Frequently Asked Questions
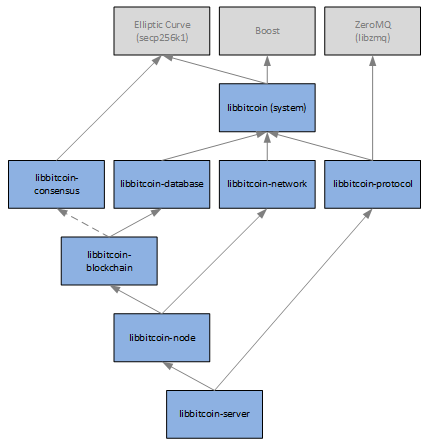
A: Libbitcoin is a Bitcoin development toolkit in C++. Included with the toolkit are three console applications: Bitcoin Server (BS), Bitcoin Node (BN) and Bitcoin Explorer (BX).
A: No. Libbitcoin is the oldest implementation of Bitcoin that is not a fork of the Satoshi code. The implementation is dramatically different and contains no Satoshi source.
A: BS is a Bitcoin full node and query server, built on libbitcoin-node and libbitcoin-protocol. It is conceptually similar to Electrum Server except that its query interface is more generalized and it incorporates its own full node (in contrast to Electrum's use of bitcoind). By default BS indexes every payment address (and stealth payment) in the entire blockchain. BS is a console application implemented as a thin command line and configuration settings wrapper around the libbitcoin-server development library. As such it provides developers with a complete implementation example.
A: BN is a Bitcoin full node, built on libbitcoin-network and libbitcoin-blockchain. It is conceptually similar to bitcoind and was the first implementation of Bitcoin not forked from the Satoshi Client. BN is a console application implemented as a thin command line and configuration settings wrapper around the libbitcoin-node development library. As such it provides developers with a complete implementation example.
A: BX is a Bitcoin utility application, built on libbitcoin (system), libbitcoin-network and libbitcoin-client. It is conceptually similar to Pybitcointools, though with a much larger set of capbilities. BX is a console application implemented as a thin command line and configuration settings wrapper around the libbitcoin-explorer development library. As such it provides developers with complete implementation examples for each of its 80+ console commands. Extensive online documentation and integrated command line help is available. BX can be used to query the blockchain via BS and to generate certificates for BS.
A: All Libbitcoin libraries and console applications are regularly tested on Windows, Linux and OSX.
A: Yes, all libraries include a configurable Linux/Unix/OSX script that downloads, builds and installs the target library and all dependencies (external dependencies as directed). The installer may be pointed at a
--prefixdirectory in which casesudois not required. There is no Windows install script (though detailed build instructions are available). For more information see server, node, explorer.
A: Yes, each release is accompanied by binaries for each of the three console applications on each of the supported platforms (see: server, node, explorer). These binaries are portable, statically-linked, single file, native, signed executables that do not require elevated privilege. There is no installation process and the use of the binaries does not modify the platform apart from writing console standard output, blockchain files and log files. Deployment is as simple as copying the binary.
Yes, however we currently restrict complete builds of libbitcoin-database to 64 bit. This is necessary because of the use of memory-mapped file storage for the blockchain. Some 32 bit systems do not provide sufficient address space.
A: All libraries have a dependency on secp256k1 and Boost (consensus requires Boost only for test execution). The client-server libraries (protocol, client, explorer, server) also have a libzmq dependency.
A: The client-server interface is a set of endpoints at which a client can obtain blockchain information from the server. It is similar in concept to the JSON RPC interface except that it is secure, scalable, and fast. There are four public endpoints and four secure endpoints, depending on configuration.
A: On ZeroMQ with CurveZMQ for security (an implementation of CurveCP/NaCl).
A: There are a large number of ZeroMQ language bindings as well as the libbitcoin-client which is used by BX.
A: Yes, there is a heartbeat endpoint.
A: Yes, either by IP address and/or using curve certificates.
A: Yes, a complete set of inputs and outputs are returned to the caller.
A: Yes, for queries with potentially large result sets.
A: No. Large queries may require extending a client's timeout value.
A: Yes, there is a independent endpoint for each. Each block confirmed in the strong chain is broadcast and each valid transaction is broadcast when it is first seen as unconfirmed and again if confirmed in a strong chain block.
A: Yes, using the query endpoint a client may subscribe to notifications of all inputs and outputs that affect a given payment address as transactions and blocks arrive at the node.
A: Yes, all transactions are mined for stealth metadata. Stealth queries and prefix notifications are both supported.
A: Yes, see the current list of servers.
A: BS is built on BN, which in turn is built on the libbitcoin-network configurable protocol library. Version3 supports P2P protocols in the version range 31402-70013. The node supports all intervening levels and through simple configuration of these values can target a narrower range (always negotiating the highest level supported by a given peer).
A: Obsolete messages are not supported (
checkorder,reply,submitorder,alert), which has no impact on network operation. Bloom filter messages (filterload,filteradd,filterclear) are not handled, though these services are excluded by not setting the NODE_BLOOM service bit in theversionmessage. Theaddrmessage is supported but response is limited to returning the node's configured address, on the first request. Because version3 does not implement transaction pool indexing there is no response to amempoolmessage.
A: The type library includes the serializable types so that a developer may add network support or perform other operations as desired. However there are significant flaws in the design of BIP37 and as such libbitcoin does not integrate it into the network layer. The feature is fundamentally client-server in nature, and as such constitutes a general denial of node service across the P2P network. Additionally, the filtering is non-private, exposing the client's wallet to each node that it connects. Finally, the client must trust nodes to provide complete information. These flaws have led to calls for secure links in the P2P network, which risks partitioning the network into public and private segments. Yet the P2P protocol must remain anonymous in order to remain public. The better solution to each of these problems is to move wallet queries to a dedicated, securable, trustable, client-server port. Libbitcoin provides that capability in the client-server interface.
A: Tor over the P2P protocol is a very bad idea for privacy and is not supported. However, BS can easily be set up as a hidden service and BX (and other clients) can query/post to the hidden service using its SOCKS5 proxy configuration. There are existing community servers that can be used to privately post transactions and blocks to the Bitcoin P2P network. This proper use of Tor in a secure client-server protocol resolves all of the privacy problems associated with using Tor in the P2P protocol and satisfies the same scenario requirements.
A: No. This protocol change provides no material privacy or security benefit to the user. Encrypting connections to anonymous peers just shifts the threat vector. The argument that ad hoc encryption will hinder the global persistent threat, or even an ISP, from monitoring the network is invalid. It is easier to become a peer on the network than to monitor wire communications. Furthermore the information carried on the network is both public and independently verifiable using consensus rules. Posting transactions to your own node is unsafe, with or without encryption to each peer. Bitcoin is not an anonymizing network. To post transactions to the network privately one should connect to a community server using an actual anonymizing network, such as Tor, over a secure client-server protocol.
A: No. This protocol change represents a significant security risk for Bitcoin for no material privacy or security benefit to the user. Bitcoin is an anonymous public network of public information. The reason for consensus-based validation is to eliminate the need to trust other parties. Instead of verifying the identity of a trusted party, Bitcoin evaluates the validity of data received from anonymous parties using consensus rules. The argument that "one trusted link is necessary to prevent chain partitioning" is invalid. Encryption cannot ensure that one is seeing the chain with the most work. Bitcoin must remain a public network in order to be distributed and therefore to be secure against attacks on points of centralization.
A: Yes, and the type library already includes the serializable types so that a developer may add network support or perform other operations as desired. This is primarily an issue of development priorities. Network operation is currently sufficient without compact blocks support, with the exception of mining. Libbitcoin is not a full mining stack until the next major release, so compact blocks support is deferred until then. At that point the maximum configurable protocol level will become
70014.
A: Libbitcoin takes a very different approach to DoS than other implementations. The node does not implement "banning" and maintains no history of disconnected peers. Violation of protocol is the only rational definition of "misbehavior". Peers that violate protocol rules are dropped. Within that context the node limits resources (processor, memory, storage, bandwidth) available to peers. When a peer exceeds a rate quota it should be dropped as well, however this feature is not yet implemented. As a result DoS protection is limited and may be insufficient depending on the scenario.
A: No, there is no way for a node to know the capacity of an independent peer. Peers are expected to manage their own resources. For example there is no estimation of "blocks in flight", the node may request 50,000 blocks of a peer or send it 50,000 requested blocks without delay.
A: Yes, simply replace the
hosts.cachefile with your own list of addresses.
A: First edit the configuration file for testnet and then initialize the store. All necessary values are documented in the sample configuration. By modifying the command line to point to a configuration file you can run multiple instances from the same binary.
A: It is currently the policy of the development team to implement support for forks that are active on the Bitcoin mainnet branch with the most work. This is primarily an issue of development priorities. This policy is likely to change as libbitcoin nodes start to make up a material portion of the economy and/or hash power, as it will become desirable to deploy forks well before they activate (i.e. in order for users to activate them).
A: Libbitcoin implements bip16, bip30, bip34, bip66, bip65, bip90, bip68, bip112, bip113 and all are enabled by default, bip141, bip143, and bip147 are added in v3.4, and testnet and regtest are also available as configurable hard forks.
A: Yes, any combination of implemented forks my be disabled via
[fork]configuration settings. This flexibility allows development to add features while leaving consensus to the community.
A: Yes, this is complete in v3.4.
A: Yes, this is implemented in v3.4. Because bip144 (witness) encoding of transactions is incompatible with original transaction encoding, there is a new query command to expose witness-serialized transactions.
A: No, as of v3.4 the server indexes only standard script and stealth addressing. Server index support for standard witness addressing (as well as wallet and explorer bip173 encoding of witness addresses) is planned for a future release.
Q: Is the libbitcoinconsensus script validation library integrated?
A: Yes, the libbitcoin-consensus library encapsulates the 33 files considered to be bitcoin script consensus-critical. This optional library is linked into BS/BN builds by default. Use of the library can be enabled by setting
blockchain.use_libconsensus = true. Otherwise native script consensus validation is used.
A: It is a design priority to produce self-documenting code. With a high level understanding of Bitcoin and C++ one can review the libbitcoin source code and easily identity each consensus rule. The implementation does not interleave chain queries with consensus checks. Queries are performed to populate the blockchain data necessary to validate a transaction or block, as the case may be, and then validation is run as a function. So for example, contextual, non-script block validation appears essentially as follows:
code header::accept(const chain_state& state) const
{
if (bits_ != state.work_required())
return error::incorrect_proof_of_work;
else if (version_ < state.minimum_version())
return error::old_version_block;
else if (timestamp_ <= state.median_time_past())
return error::timestamp_too_early;
return error::success;
}
code block::accept(const chain_state& state) const
{
code ec;
const auto bip16 = state.is_enabled(rule_fork::bip16_rule);
const auto bip34 = state.is_enabled(rule_fork::bip34_rule);
const auto bip113 = state.is_enabled(rule_fork::bip113_rule);
const auto block_time = bip113 ? state.median_time_past() :
header_.timestamp();
if ((ec = header_.accept(state)))
return ec;
else if (bip34 && !is_valid_coinbase_script(state.height()))
return error::coinbase_height_mismatch;
else if (!is_valid_coinbase_claim(state.height()))
return error::coinbase_value_limit;
else if (!is_final(state.height(), block_time))
return error::block_non_final;
else if (signature_operations(bip16) > max_block_sigops)
return error::block_embedded_sigop_limit;
return accept_transactions(state);
}
code transaction::accept(const chain_state& state) const
{
const auto bip30 = state.is_enabled(rule_fork::bip30_rule);
const auto bip68 = state.is_enabled(rule_fork::bip68_rule);
if (bip30 && validation.duplicate)
return error::unspent_duplicate;
else if (is_missing_previous_outputs())
return error::missing_previous_output;
else if (is_confirmed_double_spend())
return error::double_spend;
else if (!is_mature(state.height()))
return error::coinbase_maturity;
else if (is_overspent())
return error::spend_exceeds_value;
else if (bip68 && is_locked(state.height(), state.median_time_past()))
return error::sequence_locked;
return error::success;
}A: To run a node on testnet edit the configuration file and then initialize the store. All necessary values are documented in the sample configuration. By modifying the command line to point to a configuration file you can run multiple instances from the same binary.
A: The regtest network is fully supported via configuration in a manner similar to testnet.
A: Libbitcoin is a development toolkit for Bitcoin development. Apart from test coins for Bitcoin, the libraries does not incorporate specific support for altcoins. To the extent that an altcoin operates within a generalized implementation of Bitcoin, support is available. For example, many client stack features support most altcoins. But due to consensus and/or network protocol differences altcoins are not supported by the server stack.
A : There is no current plan to support split coins, however insofar as one can be reasonably accommodated by adding configurable fork rules (such as with existing soft forks and testnet/regtest), one or more may be added.
A: We are aware that libbitcoin has been forked with the minor modifications necessary to support a Litecoin node/server, however this work has not yet not been published. It may be possible to support this via configuration of additional fork rules.
A: The database is implemented by libbitcoin-database. The implementation is custom built for blockchain storage, utilizing operating system memory-mapped file capabilities.
A: Performance is the primary reason. However the implementation also improves scalability and reliability, and minimizes external dependencies.
A: By storing block, transaction and address records in hash tables constant time retrieval is achieved for each. Because memory-mapped files utilize highly-optimized operating system virtual memory services, efficient I/O is achieved on all platforms with minimal effort. The lock-free implementation also enables concurrent read-while-write and concurrent block write operations.
A: A common definition of scalability is a system, "whose performance improves after adding hardware, proportionally to the capacity added." The hash table structure provides constant time retrieval but paging costs are higher with less RAM. With sufficient RAM to hold the entire file paging costs are largely eliminated. As such the store scales very well in proportion to available RAM. The custom database also enables parallel block writes during periods of pre-validated block download, allowing the node to operate on all available threads.
A: External dependencies are extremely difficult to validate, and a general purpose database is a very complex system. Placing such complex external code in a consensus-critical path should be avoided. The custom store is very simple due to the access patterns of a blockchain. Resource limitations, such as the database lock exhaustion that caused the March 2013 chain fork, raise an unhandled exception that aborts the process.
A: Paging costs are inversely related to the amount of available RAM, and for very low RAM systems this can result in thrashing. To remain proportional for such systems the store implements optional caching for unspent outputs. This trades a smaller amounts of RAM for significantly reduced paging on such systems. With higher RAM systems caching is counterproductive as the uncached implementation outperforms the cached.
A: Cache priming occurs automatically as part of node operation. Cache is not independently stored to disk and is not primed from the store at startup. Therefore node performance may improve the longer the node operates. However cache is generally optimal after just a few blocks have been received.
A: No, given the store design this would be entirely counterproductive.
A: There is no store of unspent outputs, as transactions natively contain all spends and outputs. Each output in a transaction is updated with the spender height, which allows for determination of an output having been spent relative to another block at any height.
A: Yes, as with most design decisions. The store is not journaled. As such any failure during a write is treated as store corruption, requiring a regeneration of the store. This is considered an acceptable trade-off given the significant benefits achieved, and in light of the fact that the store is entirely a cache of public data. Additionally, once the blockchain has been validated regeneration can be performed very rapidly either through backup restoration and/or though reliance on previously-validated points in the chain.
A: Process termination or disk fault detected by the operating system, during a write, will corrupt the store. These faults are reliably detected by the node upon restart, preventing operation with a corrupt store. Otherwise a fault must result from a code error that does not terminate the process or an undetected platform fault. These faults are not detected by the node and will produce undefined behavior. However this situation is not unique to the custom store.
A: The store signals the start of a transactional commit using an empty file named
flush_lock. The file is cleared when the write is flushed to disk. Therefore if the process is running the presence of the file indicates an unflushed write. If the node detects the file at startup it assumes that the preceding write was not flushed and fails to start the blockchain. In this case the blockchain must be deleted and a new one initialized before starting the node. Deleting theflush_lockfile and starting with a corrupt store will produce undefined behavior (including seemingly proper operation for some arbitrary period of time).
A: Yes. A controlled shutdown arises from either a
control-cat the console or an operating systemkillsignal. If the process is allowed to terminate on its own following such a signal the store is valid. Otherwise, such as termination due to removal of power from the machine, the store may be corrupted. However if writes are flushed to disk at the time, the store remains valid. Write flushing is enabled via configuration of thedatabase.flush_writessetting. Writes are extremely fast and infrequent, so as long as each write is flushed to disk the chance of a corruption is limited. However the cumulative effect of write flushing can significantly slow initial block download and may result in a transaction backlog on slower machines, so its use is a trade-off.
A: Yes. Hash tables achieve the best performance when collision rates are low. It is possible to adjust the number of hash table buckets using the following configuration settings. These values must not be changed after initializing the store.
[database]
block_table_buckets = 650000
transaction_table_buckets = 110000000
spend_table_buckets = 250000000
history_table_buckets = 107000000A: Libbitcoin maintains no transaction orphan pool. Orphan transactions, or more specifically transactions for which the node is missing previous outputs, are discarded upon receipt. Subsequently a request is made to the peer that provided the transaction to provide transactions for all missing outputs. This helps expand the set of unconfirmed transactions.
A: Libbitcoin maintains no in-memory pool of transactions. Unconfirmed transactions are those that are valid but not included by a block in the strong chain. Those with a sufficient fee level are placed into the transaction store and others are discarded. The set of unconfirmed transactions in the store is referred to as the transaction pool.
A: The size of the transaction pool is controlled by configuration of
node.byte_fee_satoshisandnode.sigop_fee_satoshis. These default to 1 (satoshi/byte) and 100 (satoshi/sigop) respectively, and can be set to any floating point value greater than or equal to 0. Configuration of free transactions exposes the node to a cost-free attack on disk space and is therefore not recommended.
A: The store does not purge transactions. Generally speaking the store is append-only, which creates an important performance advantage. This is consistent with Bitcoin's design in that data never becomes irrelevant. Even an unconfirmed transaction in conflict with a confirmed transaction can be confirmed through a reorganization. All valid transactions can be mined at any time. Since transaction storage is the same for confirmed and unconfirmed transactions, there is no movement of the transaction in the store as these changes occur. This means that a new block can be validated without re-validating or re-storing any of its transactions. In typical operation with the default byte fee of 1 satoshi (and no soft fork transition) there is nothing to do except validate the block header, coinbase and summary transaction bytes, sigops and fees. Additionally, since most valid transactions do eventually get mined, disk storage is not materially impacted. Finally, the store can be compacted at any time by simply re-synchronizing (which can actually be faster than rewriting the data on disk, depending on the platform).
A: The transaction pool is not indexed, which precludes non-empty response to a
mempoolrequest and generation of a non-empty block template (for mining). The transaction pool index is currently under development for a future release.
A: No. Given current lack of unconfirmed transaction indexing, any transaction that conflicts with an existing transaction is rejected. Otherwise there would be no mechanism to guard against cost-free attacks on disk space. However the current work on transaction indexing will enable general acceptance of conflicting transactions in the case where the fee increment is sufficient, based on configuration.
A: Yes, the server can return any transaction in the store and provides confirmation height as applicable.
A: Libbitcoin maintains no block orphan pool. Orphan blocks, or more specifically blocks for which the node has no parent, are discarded upon receipt. Subsequently intervening blocks are requested from the peer that supplied the orphan.
A: Libbitcoin refers to blocks that are valid and connected to a weaker chain as unconfirmed, as they carry the same monetary weight as unconfirmed transactions. The node maintains an in-memory pool of unconfirmed blocks. With each confirmed block this block pool is pruned to the depth configured by the
blockchain.reorganization_limitsetting (256 by default, as this is close to the effective reorganization limit of common nodes). Elimination of the block pool is planned for a future release.
A: No, unconfirmed blocks are not visible via the client-server interface. When the block pool is eliminated in a future release all blocks will be queryable, just as are transactions.
A: Yes, there is configurable statsd integration, however it does not currently send any messages. There is also detailed block validation performance information logged to the console and debug log.
A: Libbitcoin is both asynchronous and multi-threaded. The network stack can run on a single thread of execution, which can be configured using
network.threads. The node can also operate on a single thread of execution, however it transfers execution from the network thread pool to the priority thread pool for validation. The priority thread pool can be configured usingblockchain.cores. The server requires independent threads of execution for each endpoint and the number of configured query workers.
A: Libbitcoin does not track or throttle memory usage. Instead its design produces a typically flat memory profile that increases in relation to the size of blocks and the number of peers. The caching of unspent outputs is optional, modest even on low RAM machines (and sub-optimal for high RAM machines), and there is no other blockchain caching. There is also no memory pooling apart from a configurable potential for unconfirmed blocks (which is deprecated). At the same time the blockchain store is not materially larger than that of any other node. Finally, the operating system is left to do what it typically does well, allocation of resources. As the amount of available RAM changes, node performance adjusts automatically based on operating system paging design.
A: As of March 2017 the mainnet blockchain requires 115 GB. With additional server indexing of all addresses, spends and stealth payments at all heights, the storage requirement is about 240 GB. When the process is running the store is expanded by the percentage configured in
database.file_growth_rate. This value can be reduced to a much smaller value as the store gets larger, with little impact on performance. An SSD on a high speed interface is highly recommended. See Hardware for more details.
A: There are a number of factors, including the content of the block, size of the blockchain, transaction pool relevance, cache priming, page loading, network load, compiler optimizations, operating system, and hardware resources.
A: We are not aware of any software that can validate a block faster. With no cache, a full set of peers, and without using compact blocks, the node deserializes and fully validates a typical full block in under 150 ms on a big server (275 ms on a small server with modest unspent output cache). We expect that to be reduced to 35 ms (and 70 ms respectively) with the implementation of a transaction pool index (due to amortized population and accept costs) and compact blocks (due to eliminated redundant deserialization).
A: No, all reads run concurrently when threads are available. Block and transaction validation uses an independent priority logical thread pool, giving it precedence over server queries.
A: Not noticeably. Reads are not blocked for writes and writes are not blocked for reads. However, prioritization of validation threads implies some impact on a concurrently-executing query. That prioritization is optional and may be eliminated by configuration.
A: We have not tested to a limit. However even with just one worker configured this limit should be very high.
A: The number of inbound, outbound and manual peers is limited by configuration. There are no limits imposed by the implementation. Maintaining a large number of outbound peers may be harmful to the network. The default value (8) is recommended. However tests have successfully maintained concurrent connection to thousands of mainnet peers, with no material impact on block validation performance. [The address pool is not optimized for such operations, which can lead to a high level of connection churn in attempting to locate new nodes.]
A: The maximum effective value is 1034 blocks (or 266 with all peers below protocol version 31800). This results from the maximum size of the get_headers (or get_blocks) message response, the logarithmic manner in which the requests are formulated, and the fact that block locators are generated relative to the top block. This limit can be reduced by setting
blockchain.reorganization_limit.
A: Initial block download is very inefficient. The node uses the "blocks first" approach of early satoshi design. As such it is subject to downloading costly batches of redundant blocks and must store blocks in order. Despite this limitation it performs comparably to other nodes when connected to one fast peer.
A: This came down to not delaying the release. The basic block download works quite well with 1 or 2 fast peers. It is a design goal to have the code clearly demonstrate not only how Bitcoin works, but how it has evolved. This can be seen in the configurable forks and network protocol levels. Having a basic blocks first session implementation is considered fundamental as more advanced modes require use of the
headersmessage which is not available in the lowest supported protocol level.