Job backoffLimit does not cap pod restarts when restartPolicy: OnFailure #54870
Comments
|
@kubernetes/sig-api-machinery-bugs |
|
@ritsok: Reiterating the mentions to trigger a notification: In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
I think this is because for Here's my naive thoughts: for short-term to avoid this, add a cc @soltysh |
|
Just ran into the issue as well. It might be useful to amend the documentation to warn about the fact that For Pods failing as reported in this issue, what's the difference in behavior between a |
|
For OnFailure, the failed Pod will restart on the same kubelet host, so emptyDir/hostPath is still there, for Never the failed Pod got delete and a replacement will create on another(may be the same) kubelet host, if the Pod use emptyDir/hostPath to store some tmp data, the tmp data may be lost. For Pod don't use emptyDir/hostPath, I think there's no much difference for usage( |
|
Might it be a reasonable idea to move the WDYT? |
|
can anyone tell me if I set the Never and the back off to 3 will it try a restart 3 times? this is very confusing |
|
@innovia yes, it will. In fact, setting it to |
|
I should mention that my statement is based on Kubernetes 1.8. I don't know if any fixes possibly made it into the upcoming 1.9. Then again, if there were, this issue should have been updated or at least referenced. |
|
@timoreimann this is not working for a cronjob job spec (i am running 1.8.6) any idea how to get this to actually work? jobTemplate:
spec:
backoffLimit: 3
template:
spec:
containers:
- name: cron-job
command:
- "/bin/bash"
- "-c"
- |
WORKER_PID=""
handle_sig_term(){
echo -e "Sending SIGTERM to $WORKER_PID"
kill -SIGTERM $WORKER_PID
echo -e "Waiting for $WORKER_PID"
wait $WORKER_PID
exit 143 # exit code of SIGTERM is 128 + 15
}
trap "handle_sig_term" TERM
x=1
while [ $x -le 100 ]; do
echo "Welcome $x times"
x=$(( $x + 1 ))
sleep 5
done & WORKER_PID=$!
echo "Job PID: ${WORKER_PID}"
# wait <n> waits until the process with ID is complete
# (it will block until the process completes)
wait $WORKER_PID
EXIT_CODE=$?
if [ $EXIT_CODE -ne 0 ]; then
echo "Job failed with exit code: $EXIT_CODE"
exit $EXIT_CODE
else
echo "Job done!"
fi
restartPolicy: Never
|
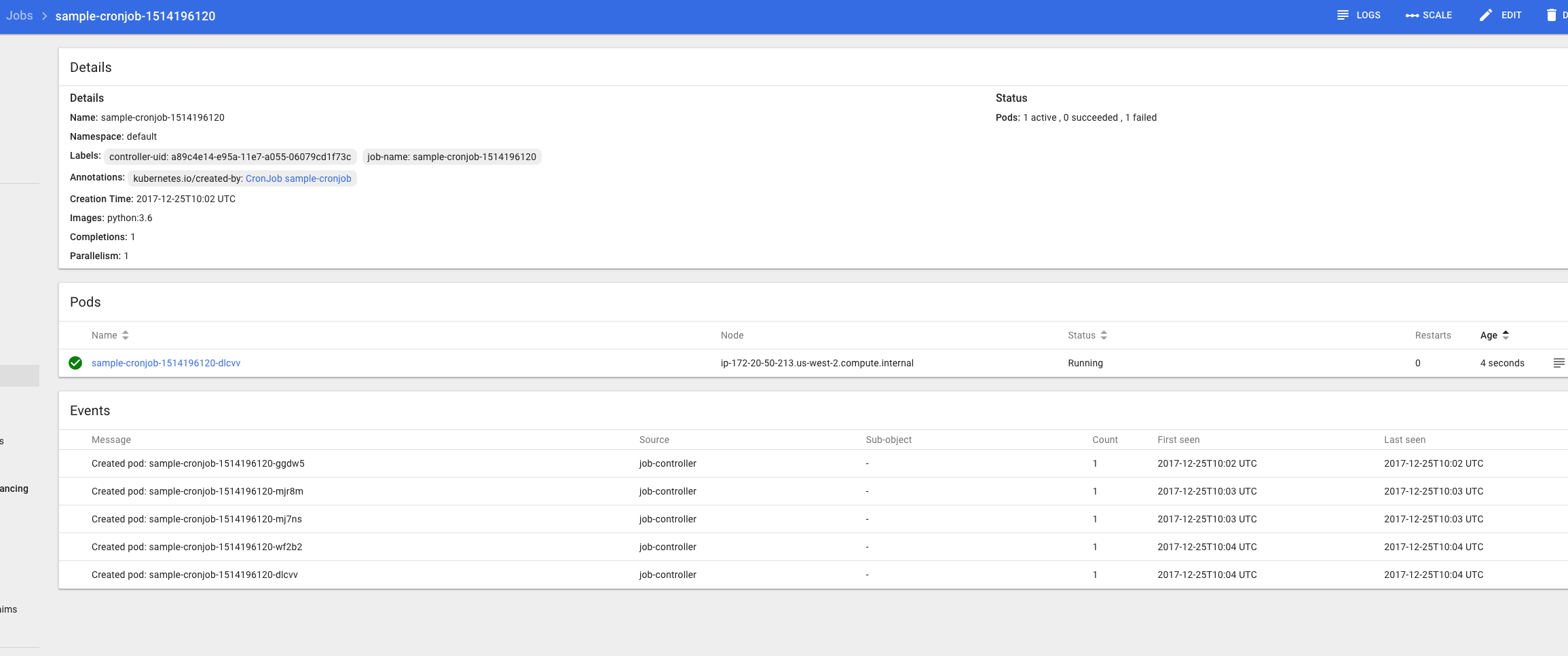
|
@innovia what's your spec's |
|
every minute just for testing |
|
Aren't you risking then that restarting jobs from a failed schedule and those from a succeeding schedule might be overlapping? How does it look like when you set the interval to, say, 10 minutes? |
|
@timoreimann same result with 10 minutes interval |
|
@innovia I ran a simplified version of your manifest against my Kubernetes 1.8.2 cluster with the command field replaced by apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/5 * * * *"
jobTemplate:
spec:
backoffLimit: 2
template:
spec:
containers:
- name: cron-job
image: ubuntu
command:
- "/bin/bash"
- "-c"
- "exit 1"
restartPolicy: NeverInitially, I get a series of three failing pods: Then it takes pretty much 5 minutes for the next batch to start up and fail: Interestingly, I only get two new containers instead of three. The next batch though comes with three again: and so does the final batch I tested: Apart from the supposed off-by-one error, things seem to work for me. |
|
Maybe you can double-check using my manifest? |
|
In the original proposal we've stated it should work for both restart policies, I've addressed the problem in #58972. It counts pod's restartCount, if overall (iow. all containers in all pods) number exceeds backoff limit the job will fail. |
Automatic merge from submit-queue (batch tested with PRs 61962, 58972, 62509, 62606). If you want to cherry-pick this change to another branch, please follow the instructions <a href="https://github.com/kubernetes/community/blob/master/contributors/devel/cherry-picks.md">here</a>. Fix job's backoff limit for restart policy OnFailure **Which issue(s) this PR fixes** *(optional, in `fixes #<issue number>(, fixes #<issue_number>, ...)` format, will close the issue(s) when PR gets merged)*: Fixes #54870 **Release note**: ```release-note NONE ``` /assign janetkuo
|
I think the backoffLimit doesn't work at all. My kubernetes version is 1.10.3 |
|
See #62382. |
* This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
* Upgrades code to support Kubernetes 1.9.4 (1.10 compatible already). * Uses restartpolicy never. This will cause that for each retry a new pod will be started instead of trying with the same all the time. Even though it seems to be fixed kubernetes/kubernetes#54870 (comment) in Kubernetes 1.9.4 backoffLimit is ignored with OnFailure policy.
kubectl get podNAME READY STATUS RESTARTS AGE cat job-with-second.yamlapiVersion: batch/v1 k8s versionv1.10.4 |
1.9 has the same problem. My cluster is 1.9.6, and i run into the same issue |
This should prevent them from re-starting when the workflow fails Note that on kubernetes before 1.12, kubernetes/kubernetes#54870 exists and these fields are not interpreted
Is this a BUG REPORT or FEATURE REQUEST?:
/kind bug
What happened:
When creating a job with
backoffLimit: 2andrestartPolicy: OnFailure, the pod with the configuration included below continued to restart and was never marked as failed:What you expected to happen:
We expected only 2 attempted pod restarts before the job was marked as failed. The pod kept restarting and
job.pod.statuswas never set to failed, remained active.How to reproduce it (as minimally and precisely as possible):
Create the above job and observe the number of pod restarts.
Anything else we need to know?:
The
backoffLimitflag works as expected whenrestartPolicy: Never.Environment:
kubectl version): 1.8.0 using minikubeThe text was updated successfully, but these errors were encountered: