This repo is a collection of mongoDB's best practices & features of Atlas. I was reading a bunch of articles, blogs & medium posts on mongoDB. So, I wanted to aggregate all the nuances and best practices into one place.
- Introduction to MongoDB
- What is Atlas?
- Data Modeling in mongoDB
- Atlas Technical Architecture
- Atlas Best Practices
At the time of writing, MongoDB is one of the 255 NoSQL databases. When compared to relational databases, NoSQL in general are more scalable and provide superior performance. Both SQL & NoSQL databases have their unique advantages and trade off. NoSQL databases are chosen for their schema-less model and highly scalable system. According to CAP theorem, any distributed system can only satisfy two of these three Qualities namely, Consistent, Availability & Partition tolerance.
As we know that SQL database are ACID constraint, it qualifies being Consistent and highly Available. So it is difficult for the SQL system to scale horizontally. In case of NoSQL as they are eventually consistent, they are highly Available and Partition tolerance.
Coming back to mongoDB, it is a document-oriented database which stores records as documents.
Having a single node mongoDB is quite easy. But, when we want to realize a multi-sharded mongo cluster, managing and monitoring the cluster becomes difficult. Atlas is mongoDB as a service, where the whole cluster is completely managed by mongoDB. We can just concentrate on our application.
MongoDb is so called schema-less database and you can ask me why should we model such a database? Even though mongoDb is a schema-less database, it is necessary to model it, in order to achieve best performance. One thumb rule to consider in NoSQL is, to design the schema based on your queries, Whereas in SQL you design based on the structure of the data.
In general, Joins are expensive operations in database. When you use a Join(one-to-N) in SQL, it will incur a time penalty. In mongoDB, all we need to do is to flatten the one-to-N relationships. Lets see how we can model the one-to-N relationships in mongoDB. In fact, Joins are not possible in mongoDB queries, but can be performed inside the application.
When designing a MongoDB schema, you need to start with a question that you would never consider when using SQL: what is the cardinality of the relationship? Put less formally: you need to characterize your “One-to-N” relationship with a bit more nuance:
Is the cardinality One-to-Few, One-to-Many, or One-to-Squillions? Depending on which one it is, you would use a different format to model the relationship.
An example of One-to-Few might be the addresses for a person. This is a good use case for embedding – you would put the addresses in an array inside of your Person object. Make a note, the maximum size of a mongoDB document is 16 MB.
> db.person.findOne()
{
name: 'Kate Monster',
ssn: '123-456-7890',
addresses : [
{ street: '123 Sesame St', city: 'Anytown', cc: 'USA' },
{ street: '123 Avenue Q', city: 'New York', cc: 'USA' }
]
}- You don`t have to perform a separate query to get the embedded address details.
- Flattened the One-to-Many relationship. One query is enough to fetch the associated details.
- You have no way of accessing the embedded details as stand-alone entities.
As I previously said, you have to model your schema based on your queries. So in this case, assuming you don`t want to query addresses as stand-alone entities.
An example of One-to-Many might be parts for a product in a replacement parts ordering system. Each product may have up to several hundred replacement parts, but never more than a couple thousand or so. (All of those different-sized bolts, washers, and gaskets add up.) This is a good use case for referencing – you’d put the ObjectIDs of the parts in an array in product document. This type of referencing is called child-referencing, where you refer the child documents in the parent document.
Each Part would have its own document:
> db.parts.findOne()
{
_id : ObjectID('AAAA'),
partno : '123-aff-456',
name : '#4 grommet',
qty: 94,
cost: 0.94,
price: 3.99
}Each Product would have its own document, which would contain an array of ObjectID references to the Parts that make up that Product:
> db.products.findOne()
{
name : 'left-handed smoke shifter',
manufacturer : 'Acme Corp',
catalog_number: 1234,
parts : [ // array of references to Part documents
ObjectID('AAAA'), // reference to the #4 grommet above
ObjectID('F17C'), // reference to a different Part
ObjectID('D2AA'),
// etc
]
}You would then use an application-level join to retrieve the parts for a particular product:
// Fetch the Product document identified by this catalog number
> product = db.products.findOne({catalog_number: 1234});
// Fetch all the Parts that are linked to this Product
> product_parts = db.parts.find({_id: { $in : product.parts } } ).toArray();We should think NoSQL has Not Only SQL, i.e it can perform extra operations in addition to the same old SQL operations. We need to borrow the index feature of SQL in NoSQL, whenever the use case arises. In the above case, for efficient operation, you would need to have an index on products.catalog_number. Note that there will always be an index on parts._id, so that query will always be efficient.
- Each Part is a stand-alone document, so it is easy to search them and update them independently.
- You can still denormalize the schema by having frequently accessed part information inside the product document along with
parts._id. This will reduce the Joins.
-
The queries like show all the parts of the given product involves a Join, which has to be done in the application level.
-
When you denormalize the schema, updates has to be done in two collections namely, Product and Part.
An example of One-to-Squillions might be an event logging system that collects log messages for different machines. Any given host could generate enough messages to overflow the 16 MB document size, even if all you stored in the array was the ObjectID. This is the classic use case for parent-referencing – you would have a document for the host, and then store the ObjectID of the host in the documents for the log messages.
> db.hosts.findOne()
{
_id : ObjectID('AAAB'),
name : 'goofy.example.com',
ipaddr : '127.66.66.66'
}
>db.logmsg.findOne()
{
time : ISODate("2014-03-28T09:42:41.382Z"),
message : 'cpu is on fire!',
host: ObjectID('AAAB') // Reference to the Host document
}You would use a (slightly different) application-level join to find the most recent 5,000 messages for a host:
// find the parent ‘host’ document
> host = db.hosts.findOne({ipaddr : '127.66.66.66'}); // assumes unique index
// find the most recent 5000 log message documents linked to that host
> last_5k_msg = db.logmsg.find({host: host._id}).sort({time : -1}).limit(5000).toArray()As you can see, when you design the schema properly, you can scale mongoDB infinitely.
The above modeling is just the basics, there is still more to it like Two-way referencing and Denormalization as per use-case. I consider this article as bible to NoSQL modeling. Check out the brilliant article by mongoDB for the best practices in mongoDB modeling. The above tips were partly from this article. Since this repo is going to concentrate more on Best Practices with mongoDB Atlas, I am going to jump to that.
The Technical architecture shows a Single Shard MongoDB cluster deployed in AWS. This gives an higher level understanding of how it works.
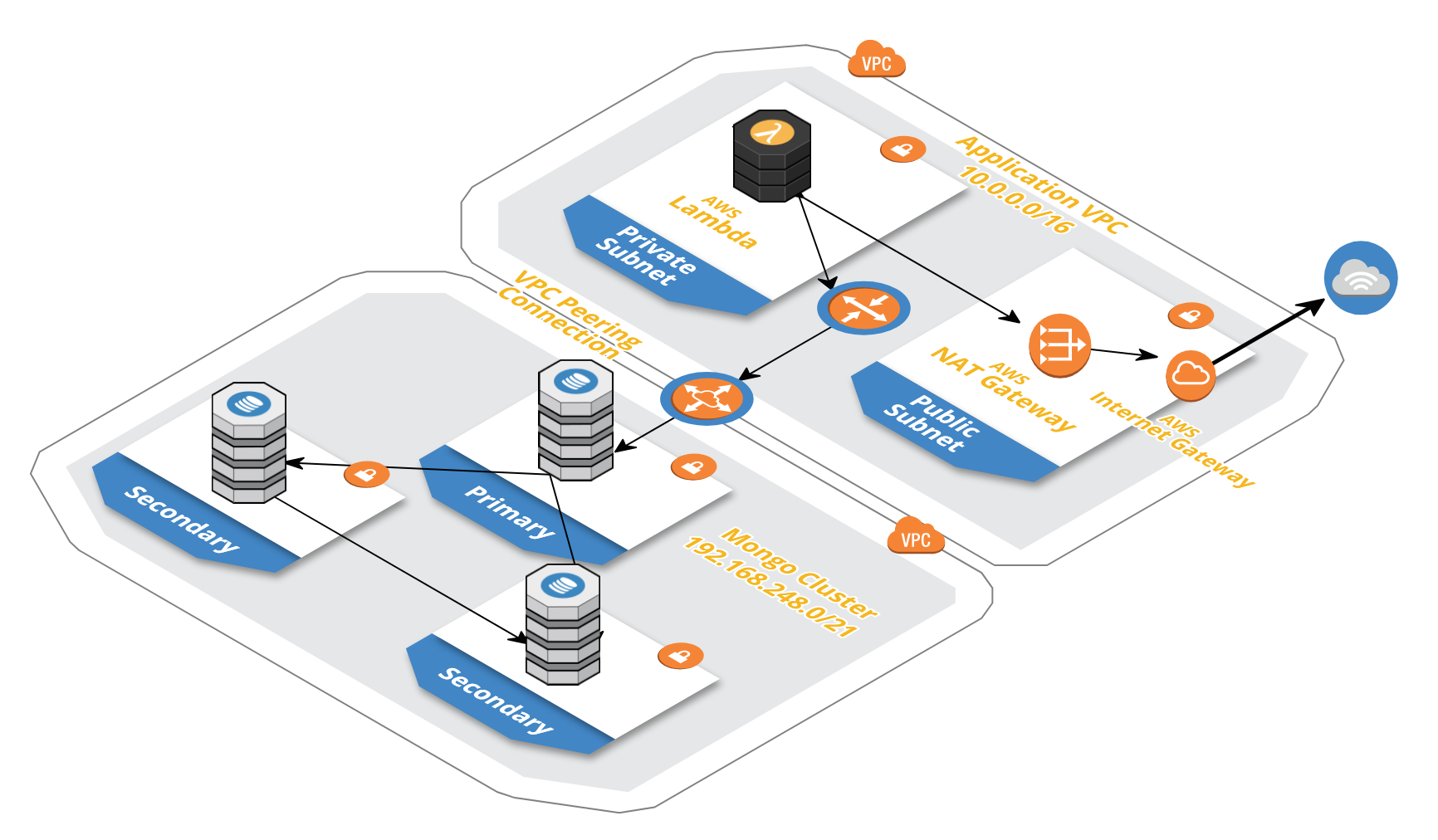
You can deploy Atlas mongoDB cluster on any cloud provider of your choice. Since, our application is on AWS, we have deployed the atlas cluster on AWS. It securely communicates with our application through the VPC peering.
The cluster creation is surprisingly simple, you can deploy an entire Atlas cluster with few button clicks. I will list down the best practices in each step of creating the cluster.
Once you are logged in to your Project -> Clusters, you will find the Build a New Cluster option in the upper right corner. Click that Button. you will see a long modal consisting steps for cluster creation process.
In the modal, first option is Cluster Name, name you cluster meaningfully as you will not be able to update it later. Second option is MongoDB Version, the Atlas itself selects the latest version for you. But If you want to change to a particular mongoDB version, you can also select that.
The third option is Cloud Provider and Region. Choose the cloud provider you wish and make sure you select a region similar to your application's region. This is important because VPC peering is region-dependent and once deployed, you cannot change the region.
Fourth option Instance Size, this is important too. If you are trying out Atlas for the first time or want to test a development version choose M0, which is a free cluster offered by the mongoDB. But for production workloads, Atlas recommends M30 & higher versions. When you select it, you can also see the cost associated with it. The Cost is shown for a single cluster(three replicas). Once you select the version say M30, you will have to select the RAM, storage capacity, storage speed and Encryption option.
MongoDB makes extensive use of RAM to speed up database operations. In MongoDB, all data is read and manipulated through in-memory representations of the data. Reading data from memory is measured in
nanoseconds and reading data from disk is measured in milliseconds, thus reading from memory is orders of magnitude faster than reading from disk.
The set of data and indexes that are accessed during normal operations is called the working set. It is best practice that the working set fits in RAM. It may be the case the working set represents a fraction of the entire database, such as in applications where data related to recent events or popular products is accessed most commonly.
When MongoDB attempts to access data that has not been loaded in RAM, it must be read from disk. If there is free memory then the operating system can locate the data on disk and load it into memory directly. However, if there is no free memory, MongoDB must write some other data from memory to disk, and then read the requested data into memory. This process can be time consuming and significantly slower than accessing data that is already resident in memory.
Some operations may inadvertently purge a large percentage of the working set from memory, which adversely affects performance. For example, a query that scans all documents in the database, where the database is larger than available RAM on the server, will cause documents to be read into memory and may lead to portions of the working set being written out to disk. Other examples include various maintenance operations such as compacting or repairing a database and rebuilding indexes.
If your database working set size exceeds the available RAM of your system, consider provisioning an instance with larger RAM capacity (scaling up) or sharding the database across additional instances (scaling out). Scaling is an automated, on-line operation which is launched by selecting the new configuration after clicking the Configure button in MongoDB Atlas. It is easier to implement sharding before the system’s resources are consumed, so capacity planning is an important element in successful project delivery.
Choose the storage capacity according to your application, but consider your working set, refer the above RAM section, before selecting the capacity. Amazon EBS provides a range of options that allow you to optimize storage performance and cost for your workload. As explaining about IOPS and throughput is out of the scope of this repo, refer to the EBS link for more information. Higher the IOPS, better the Performance. So, choose the IOPS speed depending upon your budget and SLA. Again Encryption on Rest has its own trade-offs, refer Encryption at Rest for more information.
Replicas is important to have higher availability for your mongo cluster. MongoDb provides three types of replica sets namely, 3-node, 5-node and 7-node replica set. MongoDB maintains multiple copies of data, called replica sets, using native replication. Replica failover is fully automated in MongoDB, so it is not necessary to manually intervene to recover nodes in the event of a failure.
A replica set consists of multiple replica nodes. At any given time, one member acts as the primary replica and the other members act as secondary replicas. If the primary member fails for any reason (e.g., a failure of the host system), one of the secondary members is automatically elected to primary and begins to accept all writes; this is typically completed in 2 seconds or less and reads can optionally continue on the secondaries.
Note: Replica sets are only for higher availability, not scalability For scaling, you need to shard the cluster. Updates are typically replicated to secondaries quickly, depending on network latency. However, reads on the secondaries will not normally be consistent with reads on the primary. Note that the secondaries are not idle as they must process all writes replicated from the primary. To increase read capacity in your operational system consider sharding. Secondary reads can be useful for analytics and ETL applications as this approach will isolate traffic from operational workloads. You may choose to read from secondaries if your application can tolerate eventual consistency.
MongoDB Atlas provides horizontal scale-out for databases using a technique called sharding, which is transparent to applications. MongoDB distributes data across multiple Replica Sets called shards. With automatic balancing, MongoDB ensures data is equally distributed across shards as data volumes grow or the size of the cluster increases or decreases. Sharding allows MongoDB deployments to scale beyond the limitations of a single server, such as bottlenecks in RAM or disk I/O, without adding complexity to the application. In case, you need a sharded cluster, select the number of shards required for this mongoDB cluster.
Users should consider deploying a sharded cluster in the following situations:
RAM Limitation: The size of the system's active working set plus indexes is expected to exceed the capacity of the maximum amount of RAM in the system.
Disk I/O Limitation: The system will have a large amount of write activity, and the operating system will not be able to write data fast enough to meet demand, or I/O bandwidth will limit how fast the writes can be flushed to disk.
Storage Limitation: The data set will grow to exceed the storage capacity of a single node in the system.
Refer Sharding Best Practices for achieving best performance.
Final section is backup. A backup and recovery strategy is necessary to protect your mission-critical data against catastrophic failure, such as a software bug or a user accidentally dropping collections. Best practice is to enable backups. Refer Backup & Restore section for more information.
Users who choose to shard should consider the following best practices. Select a good shard key: When selecting fields to use as a shard key, there are at least three key criteria to consider:
1. Cardinality: Data partitioning is managed in 64 MB chunks by default. Low cardinality (e.g., a user's home country) will tend to group documents together on a small number of shards, which in turn will require frequent rebalancing of the chunks and a single country is likely to exceed the 64 MB chunk size. Instead, a shard key should exhibit high cardinality.
2. Insert Scaling: Writes should be evenly distributed across all shards based on the shard key. If the shard key is monotonically increasing, for example, all inserts will go to the same shard even if they exhibit high cardinality, thereby creating an insert hotspot. Instead, the key should be evenly distributed.
3. Query Isolation: Queries should be targeted to a specific shard to maximize scalability. If queries cannot be isolated to a specific shard, all shards will be queried in a pattern called scatter/gather, which is less efficient than querying a single shard.
4. Ensure uniform distribution of shard keys: When shard keys are not uniformly distributed for reads and writes, operations may be limited by the capacity of a single shard. When shard keys are uniformly distributed, no single shard will limit the capacity of the system.
For more on selecting a shard key, see Considerations for Selecting Shard Keys.
Avoid scatter-gather queries: In sharded systems, queries that cannot be routed to a single shard must be broadcast to multiple shards for evaluation. Because these queries involve multiple shards for each request they do not scale well as more shards are added.
Use hash-based sharding when appropriate: For applications that issue range-based queries, range-based sharding is beneficial because operations can be routed to the fewest shards necessary, usually a single shard. However, range-based sharding requires a good understanding of your data and queries, which in some cases may not be practical. Hash-based sharding ensures a uniform distribution of reads and writes, but it does not provide efficient range-based operations.
Apply best practices for bulk inserts: Pre-split data into multiple chunks so that no balancing is required during the insert process. For more information see Create Chunks in a Sharded Cluster in the MongoDB Documentation.
Add capacity before it is needed: Cluster maintenance is lower risk and more simple to manage if capacity is added before the system is over utilized.
The mongoDB cluster is deployed on mongoDB's VPC and you can connect to the cluster either through a publicly available URL or through VPC peering connection. But the best practice is to connect to your cluster using a peering connection, as the database will not be publicly exposed.
With or Without a Peering connection, You still need a password to connect to the database. The best part with Atlas is you can give various privileges to the user. A user can be an Atlas admin, Read & Write to a database or only Read access to database. You can also assign fine-grained permissions like assigning above privileges to only a set of databases and collections. Once you create a user and the associated privileges, you get associated password which you can use to connect to your cluster.
Use-Case: The only Read access to database privilege will be proper fit for analytics, where the concerned user just wants to read the database, but have no permission to mutate it. Best practice is to grant least privilege required for the given user.
This user is different from the above cluster user. The fundamental unit in Atlas is the mongoDB cluster. Each project can contain multiple clusters. You can add users to your project with various privileges like Admin or Read-Only. As perviously said, the best practice is grant least privilege required for the given user.
Atlas clusters are deployed in the AWS`s EC2 instances. These instance use EBS for their storage. KMS is another AWS service which uses Envelope Encryption techniques to protect your data in the AWS services. EBS uses KMS for providing Encryption at rest which is leveraged by Atlas. The Encryption/Decryption is transparent, i.e the cryptographic process is not know to the user accessing the data from EBS. But Beware, this will introduce a latency in the reads/writes to the storage.
You can encrypt data at rest by using the above option. This option can be selected during the cluster creation process. The best practice is to select the option only if you have any SLA(service level agreement) or compliance for encryption as this will introduce some latency, which affects the user experience.
By default, SSL connection is used between your connection & the Atlas cluster. So, Encryption is made on fly, which neglects the data tampering. SSL connection is used even when you query your atlas backup.
Atlas gives you way more metrics than needed. It is important to understand the meaning of each metric, so that you can troubleshoot when you incur a problem in the Atlas cluster. You can also set alerts to a specific threshold in each metric and notify your team through mail, slack, etc., MongoDB Atlas monitors database-specific metrics, including page faults, ops counters, queues, connections and replica set status. The MongoDB Atlas team are also monitoring the underlying infrastructure, ensuring that it is always in a healthy state. Here is a short description of each topic:
These should be monitored for errors and other system information. It is important to correlate your application and database logs in order to determine whether activity in the application is ultimately responsible for other issues in the system. For example, a spike in user writes may increase the volume of writes to MongoDB, which in turn may overwhelm the underlying storage system. Without the correlation of application and database logs, it might take more time than necessary to establish that the application is responsible for the increase in writes rather than some process running in MongoDB.
When a working set ceases to fit in memory, or other operations have moved working set data out of memory, the volume of page faults may spike in your MongoDB system. Metric to be monitored, when you encounter a Slow Performance in your application.
Beyond memory, disk I/O is also a key performance consideration for a MongoDB system because writes are journaled and regularly flushed to disk. Under heavy write load the underlying disk subsystem may become overwhelmed, or other processes could be contending with MongoDB, or the storage speed chosen may be inadequate for the volume of writes.
A variety of issues could trigger high CPU utilization. This may be normal under most circumstances, but if high CPU utilization is observed without other issues such as disk saturation or page faults, there may be an unusual issue in the system. For example, a MapReduce job with an infinite loop, or a query that sorts and filters a large number of documents from the working set without good index coverage, might cause a spike in CPU without triggering issues in the disk system or page faults.
MongoDB drivers implement connection pooling to facilitate efficient use of resources. Each connection consumes 1MB of RAM, so be careful to monitor the total number of connections so they do not overwhelm RAM and reduce the available memory for the working set. This typically happens when client applications do not properly close their connections, or with Java in particular, that relies on garbage collection to close the connections. Metric to be monitored, when you encounter a Slow Performance in your application.
The utilization baselines for your application will help you determine a normal count of operations. If these counts start to substantially deviate from your baselines it may be an indicator that something has changed in the application, or that a malicious attack is underway.
If MongoDB is unable to complete all requests in a timely fashion, requests will begin to queue up. A healthy deployment will exhibit very short queues. If metrics start to deviate from baseline performance, requests from applications will start to queue. The queue is therefore a good first place to look to determine if there are issues that will affect user experience. Metric to be monitored, when you encounter a Slow Performance in your application.
Replication lag is the amount of time it takes a write operation on the primary replica set member to replicate to a secondary member. A small amount of delay is normal, but as replication lag grows, significant issues may arise. If this is observed then replication throughput can be increased by moving to larger MongoDB Atlas instances or adding shards.
Bottom Line: When you think, that your application is experiencing a significant Lag, check Page Faults,Connections and Queues first and then debug other metrics.
A backup and recovery strategy is necessary to protect your mission-critical data against catastrophic failure, such as a software bug or a user accidentally dropping collections. Taking regular backups offers other advantages, as well. The backups can be used to seed new environments for development, staging, or QA without impacting production systems.
MongoDB Atlas backups are maintained continuously, just a few seconds behind the operational system. If the MongoDB cluster experiences a failure, the most recent backup is only moments behind, minimizing exposure to data loss. Here are the sub-categories in backup & Restore
Navigate to Project -> Backups, you will see the backups of all your clusters associated with that project. In that select the options(...) button -> Edit-Snapshot-schedule. You can edit the scheduling of the cluster`s snapshot. The default and the least is 6 hours, you increase it based on your use-case and SLA. You can also schedule the longevity of these snapshots based on day, weekly and monthly categories. Best practice is to follow the default schedule.
MongoDB Atlas includes queryable backups, which allows you to perform queries against existing snapshots to more easily restore data at the document/ object level. Queryable backups allow you to accomplish the following with less time and effort:
-
Restore a subset of objects/documents within the MongoDB cluster.
-
Identify whether data has been changed in an undesirable way by looking at previous versions alongside current data.
-
Identify the best point in time to restore a system by comparing data from multiple snapshots.
You can query your backups either using Backup Tunnel or Connect Manually. Connect Manually is little tedious as you want to download the Client certificate and Client CA to connect to this backup and then query it. Lets see how to use Backup Tunnel:
1. Under Options in backups, select Query. As a first step, you have to select the snapshot to query.
2. Enter your password to authorize the process.
3. Choose the platform and follow the instructions. You will able to connect from your local terminal to this backup and start querying. It is quite beneficial.
For some reasons, you want to restore your backup. There are two options, either download the mongoDump and restore it some other machines or you restore to a cluster. You have three options namely snapshot, point in time and opLog Timestamp. snapshot is a regular one which is taken every 6 hours. Point in time helps you to restore to a particular time. opLog: You can restore based on the opLog(read/write op timings).
-
1. Under Options in backups, select Restore. As a first step, select the type of restore and select an entry from it.
2. Now choose the Download option. After the user authorization process, you will be able to download the compressed mongo dump.
-
1. Under Options in backups, select Restore. As a first step, select the type of restore and select an entry from it.
2. Now choose the Restore to Cluster option. After the user authorization process, you will be moved to next step.
3. Select the project and the cluster to restore. If you restore to a different cluster (e.g. to restore a backup from production into a QA environment) then there will be no impact on the cluster that the backup was taken from, else there will be downtime until the restore is completed. Note: You cannot restore to a free cluster(M0). Restore is available only for paid clusters. Automation will clear out all existing data for the chosen item and replace it with the data from your snapshot. All backup data and snapshots will be saved.
I know this article is very long, here is the summary to get the key takeaway from this repo:
1. Invest time in understanding the queries in your application and model database accordingly.
2. Select Instance size, RAM based on your working set of the application.
3. Enable Encryption at Rest only when you have an SLA, else don`t do it. This will introduce a latency.
4. If feasible, use VPC-Peering to connect to the mongo cluster and also whitelist the VPC-CIDR. Do not use Publicly accessible URLs to connect to your cluster.
5. When you encounter a lag in your application, the first set of metrics to look into are Connections, Page Faults and Queues.
The above contents are an aggregation of articles that I read on the internet. The best practices and thoughts are only mine. If you think something is wrong or you want to add something to this repo, a Pull Request would be amazing.