[Not for Merge]: Visualize the gradient of each node in the lattice. #251
Conversation
|
This PR is not for merge. It is useful for visualizing the node gradient in the lattice during training. |
|
Are these pictures from the very first beginning steps or the stable training steps(i.e. middle steps at epoch 5 or other larger epochs). |
|
Note: The above plots are from the first batch at the very beginning of the training, i.e., the model weights are randomly initialized and no backward pass has been performed on it yet. The following plots use the pre-trained model from #248
|
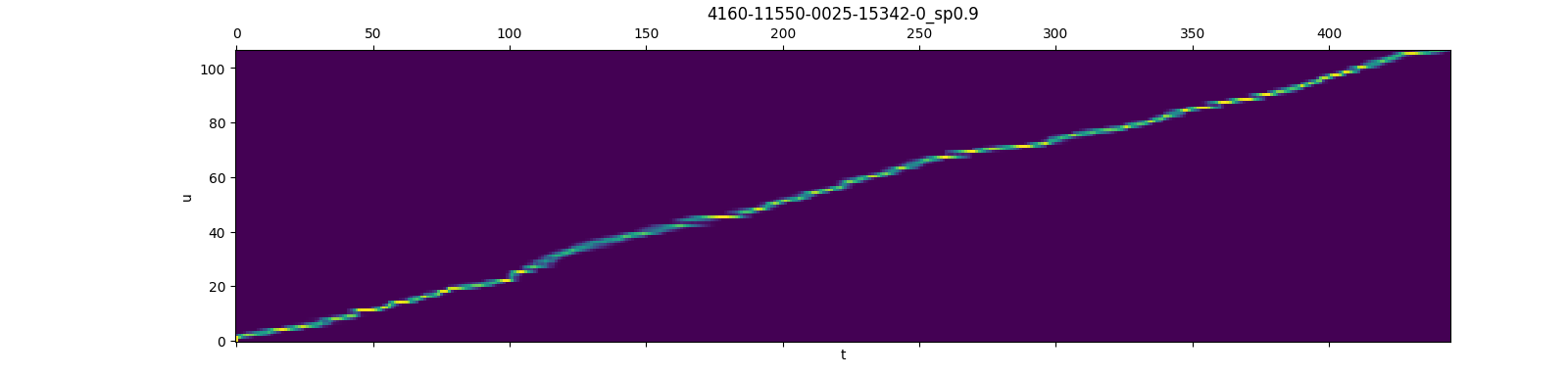




|
For better comparison, the plots between the model with randomly initialized weights and the pre-trained model are listed as follows:
|










|
@csukuangfj which quantity are you plotting here exactly? Is it |
It is related to We are plotting the occupation probability of each node in the lattice. Please # this is a kind of "fake gradient" that we use, in effect to compute
# occupation probabilities. The backprop will work regardless of the
# actual derivative w.r.t. the total probs.
ans_grad = torch.ones(B, device=px_tot.device, dtype=px_tot.dtype)
(px_grad,
py_grad) = _k2.mutual_information_backward(px_tot, py_tot, boundary, p,
ans_grad)// backward of mutual_information. Returns (px_grad, py_grad).
// p corresponds to what we computed in the forward pass.
std::vector<torch::Tensor> MutualInformationBackwardCpu(
torch::Tensor px, torch::Tensor py,
torch::optional<torch::Tensor> opt_boundary, torch::Tensor p,
torch::Tensor ans_grad) {I suggest that you derive the formula of the occupation probability of each node on your own. You can find the code at // The s,t indexes correspond to
// The statement we are backpropagating here is:
// p_a[b][s][t] = LogAdd(
// p_a[b][s - 1][t + t_offset] + px_a[b][s - 1][t + t_offset],
// p_a[b][s][t - 1] + py_a[b][s][t - 1]);
// .. which obtains p_a[b][s][t - 1] from a register.
scalar_t term1 = p_a[b][s - 1][t + t_offset] +
px_a[b][s - 1][t + t_offset],
// term2 = p_a[b][s][t - 1] + py_a[b][s][t - 1], <-- not
// actually needed..
total = p_a[b][s][t];
if (total - total != 0) total = 0;
scalar_t term1_deriv = exp(term1 - total),
term2_deriv = 1.0 - term1_deriv,
grad = p_grad_a[b][s][t];
scalar_t term1_grad, term2_grad;
if (term1_deriv - term1_deriv == 0.0) {
term1_grad = term1_deriv * grad;
term2_grad = term2_deriv * grad;
} else {
// could happen if total == -inf
term1_grad = term2_grad = 0.0;
}
px_grad_a[b][s - 1][t + t_offset] = term1_grad;
p_grad_a[b][s - 1][t + t_offset] = term1_grad;
py_grad_a[b][s][t - 1] = term2_grad;
p_grad_a[b][s][t - 1] += term2_grad; |
|
Thanks for the detailed explanation! |
This PR visualizes the gradient of each node in the lattice, which is used to compute the transducer loss.
The following shows some plots for different utterances.
You can see that