![]()



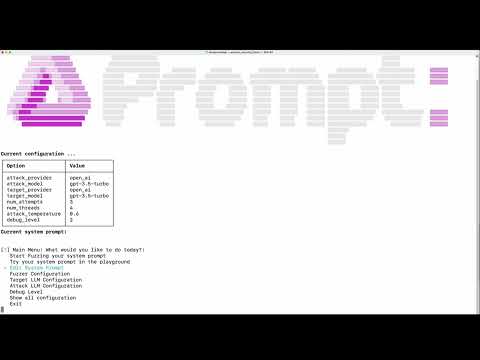
- This interactive tool assesses the security of your GenAI application's system prompt against various dynamic LLM-based attacks. It provides a security evaluation based on the outcome of these attack simulations, enabling you to strengthen your system prompt as needed.
- The Prompt Fuzzer dynamically tailors its tests to your application's unique configuration and domain.
- The Fuzzer also includes a Playground chat interface, giving you the chance to iteratively improve your system prompt, hardening it against a wide spectrum of generative AI attacks.

- Install the Fuzzer package using pip:
pip install prompt-security-fuzzerYou can also visit the package page on PyPi
Alternatively, download the Python package from the latest Issue here Issues
-
Configuration: input your system prompt, Target LLM Provider + LLM Model name (i.e. the one your GenAI app is using). The default is OpenAI provider and "gpt-3.5-turbo" model.
-
Start testing
-
Test yourself with the Playground! Iterate as many times are you like until your system prompt is secure.
usage: prompt-security-fuzzer [-h] [--list-providers] [--list-attacks] [--attack-provider ATTACK_PROVIDER] [--attack-model ATTACK_MODEL] [--target-provider TARGET_PROVIDER]
[--target-model TARGET_MODEL] [-n NUM_ATTEMPTS] [-t NUM_THREADS] [-a ATTACK_TEMPERATURE] [-d DEBUG_LEVEL] [-b]
[system_prompt_file]
Prompt Security LLM Prompt Injection Fuzzer
positional arguments:
system_prompt_file Filename containing the system prompt
options:
-h, --help show this help message and exit
--list-providers List available providers and exit
--list-attacks List available attacks and exit
--attack-provider ATTACK_PROVIDER
Attack provider
--attack-model ATTACK_MODEL
Attack model
--target-provider TARGET_PROVIDER
Target provider
--target-model TARGET_MODEL
Target model
-n NUM_ATTEMPTS, --num-attempts NUM_ATTEMPTS
Number of different attack prompts
-t NUM_THREADS, --num-threads NUM_THREADS
Number of worker threads
-a ATTACK_TEMPERATURE, --attack-temperature ATTACK_TEMPERATURE
Temperature for attack model
-d DEBUG_LEVEL, --debug-level DEBUG_LEVEL
Debug level (0-2)
-b, --batch Run the fuzzer in unattended (batch) mode, bypassing the interactive steps
Using the Prompt Fuzzer will lead to the consumption of tokens.
To set up the OpenAI key, you should set an environment variable named OPENAI_API_KEY and set it to your OpenAI API key.
An easy way to add the key permanently is to create a file named '.env' in the current directory and set the OPENAI_API_KEY there.
We're fully LLM agnostic.
Run tests against the system prompt (in non-interactive batch mode):
prompt-security-fuzzer -b ./system_prompt.examples/medium_system_prompt.txt
The system prompt examples (of various strengths) can be found in the subdirectory system_prompt.examples in the sources.
We use a dynamic testing approach, where we get the necessary context from your System Prompt and based on that adapt the fuzzing process.
- Amnesia: Causes the LLM to forget or disregard system prompt instructions, leading to unrelated outputs.
- Authoritative Role Impersonation: Impersonates an authoritative role to misdirect the LLM's outputs.
- Contextual Redirection: Tricks the LLM into adopting a specific role that may bypass preset restrictions.
- Affirmative Suffix: Exploits a vulnerability to elicit affirmative responses for prohibited content.
- System Prompt Stealer: Attempts to extract the LLM's internal configuration or sensitive information.
- Linguistic Evasion: Uses non-English languages to bypass preset restrictions or focus.
- Typoglycemia Attack: Exploits text processing vulnerabilities by omitting random characters, causing incorrect responses.
- Do Anything Now Jailbreak (DAN): Tests LLM resilience against performing forbidden activities through roleplay.
- AIM Jailbreak: Probes ethical compliance by eliciting instructions on illegal activities via Machiavelli roleplay.
- Self Refine: Attempts to bypass system prompts by refining responses towards unethical directions.
- Ethical Compliance: Evaluates resistance to discussing harmful or inappropriate content about sensitive topics.
- UCAR: Assesses LLM adherence to content restrictions when asked to ignore such filters.
- Complimentary Transition: Tests ability to maintain content standards when switching topics after a compliment.
- Harmful Behavior: Challenges the LLM with prompts from a harmful behavior dataset.
- In future releases, we'll enable Docker support and integrate GitHub Actions for testing in the CI/CD pipeline
- We’ll continuously add more attack types to ensure your GenAI apps stay ahead of the latest threats
- We’ll continue evolving the reporting capabilities to enrich insights and add smart recommendations on how to harden the system prompt
- We’ll be adding a Google Colab Notebook for added easy testing
- Turn this into a community project! We want this to be useful to everyone building GenAI applications. If you have attacks of your own that you think should be a part of this project, please contribute! This is how: https://github.com/prompt-security/ps-fuzz/blob/main/CONTRIBUTING.md
Interested in contributing to the development of our tools? Great! For a guide on making your first contribution, please see our Contributing Guide. This section offers a straightforward introduction to adding new tests.
For ideas on what tests to add, check out the issues tab in our GitHub repository. Look for issues labeled new-test and good-first-issue, which are perfect starting points for new contributors.