This repository provides code and pretrained models for the PReFIL algorithm described in the WACV 2020 Paper:
Answering Questions about Data Visualizations using Efficient Bimodal Fusion
Kushal Kafle,
Robik Shrestha,
Brian Price,
Scott Cohen,
Christopher Kanan
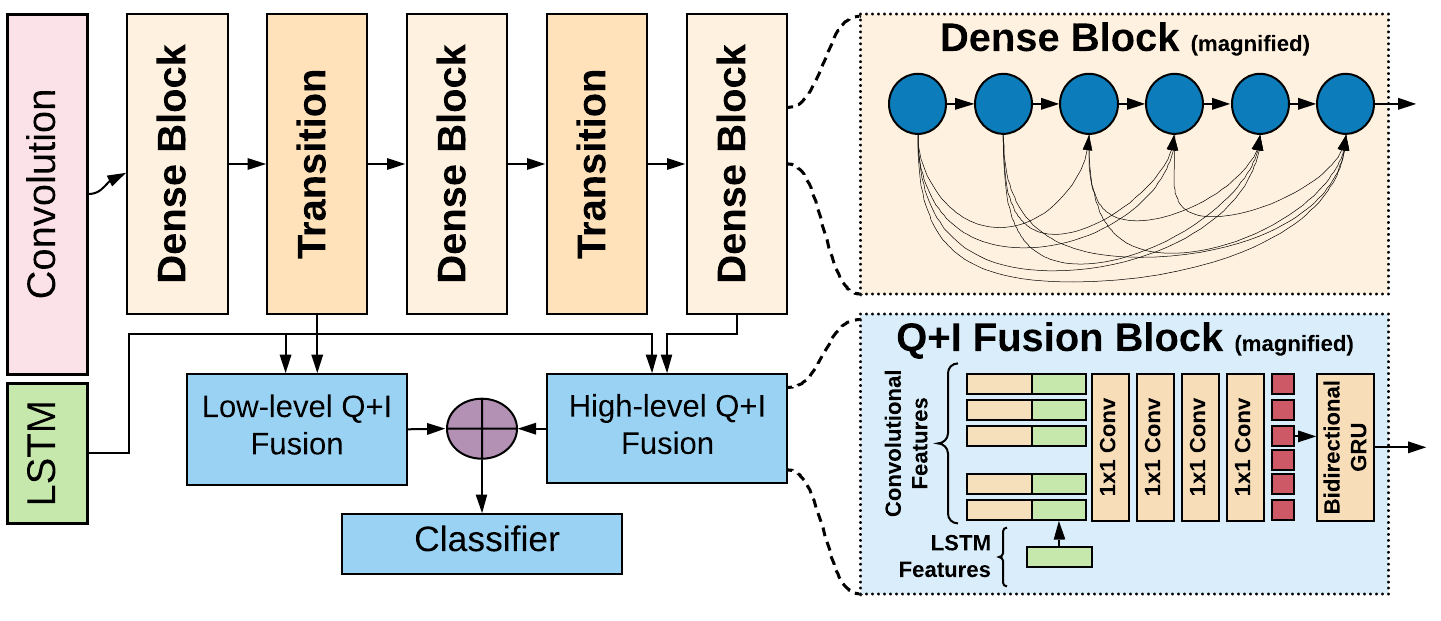
We made some minor optimizations to the code (No hyperparameters are changed from the paper). As a result, the numbers obtained from this repo are slightly better than reported in the paper.
| Paper Vs. Repo | Paper | Repo | |
|---|---|---|---|
| DVQA | |||
| Test Familiar (val_easy) | 96.37 | 96.93 | |
| Test Novel (val_hard) | 96.53 | 96.99 | |
| FigureQA | |||
| Validation 1 (same colors) | 94.84 | 96.56 | |
| Validation 2 (alternated colors) | 93.26 | 95.31 |
The repo has minimal requirements. All you should really need are CUDA 10.2, nltk and pytorch 1.5.1
However, we also provide the exact conda environment that we tested the code on. To replicate, simply edit the prefix parameter
in the requirement.yml and simply run conda env create -f requirements.yml, followed by conda activate prefil.
Head over to the README under data to download and setup data and also access pretrained model weights
The run_cqa.py provides a single entry point for training,
resuming and evaluating pre-trained models.
-
Run
python run_cqa.py --expt_name EXPT_NAME --data_root DATA_DIRto train a model according to configuration defined in config_EXPT_NAME. The config used for DVQA and FigureQA are already provided. (Optional:--data_root DATA_ROOTcan be used if your data folder is not in/data) -
This creates a folder in
DATA_ROOT/experiments/EXPT_NAMEwhich will stores a copy of the config used and all the model predictions and model snapshots -
(Optional) Different model/data variants can be trained by creating new config files. You can start by copying config_template.py to config_<YOUR_EXPT_NAME>.py and make the necessary changes.
- Run
python run_cqa.py --expt_name EXPT_NAME --resumeto resume model training from the latest snapshot saved in from the earlier run of the experiment saved inDATA_ROOT/experiments/EXPT_NAME
- Run
python run_cqa.py --expt_name EXPT_NAME --resumeto evaluate latest snapshot saved in from the previously trained modelDATA_ROOT/experiments/EXPT_NAME
- Run
python compute_metrics.py --expt_name EXPT_NAMEto compute accuracy for each question and image-type. (Optional: Use--epoch EPOCHto compute metrics for a different epoch than the latest one.)
If you use PReFIL, or the code in this repo, please cite:
@inproceedings{kafle2020answering,
title={Answering questions about data visualizations using efficient bimodal fusion},
author={Kafle, Kushal and Shrestha, Robik and Cohen, Scott and Price, Brian and Kanan, Christopher},
booktitle={The IEEE Winter Conference on Applications of Computer Vision},
pages={1498--1507},
year={2020}
}
Plus, if you use the DVQA dataset in your work, please cite:
@inproceedings{kafle2018dvqa,
title={DVQA: Understanding data visualizations via question answering},
author={Kafle, Kushal and Price, Brian and Cohen, Scott and Kanan, Christopher},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={5648--5656},
year={2018}
}