This is a repository for "Generative Sparse Detection Networks for 3D Single-shot Object Detection", ECCV 2020 Spotlight.
pip install -r requirements.txt
python setup.py install
- Website
- Full Paper (PDF, 8.4MB)
- Video (Spotlight, 10 mins)
- Video (Summary, 3 mins)
- Slides (PDF, 2.4MB)
- Poster (PDF, 1.6MB)
- Bibtex
3D object detection has been widely studied due to its potential applicability to many promising areas such as robotics and augmented reality. Yet, the sparse nature of the 3D data poses unique challenges to this task. Most notably, the observable surface of the 3D point clouds is disjoint from the center of the instance to ground the bounding box prediction on. To this end, we propose Generative Sparse Detection Network (GSDN), a fully-convolutional single-shot sparse detection network that efficiently generates the support for object proposals. The key component of our model is a generative sparse tensor decoder, which uses a series of transposed convolutions and pruning layers to expand the support of sparse tensors while discarding unlikely object centers to maintain minimal runtime and memory footprint. GSDN can process unprecedentedly large-scale inputs with a single fully-convolutional feed-forward pass, thus does not require the heuristic post-processing stage that stitches results from sliding windows as other previous methods have. We validate our approach on three 3D indoor datasets including the large-scale 3D indoor reconstruction dataset where our method outperforms the state-of-the-art methods by a relative improvement of 7.14% while being 3.78 times faster than the best prior work.
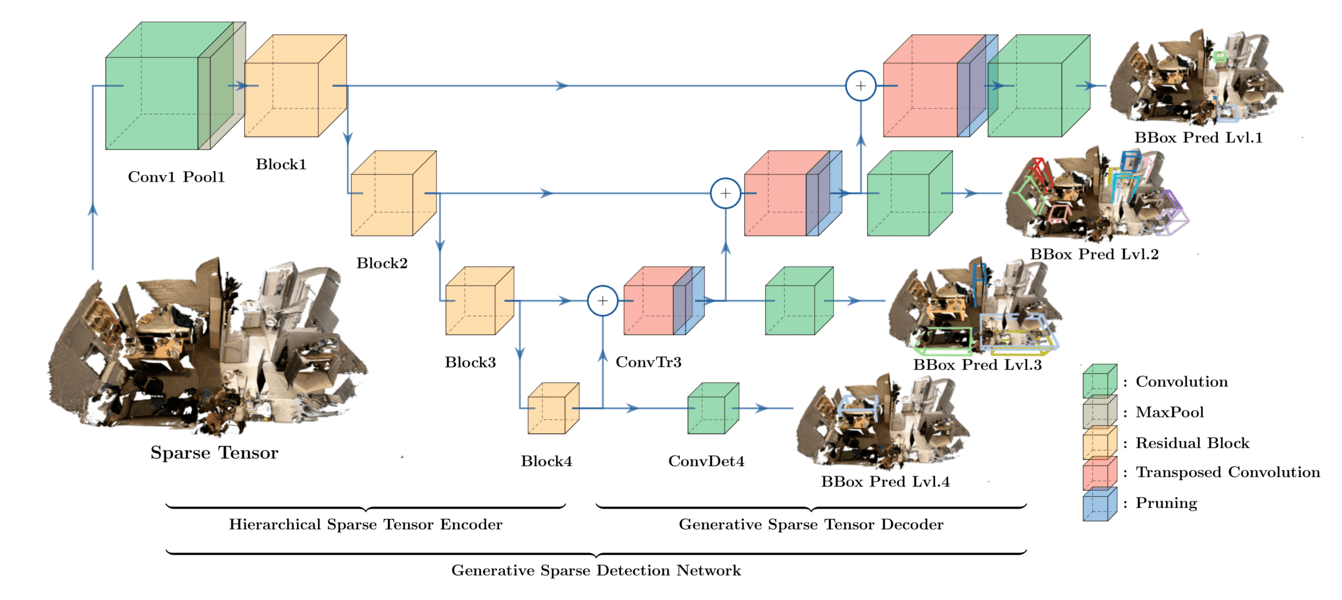
We propose Generative Sparse Detection Network (GSDN), a fully-convolutional single-shot sparse detection network that efficiently generates the support for object proposals. Our model is composed of the following two components.
- Hierarchical Sparse Tensor Encoder: Efficiently encodes large-scale 3D scene at high resolution using Sparse Convolution. Encode a pyramid of features at different resolution to detect objects at heavily varying scales.
- Generative Sparse Tensor Decoder: Generates and prunes new coordinates to support anchor box centers. More details in the following subsection.

One of the key challenges of 3D object detection is that the observable surface may be disjoint from the center of the instance that we want to ground the bounding box detection on. We first resolve this issue by generating new coordinates using convolution transpose. However, convolution transpose generates coordinates cubically in sparse 3D point clouds. For better efficiency, we propose to maintain sparsity by learning to prune out unnecessary generated coordinates.
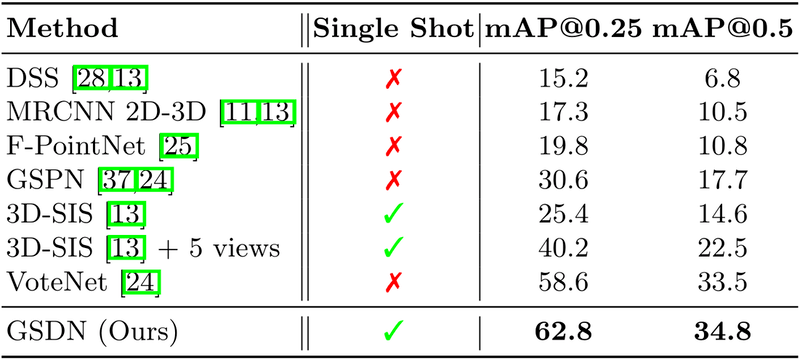
To briefly summarize the results, our method
- Outperforms previous state-of-the-art by 4.2 mAP@0.25
- While being x3.7 faster (and runtime grows sublinear to the volume)
- With minimal memory footprint (x6 efficient than dense counterpart)
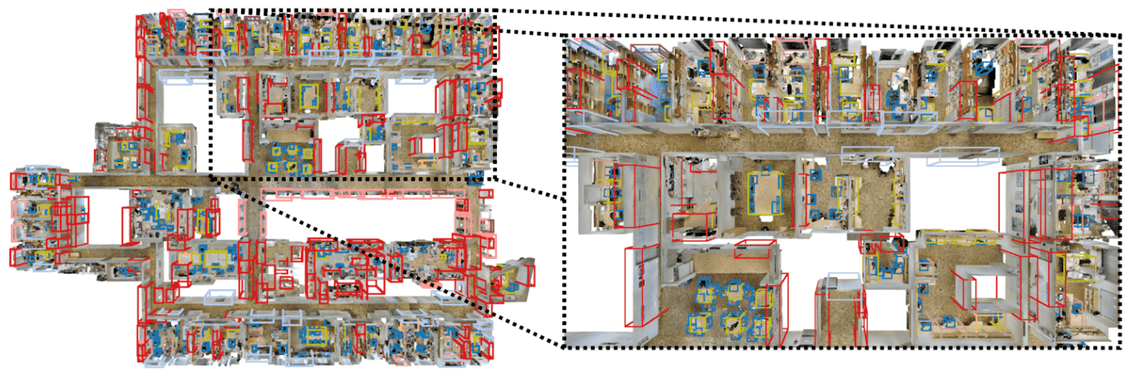
Similarly, our method outperforms a baseline method on S3DIS dataset. Additionally, we evaluate GSDN on the entire building 5 of S3DIS dataset. Our proposed model can process 78M points, 13984m3, 53 room building as a whole in a single fully convolutional feed-forward pass, only using 5G of GPU memory to detect 573 instances of 3D objects.
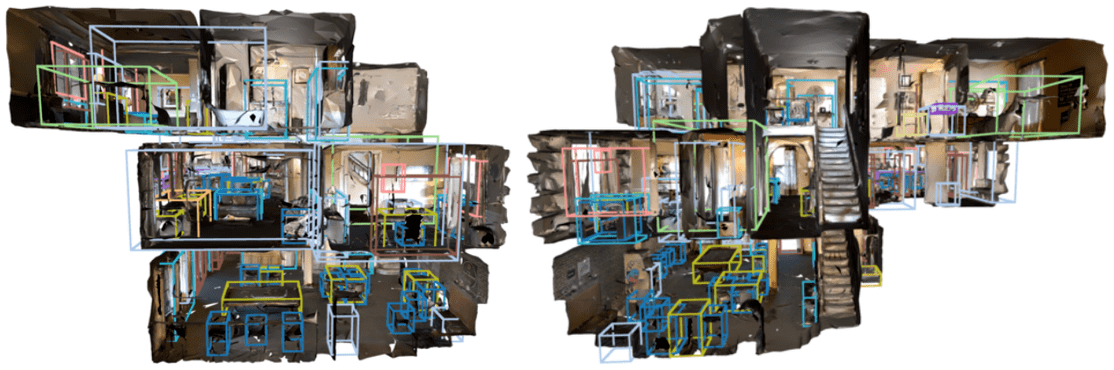
We evaluate our model on Gibson dataset as well. Our model trained on single room of ScanNet dataset generanlizes to multi-story buildings without any ad-hoc pre-processing or post-processing.
If you find our work helpful, please cite it with the following bibtex.
@inproceedings{gwak2020gsdn,
title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
booktitle={European conference on computer vision},
year={2020}
}