

A collection of transformer's guides, implementations and so on(For those who want to do some research using transformer as a baseline or simply reproduce paper's performance).
Please feel free to pull requests or report issues.
- Why this project
- Papers
- Implementations & How to reproduce paper's result
- Minimal, paper-equavalent but not certainly performance-reproducable implementations(both PyTorch implementations)
- Complex, performance-reproducable implementations
- Complex, not certainly performance-reproducable implementations
- Training tips
- Further
- Contributors
Transformer is a powerful model applied in sequence to sequence learning. However, when we were using transformer as our baseline in NMT research we found no good & reliable guide to reproduce approximate result as reported in original paper(even official tensor2tensor implementation), which means our research would be unauthentic. We collected some implementations, obtained corresponding performance-reproducable approaches and other materials, which eventually formed this project.
- seq2seq model: Sequence to Sequence Learning with Neural Networks
- seq2seq & attention: Neural Machine Translation by Jointly Learning to Align and Translate
- refined attention: Effective Approaches to Attention-based Neural Machine Translation
- seq2seq using CGRU: DL4MT
- GNMT: Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
- bytenet: Neural Machine Translation in Linear Time
- convolutional NMT: Convolutional Sequence to Sequence Learning
- bpe: Neural Machine Translation of Rare Words with Subword Units
- word piece: Japanese and Korean Voice Search
- self attention paper: A Structured Self-attentive Sentence Embedding
Indeed there are lots of transformer implementations on the Internet, in order to simplify learning curve, here we only include the most valuable projects.
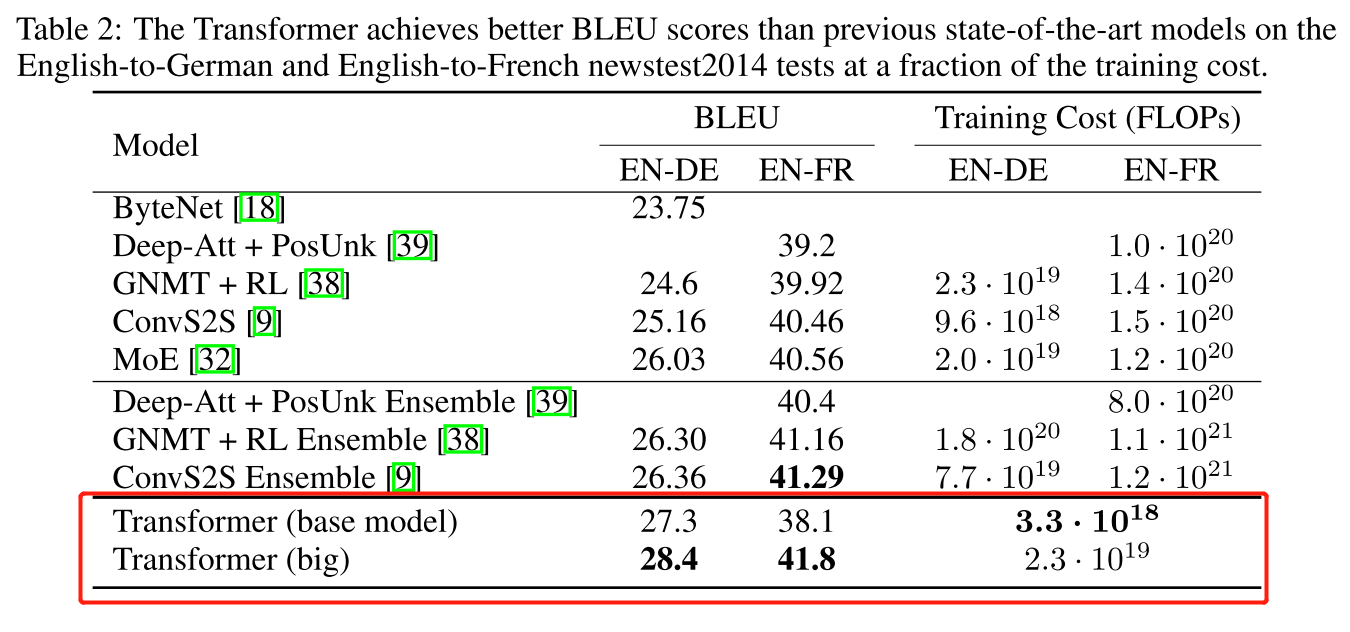
[Note]: In transformer original paper, there are WMT14 English-German, WMT14 English-French two results
Here we regard a implementation as performance-reproducable if there exists approaches to reproduce WMT14 English-German BLEU score. Therefore, we'll also support corresponding approach to reproduce WMT14 English-German result.
Minimal, paper-equavalent but not certainly performance-reproducable implementations(both PyTorch implementations)
Because transformer's original implementation should run on 8 GPU to replicate corresponding result, where each GPU loads one batch and after forward propagation 8 batch's loss is summed to execute backward operation, so we can accumulate every 8 batch's loss to execute backward operation if we only have 1 GPU to imitate this process. You'd better assemble gpu_count, tokens_on_each_gpu and gradient_accumulation_count to satisfy gpu_count * tokens_on_each_gpu * gradient_accumulation_count = 4096 * 8. See each implementation's guide for details.
Although original paper used multi-bleu.perl to evaluate bleu score, we recommend using sacrebleu, which should be equivalent to mteval-v13a.pl but more convenient, to calculate bleu score and report the signature as BLEU+case.mixed+lang.de-en+test.wmt17 = 32.97 66.1/40.2/26.6/18.1 (BP = 0.980 ratio = 0.980 hyp_len = 63134 ref_len = 64399) for easy reproduction.
# calculate lowercase bleu on all tokenized text
cat model_prediction | sacrebleu -tok none -lc ground_truth
# calculate lowercase bleu on all tokenized text if you have 3 ground truth
cat model_prediction | sacrebleu -tok none -lc ground_truth_1 ground_truth_2 ground_truth_3
# calculate lowercase bleu on all untokenized romance-language text using v13a tokenization
cat model_prediction | sacrebleu -tok 13a -lc ground_truth
# calculate lowercase bleu on all untokenized romance-language text using v14 tokenization
cat model_prediction | sacrebleu -tok intl -lc ground_truth
The transformer paper's original model settings can be found in tensor2tensor transformer.py. For example, You can find base model configs intransformer_base function.
As you can see, OpenNMT-tf also has a replicable instruction but we prefer tensor2tensor as a baseline to reproduce paper's result if we have to use TensorFlow since it is official.
- “变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统(only Chinese version, corresponding to tensor2tensor v1.6.3)
(updated on v1.10.0)
# 1. Install tensor2tensor toolkit
pip install tensor2tensor
# 2. Basic config
# For BPE model use this problem
PROBLEM=translate_ende_wmt_bpe32k
MODEL=transformer
HPARAMS=transformer_base
# or use transformer_large to reproduce large model
# HPARAMS=transformer_large
DATA_DIR=$HOME/t2t_data
TMP_DIR=/tmp/t2t_datagen
TRAIN_DIR=$HOME/t2t_train/$PROBLEM/$MODEL-$HPARAMS
mkdir -p $DATA_DIR $TMP_DIR $TRAIN_DIR
# 3. Download and preprocess corpus
# Note that tensor2tensor has an inner tokenizer
t2t-datagen \
--data_dir=$DATA_DIR \
--tmp_dir=$TMP_DIR \
--problem=$PROBLEM
# 4. Train on 8 GPUs. You'll get nearly expected performance after ~250k steps and certainly expected performance after ~500k steps.
t2t-trainer \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR \
--train_steps=600000
# 5. Translate
DECODE_FILE=$TMP_DIR/newstest2014.tok.bpe.32000.en
BEAM_SIZE=4
ALPHA=0.6
t2t-decoder \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR \
--decode_hparams="beam_size=$BEAM_SIZE,alpha=$ALPHA" \
--decode_from_file=$DECODE_FILE \
--decode_to_file=$TMP_DIR/newstest2014.en.tok.32kbpe.transformer_base.beam5.alpha0.6.decode
# 6. Debpe
cat $TMP_DIR/newstest2014.en.tok.32kbpe.transformer_base.beam5.alpha0.6.decode | sed 's/@@ //g' > $TMP_DIR/newstest2014.en.tok.32kbpe.transformer_base.beam5.alpha0.6.decode.debpe
# Do compound splitting on the translation
perl -ple 's{(\S)-(\S)}{$1 ##AT##-##AT## $2}g' < $TMP_DIR/newstest2014.en.tok.32kbpe.transformer_base.beam5.alpha0.6.decode.debpe > $TMP_DIR/newstest2014.en.tok.32kbpe.transformer_base.beam5.alpha0.6.decode.debpe.atat
# Do same compound splitting on the ground truth and then score bleu
# ...Note that step 6 remains a postprocessing. For some historical reasons, Google split compound words before getting the final BLEU results which will bring moderate increase. see get_ende_bleu.sh for more details.
If you have only 1 GPU, you can use transformer_base_multistep8 hparams to imitate 8 GPU.
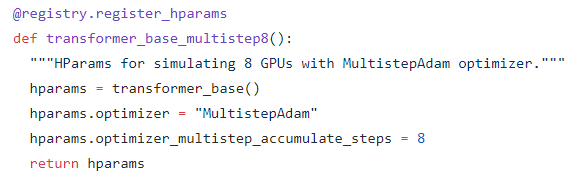
You can also modify transformer_base_multistep8 function to accumulate gradient times you want. Here is an example using 4 GPU to run transformer big model. Note that hparams.optimizer_multistep_accumulate_steps = 2 since we only need to accumulate gradient twice for 4 GPU.
@registry.register_hparams
def transformer_base_multistep8():
"""HParams for simulating 8 GPUs with MultistepAdam optimizer."""
hparams = transformer_big()
hparams.optimizer = "MultistepAdam"
hparams.optimizer_multistep_accumulate_steps = 2
return hparams(updated on v0.5.0)
For command arguments meaning, see OpenNMT-py doc or OpenNMT-py opts.py
-
Download corpus preprocessed by OpenNMT, sentencepiece model preprocessed by OpenNMT. Note that the preprocess procedure includes tokenization, bpe/word-piece operation(here using sentencepiece powered by Google which implements word-piece algorithm), see OpenNMT-tf script for more details.
-
Preprocess. Because English and German are similar languages here we use
-share_vocabto share vocabulary between source language and target language, which means you don't need to set this flag for distant language pairs such as Chinese-English. Meanwhile, we use a max sequence length of100to cover almostly all sentences on the basis of sentence length distribution of corpus. For example:python preprocess.py \ -train_src ../wmt-en-de/train.en.shuf \ -train_tgt ../wmt-en-de/train.de.shuf \ -valid_src ../wmt-en-de/valid.en \ -valid_tgt ../wmt-en-de/valid.de \ -save_data ../wmt-en-de/processed \ -src_seq_length 100 \ -tgt_seq_length 100 \ -max_shard_size 200000000 \ -share_vocab -
Train. For example, if you only have 4 GPU:
python train.py -data /tmp/de2/data -save_model /tmp/extra \ -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 \ -encoder_type transformer -decoder_type transformer -position_encoding \ -train_steps 200000 -max_generator_batches 2 -dropout 0.1 \ -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 \ -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 2 \ -max_grad_norm 0 -param_init 0 -param_init_glorot \ -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 \ -world_size 4 -gpu_ranks 0 1 2 3 -
Translate. For example:
You can set-batch_size(default30) larger to boost the translation.python translate.py -gpu 0 -replace_unk -alpha 0.6 -beta 0.0 -beam_size 5 -length_penalty wu -coverage_penalty wu \ -share_vocab vocab_file -max_length 200 -model model_file -src newstest2014.en.32kspe -output model.pred -verboseNote that testset in corpus preprocessed by OpenNMT is newstest2017 while it is newstest2014 in original paper, which may be a mistake. To obtain newstest2014 testset as in paper, here we can use sentencepiece to encode
newstest2014.enmanually. You can find<model_file>in step 1's downloaded archive.spm_encode --model=<model_file> --output_format=piece < newstest2014.en > newstest2014.en.32kspe
-
Detokenization. Since training data is processed by sentencepiece, step 4's translation should be sentencepiece-encoded style, so we need a decoding procedure to obtain a detokenized plain prediction. For example:
spm_decode --model=<model_file> --input_format=piece < input > output
There is also a bpe-version WMT'16 ENDE corpus preprocessed by Google. See subword-nmt for bpe encoding and decoding.
- OpenNMT-py FAQ
OpenNMT-py issue(deprecated)- OpenNMT: Open-Source Toolkit for Neural Machine Translation
(updated on commit 7e60d45)
For arguments meaning, see doc. Note that we can use --update-freq when training to accumulate every N batches loss to backward, so it's 8 for 1 GPU, 2 for 4 GPUs and so on.
-
Download the preprocessed WMT'16 EN-DE data provided by Google and extract it.
TEXT=wmt16_en_de_bpe32k mkdir $TEXT tar -xzvf wmt16_en_de.tar.gz -C $TEXT -
Preprocess the dataset with a joined dictionary
python preprocess.py --source-lang en --target-lang de \ --trainpref $TEXT/train.tok.clean.bpe.32000 \ --validpref $TEXT/newstest2013.tok.bpe.32000 \ --testpref $TEXT/newstest2014.tok.bpe.32000 \ --destdir data-bin/wmt16_en_de_bpe32k \ --joined-dictionary -
Train. For a base model.
# train about 180k steps python train.py data-bin/wmt16_en_de_bpe32k \ --arch transformer_wmt_en_de --share-all-embeddings \ --optimizer adam --adam-betas '(0.9, 0.98)' --clip-norm 0.0 \ --lr-scheduler inverse_sqrt --warmup-init-lr 1e-07 --warmup-updates 4000 \ --lr 0.0007 --min-lr 1e-09 \ --weight-decay 0.0 --criterion label_smoothed_cross_entropy \ --label-smoothing 0.1 --max-tokens 4096 --update-freq 2 \ --no-progress-bar --log-format json --log-interval 10 --save-interval-updates 1000 \ --keep-interval-updates 5 # average last 5 checkpoints modelfile=checkpoints python scripts/average_checkpoints.py --inputs $modelfile --num-update-checkpoints 5 \ --output $modelfile/average-model.ptFor a big model.
# train about 270k steps python train.py data-bin/wmt16_en_de_bpe32k \ --arch transformer_vaswani_wmt_en_de_big --share-all-embeddings \ --optimizer adam --adam-betas '(0.9, 0.98)' --clip-norm 0.0 \ --lr-scheduler inverse_sqrt --warmup-init-lr 1e-07 --warmup-updates 4000 \ --lr 0.0005 --min-lr 1e-09 \ --weight-decay 0.0 --criterion label_smoothed_cross_entropy \ --label-smoothing 0.1 --max-tokens 4096 --update-freq 2\ --no-progress-bar --log-format json --log-interval 10 --save-interval-updates 1000 \ --keep-interval-updates 20 # average last 20 checkpoints modelfile=checkpoints python scripts/average_checkpoints.py --inputs $modelfile --num-update-checkpoints 20 \ --output $modelfile/average-model.pt -
Inference
model=average-model.pt subset=test python generate.py data-bin/wmt16_en_de_bpe32k --path $modelfile/$model \ --gen-subset $subset --beam 4 --batch-size 128 --remove-bpe --lenpen 0.6 > pred.de # because fairseq's output is unordered, we need to recover its order grep ^H pred.de | cut -f1,3- | cut -c3- | sort -k1n | cut -f2- > pred.de
- fairseq-py example
- fairseq-py issue. The corpus problem described in the issue has been fixed now, so we can directly follow the instruction above.
- Marian(purely c++ implementation without any deep learning framework)
- RNMT+: The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation
- Scaling Neural Machine Translation
- Turing-complete Transformer: Universal Transformer
- Self-Attention with Relative Position Representations
- Improving Language Understanding by Generative Pre-Training
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
This project is developed and maintained by Natural Language Processing Group, ICT/CAS.
- Yong Shan
- Jinchao Zhang
- Shuhao Gu