Here we provide an example of how to implement inverse probability weighting with SVMs to address confounding. The basic setup is that we have feature, class label pairs of the form <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_03.png" alt="Equation Fail"height="20"> for each subject, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_04.png" alt="Equation Fail"height="20"> , where <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_05.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_06.png" alt="Equation Fail"height="20"> for all <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_07.png" alt="Equation Fail"height="20"> . We wish to train a SVM to predict <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_08.png" alt="Equation Fail"height="20"> given <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_09.png" alt="Equation Fail"height="20"> . As an example, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_10.png" alt="Equation Fail"height="20"> might be an indicator of disease/control group and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_11.png" alt="Equation Fail"height="20"> might be a vectorized image containing voxel values or volumes of regions across the brain. However, the additional feature vector <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_12.png" alt="Equation Fail"height="20"> observed for all subjects confounds the relationship between <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_13.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_14.png" alt="Equation Fail"height="20"> . For example, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_15.png" alt="Equation Fail"height="20"> might contain covariates such as age and sex. In the presence of confounding by <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_16.png" alt="Equation Fail"height="20"> , inverse probability weighting is used to recover an estimate of the target classifier, which is the SVM classifier that would have been estimated had there been no confounding by <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_17.png" alt="Equation Fail"height="20"> .
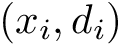{kind=link}
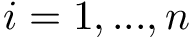{kind=link}
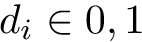{kind=link}
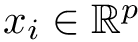{kind=link}
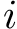{kind=link}
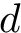{kind=link}
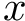{kind=link}
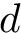{kind=link}
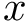{kind=link}
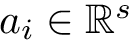{kind=link}
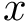{kind=link}
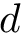{kind=link}
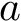{kind=link}
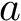{kind=link}
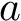{kind=link}
set.seed (1)We use the package 'rPython' to access libSVM (https://www.csie.ntu.edu.tw/~cjlin/libsvm/) through scikit learn (http://scikit-learn.org/stable/). The file fit_svm.py contains a python function that implements a linear kernel SVM with subject-level weights and a grid search to tune the cost parameter, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_18.png" alt="Equation Fail"height="20"> .
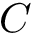{kind=link}
library(MASS)
library(rPython)
python.load("/Users/kalinn/Projects/GitHub/IPW-SVM/fit_svm.py")We generate data such that the confounders, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_19.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_20.png" alt="Equation Fail"height="20"> , affect both the features, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_21.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_22.png" alt="Equation Fail"height="20"> , as well as the class labels, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_23.png" alt="Equation Fail"height="20"> .
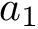{kind=link}
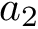{kind=link}
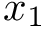{kind=link}
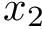{kind=link}
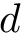{kind=link}
# Total in confounded sample
n = 200
# Number of noise features
k = 10
# a1 and a2 are confounders
a1 = runif (n, 0, 1)
a2 = rbinom(n, 1, .5)
# d is a vector of class labels
ld = -1 + a1 + a2 + rnorm(n, 0, .5)
d = 1*(exp(ld)/(1+exp(ld))>.5)
# covariance structure for features
# x1 and x2 are
covmat = matrix (c (2, .5, .5, 2), 2, 2)
errs = mvrnorm (n, mu=rep (0, 2), Sigma=covmat)
# x1 and x2 are features
x1mean = 5 - 2*d - .5*a1
x2mean = -3*a1 + .5*a2 - .5*d*(a1 + .5*a2 + .25*a1*a2)
x1 = scale(x1mean + errs[,1])
x2 = scale(x2mean + errs[,2])
noise = matrix (rnorm(n*k), n, k)
features = data.frame(x1=x1, x2=x2, noise=noise)Here, we estimate the weights by fitting a logistic regression of class ( <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_24.png" alt="Equation Fail"height="20"> ) on confounders ( <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_25.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_26.png" alt="Equation Fail"height="20"> ). However, more flexible methods can be substituted here to obtain estimates of the weights. All that is needed is an estimate of <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_27.png" alt="Equation Fail"height="20"> for each subject, <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_28.png" alt="Equation Fail"height="20"> .
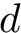{kind=link}
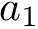{kind=link}
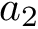{kind=link}
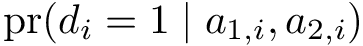{kind=link}
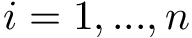{kind=link}
# Fit the model
lr.fit = glm(d~a1+a2, family=binomial)
# Obtain predicted values of pr(d=1 | a1, a2) for each subject
lr.predict = lr.fit$fitted.values
# Obtain predicted probabilities of each subject's observed class
# given observed confounder values
lr.obs = lr.predict*d + (1-lr.predict)*(1-d)
# The inverse probability weights are the inverse of the former quantity
ipweights = 1/lr.obs
hist(ipweights)
N.B. If some of the estimated weights are extremely large, one may consider truncating the predicted probabilities (e.g., at the 5th percentile) or using stabilized weights. Define <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_29.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_30.png" alt="Equation Fail"height="20"> as well as corresponding estimates <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_31.png" alt="Equation Fail"height="20"> and <img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_32.png" alt="Equation Fail"height="20"> , Then, stabilized weights and their corresponding estimates are defined, respectively, as:
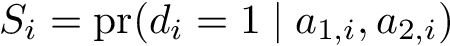{kind=link}
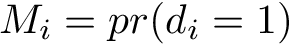{kind=link}
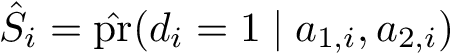{kind=link}
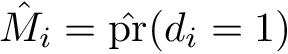{kind=link}
<img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_01.png" alt="Equation Fail"height="20">
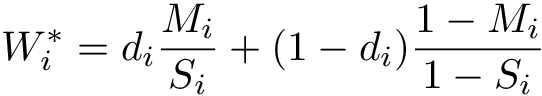{kind=link}
<img src="https://rawgit.com/kalinn/IPW-SVM/master/equations/eq_no_02.png" alt="Equation Fail"height="20">
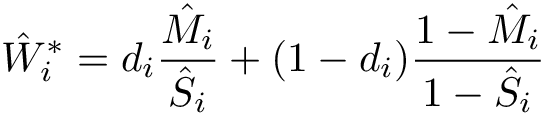{kind=link}
# For tuning the cost parameter
cost = 10^c(-3:3)
# rPython needs a matrix with no column names
features = as.matrix(features)
colnames(features) = NULL
# rPython is picky about inputs!
ipweights = as.numeric (as.character (ipweights))
# Here we input the full data as both the training and test sets,
# but in a real application we might split the original data into
# training and validation sets or perform cross-validation.
train.svm = python.call("fit_ipw_svm", features, d, features, ipweights, cost)# IPW-SVM intercept of the linear decision rule
train.svm[[1]]## [1] -0.66533796 -0.14721484 0.05854694 0.09236095 -0.01946121
## [6] 0.04282386 0.19783387 0.10237772 0.14718099 -0.17798311
## [11] 0.15213712 -0.17161128
# IPW-SVM weights of the linear decision rule
train.svm[[2]]## [1] -0.03328263
# Class predictions for the test set
train.svm[[3]]## [1] 0 0 1 1 0 1 1 0 0 1 1 0 0 0 1 1 1 1 1 0 0 0 0 1 0 0 1 0 0 1 0 0 1 1 0
## [36] 1 1 0 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0
## [71] 1 1 0 1 0 1 0 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 1 0 0 1 0 1 0 1 1 0 1 1 0
## [106] 0 0 1 0 0 1 1 1 1 0 0 0 0 0 0 1 1 1 0 1 1 0 0 0 1 1 0 0 1 0 1 1 0 1 1
## [141] 1 0 1 1 0 0 0 0 1 1 0 0 1 0 0 0 1 0 0 0 0 1 0 1 1 0 1 1 1 0 1 0 0 1 0
## [176] 0 0 0 1 1 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 0 1 0 0 1