Releases: huggingface/trl
v0.4.1
Large models training, Naive Pipeline Parallelism, peft Data Parallelism support and distributed training bug fixes
This release includes a set of features and bug fixes to scale up your RLHF experiments for much larger models leveraging peft and bitsandbytes.
Naive Pipeline Parallelism support
- Let's support naive Pipeline Parallelism by @younesbelkada in #210
We introduce a new paradigm in trl , termed as Naive Pipeline Parallelism, to fit large scale models on your training setup and apply RLHF on them. This feature uses peft to train adapters and bitsandbytes to reduce the memory foot print of your active model
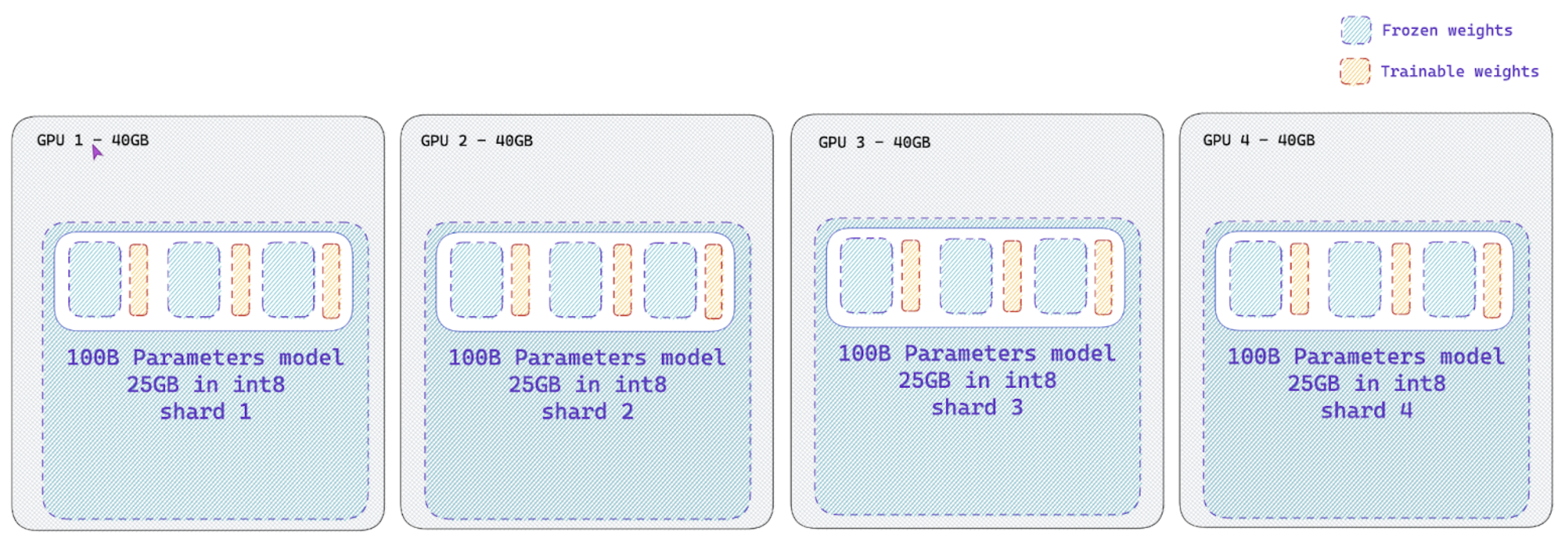
peft Data Parallelism support
- [
peft] Fix DP issues by @younesbelkada in #221 - [
core] fix DP issue by @younesbelkada in #222
There were some bugs with respect to peft integration and DP. This release includes the bug fixes to enable multi-GPU training using accelerate + DDP (DIstributed Data Parallel)
Memory optimization
Your training runs can be now much more memory efficient thanks to few tricks / bug fixes:
Now PPOConfig also supports the flag optimize_cuda_cache (set to False by default) to avoid increasing CUDA memory issues
- Grad accumulation and memory bugfix by @edbeeching in #220
- adds a missing detach to the ratio by @edbeeching in #224
Pytorch 2.0 fixes
This release also includes minor fixes related to PyTorch 2.0 release
- [
test] attempt to fix CI test for PT 2.0 by @younesbelkada in #225
What's Changed
- adds sentiment example for a 20b model by @edbeeching in #208
- Update README.md blog post link by @TeamDman in #212
- spell mistakes by @k-for-code in #213
- spell corrections by @k-for-code in #214
- Small changes when integrating into H4 by @natolambert in #216
New Contributors
Full Changelog: v0.4.0...v0.4.1
Contributors
Assets 2
v0.4.0
v0.4.0: peft integration
Apply RLHF and fine-tune your favorite large model on consumer GPU using peft and trl ! Share also easily your trained RLHF adapters on the Hub with few lines of code
With this integration you can train gpt-neo-x (20B parameter model - 40GB in bfloat16) on a 24GB consumer GPU!
What's Changed
- Allow running evaluate-toxicity with cpu by @jordimas in #195
- [
core] Fix quality issue by @younesbelkada in #197 - Add 1.12.1 torch compatibility in sum method by @PanchenkoYehor in #190
peftintegration by @edbeeching in #163- [
core] Update dependency by @younesbelkada in #206
New Contributors
- @PanchenkoYehor made their first contribution in #190
Full Changelog: v0.3.1...v0.4.0
Contributors
Assets 2
v0.3.1
What's Changed
- Clarifications of acronyms and initialisms by @meg-huggingface in #185
- Update detoxifying_a_lm.mdx by @younesbelkada in #186
- Fix reference to example by @jordimas in #184
New Contributors
- @meg-huggingface made their first contribution in #185
- @jordimas made their first contribution in #184
Full Changelog: v0.3.0...v0.3.1
Contributors
Assets 2
v0.3.0
What's Changed
- fix style, typos, license by @natolambert in #103
- fix re-added file by @natolambert in #116
- add citation by @natolambert in #124
- add manual seeding for RL experiments by @natolambert in #118
- add
set_seedto init.py by @lvwerra in #127 - update docs with Seq2seq models, set_seed, and create_reference_model by @lvwerra in #128
- [
bug] Update gpt2-sentiment.py by @younesbelkada in #132 - Fix Sentiment control notebook by @lvwerra in #126
- realign values by @lvwerra in #137
- Change unclear variables & fix typos by @natolambert in #134
- Feat/reward summarization example by @TristanThrush in #115
- [
core] Small refactor of forward pass by @younesbelkada in #136 - [
tests] Add correct repo name by @younesbelkada in #138 - fix forward batching for seq2seq and right padding models. by @lvwerra in #139
- fix bug in batched_forward_pass by @ArvinZhuang in #144
- [
core] Addtorch_dtypesupport by @younesbelkada in #147 - [
core] Fix dataloader issue by @younesbelkada in #154 - [
core] enablebf16training by @younesbelkada in #156 - [
core] fix saving multi-gpu by @younesbelkada in #157 - Added imports by @BirgerMoell in #159
- Add CITATION.cff by @kashif in #169
- [Doc] Add how to use Lion optimizer by @younesbelkada in #152
- policy kl [old | new] by @kashif in #168
- add minibatching by @lvwerra in #153
- fix bugs in tutorial by @shizhediao in #175
- [
core] Addmax_grad_normsupport by @younesbelkada in #177 - Add toxcitiy example by @younesbelkada in #162
- [
Docs] Fix barplot by @younesbelkada in #181
New Contributors
- @natolambert made their first contribution in #103
- @ArvinZhuang made their first contribution in #144
- @BirgerMoell made their first contribution in #159
- @kashif made their first contribution in #169
- @shizhediao made their first contribution in #175
Full Changelog: v0.2.1...v0.3.0
Contributors
Assets 2
v0.2.1
What's Changed
- Update customization.mdx by @younesbelkada in #109
- add
datasetsas a dependancy by @lvwerra in #110 - [Docs] Add hlinks to scripts & notebooks by @younesbelkada in #111
- Fix
Mappingin core for Python 3.10 by @lvwerra in #112
Full Changelog: v0.2.0...v0.2.1
Contributors
Assets 2
v0.2.0
Highlights
- General decoder model support in addition to GPT-2 in #53
- Encoder-decoder model support (such as T5) in #93
- New, shiny docs with the
doc-builderin #59 push_to_hubwith PPOTrainer in #68- Simple reference model creation with layer sharing in #61
What's Changed
- Remove
nbdevdependency by @younesbelkada in #52 - Adds github actions and dummy test by @edbeeching in #55
- Update README.md by @Keith-Hon in #51
- Update README.md by @TristanThrush in #49
- Adds Python highlighting to the code block by @JulesGM in #45
xxxForCausalLMsupport by @younesbelkada in #53- [
VHead] Fix slow convergence issue by @younesbelkada in #60 - add docbuilder skeleton by @lvwerra in #59
- fix docs workflow by @lvwerra in #63
accelerateintegration by @younesbelkada in #58- add create_reference_model by @lvwerra in #61
- Improve Makefile and code quality by @lvwerra in #62
- Relax requirements by @lvwerra in #66
- modeling - change namings by @younesbelkada in #65
- [
PPOTrainer] make the reference model optional by @younesbelkada in #67 - Improvements 1a by @edbeeching in #70
- update GitHub actions to
mainby @lvwerra in #77 - [core] refactor
stepmethod by @younesbelkada in #76 - [
PPOTrainer] Support generic optimizers by @younesbelkada in #78 - Update sentiment_tuning.mdx by @eltociear in #69
- Remove references to "listify_batch" by @xiaoyesoso in #81
- Collater -> collator by @LysandreJik in #88
- Model as kwarg in pipeline by @LysandreJik in #89
- Small typo correction by @LysandreJik in #87
- [API] Make
datasetattribute optional by @younesbelkada in #85 - [Doc] Improve docs by @younesbelkada in #91
- [core] Push
v_headwhen usingAutoModelForCausalLMWithValueHeadby @younesbelkada in #86 - [core] remove
wandbdependency by @younesbelkada in #92 - add logo by @lvwerra in #95
- Encoder-Decoder models support by @younesbelkada in #93
- Fix docs hyperlinks by @lewtun in #98
- [API] LR scheduler support by @younesbelkada in #96
- Version should have
dev0unless it is a release version by @mishig25 in #99 - [core] improve API by @younesbelkada in #97
- Add push to Hub for PPOTrainer by @lewtun in #68
- [
core] Advise to usefbs=1by @younesbelkada in #102 - [Doc] New additions by @younesbelkada in #105
- restructure examples by @lvwerra in #107
- Fix nits & missing things by @younesbelkada in #108
- Convert notebook 05 by @edbeeching in #80
New Contributors
- @lvwerra made their first contribution in #2
- @vblagoje made their first contribution in #16
- @dependabot made their first contribution in #26
- @younesbelkada made their first contribution in #52
- @edbeeching made their first contribution in #55
- @Keith-Hon made their first contribution in #51
- @TristanThrush made their first contribution in #49
- @JulesGM made their first contribution in #45
- @eltociear made their first contribution in #69
- @xiaoyesoso made their first contribution in #81
- @LysandreJik made their first contribution in #88
- @lewtun made their first contribution in #98
- @mishig25 made their first contribution in #99
Full Changelog: https://github.com/lvwerra/trl/commits/v0.2.0