agent
* Fix typo
* Use DISABLE_TELEMETRY
* Address review comments
* Use global env
* Add clean envs on circle CI
* Enforce string-formatting with f-strings (#10980)
* First third
* Styling and fix mistake
* Quality
* All the rest
* Treat %s and %d
* typo
* Missing )
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* add notebook (#10995)
* Merge trainers (#10975)
* Replace is_sagemaker_distributed_available
* Merge SageMakerTrainer into Trainer
* Test with shorter condition
* Put back deleted line
* Deprecate SageMakerTrainer and SageMakerTrainingArguments
* Apply suggestions from code review
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
* add blog to docs (#10997)
* Update training_args.py (#11000)
In the group by length documentation length is misspelled as legnth
* Add `examples/language_modeling/run_mlm_no_trainer.py` (#11001)
* Add initial script for finetuning MLM models with accelerate
* Add evaluation metric calculation
* Fix bugs
* Use no_grad on evaluation
* update script docstring
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* PR feedback
* Fix CI failure
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix Adafactor documentation (recommend correct settings) (#10526)
* Update optimization.py
Fix documentation to reflect optimal settings for Adafactor
* update and expand on the recommendations
* style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* flip scale_parameter to True for the 2nd recommendatoin
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Improve the speed of adding tokens from added_tokens.json (#10780)
* use bisect to add one token to unique_no_split_tokens
* fix style
* Add Vision Transformer and ViTFeatureExtractor (#10950)
* Squash all commits into one
* Update ViTFeatureExtractor to use image_utils instead of torchvision
* Remove torchvision and add Pillow
* Small docs improvement
* Address most comments by @sgugger
* Fix tests
* Clean up conversion script
* Pooler first draft
* Fix quality
* Improve conversion script
* Make style and quality
* Make fix-copies
* Minor docs improvements
* Should use fix-copies instead of manual handling
* Revert "Should use fix-copies instead of manual handling"
This reverts commit fd4e591bce4496d41406425c82606a8fdaf8a50b.
* Place ViT in alphabetical order
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* DebertaTokenizer Rework closes #10258 (#10703)
* closes #10258
* typo
* reworked deberta test
* implemented the comments from BigBird01 regarding sequence pair encoding of deberta
* Update style
* VOCAB_FILES_NAMES is now a oneliner as suggested by @sgugger
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* added #fmt: on as requested by @sgugger
* Style
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* minor typo fix
*negative* log-likelihood
* [doc] no more bucket
* added new notebook and merge of trainer (#11015)
* added new notebook and merge of trainer
* Update docs/source/sagemaker.md
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fixed typo: logging instead of logger (#11025)
* Add a script to check inits are consistent (#11024)
* s|Pretrained|PreTrained| (#11048)
* [doc] update code-block rendering (#11053)
double : prevents code-block section to be rendered, so made it single :
* Pin docutils (#11062)
* Pin docutils
* Versions table
* Remove unnecessary space (#11060)
* Some models have no tokenizers (#11064)
* Refactor AutoModel classes and add Flax Auto classes (#11027)
* Refactor AutoModel classes and add Flax Auto classes
* Add new objects to the init
* Fix hubconf and sort models
* Fix TF tests
* Missing coma
* Update src/transformers/models/auto/auto_factory.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Fix init
* Fix dummies
* Other init to fix
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Documentation about loading a fast tokenizer within Transformers (#11029)
* Documentation about loading a fast tokenizer within Transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add example for registering callbacks with trainers (#10928)
* Add example for callback registry
Resolves: #9036
* Update callback registry documentation
* Added comments for other ways to register callback
* Add `examples/language_modeling/run_clm_no_trainer.py` (#11026)
* Initial draft for clm no trainer
* Remove unwanted args
* Fix bug
* Update examples/language-modeling/run_clm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace pkg_resources with importlib_metadata (#11061)
* Replace pkg_resources with importlib_metadata
Fixes #10964. The other reason for this change is that pkg_resources has been [deprecated](https://github.com/pypa/setuptools/commit/8fe85c22cee7fde5e6af571b30f864bad156a010) in favor of importlib_metadata.
* Reduce to a single importlib_metadata import switch
* Trigger CI
Co-authored-by: Stas Bekman <stas@stason.org>
* Add center_crop to ImageFeatureExtractoMixin (#11066)
* Document common config attributes (#11070)
* Fix distributed gather for tuples of tensors of varying sizes (#11071)
* Make a base init in FeatureExtractionMixin (#11074)
* Add Readme for language modeling scripts with accelerate (#11073)
* HF emoji unicode doesn't work in console (#11081)
It doesn't look like using 🤗 is a great idea for printing to console. See attachment.
This PR proposes to replace 🤗 with "HuggingFace" for an exception message.
@LysandreJik
* Link to new blog
* added social thumbnail for docs (#11083)
* added new merged Trainer test (#11090)
* [WIP] GPT Neo cleanup (#10985)
* better names
* add attention mixin
* all slow tests in one class
* make helper methods static so we can test
* add local attention tests
* better names
* doc
* apply review suggestions
* Release v4.5.0
* Development on v4.6.0dev0
* [doc] gpt-neo (#11098)
make the example work
* Auto feature extractor (#11097)
* AutoFeatureExtractor
* Init and first tests
* Tests
* Damn you gitignore
* Quality
* Defensive test for when not all backends are here
* Use pattern for Speech2Text models
* accelerate question answering examples with no trainer (#11091)
* accelerate question answering examples with no trainer
* removed train and eval flags also fixed fill np array function
* Update examples/question-answering/run_qa_beam_search_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update examples/question-answering/run_qa_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Style
* dead link fixed (#11103)
* GPTNeo: handle padded wte (#11079)
* GPTNeo: handle padded wte
* Switch to config.vocab_size
* apply review suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* fix: The 'warn' method is deprecated (#11105)
* The 'warn' method is deprecated
* fix test
* [examples] fix white space (#11099)
these get concatenated without whitespace, so fix it
* Dummies multi backend (#11100)
* Replaces requires_xxx by one generic method
* Quality and update check_dummies
* Fix inits check
* Post-merge cleanup
* Some styling of the training table in Notebooks (#11118)
* Adds a note to resize the token embedding matrix when adding special … (#11120)
* Adds a note to resize the token embedding matrix when adding special tokens
* Remove superfluous space
* fix tests (#11109)
* [versions] handle version requirement ranges (#11110)
* handle version requirement ranges
* add mixed requirement test
* cleanup
* Adds use_auth_token with pipelines (#11123)
* added model_kwargs to infer_framework_from_model
* added model_kwargs to tokenizer
* added use_auth_token as named parameter
* added dynamic get for use_auth_token
* Fix and refactor check_repo (#11127)
* Fix typing error in Trainer class (prediction_step) (#11138)
* fix: docstrings in prediction_step
* ci: Satisfy line length requirements
* ci: character length requirements
* Typo fix of the name of BertLMHeadModel in BERT doc (#11133)
* [run_clm] clarify why we get the tokenizer warning on long input (#11145)
* clarify why we get the warning here
* Update examples/language-modeling/run_clm.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wording
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] ZeRO Stage 3 (#10753)
* synced gpus
* fix
* fix
* need to use t5-small for quality tests
* notes
* complete merge
* fix a disappearing std stream problem
* start zero3 tests
* wip
* tune params
* sorting out the pre-trained model loading
* reworking generate loop wip
* wip
* style
* fix tests
* split the tests
* refactor tests
* wip
* parameterized
* fix
* workout the resume from non-ds checkpoint pass + test
* cleanup
* remove no longer needed code
* split getter/setter functions
* complete the docs
* suggestions
* gpus and their compute capabilities link
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* style
* remove invalid paramgd
* automatically configure zero3 params that rely on hidden size
* make _get_resized_embeddings zero3-aware
* add test exercising resize_token_embeddings()
* add docstring
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Add nvidia megatron models (#10911)
* Add support for NVIDIA Megatron models
* Add support for NVIDIA Megatron GPT2 and BERT
Add the megatron_gpt2 model. That model reuses the existing GPT2 model. This
commit includes a script to convert a Megatron-GPT2 checkpoint downloaded
from NVIDIA GPU Cloud. See examples/megatron-models/README.md for details.
Add the megatron_bert model. That model is implemented as a modification of
the existing BERT model in Transformers. This commit includes a script to
convert a Megatron-BERT checkpoint downloaded from NVIDIA GPU Cloud. See
examples/megatron-models/README.md for details.
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Remove model.half in tests + add "# Copied ..."
Remove the model.half() instruction which makes tests fail on the CPU.
Add a comment "# Copied ..." before many classes in the model to enable automatic
tracking in CI between the new Megatron classes and the original Bert ones.
* Fix issues
* Fix Flax/TF tests
* Fix copyright
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update docs/source/model_doc/megatron_bert.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update docs/source/model_doc/megatron_gpt2.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/__init__.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Resolve most of 'sgugger' comments
* Fix conversion issue + Run make fix-copies/quality/docs
* Apply suggestions from code review
* Causal LM & merge
* Fix init
* Add CausalLM to last auto class
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [trainer] solve "scheduler before optimizer step" warning (#11144)
* solve "scheduler before optimizer step" warning
* style
* correct the state evaluation test
* Add fairscale and deepspeed back to the CI (#11147)
* Add fairscale and deepspeed back to the CI
* Add deepspeed to single GPU tests
* Updates SageMaker docs for updating DLCs (#11140)
* Don't duplicate logs in TensorBoard and handle --use_env (#11141)
* Run mlm pad to multiple for fp16 (#11128)
* Add mlm collator pad to multiple option (#10627)
* Use padding to 8x in run mlm (#10627)
* [tests] relocate core integration tests (#11146)
* relocate core integration tests
* add sys.path context manager
* cleanup
* try
* try2
* fix path
* doc
* style
* add dep
* add 2 more deps
* [setup] extras[docs] must include 'all' (#11148)
* extras[doc] must include 'all'
* fix
* better
* regroup
* Add support for multiple models for one config in auto classes (#11150)
* Add support for multiple models for one config in auto classes
* Use get_values everywhere
* Prettier doc
* [setup] make fairscale and deepspeed setup extras (#11151)
* make fairscale and deepspeed setup extras
* fix default
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* no reason not to ask for the good version
* update the CIs
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Skip Megatron tests for now
* typo (#11152)
* typo
* style
* [Community notebooks] Add Wav2Vec notebook for creating captions for YT Clips (#11142)
* Add Wav2Vec Inference notebook
* Update docs/source/community.md
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Fix LogitsProcessor documentation (#11130)
* Change duplicated LogitsProcessor to LogitsWarper in LogitsProcessorList document
* Write more detailed information about LogitsProcessor's scores argument
* apply suggestion from review
* style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Update README.md (#11161)
Corrected a typo ('Downlowd' to 'Download')
* Make `get_special_tokens_mask` consider all tokens (#11163)
* Add a special tokenizer for CPM model (#11068)
* Add a special tokenizer for CPM model
* make style
* fix
* Add docs
* styles
* cpm doc
* fix ci
* fix the overview
* add test
* make style
* typo
* Custom tokenizer flag
* Add REAMDE.md
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [examples/translation] support mBART-50 and M2M100 fine-tuning (#11170)
* keep a list of multilingual tokenizers
* add forced_bos_token argument
* [examples run_clm] fix _LazyModule hasher error (#11168)
* fix _LazyModule hasher error
* reword
* added json dump and extraction of train run time (#11167)
* added json dump and extraction of train run time
* make style happy
* Fix Typo
* Reactivate Megatron tests an use less workers
* Minor typos fixed (#11182)
* Fix style
* model_path should be ignored as the checkpoint path (#11157)
* model_path is refered as the path of the trainer, and should be ignored as the checkpoint path.
* Improved according to Sgugger's comment.
* Added documentation for data collator. (#10941)
* Added documentation for data collator.
* Update docs/source/data_collator.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Added documentation for data collator.
* Added documentation for the data collator.
* Merge branch 'doc_DataCollator' of C:\Users\mahii\PycharmProjects\transformers with conflicts.
* Update documentation for the data collator.
* Update documentation for the data collator.
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
* Fix typo (#11188)
* Add DeiT (PyTorch) (#11056)
* First draft of deit
* More improvements
* Remove DeiTTokenizerFast from init
* Conversion script works
* Add DeiT to ViT conversion script
* Add tests, add head model, add support for deit in vit conversion script
* Update model checkpoint names
* Update image_mean and image_std, set resample to bicubic
* Improve docs
* Docs improvements
* Add DeiTForImageClassificationWithTeacher to init
* Address comments by @sgugger
* Improve feature extractors
* Make fix-copies
* Minor fixes
* Address comments by @patil-suraj
* All models uploaded
* Fix tests
* Remove labels argument from DeiTForImageClassificationWithTeacher
* Fix-copies, style and quality
* Fix tests
* Fix typo
* Multiple docs improvements
* More docs fixes
* Replaced `which` with `who` (#11183)
* Import torch.utils.checkpoint in ProphetNet (#11214)
* Sagemaker test docs update for framework upgrade (#11206)
* increased train_runtime for model parallelism
* added documentation for framework upgrade
* Use MSELoss in (M)BartForSequenceClassification (#11178)
* wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model (#11041)
* add vocab while converting wav2vec2 original finetuned model
* check save directory exists
* return_attention_mask fix
* quality
* Add Matt as the TensorFlow reference (#11212)
* Fix GPT-2 warnings (#11213)
* Fix GPT-2 warnings
* Update src/transformers/models/gpt2/modeling_gpt2.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* fix docstrings (#11221)
* Add documentation for BertJapanese (#11219)
* Start writing BERT-Japanese doc
* Fix typo, Update toctree
* Modify model file to use comment for document, Add examples
* Clean bert_japanese by make style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Split a big code block into two
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add prefix >>> to all lines in code blocks
* Clean bert_japanese by make fixup
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace error by warning when loading an architecture in another (#11207)
* Replace error by warning when loading an architecture in another
* Style
* Style again
* Add a test
* Adapt old test
* Document v4.5.1
* Refactor GPT2 (#11225)
* refactor GPT2
* fix mlp and head pruning
* address Sylvains comments
* apply suggestion from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Doc check: a bit of clean up (#11224)
* added cache_dir=model_args.cache_dir to all example with cache_dir arg (#11220)
* Avoid using no_sync on SageMaker DP (#11229)
* Indent code block in the documentation (#11233)
* Indent code block
* Indent code blocks version 2
* Quality
* Run CI on deepspeed and fairscale (#11172)
* Run CI on deepspeed and fairscale
* Test it on this branch :)
* Rename
* Update the CI image
* [Deepspeed] zero3 tests band aid (#11235)
* temp band-aid
* style
* Save the Wav2Vec2 processor before training starts (#10910)
Co-authored-by: nithin19 <nithin@amberscript.com>
* make embeddings plural in warning message (#11228)
* Stale bot updated (#10562)
* Updated stale bot
* Specify issue number
* Remove particular handling of assignees
* Unleash the stalebot
* Remove debug branch
* Close open files to suppress ResourceWarning (#11240)
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
* Fix dimention misspellings. (#11238)
* Update modeling_gpt_neo.py
dimention -> dimension
* Update configuration_speech_to_text.py
dimention -> dimension
* Add prefix to examples in model_doc rst (#11226)
* Add prefix to examples in model_doc rst
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [troubleshooting] add 2 points of reference to the offline mode (#11236)
* add 2 points of reference to the offline mode
* link the new doc
* add error message
* Update src/transformers/modeling_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
* rename
* Trigger CI
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix #10128 (#11248)
* [deepspeed] test on one node 2 gpus max (#11237)
* test on one node 2 gpus max
* fix the other place
* refactor
* fix
* cleanup
* more exact version
* Trainer iterable dataset (#11254)
* IterableDatasetShard
* Test and integration in Trainer
* Update src/transformers/trainer_pt_utils.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Style
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding pipeline task aliases. (#11247)
* Adding task aliases and adding `token-classification` and
`text-classification` tasks.
* Cleaning docstring.
* Support for set_epoch (#11258)
* Tokenizer fast save (#11234)
* Save fast tokenizers in both formats
* Fix for HerBERT
* Proper fix
* Properly test new behavior
* update dependency_versions_table (#11273)
missed this updating when bumped the version.
* Workflow fixes (#11270)
* Enabling multilingual models for translation pipelines. (#10536)
* [WIP] Enabling multilingual models for translation pipelines.
* decoder_input_ids -> forced_bos_token_id
* Improve docstring.
* Rebase
* Fixing 2 bugs
- Type token_ids coming from `_parse_and_tokenize`
- Wrong index from tgt_lang.
* Fixing black version.
* Adding tests for _build_translation_inputs and add them for all
tokenizers.
* Mbart actually puts the lang code at the end.
* Fixing m2m100.
* Adding TF support to `deep_round`.
* Update src/transformers/pipelines/text2text_generation.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Adding one line comment.
* Fixing M2M100 `_build_translation_input_ids`, and fix the call site.
* Fixing tests + deep_round -> nested_simplify
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix failing workflows
* Trainer support for IterableDataset for evaluation and predict (#11286)
* Bulk of the work
* Polish and tests
* Update QA Trainer
* Avoid breaking the predict method
* Deprecation warnings
* Store real eval dataloder
* Get eval dataset reference before wrap
* move device statements outside if statements (#11292)
* modify double considering special tokens in `language_modeling.py` (#11275)
* Update language_modeling.py
in "class TextDatasetForNextSentencePrediction(Dataset)", double considering "self.tokenizer.num_special_tokens_to_add(pair=True)"
so, i remove self.block_size, and add parameter for "def create_examples_from_document". like "class LineByLineWithSOPTextDataset" do
* Update language_modeling.py
* [Trainer] fix the placement on device with fp16_full_eval (#11322)
* fix the placement on device with fp16_full_eval
* deepspeed never goes on device
* [Trainer] Add a progress bar for batches skipped (#11324)
* Load checkpoint without re-creating the model (#11318)
* Added translation example script (#11196)
* initial changes
* modified evaluation
* updated evaluation
* updated evaluation on text translation example script
* added translation example script
* Formatted translation example script
* Reformatted translation example
* Fixed evaluation bug and added support for other tokenisers
* Fixed evaluation bug and added support for other tokenisers
* Added translation example script
* Formatted summarization example script
* Removed typos from summarization example script
* [Generate] Remove outdated code (#11331)
* remove update function
* update
* refactor more
* refactor
* [GPTNeo] create local attention mask ones (#11335)
* create local attention mask ones
* remove old method, address patricks comment
* Update to use datasets remove_cloumns method (#11343)
* Update to use datasets remove_cloumns method
* Quality
* Add an error message that fires when Reformer is not in training mode, but one runs .backward() (#11117)
* Removed `max_length` from being mandatory within `generate`. (#11314)
* Removed `max_length` from being mandatory within `generate`.
- Moving on to fully using `StoppingCriteria` for `greedy` and `sample`
modes.
- `max_length` still used for `beam_search` and `group_beam_search`
(Follow up PR)
- Fixes a bug with MaxLengthStoppingCriteria (we should stop as soon a
we hit the max_length, the comparison needs to be or equal, that affects
the tests).
- Added options to use `logits_processor` and `stopping_criteria`
directly within `generate` function (so some users can define their own
`logits_processor` and `stopping_criteria`).
- Modified the backward compat tests to make sure we issue a warning.
* Fix `max_length` argument in `generate`.
* Moving validate to being functional.
- Renamed `smax_length` to `stoppping_max_length`.
* Removing `logits_processor` and `stopping_criteria` from `generate`
arguments.
* Deepcopy.
* Fix global variable name.
* Honor contributors to models (#11329)
* Honor contributors to models
* Fix typo
* Address review comments
* Add more authors
* [deepspeed] fix resume from checkpoint (#11352)
This PR fixes a bug that most likely somehow got exposed (not caused) by https://github.com/huggingface/transformers/pull/11318 - surprisingly the same test worked just fine before that other PR.
* Examples reorg (#11350)
* Base move
* Examples reorganization
* Update references
* Put back test data
* Move conftest
* More fixes
* Move test data to test fixtures
* Update path
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Address review comments and clean
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Extract metric_key_prefix during NotebookProgressCallback.on_evaluate (#11347)
* Pass metric_key_prefix as kwarg to on_evaluate
* Replace eval_loss with metric_key_prefix_loss
* Default to "eval" if metric_key_prefix not in kwargs
* Add kwargs to CallbackHandler.on_evaluate signature
* Revert "Add kwargs to CallbackHandler.on_evaluate signature"
This reverts commit 8d4c85ed512f558f7579d36771e907b3379947b7.
* Revert "Pass metric_key_prefix as kwarg to on_evaluate"
This reverts commit 7766bfe2718601230ae593d37b1317bd53cfc075.
* Extract metric_key_prefix from metrics
* [testing doc] bring doc up to date (#11359)
* bring doc up to date
* fix
* Merge new TF example script (#11360)
First of the new and more idiomatic TF examples!
* Remove boiler plate code (#11340)
* remove boiler plate code
* adapt roberta
* correct docs
* finish refactor
* Move old TF text classification script to legacy (#11361)
And update README to explain the work-in-progress!
* [contributing doc] explain/link to good first issue (#11346)
* explain/link to good first issue
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix token_type_ids error for big_bird model. (#11355)
* MOD: fit chinese wwm to new datasets
* MOD: move wwm to new folder
* MOD: formate code
* Styling
* MOD add param and recover trainer
* MOD: add token_type_ids method for big bird
* MOD: format code
* MOD: format code
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
* Add huggingface_hub dep for #11328
* Add in torchhub
* [Wav2Vec2] Fix special tokens for Wav2Vec2 tokenizer (#11349)
* fix wav2vec2 tok
* up
* [Flax] Correct typo (#11374)
* finish
* fix copy
* [run_translation.py] fix typo (#11372)
fix typo
Co-authored-by: johnson <johnson@github.com>
* Add space (#11373)
* Correctly cast num_train_epochs to int (#11379)
* Fix typo (#11369)
* Fix Trainer with remove_unused_columns=False (#11382)
* Fix Trainer with remove_unused_columns=False
* Typo
* [Flax] Big FlaxBert Refactor (#11364)
* improve flax
* refactor
* typos
* Update src/transformers/modeling_flax_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_flax_utils.py
* fix typo
* improve error tolerance
* typo
* correct nasty saving bug
* fix from pretrained
* correct tree map
* add note
* correct weight tying
* correct typo (#11393)
* correct conversion (#11394)
* Fix typo in text (#11396)
* fixed typos (#11391)
* make blenderbot test slow (#11395)
* Fixed trainer total_flos relaoding in distributed mode (#11383)
* Fixed trainer total_flos relaoding in distributed mode
* logging flos at the end of training
* Trainer push to hub (#11328)
* Initial support for upload to hub
* push -> upload
* Fixes + examples
* Fix torchhub test
* Torchhub test I hate you
* push_model_to_hub -> push_to_hub
* Apply mixin to other pretrained models
* Remove ABC inheritance
* Add tests
* Typo
* Run tests
* Install git-lfs
* Change approach
* Add push_to_hub to all
* Staging test suite
* Typo
* Maybe like this?
* More deps
* Cache
* Adapt name
* Quality
* MOAR tests
* Put it in testing_utils
* Docs + torchhub last hope
* Styling
* Wrong method
* Typos
* Update src/transformers/file_utils.py
Co-authored-by: Julien Chaumond <julien@huggingface.co>
* Address review comments
* Apply suggestions from code review
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* push (#11400)
* added support for exporting of t5 to onnx with past_key_values (#10651)
* Fixing bug in generation (#11297)
When passing `inputs_embeds` and not `input_ids=None` the generation function fails because `input_ids` is created but the function but it should not.
* Style
* Try to trigger failure more
* Wrong branch Sylvain...
* Fix cross-attention head mask for Torch encoder-decoder models (#10605)
* Fix cross-attention head mask for Torch BART models
* Fix head masking for cross-attention module for the following
models: BART, Blenderbot, Blenderbot_small, M2M_100, Marian, MBart,
Pegasus
* Enable test_headmasking for M2M_100 model
* Fix cross_head_mask for FSMT, LED and T5
* This commit fixes `head_mask` for cross-attention modules
in the following models: FSMT, LED, T5
* It also contains some smaller changes in doc so that
it is be perfectly clear the shape of `cross_head_mask`
is the same as of `decoder_head_mask`
* Update template
* Fix template for BartForCausalLM
* Fix cross_head_mask for Speech2Text models
* Fix cross_head_mask in templates
* Fix args order in BartForCausalLM template
* Fix doc in BART templates
* Make more explicit naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Fix doc
* make style quality
* Fix speech2text docstring
* Default to accuracy metric (#11405)
* Enable option for subword regularization in `XLMRobertaTokenizer` (#11149)
* enable subword regularization.
* fix tokenizer storage
* fix docstring formatting
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Stefan Schweter <stefan@schweter.it>
* fix docstring formatting
* add test for subword regularization tokenizer
* improve comments of test
* add sp_model_kwargs
* reformat docstring to match the style
* add some more documentation
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* improve docstring
* empty commit to trigger CI
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docstring formatting for sphinx
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Use 3 workers for torch tests
* documentation linked to the parent class PreTrainedTokenizerFast but it should be the slow tokenizer (#11410)
* Style
* Add head_mask, decoder_head_mask, cross_head_mask to ProphetNet (#9964)
* Add head_mask & decoder_head_mask + some corrections
* Fix head masking for N-grams
* Enable test_headmasking for encoder and decod
* Fix one typo regarding in modeling_propgetnet.py
* Enable test_headmasking for ProphetNetStandaloneDecoderModelTest
and ProphetNetStandaloneEncoderModelTest in test_modeling_prophetnet.py
* make style
* Fix cross_head_mask
* Fix attention head mask naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Still need to merge #10605 to master to pass the tests
* EncoderDecoderConfigs should not create new objects (#11300)
* removes the creation of separate config objects and uses the existing ones instead+overwrite resize_token_embeddings from parent class because it is not working for the EncoderDecoderModel
* rollback to current version of the huggingface master branch
* reworked version that ties the encoder and decoder config of the parent encoderdecoder instance
* overwrite of resize_token_embeddings throws an error now
* review comment suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* implemented warning in case encoderdecoder is created with differing configs of encoderdecoderconfig and decoderconfig or encoderconfig
* added test to avoid diverging configs of wrapper class and wrapped classes
* Update src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
* make style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* updating the checkpoint for GPT2ForSequence Classification to one with classification head (#11434)
* add pooling layer support (#11439)
* make style (#11442)
* Pin black to 20.8.b1
* With style
* Pin black to 21.4b0
* TF BART models - Add `cross_attentions` to model output and fix cross-attention head masking (#10699)
* Add cross_attn_head_mask to BART
* Fix cross_attentions in TFBart-like models
* This commit enables returning of `cross_attentions`
for TFBart-like models
* It also fixes attention head masking in cross-attenion module
* Update TF model templates
* Fix missing , in TF model templates
* Fix typo: congig -> config
* Add basic support for FP16 in SageMaker model parallelism (#11407)
* Add FP16 support for SageMaker MP
* Add print debugs
* Squeeze
* Remove debug statements
* Add defensive check
* Typo
* docs(examples): fix link to TPU launcher script (#11427)
* fix some typos in docs, comments, logging/errors (#11432)
* Pass along seed to DistributedSampler (#11406)
* Pass along seed to DistributedSampler
* Add seed to DistributedLengthGroupedSampler
* Clarify description of the is_split_into_words argument (#11449)
* Improve documentation for is_split_into_words argument
* Change description wording
* [docs] fix invalid class name (#11438)
* fix invalid class name
* proper ref
* proper ref
* make sure to test against the local checkout (#11437)
* Style
* Give each test a different repo name (#11453)
* [Examples] Fixes inconsistency around eval vs val and predict vs test (#11380)
* added changes for uniformity
* modified files
* corrected typo
* fixed qa scripts
* fix typos
* fixed predict typo in qa no trainer
* fixed test file
* reverted trainer changes
* reverted trainer changes in custom exmaples
* updated readme
* added changes in deepspeed test
* added changes for predict and eval
* Variable Correction for Consistency in Distillation Example (#11444)
As the error comes from the inconsistency of variable meaning number of gpus in parser and its actual usage in the train.py script, 'gpus' and 'n_gpu' respectively, the correction makes the example work
* [Deepspeed] ZeRO-Infinity integration plus config revamp (#11418)
* adding Z-inf
* revamp config process
* up version requirement
* wip
* massive rewrite
* cleanup
* cleanup
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* consistent json commas
* act on suggestions
* leave this feature for 0.3.16
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Remove max length beam scorer (#11378)
* removed max_len
* removed max_length from BeamSearchScorer
* correct max length
* finish
* del vim
* finish & add test
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* update QuickTour docs to reflect model output object (#11462)
* update docs to reflect model output object
* run make style`
* Finish Making Quick Tour respect the model object (#11467)
* finish quicktour
* fix import
* fix print
* explain config default better
* Update docs/source/quicktour.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docs for decoder_input_ids (#11466)
* fix docs for decoder_input_ids
* revert the changes for bart and mbart
* Update min versions in README and add Flax (#11472)
* Update min versions in README and add Flax
* Adapt index
* Update `PreTrainedTokenizerBase` to check/handle batch length for `text_pair` parameter (#11486)
* Update tokenization_utils_base.py
* add assertion
* check batch len
* Update src/transformers/tokenization_utils_base.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* add error message
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix #1149 (#11493)
* [Flax] Add docstrings & model outputs (#11498)
* add attentions & hidden states
* add model outputs + docs
* finish docs
* finish tests
* finish impl
* del @
* finish
* finish
* correct test
* apply sylvains suggestions
* Update src/transformers/models/bert/modeling_flax_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* simplify more
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Reformat to make code clearer in tokenizer call (#11497)
* Reformat to make code clearer
* Reformat to make code clearer
* solved coefficient issue for the TF version of gelu_fast (#11514)
Co-authored-by: Michael Benayoun <michael@huggingface.co>
* Split checkpoint from model_name_or_path in examples (#11492)
* Split checkpoint from model_name_or_path in examples
* Address review comments
* Address review comments
* Patch notification service
* Pin HuggingFace Hub dependency (#11502)
* correct the dimension comment of matrix multiplication (#11494)
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
* add sp_model_kwargs to unpickle of xlm roberta tok (#11430)
add test for pickle
simplify test
fix test code style
add missing pickle import
fix test
fix test
fix test
* make style (#11520)
* Update README.md (#11489)
Add link to code
* T5 Gradient Checkpointing (#11353)
* Implement gradient checkpoinging for T5Stack
* A bit more robust type checking
* Add `gradient_checkpointing` to T5Config
* Formatting
* Set requires_grad only when training
* None return value will only cause problems when training
* Change the output tuple according to `use_cache`
* Enable gradient checkpointing for the decoder
Squashed commit of the following:
commit 658bdd0bd1215353a8770f558bda2ea69a0ad0c7
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 14:08:17 2021 +0800
Only set `require_grad` for gradient checkpointing
commit acaeee6b2e675045fb28ce2176444c1d63e908bd
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 13:59:35 2021 +0800
Make gradient checkpointing work with the decoder
* Formatting
* Adding `AutomaticSpeechRecognitionPipeline`. (#11337)
* Adding `AutomaticSpeechRecognitionPipeline`.
- Because we added everything to enable this pipeline, we probably
should add it to `transformers`.
- This PR tries to limit the scope and focuses only on the pipeline part
(what should go in, and out).
- The tests are very specific for S2T and Wav2vec2 to make sure both
architectures are supported by the pipeline. We don't use the mixin for
tests right now, because that requires more work in the `pipeline`
function (will be done in a follow up PR).
- Unsure about the "helper" function `ffmpeg_read`. It makes a lot of
sense from a user perspective, it does not add any additional
dependencies (as in hard dependency, because users can always use their
own load mechanism). Meanwhile, it feels slightly clunky to have so much
optional preprocessing.
- The pipeline is not done to support streaming audio right now.
Future work:
- Add `automatic-speech-recognition` as a `task`. And add the
FeatureExtractor.from_pretrained within `pipeline` function.
- Add small models within tests
- Add the Mixin to tests.
- Make the logic between ForCTC vs ForConditionalGeneration better.
* Update tests/test_pipelines_automatic_speech_recognition.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding docs + main import + type checking + LICENSE.
* Doc style !.
* Fixing TYPE_HINT.
* Specifying waveform shape in the docs.
* Adding asserts + specify in the documentation the shape of the input
np.ndarray.
* Update src/transformers/pipelines/automatic_speech_recognition.py
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Adding require to tests + move the `feature_extractor` doc.
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Implement Fast Tokenization for Deberta (#11387)
* Accepts BatchEncoding in LengthSampler (#11431)
* Fix do_eval default value in training_args.py (#11511)
* Fix do_eval default value in training_args.py
* Update PULL_REQUEST_TEMPLATE.md
* Update TF text classification example (#11496)
Big refactor, fixes and multi-GPU/TPU support
* reszie token embeds (#11524)
* Run model templates on master (#11527)
* [Examples] Added support for test-file in QA examples with no trainer (#11510)
* added support for test-file
* fixed typo
* added suggested changes
* reformatted code
* modifed files
* fix post processing error
* Trigger CI
* removed extra lines
* Add Stas and Suraj as authors (#11526)
* Improve task summary docs (#11513)
* fix task summary docs
* refactor to use model.config.id2label instead of list
* fix nit
* Update docs/source/task_summary.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [debug utils] activation/weights underflow/overflow detector (#11274)
* sync
* add activation overflow debug utility
* cleanup
* document detect_overflow
* import torch
* add deprecation warning
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* convert to rst, add note
* add class
* fix docs
* improve the doc
* rework to dump a lot more info about each frame
* complete expansion
* cleanup
* format
* cleanup
* doesn't have to be transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wrap long line
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] fp32 support (#11499)
* prep for deepspeed==0.3.16
* new version
* too soon
* support and test fp32 mode
* troubleshooting doc start
* workaround no longer needed
* add fp32 doc
* style
* cleanup, add tf32 note
* clarify
* release was made
* Fixed docs for the shape of `scores` in `generate()` (#10057)
* Fixed the doc for the shape of return scores tuples in generation_utils.py.
* Fix the output shape of `scores` for `DecoderOnlyOutput`.
* style fix
* Fix examples in M2M100 docstrings (#11540)
Replaces `tok` with `tokenizer` so examples can run with copy-paste
* [Flax BERT/Roberta] few small fixes (#11558)
* small fixes
* style
* [Wav2Vec2] Fix convert (#11562)
* push
* small change
* correct other typo
* Remove `datasets` submodule. (#11563)
* fix the mlm longformer example by changing [MASK] to <mask> (#11559)
* Add LUKE (#11223)
* Rebase with master
* Minor bug fix in docs
* Copy files from adding_luke_v2 and improve docs
* change the default value of use_entity_aware_attention to True
* remove word_hidden_states
* fix head models
* fix tests
* fix the conversion script
* add integration tests for the pretrained large model
* improve docstring
* Improve docs, make style
* fix _init_weights for pytorch 1.8
* improve docs
* fix tokenizer to construct entity sequence with [MASK] entity when entities=None
* Make fix-copies
* Make style & quality
* Bug fixes
* Add LukeTokenizer to init
* Address most comments by @patil-suraj and @LysandreJik
* rename _compute_extended_attention_mask to get_extended_attention_mask
* add comments to LukeSelfAttention
* fix the documentation of the tokenizer
* address comments by @patil-suraj, @LysandreJik, and @sgugger
* improve docs
* Make style, quality and fix-copies
* Improve docs
* fix docs
* add "entity_span_classification" task
* update example code for LukeForEntitySpanClassification
* improve docs
* improve docs
* improve the code example in luke.rst
* rename the classification layer in LukeForEntityClassification from typing to classifier
* add bias to the classifier in LukeForEntitySpanClassification
* update docs to use fine-tuned hub models in code examples of the head models
* update the example sentences
* Make style & quality
* Add require_torch to tokenizer tests
* Add require_torch to tokenizer tests
* Address comments by @sgugger and add community notebooks
* Make fix-copies
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
* [Wav2vec2] Fixed tokenization mistakes while adding single-char tokens to tokenizer (#11538)
* Fixed tokenization mistakes while adding single-char tokens to tokenizer
* Added tests and Removed unnecessary comments.
* finalize wav2vec2 tok
* add more aggressive tests
* Apply suggestions from code review
* fix useless import
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Fix metric computation in `run_glue_no_trainer` (#11569)
* Fixes a useless warning. (#11566)
Fixes #11525
* Accumulate opt state dict on do_rank 0 (#11481)
* Update training tutorial (#11533)
* Update training tutorial
* Apply suggestions from code review
Co-authored-by: Hamel Husain <hamelsmu@github.com>
* Address review comments
* Update docs/source/training.rst
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* More review comments
* Last review comments
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fix resize_token_embeddings (#11572)
* Add multi-class, multi-label and regression to transformers (#11012)
* add to bert
* review comments
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* self.config.problem_type
* fix style
* fix
* fin
* fix
* update doc
* fix
* test
* Test more problem types
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix
* remove
* fix
* quality
* make fix-copies
* remove test
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* Enable added tokens (#11325)
* Fix tests
* Reorganize
* Update tests/test_modeling_mobilebert.py
* Remove unnecessary addition
* Make quality scripts work when one backend is missing. (#11573)
* Make quality scripts work when one backend is missing.
* Check env variable is properly set
* Add default
* With print statements
* Fix typo
* Set env variable
* Remove debug code
* [FlaxRoberta] Add FlaxRobertaModels & adapt run_mlm_flax.py (#11470)
* add flax roberta
* make style
* correct initialiazation
* modify model to save weights
* fix copied from
* fix copied from
* correct some more code
* add more roberta models
* Apply suggestions from code review
* merge from master
* finish
* finish docs
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
* Removes SageMakerTrainer code but keeps class as wrapper (#11587)
* removed all old code
* make quality
* [Flax] Add Electra models (#11426)
* add electra model to flax
* Remove Electra Next Sentence Prediction model added by mistake
* fix parameter sharing and loosen equality threshold
* fix styling issues
* add mistaken removen imports
* fix electra table
* Add FlaxElectra to automodels and fixe docs
* fix issues pointed out the PR
* fix flax electra to comply with latest changes
* remove stale class
* add copied from
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Reproducible checkpoint (#11582)
* Set generator in dataloader
* Use generator in all random samplers
* Checkpoint all RNG states
* Final version
* Quality
* Test
* Address review comments
* Quality
* Remove debug util
* Add python and numpy RNGs
* Split states in different files in distributed
* Quality
* local_rank for TPUs
* Only use generator when accepted
* Add test
* Set seed to avoid flakiness
* Make test less flaky
* Quality
* [trainer] document resume randomness (#11588)
* document resume randomness
* fix link
* reword
* fix
* reword
* style
* copies need to be fixed too (#11585)
* add importlib_metadata and huggingface_hub as dependency in the conda recipe (#11591)
* add importlib_metadata as dependency (#11490)
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* add huggingface_hub dependency
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* Skip Funnel test
* Pytorch - Lazy initialization of models (#11471)
* lazy_init_weights
* remove ipdb
* save int
* add necessary code
* remove unnecessary utils
* Update src/transformers/models/t5/modeling_t5.py
* clean
* add tests
* correct
* finish tests
* finish tests
* fix some more tests
* fix xlnet & transfo-xl
* fix more tests
* make sure tests are independent
* fix tests more
* finist tests
* final touches
* Update src/transformers/modeling_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* clean tests
* give arg positive name
* add more mock weights to xlnet
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Accept tensorflow-rocm package when checking TF availability (#11595)
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: JohnnyC08 <jcastaldo08@gmail.com>
Co-authored-by: Hemil Desai <hemil.desai10@gmail.com>
Co-authored-by: Josh <1113285+jsrozner@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: cchen-dialpad <47165889+cchen-dialpad@users.noreply.github.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: cronoik <johannes.schaffrath@mail.de>
Co-authored-by: Joe Davison <josephddavison@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: versis <versis791@gmail.com>
Co-authored-by: Eren Şahin <sahineren.09@gmail.com>
Co-authored-by: Amala Deshmukh <amala.d166@gmail.com>
Co-authored-by: konstin <konstin@mailbox.org>
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: SHYAM SUNDER KUMAR <beingprofess@gmail.com>
Co-authored-by: Leo Gao <54557097+leogao2@users.noreply.github.com>
Co-authored-by: Vasudev Gupta <7vasudevgupta@gmail.com>
Co-authored-by: Jannis Born <jannis.born@gmx.de>
Co-authored-by: Yusuke Mori <mori@mi.t.u-tokyo.ac.jp>
Co-authored-by: Julien Demouth <julien.demouth@gmail.com>
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Andrea Cappelli <ak314@users.noreply.github.com>
Co-authored-by: Niklas Muennighoff <62820084+Muennighoff@users.noreply.github.com>
Co-authored-by: Keisuke Hirota <tahiro.k.ad@gmail.com>
Co-authored-by: Saviour Owolabi <42647840+Seyviour@users.noreply.github.com>
Co-authored-by: Kevin Canwen Xu <canwenxu@126.com>
Co-authored-by: Masatoshi TSUCHIYA <tsuchm@users.noreply.github.com>
Co-authored-by: fghuman <f.z.ghuman@student.tudelft.nl>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
Co-authored-by: Takuya Makino <takuyamakino15@gmail.com>
Co-authored-by: calpt <calpt@mail.de>
Co-authored-by: Ceyda Cinarel <15624271+cceyda@users.noreply.github.com>
Co-authored-by: Nithin Holla <nithin.holla7@gmail.com>
Co-authored-by: nithin19 <nithin@amberscript.com>
Co-authored-by: Joel Stremmel <joelstremmel22@gmail.com>
Co-authored-by: Sudharsan S T <stsudharshan@gmail.com>
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
Co-authored-by: Thomas Wood <odell.wood@gmail.com>
Co-authored-by: Nicolas Patry <patry.nicolas@protonmail.com>
Co-authored-by: e <e_yi@foxmail.com>
Co-authored-by: TAE YOUNGDON <49802647+taepd@users.noreply.github.com>
Co-authored-by: rajvi-k <rajvi.kapadia01@gmail.com>
Co-authored-by: lewtun <lewis.c.tunstall@gmail.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: wlhgtc <hgtcwl@foxmail.com>
Co-authored-by: johnson7788 <linghuchongxajh@gmail.com>
Co-authored-by: johnson <johnson@github.com>
Co-authored-by: PenutChen <penut85420@gmail.com>
Co-authored-by: Max Del <max.del.edu@gmail.com>
Co-authored-by: Yoshitomo Matsubara <yoshitomo-matsubara@users.noreply.github.com>
Co-authored-by: Teven <teven.lescao@gmail.com>
Co-authored-by: Kiran R <kiranr8k@gmail.com>
Co-authored-by: Nicola De Cao <nicola.decao@gmail.com>
Co-authored-by: Daniel Stancl <46073029+stancld@users.noreply.github.com>
Co-authored-by: Philip May <philip@may.la>
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: abiolaTresor <48957493+abiolaTresor@users.noreply.github.com>
Co-authored-by: Amine Abdaoui <abdaoui@lirmm.fr>
Co-authored-by: LSinev <LSinev@users.noreply.github.com>
Co-authored-by: Kostas Stathoulopoulos <k.stathoylopoylos@gmail.com>
Co-authored-by: Bhadresh Savani <bhadreshpsavani@gmail.com>
Co-authored-by: Jaimeen Ahn <32367255+jaimeenahn@users.noreply.github.com>
Co-authored-by: Ashwin Geet D'Sa <win.12894@gmail.com>
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Hamel Husain <hamel.husain@gmail.com>
Co-authored-by: Michael Benayoun <mickbenayoun@gmail.com>
Co-authored-by: Michael Benayoun <michael@huggingface.co>
Co-authored-by: Frederik Bode <fredo.bode@gmail.com>
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
Co-authored-by: Manuel Romero <mrm8488@gmail.com>
Co-authored-by: CeShine Lee <ceshine@users.noreply.github.com>
Co-authored-by: Shubham Sanghavi <shubham.sanghavi@outlook.com>
Co-authored-by: bonniehyeon <50580028+bonniehyeon@users.noreply.github.com>
Co-authored-by: jingyihe <29100716+kylie-box@users.noreply.github.com>
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
Co-authored-by: Muktan <muktan123@gmail.com>
Co-authored-by: abhishek thakur <1183441+abhi1thakur@users.noreply.github.com>
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
Co-authored-by: Patrick Fernandes <pattuga@gmail.com>
Co-authored-by: Deepali <70963368+cdeepali@users.noreply.github.com>
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
Co-authored-by: Mats Sjöberg <mats.sjoberg@csc.fi>
* Add more metadata to the user agent (#10972)
* Add more metadata to the user agent
* Fix typo
* Use DISABLE_TELEMETRY
* Address review comments
* Use global env
* Add clean envs on circle CI
* Enforce string-formatting with f-strings (#10980)
* First third
* Styling and fix mistake
* Quality
* All the rest
* Treat %s and %d
* typo
* Missing )
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* add notebook (#10995)
* Merge trainers (#10975)
* Replace is_sagemaker_distributed_available
* Merge SageMakerTrainer into Trainer
* Test with shorter condition
* Put back deleted line
* Deprecate SageMakerTrainer and SageMakerTrainingArguments
* Apply suggestions from code review
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
* add blog to docs (#10997)
* Update training_args.py (#11000)
In the group by length documentation length is misspelled as legnth
* Add `examples/language_modeling/run_mlm_no_trainer.py` (#11001)
* Add initial script for finetuning MLM models with accelerate
* Add evaluation metric calculation
* Fix bugs
* Use no_grad on evaluation
* update script docstring
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* PR feedback
* Fix CI failure
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix Adafactor documentation (recommend correct settings) (#10526)
* Update optimization.py
Fix documentation to reflect optimal settings for Adafactor
* update and expand on the recommendations
* style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* flip scale_parameter to True for the 2nd recommendatoin
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Improve the speed of adding tokens from added_tokens.json (#10780)
* use bisect to add one token to unique_no_split_tokens
* fix style
* Add Vision Transformer and ViTFeatureExtractor (#10950)
* Squash all commits into one
* Update ViTFeatureExtractor to use image_utils instead of torchvision
* Remove torchvision and add Pillow
* Small docs improvement
* Address most comments by @sgugger
* Fix tests
* Clean up conversion script
* Pooler first draft
* Fix quality
* Improve conversion script
* Make style and quality
* Make fix-copies
* Minor docs improvements
* Should use fix-copies instead of manual handling
* Revert "Should use fix-copies instead of manual handling"
This reverts commit fd4e591bce4496d41406425c82606a8fdaf8a50b.
* Place ViT in alphabetical order
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* DebertaTokenizer Rework closes #10258 (#10703)
* closes #10258
* typo
* reworked deberta test
* implemented the comments from BigBird01 regarding sequence pair encoding of deberta
* Update style
* VOCAB_FILES_NAMES is now a oneliner as suggested by @sgugger
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* added #fmt: on as requested by @sgugger
* Style
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* minor typo fix
*negative* log-likelihood
* [doc] no more bucket
* added new notebook and merge of trainer (#11015)
* added new notebook and merge of trainer
* Update docs/source/sagemaker.md
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fixed typo: logging instead of logger (#11025)
* Add a script to check inits are consistent (#11024)
* s|Pretrained|PreTrained| (#11048)
* [doc] update code-block rendering (#11053)
double : prevents code-block section to be rendered, so made it single :
* Pin docutils (#11062)
* Pin docutils
* Versions table
* Remove unnecessary space (#11060)
* Some models have no tokenizers (#11064)
* Refactor AutoModel classes and add Flax Auto classes (#11027)
* Refactor AutoModel classes and add Flax Auto classes
* Add new objects to the init
* Fix hubconf and sort models
* Fix TF tests
* Missing coma
* Update src/transformers/models/auto/auto_factory.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Fix init
* Fix dummies
* Other init to fix
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Documentation about loading a fast tokenizer within Transformers (#11029)
* Documentation about loading a fast tokenizer within Transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add example for registering callbacks with trainers (#10928)
* Add example for callback registry
Resolves: #9036
* Update callback registry documentation
* Added comments for other ways to register callback
* Add `examples/language_modeling/run_clm_no_trainer.py` (#11026)
* Initial draft for clm no trainer
* Remove unwanted args
* Fix bug
* Update examples/language-modeling/run_clm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace pkg_resources with importlib_metadata (#11061)
* Replace pkg_resources with importlib_metadata
Fixes #10964. The other reason for this change is that pkg_resources has been [deprecated](https://github.com/pypa/setuptools/commit/8fe85c22cee7fde5e6af571b30f864bad156a010) in favor of importlib_metadata.
* Reduce to a single importlib_metadata import switch
* Trigger CI
Co-authored-by: Stas Bekman <stas@stason.org>
* Add center_crop to ImageFeatureExtractoMixin (#11066)
* Document common config attributes (#11070)
* Fix distributed gather for tuples of tensors of varying sizes (#11071)
* Make a base init in FeatureExtractionMixin (#11074)
* Add Readme for language modeling scripts with accelerate (#11073)
* HF emoji unicode doesn't work in console (#11081)
It doesn't look like using 🤗 is a great idea for printing to console. See attachment.
This PR proposes to replace 🤗 with "HuggingFace" for an exception message.
@LysandreJik
* Link to new blog
* added social thumbnail for docs (#11083)
* added new merged Trainer test (#11090)
* [WIP] GPT Neo cleanup (#10985)
* better names
* add attention mixin
* all slow tests in one class
* make helper methods static so we can test
* add local attention tests
* better names
* doc
* apply review suggestions
* Release v4.5.0
* Development on v4.6.0dev0
* [doc] gpt-neo (#11098)
make the example work
* Auto feature extractor (#11097)
* AutoFeatureExtractor
* Init and first tests
* Tests
* Damn you gitignore
* Quality
* Defensive test for when not all backends are here
* Use pattern for Speech2Text models
* accelerate question answering examples with no trainer (#11091)
* accelerate question answering examples with no trainer
* removed train and eval flags also fixed fill np array function
* Update examples/question-answering/run_qa_beam_search_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update examples/question-answering/run_qa_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Style
* dead link fixed (#11103)
* GPTNeo: handle padded wte (#11079)
* GPTNeo: handle padded wte
* Switch to config.vocab_size
* apply review suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* fix: The 'warn' method is deprecated (#11105)
* The 'warn' method is deprecated
* fix test
* [examples] fix white space (#11099)
these get concatenated without whitespace, so fix it
* Dummies multi backend (#11100)
* Replaces requires_xxx by one generic method
* Quality and update check_dummies
* Fix inits check
* Post-merge cleanup
* Some styling of the training table in Notebooks (#11118)
* Adds a note to resize the token embedding matrix when adding special … (#11120)
* Adds a note to resize the token embedding matrix when adding special tokens
* Remove superfluous space
* fix tests (#11109)
* [versions] handle version requirement ranges (#11110)
* handle version requirement ranges
* add mixed requirement test
* cleanup
* Adds use_auth_token with pipelines (#11123)
* added model_kwargs to infer_framework_from_model
* added model_kwargs to tokenizer
* added use_auth_token as named parameter
* added dynamic get for use_auth_token
* Fix and refactor check_repo (#11127)
* Fix typing error in Trainer class (prediction_step) (#11138)
* fix: docstrings in prediction_step
* ci: Satisfy line length requirements
* ci: character length requirements
* Typo fix of the name of BertLMHeadModel in BERT doc (#11133)
* [run_clm] clarify why we get the tokenizer warning on long input (#11145)
* clarify why we get the warning here
* Update examples/language-modeling/run_clm.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wording
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] ZeRO Stage 3 (#10753)
* synced gpus
* fix
* fix
* need to use t5-small for quality tests
* notes
* complete merge
* fix a disappearing std stream problem
* start zero3 tests
* wip
* tune params
* sorting out the pre-trained model loading
* reworking generate loop wip
* wip
* style
* fix tests
* split the tests
* refactor tests
* wip
* parameterized
* fix
* workout the resume from non-ds checkpoint pass + test
* cleanup
* remove no longer needed code
* split getter/setter functions
* complete the docs
* suggestions
* gpus and their compute capabilities link
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* style
* remove invalid paramgd
* automatically configure zero3 params that rely on hidden size
* make _get_resized_embeddings zero3-aware
* add test exercising resize_token_embeddings()
* add docstring
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Add nvidia megatron models (#10911)
* Add support for NVIDIA Megatron models
* Add support for NVIDIA Megatron GPT2 and BERT
Add the megatron_gpt2 model. That model reuses the existing GPT2 model. This
commit includes a script to convert a Megatron-GPT2 checkpoint downloaded
from NVIDIA GPU Cloud. See examples/megatron-models/README.md for details.
Add the megatron_bert model. That model is implemented as a modification of
the existing BERT model in Transformers. This commit includes a script to
convert a Megatron-BERT checkpoint downloaded from NVIDIA GPU Cloud. See
examples/megatron-models/README.md for details.
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Remove model.half in tests + add "# Copied ..."
Remove the model.half() instruction which makes tests fail on the CPU.
Add a comment "# Copied ..." before many classes in the model to enable automatic
tracking in CI between the new Megatron classes and the original Bert ones.
* Fix issues
* Fix Flax/TF tests
* Fix copyright
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update docs/source/model_doc/megatron_bert.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update docs/source/model_doc/megatron_gpt2.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/__init__.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Resolve most of 'sgugger' comments
* Fix conversion issue + Run make fix-copies/quality/docs
* Apply suggestions from code review
* Causal LM & merge
* Fix init
* Add CausalLM to last auto class
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [trainer] solve "scheduler before optimizer step" warning (#11144)
* solve "scheduler before optimizer step" warning
* style
* correct the state evaluation test
* Add fairscale and deepspeed back to the CI (#11147)
* Add fairscale and deepspeed back to the CI
* Add deepspeed to single GPU tests
* Updates SageMaker docs for updating DLCs (#11140)
* Don't duplicate logs in TensorBoard and handle --use_env (#11141)
* Run mlm pad to multiple for fp16 (#11128)
* Add mlm collator pad to multiple option (#10627)
* Use padding to 8x in run mlm (#10627)
* [tests] relocate core integration tests (#11146)
* relocate core integration tests
* add sys.path context manager
* cleanup
* try
* try2
* fix path
* doc
* style
* add dep
* add 2 more deps
* [setup] extras[docs] must include 'all' (#11148)
* extras[doc] must include 'all'
* fix
* better
* regroup
* Add support for multiple models for one config in auto classes (#11150)
* Add support for multiple models for one config in auto classes
* Use get_values everywhere
* Prettier doc
* [setup] make fairscale and deepspeed setup extras (#11151)
* make fairscale and deepspeed setup extras
* fix default
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* no reason not to ask for the good version
* update the CIs
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Skip Megatron tests for now
* typo (#11152)
* typo
* style
* [Community notebooks] Add Wav2Vec notebook for creating captions for YT Clips (#11142)
* Add Wav2Vec Inference notebook
* Update docs/source/community.md
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Fix LogitsProcessor documentation (#11130)
* Change duplicated LogitsProcessor to LogitsWarper in LogitsProcessorList document
* Write more detailed information about LogitsProcessor's scores argument
* apply suggestion from review
* style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Update README.md (#11161)
Corrected a typo ('Downlowd' to 'Download')
* Make `get_special_tokens_mask` consider all tokens (#11163)
* Add a special tokenizer for CPM model (#11068)
* Add a special tokenizer for CPM model
* make style
* fix
* Add docs
* styles
* cpm doc
* fix ci
* fix the overview
* add test
* make style
* typo
* Custom tokenizer flag
* Add REAMDE.md
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [examples/translation] support mBART-50 and M2M100 fine-tuning (#11170)
* keep a list of multilingual tokenizers
* add forced_bos_token argument
* [examples run_clm] fix _LazyModule hasher error (#11168)
* fix _LazyModule hasher error
* reword
* added json dump and extraction of train run time (#11167)
* added json dump and extraction of train run time
* make style happy
* Fix Typo
* Reactivate Megatron tests an use less workers
* Minor typos fixed (#11182)
* Fix style
* model_path should be ignored as the checkpoint path (#11157)
* model_path is refered as the path of the trainer, and should be ignored as the checkpoint path.
* Improved according to Sgugger's comment.
* Added documentation for data collator. (#10941)
* Added documentation for data collator.
* Update docs/source/data_collator.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Added documentation for data collator.
* Added documentation for the data collator.
* Merge branch 'doc_DataCollator' of C:\Users\mahii\PycharmProjects\transformers with conflicts.
* Update documentation for the data collator.
* Update documentation for the data collator.
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
* Fix typo (#11188)
* Add DeiT (PyTorch) (#11056)
* First draft of deit
* More improvements
* Remove DeiTTokenizerFast from init
* Conversion script works
* Add DeiT to ViT conversion script
* Add tests, add head model, add support for deit in vit conversion script
* Update model checkpoint names
* Update image_mean and image_std, set resample to bicubic
* Improve docs
* Docs improvements
* Add DeiTForImageClassificationWithTeacher to init
* Address comments by @sgugger
* Improve feature extractors
* Make fix-copies
* Minor fixes
* Address comments by @patil-suraj
* All models uploaded
* Fix tests
* Remove labels argument from DeiTForImageClassificationWithTeacher
* Fix-copies, style and quality
* Fix tests
* Fix typo
* Multiple docs improvements
* More docs fixes
* Replaced `which` with `who` (#11183)
* Import torch.utils.checkpoint in ProphetNet (#11214)
* Sagemaker test docs update for framework upgrade (#11206)
* increased train_runtime for model parallelism
* added documentation for framework upgrade
* Use MSELoss in (M)BartForSequenceClassification (#11178)
* wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model (#11041)
* add vocab while converting wav2vec2 original finetuned model
* check save directory exists
* return_attention_mask fix
* quality
* Add Matt as the TensorFlow reference (#11212)
* Fix GPT-2 warnings (#11213)
* Fix GPT-2 warnings
* Update src/transformers/models/gpt2/modeling_gpt2.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* fix docstrings (#11221)
* Add documentation for BertJapanese (#11219)
* Start writing BERT-Japanese doc
* Fix typo, Update toctree
* Modify model file to use comment for document, Add examples
* Clean bert_japanese by make style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Split a big code block into two
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add prefix >>> to all lines in code blocks
* Clean bert_japanese by make fixup
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace error by warning when loading an architecture in another (#11207)
* Replace error by warning when loading an architecture in another
* Style
* Style again
* Add a test
* Adapt old test
* Document v4.5.1
* Refactor GPT2 (#11225)
* refactor GPT2
* fix mlp and head pruning
* address Sylvains comments
* apply suggestion from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Doc check: a bit of clean up (#11224)
* added cache_dir=model_args.cache_dir to all example with cache_dir arg (#11220)
* Avoid using no_sync on SageMaker DP (#11229)
* Indent code block in the documentation (#11233)
* Indent code block
* Indent code blocks version 2
* Quality
* Run CI on deepspeed and fairscale (#11172)
* Run CI on deepspeed and fairscale
* Test it on this branch :)
* Rename
* Update the CI image
* [Deepspeed] zero3 tests band aid (#11235)
* temp band-aid
* style
* Save the Wav2Vec2 processor before training starts (#10910)
Co-authored-by: nithin19 <nithin@amberscript.com>
* make embeddings plural in warning message (#11228)
* Stale bot updated (#10562)
* Updated stale bot
* Specify issue number
* Remove particular handling of assignees
* Unleash the stalebot
* Remove debug branch
* Close open files to suppress ResourceWarning (#11240)
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
* Fix dimention misspellings. (#11238)
* Update modeling_gpt_neo.py
dimention -> dimension
* Update configuration_speech_to_text.py
dimention -> dimension
* Add prefix to examples in model_doc rst (#11226)
* Add prefix to examples in model_doc rst
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [troubleshooting] add 2 points of reference to the offline mode (#11236)
* add 2 points of reference to the offline mode
* link the new doc
* add error message
* Update src/transformers/modeling_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
* rename
* Trigger CI
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix #10128 (#11248)
* [deepspeed] test on one node 2 gpus max (#11237)
* test on one node 2 gpus max
* fix the other place
* refactor
* fix
* cleanup
* more exact version
* Trainer iterable dataset (#11254)
* IterableDatasetShard
* Test and integration in Trainer
* Update src/transformers/trainer_pt_utils.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Style
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding pipeline task aliases. (#11247)
* Adding task aliases and adding `token-classification` and
`text-classification` tasks.
* Cleaning docstring.
* Support for set_epoch (#11258)
* Tokenizer fast save (#11234)
* Save fast tokenizers in both formats
* Fix for HerBERT
* Proper fix
* Properly test new behavior
* update dependency_versions_table (#11273)
missed this updating when bumped the version.
* Workflow fixes (#11270)
* Enabling multilingual models for translation pipelines. (#10536)
* [WIP] Enabling multilingual models for translation pipelines.
* decoder_input_ids -> forced_bos_token_id
* Improve docstring.
* Rebase
* Fixing 2 bugs
- Type token_ids coming from `_parse_and_tokenize`
- Wrong index from tgt_lang.
* Fixing black version.
* Adding tests for _build_translation_inputs and add them for all
tokenizers.
* Mbart actually puts the lang code at the end.
* Fixing m2m100.
* Adding TF support to `deep_round`.
* Update src/transformers/pipelines/text2text_generation.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Adding one line comment.
* Fixing M2M100 `_build_translation_input_ids`, and fix the call site.
* Fixing tests + deep_round -> nested_simplify
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix failing workflows
* Trainer support for IterableDataset for evaluation and predict (#11286)
* Bulk of the work
* Polish and tests
* Update QA Trainer
* Avoid breaking the predict method
* Deprecation warnings
* Store real eval dataloder
* Get eval dataset reference before wrap
* move device statements outside if statements (#11292)
* modify double considering special tokens in `language_modeling.py` (#11275)
* Update language_modeling.py
in "class TextDatasetForNextSentencePrediction(Dataset)", double considering "self.tokenizer.num_special_tokens_to_add(pair=True)"
so, i remove self.block_size, and add parameter for "def create_examples_from_document". like "class LineByLineWithSOPTextDataset" do
* Update language_modeling.py
* [Trainer] fix the placement on device with fp16_full_eval (#11322)
* fix the placement on device with fp16_full_eval
* deepspeed never goes on device
* [Trainer] Add a progress bar for batches skipped (#11324)
* Load checkpoint without re-creating the model (#11318)
* Added translation example script (#11196)
* initial changes
* modified evaluation
* updated evaluation
* updated evaluation on text translation example script
* added translation example script
* Formatted translation example script
* Reformatted translation example
* Fixed evaluation bug and added support for other tokenisers
* Fixed evaluation bug and added support for other tokenisers
* Added translation example script
* Formatted summarization example script
* Removed typos from summarization example script
* [Generate] Remove outdated code (#11331)
* remove update function
* update
* refactor more
* refactor
* [GPTNeo] create local attention mask ones (#11335)
* create local attention mask ones
* remove old method, address patricks comment
* Update to use datasets remove_cloumns method (#11343)
* Update to use datasets remove_cloumns method
* Quality
* Add an error message that fires when Reformer is not in training mode, but one runs .backward() (#11117)
* Removed `max_length` from being mandatory within `generate`. (#11314)
* Removed `max_length` from being mandatory within `generate`.
- Moving on to fully using `StoppingCriteria` for `greedy` and `sample`
modes.
- `max_length` still used for `beam_search` and `group_beam_search`
(Follow up PR)
- Fixes a bug with MaxLengthStoppingCriteria (we should stop as soon a
we hit the max_length, the comparison needs to be or equal, that affects
the tests).
- Added options to use `logits_processor` and `stopping_criteria`
directly within `generate` function (so some users can define their own
`logits_processor` and `stopping_criteria`).
- Modified the backward compat tests to make sure we issue a warning.
* Fix `max_length` argument in `generate`.
* Moving validate to being functional.
- Renamed `smax_length` to `stoppping_max_length`.
* Removing `logits_processor` and `stopping_criteria` from `generate`
arguments.
* Deepcopy.
* Fix global variable name.
* Honor contributors to models (#11329)
* Honor contributors to models
* Fix typo
* Address review comments
* Add more authors
* [deepspeed] fix resume from checkpoint (#11352)
This PR fixes a bug that most likely somehow got exposed (not caused) by https://github.com/huggingface/transformers/pull/11318 - surprisingly the same test worked just fine before that other PR.
* Examples reorg (#11350)
* Base move
* Examples reorganization
* Update references
* Put back test data
* Move conftest
* More fixes
* Move test data to test fixtures
* Update path
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Address review comments and clean
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Extract metric_key_prefix during NotebookProgressCallback.on_evaluate (#11347)
* Pass metric_key_prefix as kwarg to on_evaluate
* Replace eval_loss with metric_key_prefix_loss
* Default to "eval" if metric_key_prefix not in kwargs
* Add kwargs to CallbackHandler.on_evaluate signature
* Revert "Add kwargs to CallbackHandler.on_evaluate signature"
This reverts commit 8d4c85ed512f558f7579d36771e907b3379947b7.
* Revert "Pass metric_key_prefix as kwarg to on_evaluate"
This reverts commit 7766bfe2718601230ae593d37b1317bd53cfc075.
* Extract metric_key_prefix from metrics
* [testing doc] bring doc up to date (#11359)
* bring doc up to date
* fix
* Merge new TF example script (#11360)
First of the new and more idiomatic TF examples!
* Remove boiler plate code (#11340)
* remove boiler plate code
* adapt roberta
* correct docs
* finish refactor
* Move old TF text classification script to legacy (#11361)
And update README to explain the work-in-progress!
* [contributing doc] explain/link to good first issue (#11346)
* explain/link to good first issue
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix token_type_ids error for big_bird model. (#11355)
* MOD: fit chinese wwm to new datasets
* MOD: move wwm to new folder
* MOD: formate code
* Styling
* MOD add param and recover trainer
* MOD: add token_type_ids method for big bird
* MOD: format code
* MOD: format code
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
* Add huggingface_hub dep for #11328
* Add in torchhub
* [Wav2Vec2] Fix special tokens for Wav2Vec2 tokenizer (#11349)
* fix wav2vec2 tok
* up
* [Flax] Correct typo (#11374)
* finish
* fix copy
* [run_translation.py] fix typo (#11372)
fix typo
Co-authored-by: johnson <johnson@github.com>
* Add space (#11373)
* Correctly cast num_train_epochs to int (#11379)
* Fix typo (#11369)
* Fix Trainer with remove_unused_columns=False (#11382)
* Fix Trainer with remove_unused_columns=False
* Typo
* [Flax] Big FlaxBert Refactor (#11364)
* improve flax
* refactor
* typos
* Update src/transformers/modeling_flax_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_flax_utils.py
* fix typo
* improve error tolerance
* typo
* correct nasty saving bug
* fix from pretrained
* correct tree map
* add note
* correct weight tying
* correct typo (#11393)
* correct conversion (#11394)
* Fix typo in text (#11396)
* fixed typos (#11391)
* make blenderbot test slow (#11395)
* Fixed trainer total_flos relaoding in distributed mode (#11383)
* Fixed trainer total_flos relaoding in distributed mode
* logging flos at the end of training
* Trainer push to hub (#11328)
* Initial support for upload to hub
* push -> upload
* Fixes + examples
* Fix torchhub test
* Torchhub test I hate you
* push_model_to_hub -> push_to_hub
* Apply mixin to other pretrained models
* Remove ABC inheritance
* Add tests
* Typo
* Run tests
* Install git-lfs
* Change approach
* Add push_to_hub to all
* Staging test suite
* Typo
* Maybe like this?
* More deps
* Cache
* Adapt name
* Quality
* MOAR tests
* Put it in testing_utils
* Docs + torchhub last hope
* Styling
* Wrong method
* Typos
* Update src/transformers/file_utils.py
Co-authored-by: Julien Chaumond <julien@huggingface.co>
* Address review comments
* Apply suggestions from code review
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* push (#11400)
* added support for exporting of t5 to onnx with past_key_values (#10651)
* Fixing bug in generation (#11297)
When passing `inputs_embeds` and not `input_ids=None` the generation function fails because `input_ids` is created but the function but it should not.
* Style
* Try to trigger failure more
* Wrong branch Sylvain...
* Fix cross-attention head mask for Torch encoder-decoder models (#10605)
* Fix cross-attention head mask for Torch BART models
* Fix head masking for cross-attention module for the following
models: BART, Blenderbot, Blenderbot_small, M2M_100, Marian, MBart,
Pegasus
* Enable test_headmasking for M2M_100 model
* Fix cross_head_mask for FSMT, LED and T5
* This commit fixes `head_mask` for cross-attention modules
in the following models: FSMT, LED, T5
* It also contains some smaller changes in doc so that
it is be perfectly clear the shape of `cross_head_mask`
is the same as of `decoder_head_mask`
* Update template
* Fix template for BartForCausalLM
* Fix cross_head_mask for Speech2Text models
* Fix cross_head_mask in templates
* Fix args order in BartForCausalLM template
* Fix doc in BART templates
* Make more explicit naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Fix doc
* make style quality
* Fix speech2text docstring
* Default to accuracy metric (#11405)
* Enable option for subword regularization in `XLMRobertaTokenizer` (#11149)
* enable subword regularization.
* fix tokenizer storage
* fix docstring formatting
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Stefan Schweter <stefan@schweter.it>
* fix docstring formatting
* add test for subword regularization tokenizer
* improve comments of test
* add sp_model_kwargs
* reformat docstring to match the style
* add some more documentation
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* improve docstring
* empty commit to trigger CI
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docstring formatting for sphinx
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Use 3 workers for torch tests
* documentation linked to the parent class PreTrainedTokenizerFast but it should be the slow tokenizer (#11410)
* Style
* Add head_mask, decoder_head_mask, cross_head_mask to ProphetNet (#9964)
* Add head_mask & decoder_head_mask + some corrections
* Fix head masking for N-grams
* Enable test_headmasking for encoder and decod
* Fix one typo regarding in modeling_propgetnet.py
* Enable test_headmasking for ProphetNetStandaloneDecoderModelTest
and ProphetNetStandaloneEncoderModelTest in test_modeling_prophetnet.py
* make style
* Fix cross_head_mask
* Fix attention head mask naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Still need to merge #10605 to master to pass the tests
* EncoderDecoderConfigs should not create new objects (#11300)
* removes the creation of separate config objects and uses the existing ones instead+overwrite resize_token_embeddings from parent class because it is not working for the EncoderDecoderModel
* rollback to current version of the huggingface master branch
* reworked version that ties the encoder and decoder config of the parent encoderdecoder instance
* overwrite of resize_token_embeddings throws an error now
* review comment suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* implemented warning in case encoderdecoder is created with differing configs of encoderdecoderconfig and decoderconfig or encoderconfig
* added test to avoid diverging configs of wrapper class and wrapped classes
* Update src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
* make style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* updating the checkpoint for GPT2ForSequence Classification to one with classification head (#11434)
* add pooling layer support (#11439)
* make style (#11442)
* Pin black to 20.8.b1
* With style
* Pin black to 21.4b0
* TF BART models - Add `cross_attentions` to model output and fix cross-attention head masking (#10699)
* Add cross_attn_head_mask to BART
* Fix cross_attentions in TFBart-like models
* This commit enables returning of `cross_attentions`
for TFBart-like models
* It also fixes attention head masking in cross-attenion module
* Update TF model templates
* Fix missing , in TF model templates
* Fix typo: congig -> config
* Add basic support for FP16 in SageMaker model parallelism (#11407)
* Add FP16 support for SageMaker MP
* Add print debugs
* Squeeze
* Remove debug statements
* Add defensive check
* Typo
* docs(examples): fix link to TPU launcher script (#11427)
* fix some typos in docs, comments, logging/errors (#11432)
* Pass along seed to DistributedSampler (#11406)
* Pass along seed to DistributedSampler
* Add seed to DistributedLengthGroupedSampler
* Clarify description of the is_split_into_words argument (#11449)
* Improve documentation for is_split_into_words argument
* Change description wording
* [docs] fix invalid class name (#11438)
* fix invalid class name
* proper ref
* proper ref
* make sure to test against the local checkout (#11437)
* Style
* Give each test a different repo name (#11453)
* [Examples] Fixes inconsistency around eval vs val and predict vs test (#11380)
* added changes for uniformity
* modified files
* corrected typo
* fixed qa scripts
* fix typos
* fixed predict typo in qa no trainer
* fixed test file
* reverted trainer changes
* reverted trainer changes in custom exmaples
* updated readme
* added changes in deepspeed test
* added changes for predict and eval
* Variable Correction for Consistency in Distillation Example (#11444)
As the error comes from the inconsistency of variable meaning number of gpus in parser and its actual usage in the train.py script, 'gpus' and 'n_gpu' respectively, the correction makes the example work
* [Deepspeed] ZeRO-Infinity integration plus config revamp (#11418)
* adding Z-inf
* revamp config process
* up version requirement
* wip
* massive rewrite
* cleanup
* cleanup
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* consistent json commas
* act on suggestions
* leave this feature for 0.3.16
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Remove max length beam scorer (#11378)
* removed max_len
* removed max_length from BeamSearchScorer
* correct max length
* finish
* del vim
* finish & add test
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* update QuickTour docs to reflect model output object (#11462)
* update docs to reflect model output object
* run make style`
* Finish Making Quick Tour respect the model object (#11467)
* finish quicktour
* fix import
* fix print
* explain config default better
* Update docs/source/quicktour.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docs for decoder_input_ids (#11466)
* fix docs for decoder_input_ids
* revert the changes for bart and mbart
* Update min versions in README and add Flax (#11472)
* Update min versions in README and add Flax
* Adapt index
* Update `PreTrainedTokenizerBase` to check/handle batch length for `text_pair` parameter (#11486)
* Update tokenization_utils_base.py
* add assertion
* check batch len
* Update src/transformers/tokenization_utils_base.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* add error message
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix #1149 (#11493)
* [Flax] Add docstrings & model outputs (#11498)
* add attentions & hidden states
* add model outputs + docs
* finish docs
* finish tests
* finish impl
* del @
* finish
* finish
* correct test
* apply sylvains suggestions
* Update src/transformers/models/bert/modeling_flax_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* simplify more
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Reformat to make code clearer in tokenizer call (#11497)
* Reformat to make code clearer
* Reformat to make code clearer
* solved coefficient issue for the TF version of gelu_fast (#11514)
Co-authored-by: Michael Benayoun <michael@huggingface.co>
* Split checkpoint from model_name_or_path in examples (#11492)
* Split checkpoint from model_name_or_path in examples
* Address review comments
* Address review comments
* Patch notification service
* Pin HuggingFace Hub dependency (#11502)
* correct the dimension comment of matrix multiplication (#11494)
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
* add sp_model_kwargs to unpickle of xlm roberta tok (#11430)
add test for pickle
simplify test
fix test code style
add missing pickle import
fix test
fix test
fix test
* make style (#11520)
* Update README.md (#11489)
Add link to code
* T5 Gradient Checkpointing (#11353)
* Implement gradient checkpoinging for T5Stack
* A bit more robust type checking
* Add `gradient_checkpointing` to T5Config
* Formatting
* Set requires_grad only when training
* None return value will only cause problems when training
* Change the output tuple according to `use_cache`
* Enable gradient checkpointing for the decoder
Squashed commit of the following:
commit 658bdd0bd1215353a8770f558bda2ea69a0ad0c7
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 14:08:17 2021 +0800
Only set `require_grad` for gradient checkpointing
commit acaeee6b2e675045fb28ce2176444c1d63e908bd
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 13:59:35 2021 +0800
Make gradient checkpointing work with the decoder
* Formatting
* Adding `AutomaticSpeechRecognitionPipeline`. (#11337)
* Adding `AutomaticSpeechRecognitionPipeline`.
- Because we added everything to enable this pipeline, we probably
should add it to `transformers`.
- This PR tries to limit the scope and focuses only on the pipeline part
(what should go in, and out).
- The tests are very specific for S2T and Wav2vec2 to make sure both
architectures are supported by the pipeline. We don't use the mixin for
tests right now, because that requires more work in the `pipeline`
function (will be done in a follow up PR).
- Unsure about the "helper" function `ffmpeg_read`. It makes a lot of
sense from a user perspective, it does not add any additional
dependencies (as in hard dependency, because users can always use their
own load mechanism). Meanwhile, it feels slightly clunky to have so much
optional preprocessing.
- The pipeline is not done to support streaming audio right now.
Future work:
- Add `automatic-speech-recognition` as a `task`. And add the
FeatureExtractor.from_pretrained within `pipeline` function.
- Add small models within tests
- Add the Mixin to tests.
- Make the logic between ForCTC vs ForConditionalGeneration better.
* Update tests/test_pipelines_automatic_speech_recognition.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding docs + main import + type checking + LICENSE.
* Doc style !.
* Fixing TYPE_HINT.
* Specifying waveform shape in the docs.
* Adding asserts + specify in the documentation the shape of the input
np.ndarray.
* Update src/transformers/pipelines/automatic_speech_recognition.py
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Adding require to tests + move the `feature_extractor` doc.
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Implement Fast Tokenization for Deberta (#11387)
* Accepts BatchEncoding in LengthSampler (#11431)
* Fix do_eval default value in training_args.py (#11511)
* Fix do_eval default value in training_args.py
* Update PULL_REQUEST_TEMPLATE.md
* Update TF text classification example (#11496)
Big refactor, fixes and multi-GPU/TPU support
* reszie token embeds (#11524)
* Run model templates on master (#11527)
* [Examples] Added support for test-file in QA examples with no trainer (#11510)
* added support for test-file
* fixed typo
* added suggested changes
* reformatted code
* modifed files
* fix post processing error
* Trigger CI
* removed extra lines
* Add Stas and Suraj as authors (#11526)
* Improve task summary docs (#11513)
* fix task summary docs
* refactor to use model.config.id2label instead of list
* fix nit
* Update docs/source/task_summary.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [debug utils] activation/weights underflow/overflow detector (#11274)
* sync
* add activation overflow debug utility
* cleanup
* document detect_overflow
* import torch
* add deprecation warning
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* convert to rst, add note
* add class
* fix docs
* improve the doc
* rework to dump a lot more info about each frame
* complete expansion
* cleanup
* format
* cleanup
* doesn't have to be transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wrap long line
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] fp32 support (#11499)
* prep for deepspeed==0.3.16
* new version
* too soon
* support and test fp32 mode
* troubleshooting doc start
* workaround no longer needed
* add fp32 doc
* style
* cleanup, add tf32 note
* clarify
* release was made
* Fixed docs for the shape of `scores` in `generate()` (#10057)
* Fixed the doc for the shape of return scores tuples in generation_utils.py.
* Fix the output shape of `scores` for `DecoderOnlyOutput`.
* style fix
* Fix examples in M2M100 docstrings (#11540)
Replaces `tok` with `tokenizer` so examples can run with copy-paste
* [Flax BERT/Roberta] few small fixes (#11558)
* small fixes
* style
* [Wav2Vec2] Fix convert (#11562)
* push
* small change
* correct other typo
* Remove `datasets` submodule. (#11563)
* fix the mlm longformer example by changing [MASK] to <mask> (#11559)
* Add LUKE (#11223)
* Rebase with master
* Minor bug fix in docs
* Copy files from adding_luke_v2 and improve docs
* change the default value of use_entity_aware_attention to True
* remove word_hidden_states
* fix head models
* fix tests
* fix the conversion script
* add integration tests for the pretrained large model
* improve docstring
* Improve docs, make style
* fix _init_weights for pytorch 1.8
* improve docs
* fix tokenizer to construct entity sequence with [MASK] entity when entities=None
* Make fix-copies
* Make style & quality
* Bug fixes
* Add LukeTokenizer to init
* Address most comments by @patil-suraj and @LysandreJik
* rename _compute_extended_attention_mask to get_extended_attention_mask
* add comments to LukeSelfAttention
* fix the documentation of the tokenizer
* address comments by @patil-suraj, @LysandreJik, and @sgugger
* improve docs
* Make style, quality and fix-copies
* Improve docs
* fix docs
* add "entity_span_classification" task
* update example code for LukeForEntitySpanClassification
* improve docs
* improve docs
* improve the code example in luke.rst
* rename the classification layer in LukeForEntityClassification from typing to classifier
* add bias to the classifier in LukeForEntitySpanClassification
* update docs to use fine-tuned hub models in code examples of the head models
* update the example sentences
* Make style & quality
* Add require_torch to tokenizer tests
* Add require_torch to tokenizer tests
* Address comments by @sgugger and add community notebooks
* Make fix-copies
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
* [Wav2vec2] Fixed tokenization mistakes while adding single-char tokens to tokenizer (#11538)
* Fixed tokenization mistakes while adding single-char tokens to tokenizer
* Added tests and Removed unnecessary comments.
* finalize wav2vec2 tok
* add more aggressive tests
* Apply suggestions from code review
* fix useless import
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Fix metric computation in `run_glue_no_trainer` (#11569)
* Fixes a useless warning. (#11566)
Fixes #11525
* Accumulate opt state dict on do_rank 0 (#11481)
* Update training tutorial (#11533)
* Update training tutorial
* Apply suggestions from code review
Co-authored-by: Hamel Husain <hamelsmu@github.com>
* Address review comments
* Update docs/source/training.rst
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* More review comments
* Last review comments
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fix resize_token_embeddings (#11572)
* Add multi-class, multi-label and regression to transformers (#11012)
* add to bert
* review comments
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* self.config.problem_type
* fix style
* fix
* fin
* fix
* update doc
* fix
* test
* Test more problem types
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix
* remove
* fix
* quality
* make fix-copies
* remove test
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* Enable added tokens (#11325)
* Fix tests
* Reorganize
* Update tests/test_modeling_mobilebert.py
* Remove unnecessary addition
* Make quality scripts work when one backend is missing. (#11573)
* Make quality scripts work when one backend is missing.
* Check env variable is properly set
* Add default
* With print statements
* Fix typo
* Set env variable
* Remove debug code
* [FlaxRoberta] Add FlaxRobertaModels & adapt run_mlm_flax.py (#11470)
* add flax roberta
* make style
* correct initialiazation
* modify model to save weights
* fix copied from
* fix copied from
* correct some more code
* add more roberta models
* Apply suggestions from code review
* merge from master
* finish
* finish docs
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
* Removes SageMakerTrainer code but keeps class as wrapper (#11587)
* removed all old code
* make quality
* [Flax] Add Electra models (#11426)
* add electra model to flax
* Remove Electra Next Sentence Prediction model added by mistake
* fix parameter sharing and loosen equality threshold
* fix styling issues
* add mistaken removen imports
* fix electra table
* Add FlaxElectra to automodels and fixe docs
* fix issues pointed out the PR
* fix flax electra to comply with latest changes
* remove stale class
* add copied from
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Reproducible checkpoint (#11582)
* Set generator in dataloader
* Use generator in all random samplers
* Checkpoint all RNG states
* Final version
* Quality
* Test
* Address review comments
* Quality
* Remove debug util
* Add python and numpy RNGs
* Split states in different files in distributed
* Quality
* local_rank for TPUs
* Only use generator when accepted
* Add test
* Set seed to avoid flakiness
* Make test less flaky
* Quality
* [trainer] document resume randomness (#11588)
* document resume randomness
* fix link
* reword
* fix
* reword
* style
* copies need to be fixed too (#11585)
* add importlib_metadata and huggingface_hub as dependency in the conda recipe (#11591)
* add importlib_metadata as dependency (#11490)
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* add huggingface_hub dependency
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* Skip Funnel test
* Pytorch - Lazy initialization of models (#11471)
* lazy_init_weights
* remove ipdb
* save int
* add necessary code
* remove unnecessary utils
* Update src/transformers/models/t5/modeling_t5.py
* clean
* add tests
* correct
* finish tests
* finish tests
* fix some more tests
* fix xlnet & transfo-xl
* fix more tests
* make sure tests are independent
* fix tests more
* finist tests
* final touches
* Update src/transformers/modeling_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* clean tests
* give arg positive name
* add more mock weights to xlnet
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Accept tensorflow-rocm package when checking TF availability (#11595)
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: JohnnyC08 <jcastaldo08@gmail.com>
Co-authored-by: Hemil Desai <hemil.desai10@gmail.com>
Co-authored-by: Josh <1113285+jsrozner@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: cchen-dialpad <47165889+cchen-dialpad@users.noreply.github.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: cronoik <johannes.schaffrath@mail.de>
Co-authored-by: Joe Davison <josephddavison@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: versis <versis791@gmail.com>
Co-authored-by: Eren Şahin <sahineren.09@gmail.com>
Co-authored-by: Amala Deshmukh <amala.d166@gmail.com>
Co-authored-by: konstin <konstin@mailbox.org>
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: SHYAM SUNDER KUMAR <beingprofess@gmail.com>
Co-authored-by: Leo Gao <54557097+leogao2@users.noreply.github.com>
Co-authored-by: Vasudev Gupta <7vasudevgupta@gmail.com>
Co-authored-by: Jannis Born <jannis.born@gmx.de>
Co-authored-by: Yusuke Mori <mori@mi.t.u-tokyo.ac.jp>
Co-authored-by: Julien Demouth <julien.demouth@gmail.com>
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Andrea Cappelli <ak314@users.noreply.github.com>
Co-authored-by: Niklas Muennighoff <62820084+Muennighoff@users.noreply.github.com>
Co-authored-by: Keisuke Hirota <tahiro.k.ad@gmail.com>
Co-authored-by: Saviour Owolabi <42647840+Seyviour@users.noreply.github.com>
Co-authored-by: Kevin Canwen Xu <canwenxu@126.com>
Co-authored-by: Masatoshi TSUCHIYA <tsuchm@users.noreply.github.com>
Co-authored-by: fghuman <f.z.ghuman@student.tudelft.nl>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
Co-authored-by: Takuya Makino <takuyamakino15@gmail.com>
Co-authored-by: calpt <calpt@mail.de>
Co-authored-by: Ceyda Cinarel <15624271+cceyda@users.noreply.github.com>
Co-authored-by: Nithin Holla <nithin.holla7@gmail.com>
Co-authored-by: nithin19 <nithin@amberscript.com>
Co-authored-by: Joel Stremmel <joelstremmel22@gmail.com>
Co-authored-by: Sudharsan S T <stsudharshan@gmail.com>
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
Co-authored-by: Thomas Wood <odell.wood@gmail.com>
Co-authored-by: Nicolas Patry <patry.nicolas@protonmail.com>
Co-authored-by: e <e_yi@foxmail.com>
Co-authored-by: TAE YOUNGDON <49802647+taepd@users.noreply.github.com>
Co-authored-by: rajvi-k <rajvi.kapadia01@gmail.com>
Co-authored-by: lewtun <lewis.c.tunstall@gmail.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: wlhgtc <hgtcwl@foxmail.com>
Co-authored-by: johnson7788 <linghuchongxajh@gmail.com>
Co-authored-by: johnson <johnson@github.com>
Co-authored-by: PenutChen <penut85420@gmail.com>
Co-authored-by: Max Del <max.del.edu@gmail.com>
Co-authored-by: Yoshitomo Matsubara <yoshitomo-matsubara@users.noreply.github.com>
Co-authored-by: Teven <teven.lescao@gmail.com>
Co-authored-by: Kiran R <kiranr8k@gmail.com>
Co-authored-by: Nicola De Cao <nicola.decao@gmail.com>
Co-authored-by: Daniel Stancl <46073029+stancld@users.noreply.github.com>
Co-authored-by: Philip May <philip@may.la>
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: abiolaTresor <48957493+abiolaTresor@users.noreply.github.com>
Co-authored-by: Amine Abdaoui <abdaoui@lirmm.fr>
Co-authored-by: LSinev <LSinev@users.noreply.github.com>
Co-authored-by: Kostas Stathoulopoulos <k.stathoylopoylos@gmail.com>
Co-authored-by: Bhadresh Savani <bhadreshpsavani@gmail.com>
Co-authored-by: Jaimeen Ahn <32367255+jaimeenahn@users.noreply.github.com>
Co-authored-by: Ashwin Geet D'Sa <win.12894@gmail.com>
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Hamel Husain <hamel.husain@gmail.com>
Co-authored-by: Michael Benayoun <mickbenayoun@gmail.com>
Co-authored-by: Michael Benayoun <michael@huggingface.co>
Co-authored-by: Frederik Bode <fredo.bode@gmail.com>
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
Co-authored-by: Manuel Romero <mrm8488@gmail.com>
Co-authored-by: CeShine Lee <ceshine@users.noreply.github.com>
Co-authored-by: Shubham Sanghavi <shubham.sanghavi@outlook.com>
Co-authored-by: bonniehyeon <50580028+bonniehyeon@users.noreply.github.com>
Co-authored-by: jingyihe <29100716+kylie-box@users.noreply.github.com>
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
Co-authored-by: Muktan <muktan123@gmail.com>
Co-authored-by: abhishek thakur <1183441+abhi1thakur@users.noreply.github.com>
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
Co-authored-by: Patrick Fernandes <pattuga@gmail.com>
Co-authored-by: Deepali <70963368+cdeepali@users.noreply.github.com>
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
Co-authored-by: Mats Sjöberg <mats.sjoberg@csc.fi>
…#10526) * Update optimization.py Fix documentation to reflect optimal settings for Adafactor * update and expand on the recommendations * style * Apply suggestions from code review Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com> * flip scale_parameter to True for the 2nd recommendatoin Co-authored-by: Stas Bekman <stas@stason.org> Co-authored-by: Stas Bekman <stas00@users.noreply.github.com> Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add more metadata to the user agent (#10972)
* Add more metadata to the user agent
* Fix typo
* Use DISABLE_TELEMETRY
* Address review comments
* Use global env
* Add clean envs on circle CI
* Enforce string-formatting with f-strings (#10980)
* First third
* Styling and fix mistake
* Quality
* All the rest
* Treat %s and %d
* typo
* Missing )
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* add notebook (#10995)
* Merge trainers (#10975)
* Replace is_sagemaker_distributed_available
* Merge SageMakerTrainer into Trainer
* Test with shorter condition
* Put back deleted line
* Deprecate SageMakerTrainer and SageMakerTrainingArguments
* Apply suggestions from code review
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
* add blog to docs (#10997)
* Update training_args.py (#11000)
In the group by length documentation length is misspelled as legnth
* Add `examples/language_modeling/run_mlm_no_trainer.py` (#11001)
* Add initial script for finetuning MLM models with accelerate
* Add evaluation metric calculation
* Fix bugs
* Use no_grad on evaluation
* update script docstring
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* PR feedback
* Fix CI failure
* Update examples/language-modeling/run_mlm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix Adafactor documentation (recommend correct settings) (#10526)
* Update optimization.py
Fix documentation to reflect optimal settings for Adafactor
* update and expand on the recommendations
* style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* flip scale_parameter to True for the 2nd recommendatoin
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Improve the speed of adding tokens from added_tokens.json (#10780)
* use bisect to add one token to unique_no_split_tokens
* fix style
* Add Vision Transformer and ViTFeatureExtractor (#10950)
* Squash all commits into one
* Update ViTFeatureExtractor to use image_utils instead of torchvision
* Remove torchvision and add Pillow
* Small docs improvement
* Address most comments by @sgugger
* Fix tests
* Clean up conversion script
* Pooler first draft
* Fix quality
* Improve conversion script
* Make style and quality
* Make fix-copies
* Minor docs improvements
* Should use fix-copies instead of manual handling
* Revert "Should use fix-copies instead of manual handling"
This reverts commit fd4e591bce4496d41406425c82606a8fdaf8a50b.
* Place ViT in alphabetical order
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* DebertaTokenizer Rework closes #10258 (#10703)
* closes #10258
* typo
* reworked deberta test
* implemented the comments from BigBird01 regarding sequence pair encoding of deberta
* Update style
* VOCAB_FILES_NAMES is now a oneliner as suggested by @sgugger
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* added #fmt: on as requested by @sgugger
* Style
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* minor typo fix
*negative* log-likelihood
* [doc] no more bucket
* added new notebook and merge of trainer (#11015)
* added new notebook and merge of trainer
* Update docs/source/sagemaker.md
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fixed typo: logging instead of logger (#11025)
* Add a script to check inits are consistent (#11024)
* s|Pretrained|PreTrained| (#11048)
* [doc] update code-block rendering (#11053)
double : prevents code-block section to be rendered, so made it single :
* Pin docutils (#11062)
* Pin docutils
* Versions table
* Remove unnecessary space (#11060)
* Some models have no tokenizers (#11064)
* Refactor AutoModel classes and add Flax Auto classes (#11027)
* Refactor AutoModel classes and add Flax Auto classes
* Add new objects to the init
* Fix hubconf and sort models
* Fix TF tests
* Missing coma
* Update src/transformers/models/auto/auto_factory.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Fix init
* Fix dummies
* Other init to fix
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Documentation about loading a fast tokenizer within Transformers (#11029)
* Documentation about loading a fast tokenizer within Transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add example for registering callbacks with trainers (#10928)
* Add example for callback registry
Resolves: #9036
* Update callback registry documentation
* Added comments for other ways to register callback
* Add `examples/language_modeling/run_clm_no_trainer.py` (#11026)
* Initial draft for clm no trainer
* Remove unwanted args
* Fix bug
* Update examples/language-modeling/run_clm_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace pkg_resources with importlib_metadata (#11061)
* Replace pkg_resources with importlib_metadata
Fixes #10964. The other reason for this change is that pkg_resources has been [deprecated](https://github.com/pypa/setuptools/commit/8fe85c22cee7fde5e6af571b30f864bad156a010) in favor of importlib_metadata.
* Reduce to a single importlib_metadata import switch
* Trigger CI
Co-authored-by: Stas Bekman <stas@stason.org>
* Add center_crop to ImageFeatureExtractoMixin (#11066)
* Document common config attributes (#11070)
* Fix distributed gather for tuples of tensors of varying sizes (#11071)
* Make a base init in FeatureExtractionMixin (#11074)
* Add Readme for language modeling scripts with accelerate (#11073)
* HF emoji unicode doesn't work in console (#11081)
It doesn't look like using 🤗 is a great idea for printing to console. See attachment.
This PR proposes to replace 🤗 with "HuggingFace" for an exception message.
@LysandreJik
* Link to new blog
* added social thumbnail for docs (#11083)
* added new merged Trainer test (#11090)
* [WIP] GPT Neo cleanup (#10985)
* better names
* add attention mixin
* all slow tests in one class
* make helper methods static so we can test
* add local attention tests
* better names
* doc
* apply review suggestions
* Release v4.5.0
* Development on v4.6.0dev0
* [doc] gpt-neo (#11098)
make the example work
* Auto feature extractor (#11097)
* AutoFeatureExtractor
* Init and first tests
* Tests
* Damn you gitignore
* Quality
* Defensive test for when not all backends are here
* Use pattern for Speech2Text models
* accelerate question answering examples with no trainer (#11091)
* accelerate question answering examples with no trainer
* removed train and eval flags also fixed fill np array function
* Update examples/question-answering/run_qa_beam_search_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update examples/question-answering/run_qa_no_trainer.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Style
* dead link fixed (#11103)
* GPTNeo: handle padded wte (#11079)
* GPTNeo: handle padded wte
* Switch to config.vocab_size
* apply review suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* fix: The 'warn' method is deprecated (#11105)
* The 'warn' method is deprecated
* fix test
* [examples] fix white space (#11099)
these get concatenated without whitespace, so fix it
* Dummies multi backend (#11100)
* Replaces requires_xxx by one generic method
* Quality and update check_dummies
* Fix inits check
* Post-merge cleanup
* Some styling of the training table in Notebooks (#11118)
* Adds a note to resize the token embedding matrix when adding special … (#11120)
* Adds a note to resize the token embedding matrix when adding special tokens
* Remove superfluous space
* fix tests (#11109)
* [versions] handle version requirement ranges (#11110)
* handle version requirement ranges
* add mixed requirement test
* cleanup
* Adds use_auth_token with pipelines (#11123)
* added model_kwargs to infer_framework_from_model
* added model_kwargs to tokenizer
* added use_auth_token as named parameter
* added dynamic get for use_auth_token
* Fix and refactor check_repo (#11127)
* Fix typing error in Trainer class (prediction_step) (#11138)
* fix: docstrings in prediction_step
* ci: Satisfy line length requirements
* ci: character length requirements
* Typo fix of the name of BertLMHeadModel in BERT doc (#11133)
* [run_clm] clarify why we get the tokenizer warning on long input (#11145)
* clarify why we get the warning here
* Update examples/language-modeling/run_clm.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wording
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] ZeRO Stage 3 (#10753)
* synced gpus
* fix
* fix
* need to use t5-small for quality tests
* notes
* complete merge
* fix a disappearing std stream problem
* start zero3 tests
* wip
* tune params
* sorting out the pre-trained model loading
* reworking generate loop wip
* wip
* style
* fix tests
* split the tests
* refactor tests
* wip
* parameterized
* fix
* workout the resume from non-ds checkpoint pass + test
* cleanup
* remove no longer needed code
* split getter/setter functions
* complete the docs
* suggestions
* gpus and their compute capabilities link
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* style
* remove invalid paramgd
* automatically configure zero3 params that rely on hidden size
* make _get_resized_embeddings zero3-aware
* add test exercising resize_token_embeddings()
* add docstring
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Add nvidia megatron models (#10911)
* Add support for NVIDIA Megatron models
* Add support for NVIDIA Megatron GPT2 and BERT
Add the megatron_gpt2 model. That model reuses the existing GPT2 model. This
commit includes a script to convert a Megatron-GPT2 checkpoint downloaded
from NVIDIA GPU Cloud. See examples/megatron-models/README.md for details.
Add the megatron_bert model. That model is implemented as a modification of
the existing BERT model in Transformers. This commit includes a script to
convert a Megatron-BERT checkpoint downloaded from NVIDIA GPU Cloud. See
examples/megatron-models/README.md for details.
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Remove model.half in tests + add "# Copied ..."
Remove the model.half() instruction which makes tests fail on the CPU.
Add a comment "# Copied ..." before many classes in the model to enable automatic
tracking in CI between the new Megatron classes and the original Bert ones.
* Fix issues
* Fix Flax/TF tests
* Fix copyright
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/configuration_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Update docs/source/model_doc/megatron_bert.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update docs/source/model_doc/megatron_gpt2.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/__init__.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/models/megatron_bert/modeling_megatron_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Resolve most of 'sgugger' comments
* Fix conversion issue + Run make fix-copies/quality/docs
* Apply suggestions from code review
* Causal LM & merge
* Fix init
* Add CausalLM to last auto class
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [trainer] solve "scheduler before optimizer step" warning (#11144)
* solve "scheduler before optimizer step" warning
* style
* correct the state evaluation test
* Add fairscale and deepspeed back to the CI (#11147)
* Add fairscale and deepspeed back to the CI
* Add deepspeed to single GPU tests
* Updates SageMaker docs for updating DLCs (#11140)
* Don't duplicate logs in TensorBoard and handle --use_env (#11141)
* Run mlm pad to multiple for fp16 (#11128)
* Add mlm collator pad to multiple option (#10627)
* Use padding to 8x in run mlm (#10627)
* [tests] relocate core integration tests (#11146)
* relocate core integration tests
* add sys.path context manager
* cleanup
* try
* try2
* fix path
* doc
* style
* add dep
* add 2 more deps
* [setup] extras[docs] must include 'all' (#11148)
* extras[doc] must include 'all'
* fix
* better
* regroup
* Add support for multiple models for one config in auto classes (#11150)
* Add support for multiple models for one config in auto classes
* Use get_values everywhere
* Prettier doc
* [setup] make fairscale and deepspeed setup extras (#11151)
* make fairscale and deepspeed setup extras
* fix default
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* no reason not to ask for the good version
* update the CIs
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Skip Megatron tests for now
* typo (#11152)
* typo
* style
* [Community notebooks] Add Wav2Vec notebook for creating captions for YT Clips (#11142)
* Add Wav2Vec Inference notebook
* Update docs/source/community.md
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Fix LogitsProcessor documentation (#11130)
* Change duplicated LogitsProcessor to LogitsWarper in LogitsProcessorList document
* Write more detailed information about LogitsProcessor's scores argument
* apply suggestion from review
* style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* Update README.md (#11161)
Corrected a typo ('Downlowd' to 'Download')
* Make `get_special_tokens_mask` consider all tokens (#11163)
* Add a special tokenizer for CPM model (#11068)
* Add a special tokenizer for CPM model
* make style
* fix
* Add docs
* styles
* cpm doc
* fix ci
* fix the overview
* add test
* make style
* typo
* Custom tokenizer flag
* Add REAMDE.md
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* [examples/translation] support mBART-50 and M2M100 fine-tuning (#11170)
* keep a list of multilingual tokenizers
* add forced_bos_token argument
* [examples run_clm] fix _LazyModule hasher error (#11168)
* fix _LazyModule hasher error
* reword
* added json dump and extraction of train run time (#11167)
* added json dump and extraction of train run time
* make style happy
* Fix Typo
* Reactivate Megatron tests an use less workers
* Minor typos fixed (#11182)
* Fix style
* model_path should be ignored as the checkpoint path (#11157)
* model_path is refered as the path of the trainer, and should be ignored as the checkpoint path.
* Improved according to Sgugger's comment.
* Added documentation for data collator. (#10941)
* Added documentation for data collator.
* Update docs/source/data_collator.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Added documentation for data collator.
* Added documentation for the data collator.
* Merge branch 'doc_DataCollator' of C:\Users\mahii\PycharmProjects\transformers with conflicts.
* Update documentation for the data collator.
* Update documentation for the data collator.
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
* Fix typo (#11188)
* Add DeiT (PyTorch) (#11056)
* First draft of deit
* More improvements
* Remove DeiTTokenizerFast from init
* Conversion script works
* Add DeiT to ViT conversion script
* Add tests, add head model, add support for deit in vit conversion script
* Update model checkpoint names
* Update image_mean and image_std, set resample to bicubic
* Improve docs
* Docs improvements
* Add DeiTForImageClassificationWithTeacher to init
* Address comments by @sgugger
* Improve feature extractors
* Make fix-copies
* Minor fixes
* Address comments by @patil-suraj
* All models uploaded
* Fix tests
* Remove labels argument from DeiTForImageClassificationWithTeacher
* Fix-copies, style and quality
* Fix tests
* Fix typo
* Multiple docs improvements
* More docs fixes
* Replaced `which` with `who` (#11183)
* Import torch.utils.checkpoint in ProphetNet (#11214)
* Sagemaker test docs update for framework upgrade (#11206)
* increased train_runtime for model parallelism
* added documentation for framework upgrade
* Use MSELoss in (M)BartForSequenceClassification (#11178)
* wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model (#11041)
* add vocab while converting wav2vec2 original finetuned model
* check save directory exists
* return_attention_mask fix
* quality
* Add Matt as the TensorFlow reference (#11212)
* Fix GPT-2 warnings (#11213)
* Fix GPT-2 warnings
* Update src/transformers/models/gpt2/modeling_gpt2.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* fix docstrings (#11221)
* Add documentation for BertJapanese (#11219)
* Start writing BERT-Japanese doc
* Fix typo, Update toctree
* Modify model file to use comment for document, Add examples
* Clean bert_japanese by make style
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Split a big code block into two
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Add prefix >>> to all lines in code blocks
* Clean bert_japanese by make fixup
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Replace error by warning when loading an architecture in another (#11207)
* Replace error by warning when loading an architecture in another
* Style
* Style again
* Add a test
* Adapt old test
* Document v4.5.1
* Refactor GPT2 (#11225)
* refactor GPT2
* fix mlp and head pruning
* address Sylvains comments
* apply suggestion from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Doc check: a bit of clean up (#11224)
* added cache_dir=model_args.cache_dir to all example with cache_dir arg (#11220)
* Avoid using no_sync on SageMaker DP (#11229)
* Indent code block in the documentation (#11233)
* Indent code block
* Indent code blocks version 2
* Quality
* Run CI on deepspeed and fairscale (#11172)
* Run CI on deepspeed and fairscale
* Test it on this branch :)
* Rename
* Update the CI image
* [Deepspeed] zero3 tests band aid (#11235)
* temp band-aid
* style
* Save the Wav2Vec2 processor before training starts (#10910)
Co-authored-by: nithin19 <nithin@amberscript.com>
* make embeddings plural in warning message (#11228)
* Stale bot updated (#10562)
* Updated stale bot
* Specify issue number
* Remove particular handling of assignees
* Unleash the stalebot
* Remove debug branch
* Close open files to suppress ResourceWarning (#11240)
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
* Fix dimention misspellings. (#11238)
* Update modeling_gpt_neo.py
dimention -> dimension
* Update configuration_speech_to_text.py
dimention -> dimension
* Add prefix to examples in model_doc rst (#11226)
* Add prefix to examples in model_doc rst
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [troubleshooting] add 2 points of reference to the offline mode (#11236)
* add 2 points of reference to the offline mode
* link the new doc
* add error message
* Update src/transformers/modeling_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* style
* rename
* Trigger CI
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix #10128 (#11248)
* [deepspeed] test on one node 2 gpus max (#11237)
* test on one node 2 gpus max
* fix the other place
* refactor
* fix
* cleanup
* more exact version
* Trainer iterable dataset (#11254)
* IterableDatasetShard
* Test and integration in Trainer
* Update src/transformers/trainer_pt_utils.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Style
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding pipeline task aliases. (#11247)
* Adding task aliases and adding `token-classification` and
`text-classification` tasks.
* Cleaning docstring.
* Support for set_epoch (#11258)
* Tokenizer fast save (#11234)
* Save fast tokenizers in both formats
* Fix for HerBERT
* Proper fix
* Properly test new behavior
* update dependency_versions_table (#11273)
missed this updating when bumped the version.
* Workflow fixes (#11270)
* Enabling multilingual models for translation pipelines. (#10536)
* [WIP] Enabling multilingual models for translation pipelines.
* decoder_input_ids -> forced_bos_token_id
* Improve docstring.
* Rebase
* Fixing 2 bugs
- Type token_ids coming from `_parse_and_tokenize`
- Wrong index from tgt_lang.
* Fixing black version.
* Adding tests for _build_translation_inputs and add them for all
tokenizers.
* Mbart actually puts the lang code at the end.
* Fixing m2m100.
* Adding TF support to `deep_round`.
* Update src/transformers/pipelines/text2text_generation.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Adding one line comment.
* Fixing M2M100 `_build_translation_input_ids`, and fix the call site.
* Fixing tests + deep_round -> nested_simplify
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix failing workflows
* Trainer support for IterableDataset for evaluation and predict (#11286)
* Bulk of the work
* Polish and tests
* Update QA Trainer
* Avoid breaking the predict method
* Deprecation warnings
* Store real eval dataloder
* Get eval dataset reference before wrap
* move device statements outside if statements (#11292)
* modify double considering special tokens in `language_modeling.py` (#11275)
* Update language_modeling.py
in "class TextDatasetForNextSentencePrediction(Dataset)", double considering "self.tokenizer.num_special_tokens_to_add(pair=True)"
so, i remove self.block_size, and add parameter for "def create_examples_from_document". like "class LineByLineWithSOPTextDataset" do
* Update language_modeling.py
* [Trainer] fix the placement on device with fp16_full_eval (#11322)
* fix the placement on device with fp16_full_eval
* deepspeed never goes on device
* [Trainer] Add a progress bar for batches skipped (#11324)
* Load checkpoint without re-creating the model (#11318)
* Added translation example script (#11196)
* initial changes
* modified evaluation
* updated evaluation
* updated evaluation on text translation example script
* added translation example script
* Formatted translation example script
* Reformatted translation example
* Fixed evaluation bug and added support for other tokenisers
* Fixed evaluation bug and added support for other tokenisers
* Added translation example script
* Formatted summarization example script
* Removed typos from summarization example script
* [Generate] Remove outdated code (#11331)
* remove update function
* update
* refactor more
* refactor
* [GPTNeo] create local attention mask ones (#11335)
* create local attention mask ones
* remove old method, address patricks comment
* Update to use datasets remove_cloumns method (#11343)
* Update to use datasets remove_cloumns method
* Quality
* Add an error message that fires when Reformer is not in training mode, but one runs .backward() (#11117)
* Removed `max_length` from being mandatory within `generate`. (#11314)
* Removed `max_length` from being mandatory within `generate`.
- Moving on to fully using `StoppingCriteria` for `greedy` and `sample`
modes.
- `max_length` still used for `beam_search` and `group_beam_search`
(Follow up PR)
- Fixes a bug with MaxLengthStoppingCriteria (we should stop as soon a
we hit the max_length, the comparison needs to be or equal, that affects
the tests).
- Added options to use `logits_processor` and `stopping_criteria`
directly within `generate` function (so some users can define their own
`logits_processor` and `stopping_criteria`).
- Modified the backward compat tests to make sure we issue a warning.
* Fix `max_length` argument in `generate`.
* Moving validate to being functional.
- Renamed `smax_length` to `stoppping_max_length`.
* Removing `logits_processor` and `stopping_criteria` from `generate`
arguments.
* Deepcopy.
* Fix global variable name.
* Honor contributors to models (#11329)
* Honor contributors to models
* Fix typo
* Address review comments
* Add more authors
* [deepspeed] fix resume from checkpoint (#11352)
This PR fixes a bug that most likely somehow got exposed (not caused) by https://github.com/huggingface/transformers/pull/11318 - surprisingly the same test worked just fine before that other PR.
* Examples reorg (#11350)
* Base move
* Examples reorganization
* Update references
* Put back test data
* Move conftest
* More fixes
* Move test data to test fixtures
* Update path
* Apply suggestions from code review
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Address review comments and clean
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Extract metric_key_prefix during NotebookProgressCallback.on_evaluate (#11347)
* Pass metric_key_prefix as kwarg to on_evaluate
* Replace eval_loss with metric_key_prefix_loss
* Default to "eval" if metric_key_prefix not in kwargs
* Add kwargs to CallbackHandler.on_evaluate signature
* Revert "Add kwargs to CallbackHandler.on_evaluate signature"
This reverts commit 8d4c85ed512f558f7579d36771e907b3379947b7.
* Revert "Pass metric_key_prefix as kwarg to on_evaluate"
This reverts commit 7766bfe2718601230ae593d37b1317bd53cfc075.
* Extract metric_key_prefix from metrics
* [testing doc] bring doc up to date (#11359)
* bring doc up to date
* fix
* Merge new TF example script (#11360)
First of the new and more idiomatic TF examples!
* Remove boiler plate code (#11340)
* remove boiler plate code
* adapt roberta
* correct docs
* finish refactor
* Move old TF text classification script to legacy (#11361)
And update README to explain the work-in-progress!
* [contributing doc] explain/link to good first issue (#11346)
* explain/link to good first issue
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Fix token_type_ids error for big_bird model. (#11355)
* MOD: fit chinese wwm to new datasets
* MOD: move wwm to new folder
* MOD: formate code
* Styling
* MOD add param and recover trainer
* MOD: add token_type_ids method for big bird
* MOD: format code
* MOD: format code
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
* Add huggingface_hub dep for #11328
* Add in torchhub
* [Wav2Vec2] Fix special tokens for Wav2Vec2 tokenizer (#11349)
* fix wav2vec2 tok
* up
* [Flax] Correct typo (#11374)
* finish
* fix copy
* [run_translation.py] fix typo (#11372)
fix typo
Co-authored-by: johnson <johnson@github.com>
* Add space (#11373)
* Correctly cast num_train_epochs to int (#11379)
* Fix typo (#11369)
* Fix Trainer with remove_unused_columns=False (#11382)
* Fix Trainer with remove_unused_columns=False
* Typo
* [Flax] Big FlaxBert Refactor (#11364)
* improve flax
* refactor
* typos
* Update src/transformers/modeling_flax_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_flax_utils.py
* fix typo
* improve error tolerance
* typo
* correct nasty saving bug
* fix from pretrained
* correct tree map
* add note
* correct weight tying
* correct typo (#11393)
* correct conversion (#11394)
* Fix typo in text (#11396)
* fixed typos (#11391)
* make blenderbot test slow (#11395)
* Fixed trainer total_flos relaoding in distributed mode (#11383)
* Fixed trainer total_flos relaoding in distributed mode
* logging flos at the end of training
* Trainer push to hub (#11328)
* Initial support for upload to hub
* push -> upload
* Fixes + examples
* Fix torchhub test
* Torchhub test I hate you
* push_model_to_hub -> push_to_hub
* Apply mixin to other pretrained models
* Remove ABC inheritance
* Add tests
* Typo
* Run tests
* Install git-lfs
* Change approach
* Add push_to_hub to all
* Staging test suite
* Typo
* Maybe like this?
* More deps
* Cache
* Adapt name
* Quality
* MOAR tests
* Put it in testing_utils
* Docs + torchhub last hope
* Styling
* Wrong method
* Typos
* Update src/transformers/file_utils.py
Co-authored-by: Julien Chaumond <julien@huggingface.co>
* Address review comments
* Apply suggestions from code review
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* push (#11400)
* added support for exporting of t5 to onnx with past_key_values (#10651)
* Fixing bug in generation (#11297)
When passing `inputs_embeds` and not `input_ids=None` the generation function fails because `input_ids` is created but the function but it should not.
* Style
* Try to trigger failure more
* Wrong branch Sylvain...
* Fix cross-attention head mask for Torch encoder-decoder models (#10605)
* Fix cross-attention head mask for Torch BART models
* Fix head masking for cross-attention module for the following
models: BART, Blenderbot, Blenderbot_small, M2M_100, Marian, MBart,
Pegasus
* Enable test_headmasking for M2M_100 model
* Fix cross_head_mask for FSMT, LED and T5
* This commit fixes `head_mask` for cross-attention modules
in the following models: FSMT, LED, T5
* It also contains some smaller changes in doc so that
it is be perfectly clear the shape of `cross_head_mask`
is the same as of `decoder_head_mask`
* Update template
* Fix template for BartForCausalLM
* Fix cross_head_mask for Speech2Text models
* Fix cross_head_mask in templates
* Fix args order in BartForCausalLM template
* Fix doc in BART templates
* Make more explicit naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Fix doc
* make style quality
* Fix speech2text docstring
* Default to accuracy metric (#11405)
* Enable option for subword regularization in `XLMRobertaTokenizer` (#11149)
* enable subword regularization.
* fix tokenizer storage
* fix docstring formatting
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Stefan Schweter <stefan@schweter.it>
* fix docstring formatting
* add test for subword regularization tokenizer
* improve comments of test
* add sp_model_kwargs
* reformat docstring to match the style
* add some more documentation
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* improve docstring
* empty commit to trigger CI
* Update src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docstring formatting for sphinx
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Use 3 workers for torch tests
* documentation linked to the parent class PreTrainedTokenizerFast but it should be the slow tokenizer (#11410)
* Style
* Add head_mask, decoder_head_mask, cross_head_mask to ProphetNet (#9964)
* Add head_mask & decoder_head_mask + some corrections
* Fix head masking for N-grams
* Enable test_headmasking for encoder and decod
* Fix one typo regarding in modeling_propgetnet.py
* Enable test_headmasking for ProphetNetStandaloneDecoderModelTest
and ProphetNetStandaloneEncoderModelTest in test_modeling_prophetnet.py
* make style
* Fix cross_head_mask
* Fix attention head mask naming
* `cross_head_mask` -> `cross_attn_head_mask`
* `cross_layer_head_mask` -> `cross_attn_layer_head_mask`
* Still need to merge #10605 to master to pass the tests
* EncoderDecoderConfigs should not create new objects (#11300)
* removes the creation of separate config objects and uses the existing ones instead+overwrite resize_token_embeddings from parent class because it is not working for the EncoderDecoderModel
* rollback to current version of the huggingface master branch
* reworked version that ties the encoder and decoder config of the parent encoderdecoder instance
* overwrite of resize_token_embeddings throws an error now
* review comment suggestion
Co-authored-by: Suraj Patil <surajp815@gmail.com>
* implemented warning in case encoderdecoder is created with differing configs of encoderdecoderconfig and decoderconfig or encoderconfig
* added test to avoid diverging configs of wrapper class and wrapped classes
* Update src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
* make style
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* updating the checkpoint for GPT2ForSequence Classification to one with classification head (#11434)
* add pooling layer support (#11439)
* make style (#11442)
* Pin black to 20.8.b1
* With style
* Pin black to 21.4b0
* TF BART models - Add `cross_attentions` to model output and fix cross-attention head masking (#10699)
* Add cross_attn_head_mask to BART
* Fix cross_attentions in TFBart-like models
* This commit enables returning of `cross_attentions`
for TFBart-like models
* It also fixes attention head masking in cross-attenion module
* Update TF model templates
* Fix missing , in TF model templates
* Fix typo: congig -> config
* Add basic support for FP16 in SageMaker model parallelism (#11407)
* Add FP16 support for SageMaker MP
* Add print debugs
* Squeeze
* Remove debug statements
* Add defensive check
* Typo
* docs(examples): fix link to TPU launcher script (#11427)
* fix some typos in docs, comments, logging/errors (#11432)
* Pass along seed to DistributedSampler (#11406)
* Pass along seed to DistributedSampler
* Add seed to DistributedLengthGroupedSampler
* Clarify description of the is_split_into_words argument (#11449)
* Improve documentation for is_split_into_words argument
* Change description wording
* [docs] fix invalid class name (#11438)
* fix invalid class name
* proper ref
* proper ref
* make sure to test against the local checkout (#11437)
* Style
* Give each test a different repo name (#11453)
* [Examples] Fixes inconsistency around eval vs val and predict vs test (#11380)
* added changes for uniformity
* modified files
* corrected typo
* fixed qa scripts
* fix typos
* fixed predict typo in qa no trainer
* fixed test file
* reverted trainer changes
* reverted trainer changes in custom exmaples
* updated readme
* added changes in deepspeed test
* added changes for predict and eval
* Variable Correction for Consistency in Distillation Example (#11444)
As the error comes from the inconsistency of variable meaning number of gpus in parser and its actual usage in the train.py script, 'gpus' and 'n_gpu' respectively, the correction makes the example work
* [Deepspeed] ZeRO-Infinity integration plus config revamp (#11418)
* adding Z-inf
* revamp config process
* up version requirement
* wip
* massive rewrite
* cleanup
* cleanup
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* consistent json commas
* act on suggestions
* leave this feature for 0.3.16
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Remove max length beam scorer (#11378)
* removed max_len
* removed max_length from BeamSearchScorer
* correct max length
* finish
* del vim
* finish & add test
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* update QuickTour docs to reflect model output object (#11462)
* update docs to reflect model output object
* run make style`
* Finish Making Quick Tour respect the model object (#11467)
* finish quicktour
* fix import
* fix print
* explain config default better
* Update docs/source/quicktour.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix docs for decoder_input_ids (#11466)
* fix docs for decoder_input_ids
* revert the changes for bart and mbart
* Update min versions in README and add Flax (#11472)
* Update min versions in README and add Flax
* Adapt index
* Update `PreTrainedTokenizerBase` to check/handle batch length for `text_pair` parameter (#11486)
* Update tokenization_utils_base.py
* add assertion
* check batch len
* Update src/transformers/tokenization_utils_base.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* add error message
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix #1149 (#11493)
* [Flax] Add docstrings & model outputs (#11498)
* add attentions & hidden states
* add model outputs + docs
* finish docs
* finish tests
* finish impl
* del @
* finish
* finish
* correct test
* apply sylvains suggestions
* Update src/transformers/models/bert/modeling_flax_bert.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* simplify more
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Reformat to make code clearer in tokenizer call (#11497)
* Reformat to make code clearer
* Reformat to make code clearer
* solved coefficient issue for the TF version of gelu_fast (#11514)
Co-authored-by: Michael Benayoun <michael@huggingface.co>
* Split checkpoint from model_name_or_path in examples (#11492)
* Split checkpoint from model_name_or_path in examples
* Address review comments
* Address review comments
* Patch notification service
* Pin HuggingFace Hub dependency (#11502)
* correct the dimension comment of matrix multiplication (#11494)
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
* add sp_model_kwargs to unpickle of xlm roberta tok (#11430)
add test for pickle
simplify test
fix test code style
add missing pickle import
fix test
fix test
fix test
* make style (#11520)
* Update README.md (#11489)
Add link to code
* T5 Gradient Checkpointing (#11353)
* Implement gradient checkpoinging for T5Stack
* A bit more robust type checking
* Add `gradient_checkpointing` to T5Config
* Formatting
* Set requires_grad only when training
* None return value will only cause problems when training
* Change the output tuple according to `use_cache`
* Enable gradient checkpointing for the decoder
Squashed commit of the following:
commit 658bdd0bd1215353a8770f558bda2ea69a0ad0c7
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 14:08:17 2021 +0800
Only set `require_grad` for gradient checkpointing
commit acaeee6b2e675045fb28ce2176444c1d63e908bd
Author: Ceshine Lee <shuanck@gmail.com>
Date: Sat Apr 24 13:59:35 2021 +0800
Make gradient checkpointing work with the decoder
* Formatting
* Adding `AutomaticSpeechRecognitionPipeline`. (#11337)
* Adding `AutomaticSpeechRecognitionPipeline`.
- Because we added everything to enable this pipeline, we probably
should add it to `transformers`.
- This PR tries to limit the scope and focuses only on the pipeline part
(what should go in, and out).
- The tests are very specific for S2T and Wav2vec2 to make sure both
architectures are supported by the pipeline. We don't use the mixin for
tests right now, because that requires more work in the `pipeline`
function (will be done in a follow up PR).
- Unsure about the "helper" function `ffmpeg_read`. It makes a lot of
sense from a user perspective, it does not add any additional
dependencies (as in hard dependency, because users can always use their
own load mechanism). Meanwhile, it feels slightly clunky to have so much
optional preprocessing.
- The pipeline is not done to support streaming audio right now.
Future work:
- Add `automatic-speech-recognition` as a `task`. And add the
FeatureExtractor.from_pretrained within `pipeline` function.
- Add small models within tests
- Add the Mixin to tests.
- Make the logic between ForCTC vs ForConditionalGeneration better.
* Update tests/test_pipelines_automatic_speech_recognition.py
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* Adding docs + main import + type checking + LICENSE.
* Doc style !.
* Fixing TYPE_HINT.
* Specifying waveform shape in the docs.
* Adding asserts + specify in the documentation the shape of the input
np.ndarray.
* Update src/transformers/pipelines/automatic_speech_recognition.py
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Adding require to tests + move the `feature_extractor` doc.
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Implement Fast Tokenization for Deberta (#11387)
* Accepts BatchEncoding in LengthSampler (#11431)
* Fix do_eval default value in training_args.py (#11511)
* Fix do_eval default value in training_args.py
* Update PULL_REQUEST_TEMPLATE.md
* Update TF text classification example (#11496)
Big refactor, fixes and multi-GPU/TPU support
* reszie token embeds (#11524)
* Run model templates on master (#11527)
* [Examples] Added support for test-file in QA examples with no trainer (#11510)
* added support for test-file
* fixed typo
* added suggested changes
* reformatted code
* modifed files
* fix post processing error
* Trigger CI
* removed extra lines
* Add Stas and Suraj as authors (#11526)
* Improve task summary docs (#11513)
* fix task summary docs
* refactor to use model.config.id2label instead of list
* fix nit
* Update docs/source/task_summary.rst
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [debug utils] activation/weights underflow/overflow detector (#11274)
* sync
* add activation overflow debug utility
* cleanup
* document detect_overflow
* import torch
* add deprecation warning
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* convert to rst, add note
* add class
* fix docs
* improve the doc
* rework to dump a lot more info about each frame
* complete expansion
* cleanup
* format
* cleanup
* doesn't have to be transformers
* Apply suggestions from code review
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* wrap long line
* style
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* [DeepSpeed] fp32 support (#11499)
* prep for deepspeed==0.3.16
* new version
* too soon
* support and test fp32 mode
* troubleshooting doc start
* workaround no longer needed
* add fp32 doc
* style
* cleanup, add tf32 note
* clarify
* release was made
* Fixed docs for the shape of `scores` in `generate()` (#10057)
* Fixed the doc for the shape of return scores tuples in generation_utils.py.
* Fix the output shape of `scores` for `DecoderOnlyOutput`.
* style fix
* Fix examples in M2M100 docstrings (#11540)
Replaces `tok` with `tokenizer` so examples can run with copy-paste
* [Flax BERT/Roberta] few small fixes (#11558)
* small fixes
* style
* [Wav2Vec2] Fix convert (#11562)
* push
* small change
* correct other typo
* Remove `datasets` submodule. (#11563)
* fix the mlm longformer example by changing [MASK] to <mask> (#11559)
* Add LUKE (#11223)
* Rebase with master
* Minor bug fix in docs
* Copy files from adding_luke_v2 and improve docs
* change the default value of use_entity_aware_attention to True
* remove word_hidden_states
* fix head models
* fix tests
* fix the conversion script
* add integration tests for the pretrained large model
* improve docstring
* Improve docs, make style
* fix _init_weights for pytorch 1.8
* improve docs
* fix tokenizer to construct entity sequence with [MASK] entity when entities=None
* Make fix-copies
* Make style & quality
* Bug fixes
* Add LukeTokenizer to init
* Address most comments by @patil-suraj and @LysandreJik
* rename _compute_extended_attention_mask to get_extended_attention_mask
* add comments to LukeSelfAttention
* fix the documentation of the tokenizer
* address comments by @patil-suraj, @LysandreJik, and @sgugger
* improve docs
* Make style, quality and fix-copies
* Improve docs
* fix docs
* add "entity_span_classification" task
* update example code for LukeForEntitySpanClassification
* improve docs
* improve docs
* improve the code example in luke.rst
* rename the classification layer in LukeForEntityClassification from typing to classifier
* add bias to the classifier in LukeForEntitySpanClassification
* update docs to use fine-tuned hub models in code examples of the head models
* update the example sentences
* Make style & quality
* Add require_torch to tokenizer tests
* Add require_torch to tokenizer tests
* Address comments by @sgugger and add community notebooks
* Make fix-copies
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
* [Wav2vec2] Fixed tokenization mistakes while adding single-char tokens to tokenizer (#11538)
* Fixed tokenization mistakes while adding single-char tokens to tokenizer
* Added tests and Removed unnecessary comments.
* finalize wav2vec2 tok
* add more aggressive tests
* Apply suggestions from code review
* fix useless import
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Fix metric computation in `run_glue_no_trainer` (#11569)
* Fixes a useless warning. (#11566)
Fixes #11525
* Accumulate opt state dict on do_rank 0 (#11481)
* Update training tutorial (#11533)
* Update training tutorial
* Apply suggestions from code review
Co-authored-by: Hamel Husain <hamelsmu@github.com>
* Address review comments
* Update docs/source/training.rst
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* More review comments
* Last review comments
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
* fix resize_token_embeddings (#11572)
* Add multi-class, multi-label and regression to transformers (#11012)
* add to bert
* review comments
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* self.config.problem_type
* fix style
* fix
* fin
* fix
* update doc
* fix
* test
* Test more problem types
* Update src/transformers/configuration_utils.py
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
* fix
* remove
* fix
* quality
* make fix-copies
* remove test
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
* Enable added tokens (#11325)
* Fix tests
* Reorganize
* Update tests/test_modeling_mobilebert.py
* Remove unnecessary addition
* Make quality scripts work when one backend is missing. (#11573)
* Make quality scripts work when one backend is missing.
* Check env variable is properly set
* Add default
* With print statements
* Fix typo
* Set env variable
* Remove debug code
* [FlaxRoberta] Add FlaxRobertaModels & adapt run_mlm_flax.py (#11470)
* add flax roberta
* make style
* correct initialiazation
* modify model to save weights
* fix copied from
* fix copied from
* correct some more code
* add more roberta models
* Apply suggestions from code review
* merge from master
* finish
* finish docs
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
* Removes SageMakerTrainer code but keeps class as wrapper (#11587)
* removed all old code
* make quality
* [Flax] Add Electra models (#11426)
* add electra model to flax
* Remove Electra Next Sentence Prediction model added by mistake
* fix parameter sharing and loosen equality threshold
* fix styling issues
* add mistaken removen imports
* fix electra table
* Add FlaxElectra to automodels and fixe docs
* fix issues pointed out the PR
* fix flax electra to comply with latest changes
* remove stale class
* add copied from
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
* Reproducible checkpoint (#11582)
* Set generator in dataloader
* Use generator in all random samplers
* Checkpoint all RNG states
* Final version
* Quality
* Test
* Address review comments
* Quality
* Remove debug util
* Add python and numpy RNGs
* Split states in different files in distributed
* Quality
* local_rank for TPUs
* Only use generator when accepted
* Add test
* Set seed to avoid flakiness
* Make test less flaky
* Quality
* [trainer] document resume randomness (#11588)
* document resume randomness
* fix link
* reword
* fix
* reword
* style
* copies need to be fixed too (#11585)
* add importlib_metadata and huggingface_hub as dependency in the conda recipe (#11591)
* add importlib_metadata as dependency (#11490)
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* add huggingface_hub dependency
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
* Skip Funnel test
* Pytorch - Lazy initialization of models (#11471)
* lazy_init_weights
* remove ipdb
* save int
* add necessary code
* remove unnecessary utils
* Update src/transformers/models/t5/modeling_t5.py
* clean
* add tests
* correct
* finish tests
* finish tests
* fix some more tests
* fix xlnet & transfo-xl
* fix more tests
* make sure tests are independent
* fix tests more
* finist tests
* final touches
* Update src/transformers/modeling_utils.py
* Apply suggestions from code review
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Update src/transformers/modeling_utils.py
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* clean tests
* give arg positive name
* add more mock weights to xlnet
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
* Accept tensorflow-rocm package when checking TF availability (#11595)
Co-authored-by: Sylvain Gugger <35901082+sgugger@users.noreply.github.com>
Co-authored-by: Lysandre Debut <lysandre@huggingface.co>
Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com>
Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
Co-authored-by: JohnnyC08 <jcastaldo08@gmail.com>
Co-authored-by: Hemil Desai <hemil.desai10@gmail.com>
Co-authored-by: Josh <1113285+jsrozner@users.noreply.github.com>
Co-authored-by: Stas Bekman <stas@stason.org>
Co-authored-by: Stas Bekman <stas00@users.noreply.github.com>
Co-authored-by: cchen-dialpad <47165889+cchen-dialpad@users.noreply.github.com>
Co-authored-by: NielsRogge <48327001+NielsRogge@users.noreply.github.com>
Co-authored-by: Lysandre <lysandre.debut@reseau.eseo.fr>
Co-authored-by: cronoik <johannes.schaffrath@mail.de>
Co-authored-by: Joe Davison <josephddavison@gmail.com>
Co-authored-by: Julien Chaumond <julien@huggingface.co>
Co-authored-by: versis <versis791@gmail.com>
Co-authored-by: Eren Şahin <sahineren.09@gmail.com>
Co-authored-by: Amala Deshmukh <amala.d166@gmail.com>
Co-authored-by: konstin <konstin@mailbox.org>
Co-authored-by: Sylvain Gugger <sylvain.gugger@gmail.com>
Co-authored-by: Suraj Patil <surajp815@gmail.com>
Co-authored-by: SHYAM SUNDER KUMAR <beingprofess@gmail.com>
Co-authored-by: Leo Gao <54557097+leogao2@users.noreply.github.com>
Co-authored-by: Vasudev Gupta <7vasudevgupta@gmail.com>
Co-authored-by: Jannis Born <jannis.born@gmx.de>
Co-authored-by: Yusuke Mori <mori@mi.t.u-tokyo.ac.jp>
Co-authored-by: Julien Demouth <julien.demouth@gmail.com>
Co-authored-by: Julien Demouth <jdemouth@nvidia.com>
Co-authored-by: Andrea Cappelli <ak314@users.noreply.github.com>
Co-authored-by: Niklas Muennighoff <62820084+Muennighoff@users.noreply.github.com>
Co-authored-by: Keisuke Hirota <tahiro.k.ad@gmail.com>
Co-authored-by: Saviour Owolabi <42647840+Seyviour@users.noreply.github.com>
Co-authored-by: Kevin Canwen Xu <canwenxu@126.com>
Co-authored-by: Masatoshi TSUCHIYA <tsuchm@users.noreply.github.com>
Co-authored-by: fghuman <f.z.ghuman@student.tudelft.nl>
Co-authored-by: Amna <A.A.Ahmad@student.tudelft.nl>
Co-authored-by: Takuya Makino <takuyamakino15@gmail.com>
Co-authored-by: calpt <calpt@mail.de>
Co-authored-by: Ceyda Cinarel <15624271+cceyda@users.noreply.github.com>
Co-authored-by: Nithin Holla <nithin.holla7@gmail.com>
Co-authored-by: nithin19 <nithin@amberscript.com>
Co-authored-by: Joel Stremmel <joelstremmel22@gmail.com>
Co-authored-by: Sudharsan S T <stsudharshan@gmail.com>
Co-authored-by: Sudharsan Thirumalai <sudharsan.t@sprinklr.com>
Co-authored-by: Thomas Wood <odell.wood@gmail.com>
Co-authored-by: Nicolas Patry <patry.nicolas@protonmail.com>
Co-authored-by: e <e_yi@foxmail.com>
Co-authored-by: TAE YOUNGDON <49802647+taepd@users.noreply.github.com>
Co-authored-by: rajvi-k <rajvi.kapadia01@gmail.com>
Co-authored-by: lewtun <lewis.c.tunstall@gmail.com>
Co-authored-by: Matt <Rocketknight1@users.noreply.github.com>
Co-authored-by: wlhgtc <hgtcwl@foxmail.com>
Co-authored-by: johnson7788 <linghuchongxajh@gmail.com>
Co-authored-by: johnson <johnson@github.com>
Co-authored-by: PenutChen <penut85420@gmail.com>
Co-authored-by: Max Del <max.del.edu@gmail.com>
Co-authored-by: Yoshitomo Matsubara <yoshitomo-matsubara@users.noreply.github.com>
Co-authored-by: Teven <teven.lescao@gmail.com>
Co-authored-by: Kiran R <kiranr8k@gmail.com>
Co-authored-by: Nicola De Cao <nicola.decao@gmail.com>
Co-authored-by: Daniel Stancl <46073029+stancld@users.noreply.github.com>
Co-authored-by: Philip May <philip@may.la>
Co-authored-by: Stefan Schweter <stefan@schweter.it>
Co-authored-by: abiolaTresor <48957493+abiolaTresor@users.noreply.github.com>
Co-authored-by: Amine Abdaoui <abdaoui@lirmm.fr>
Co-authored-by: LSinev <LSinev@users.noreply.github.com>
Co-authored-by: Kostas Stathoulopoulos <k.stathoylopoylos@gmail.com>
Co-authored-by: Bhadresh Savani <bhadreshpsavani@gmail.com>
Co-authored-by: Jaimeen Ahn <32367255+jaimeenahn@users.noreply.github.com>
Co-authored-by: Ashwin Geet D'Sa <win.12894@gmail.com>
Co-authored-by: Hamel Husain <hamelsmu@github.com>
Co-authored-by: Hamel Husain <hamel.husain@gmail.com>
Co-authored-by: Michael Benayoun <mickbenayoun@gmail.com>
Co-authored-by: Michael Benayoun <michael@huggingface.co>
Co-authored-by: Frederik Bode <fredo.bode@gmail.com>
Co-authored-by: Frederik Bode <frederik@paperbox.ai>
Co-authored-by: Manuel Romero <mrm8488@gmail.com>
Co-authored-by: CeShine Lee <ceshine@users.noreply.github.com>
Co-authored-by: Shubham Sanghavi <shubham.sanghavi@outlook.com>
Co-authored-by: bonniehyeon <50580028+bonniehyeon@users.noreply.github.com>
Co-authored-by: jingyihe <29100716+kylie-box@users.noreply.github.com>
Co-authored-by: Ikuya Yamada <ikuya@ikuya.net>
Co-authored-by: Muktan <muktan123@gmail.com>
Co-authored-by: abhishek thakur <1183441+abhi1thakur@users.noreply.github.com>
Co-authored-by: abhishek thakur <abhishekkrthakur@users.noreply.github.com>
Co-authored-by: Patrick von Platen <patrick@huggingface.co>
Co-authored-by: Patrick Fernandes <pattuga@gmail.com>
Co-authored-by: Deepali <70963368+cdeepali@users.noreply.github.com>
Co-authored-by: Deepali Chourasia <deepch23@us.ibm.com>
Co-authored-by: Mats Sjöberg <mats.sjoberg@csc.fi>
This PR fixes documentation to reflect optimal settings for Adafactor:
clip_tresholdis discussedscale_parameter=FalseFixes #7789
@sgugger
(edited by @stas00 to reflect it's pre-merge state as the PR evolved since it's original submission)