

Jeongwhan Choi1*,
Hyowon Wi2*,
Jayoung Kim2,
Yehjin Shin2,
Kookjin Lee3,
Nathaniel Trask4,
Noseong Park2,
1Yonsei University, 2KAIST, 3Arizona State University, 4University of Pennsylvania
- Dec 11, 2024: We presented our work at NeurIPS 2024! 🚀
- 🖼️ See our poster
- 📄 Read the paper
- 📽️ Watch the video presentation and slides
- Dec 3, 2024: 🏆 With this work, Jeongwhan Choi and Hyowon Wi have won a 2024 Qualcomm Innovation Fellowship!
- Dec 9, 2024: Our source code is available now!
- Oct 23, 2024: 🏆 With this work, Jeongwhan Choi and Hyowon Wi were qualified as a Qualcomm Innovation Fellowship Finalist in the field of AI/ML.
- Sep 26, 2024: Our paper has been accepted to NeurIPS 2024! 🎉
{kind=link}
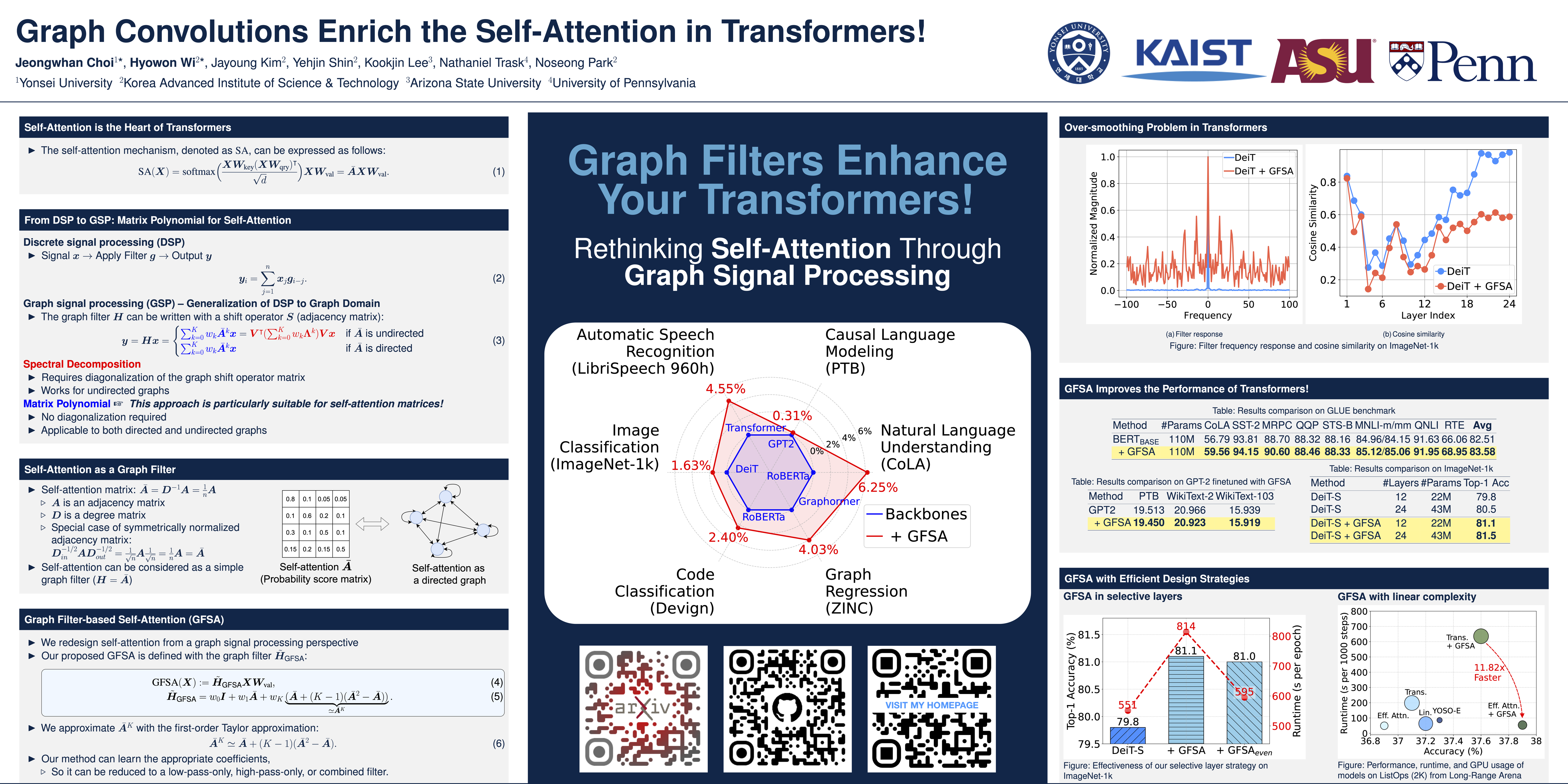
- Graph Filter-based Self-Attention (GFSA) is a novel approach to enhance the self-attention mechanism in Transformers.
- By redesigning self-attention from a graph signal processing (GSP) perspective, GFSA addresses the oversmoothing problem and improves performance for various domains.
- Easily integrates with existing Transformer models
- Improves performance with minimal computational overhead
- GFSA shows significant improvements across various tasks on multiple domains

The detailed guidance is included in the README.md of each subdirectory:
-
🖼️ Image Classification 👉
./Image -
📚 Natural Language Understanding 👉
./NLP -
🧠 Causal Language Modeling 👉
./NLP -
🌐 Graph Regression 👉
./Graph -
🎙️ Speech Recognition 👉
./Speech -
💻 Code Classification 👉
./Code
GFSA's core implementation is shown in the following pseudocode:
def GFSA(att, K):
"""
Graph Filter-based Self-Attention
Args:
att: original self-attention matrix
K: order of high-order term
Notes:
w_0, w_1 can be set in two ways:
1) As learnable parameters
2) Fixed as hyperparameters (w_0=0, w_1=1)
Returns:
gf_att: GFSA attention matrix
"""
# Initialize weights
w_0 = torch.zeros(h) # identity term weight
w_1 = torch.ones(h) # first-order term weight
w_K = torch.zeros(h) # high-order term weight
I = torch.eyes(n)[None, None, ...]
# Compute high-order term using Taylor approximation
att_K = att + (K-1) * (torch.mm(att,att) - att)
# Combine terms with weights
gf_att = w_0[None, :, None, None] * I + \
w_1[None, :, None, None] * att + \
w_K[None, :, None, None] * att_K
return gf_att- Weight Initialization:
w_0,w_1can be either learnable parameters or fixed hyperparameters - High-order Term: Uses Taylor approximation to reduce computational cost
- Minimal Parameters: Adds only a small number of parameters compared to base models
from models.attention import GFSA
# Replace original self-attention with GFSA
attention_output = GFSA(
att=attention_scores, # original attention matrix
K=3 # order of high-order term
)If you use this code for your research, please cite our paper:
@inproceedings{choi2024gfsa,
title={Graph Convolutions Enrich the Self-Attention in Transformers!},
author={Jeongwhan Choi and Hyowon Wi and Jayoung Kim and Yehjin Shin and Kookjin Lee and Nathaniel Trask and Noseong Park},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=ffNrpcBpi6}
}