Performance
One of the common refrains about writing code functionally is that it comes with a performance cost. One of the major discussion points is around memory usage. In my previous life I wrote 3D graphics engines for the Playstation and Xbox (amongst other devices) and so I am no stranger to writing high-performance code and I have an instinctive feel for what is efficient or not.
There is no doubt that there is some performance overhead to working in the functional paradigm, but I would argue that we're a long way from the days of having to hand-write assembly, or custom memory managers, so that we can get the last bit of juice out of a processor.
This library is very much about trying to write code that can survive until tomorrow: more robust, easier to reason about, easier to maintain. Writing code functionally is a crutch to help programmers develop larger and more complex applications. And, because of that, there are trade-offs.
One common tenet of writing code (in any paradigm) is that one should not prematurely optimise. I strongly agree with that tenet. I have found that over the years of using this library and writing functionally that it's been super rare that I have hit performance issues, but when I have, it's been relatively easy to lift out the offending code and package it up into some lower level imperative code. Going the other way is much harder.
As more people start using this library with Unity (for writing games) you could argue that the slow loss of performance (i.e. many operations taking a little longer rather than a few taking a lot longer) is a problem. And so here I'm going to talk about some of the types and their trade-offs.
But, before going on to that I'd like to address the memory usage issue. Functional programming tends to create a lot of very short lived objects on the heap. Examples of this would be lambdas. When you use a lambda in a function you are incurring two allocations. At the end of their usage (micro or milliseconds later) those objects are dereferenced and ready to be collected by the garbage collector.
The .NET garbage collector is a generational garbage collector. What follows is a slightly hand-wavy description of generational garbage collectors (I have personally written one in C before, so it's not that hand-wavy, but it leaves out some of the special case stuff in the .NET GC which deals with large objects and the like).
When an object is allocated it's allocated in Gen 0. Allocation is fast, in fact faster than any other type of memory management system (except perhaps free-lists, but even then they're going to be close in performance), because other memory management systems need to look for some appropriate space, whereas a garbage collector can just take the head pointer and add the size of the memory required to create a new head. And so we should never worry about the cost of allocating lots of objects. In fact because generational garbage collectors allocate memory by just moving up through the heap linearly, often the thing you've allocated is next to other things your code needs and can help with CPU cache usage.
The problems come when Gen 0 runs out of space. This causes a garbage collection. The garbage collector sweeps Gen 0 looking for objects that have no references and then frees up the space. Clearly though that would lead to a load of holes in the address space and so it compacts the remaining (still referenced) objects and sets their generation to Gen 1. And so Gen 0 is smaller, Gen 1 is bigger. Eventually compaction of Gen 0 doesn't free up enough space and so and Gen 1 is compacted too, which relegates objects to Gen 2. Gen 2 objects are more of a problem. Gen 2 collection and compaction causes a pause in your application (where Gen 0 and Gen 1 don't), this is more of an issue with games where a consistent frame-rate is required.
Because functional programming allocates lots of small objects that are almost immediately thrown away (dereferenced) the expectation is that they'll mostly be hovering around Gen 0. You may be unlucky and a compaction happens mid-operation and some objects make it to Gen 1, but the reality is that short lived items don't make it to the problematic Gen 2. This is good.
And so we should be less concerned about the churn of objects in functional programming. That doesn't mean a generational compaction on any generation doesn't have a cost, it clearly has to do some work, it has to move memory around, but I would argue this is an acceptable cost for writing more reliable code. YMMV and you should profile this to see if it will cause you problems. I don't work in games any more, but I still have to consider the costs of many 1000s of users connecting to our web-servers for a hugely complex healthcare application, and to-date I've not had to change direction because of the GC.
The core optional types like Option<A>, Either<L, R>, etc. are all struct types. This means for most local operations they'll be passed around on the stack - which means they're not making into the generational garbage collector and can be released by the CLR just popping them off the stack. Value-types are often misunderstood to always be on the stack, but that's not the case, they can end up on the heap - but that's an aside, you can pretty much assume that if they're being used as local variables, being passed as arguments, or being returned from a method call then they're on the stack.
As much as possible I have tried to make the internals of these types both memory and CPU efficient. However, they rely on lambdas for matching. You can avoid that by casting, which is risky, but if you need the max performance this will work:
var opt = Some(123);
if(opt.IsSome)
{
var x = (int)opt;
}If you use that style a lot then you may as well not use Option or Either at all, because it's the opposite of the declarative style of functional programming and it's massively error prone (just like nullable references).
The optional delegate types are mostly the Try* types. These are defined as delegates that cause allocations all over the place. They're mostly short-lived for complex computations (like LINQ) but the initial Try* delegates that you create are headed straight to the heap and will hang around as long as you hold on to them. One useful feature however is that they memoise their operations, so when you run them once they cache the result and then won't run again. Because Try operations are usually wrapping risky IO code or whatever, you could see performance improvements from the built-in caching.
Just remember that you need to keep hold of the Try (as a reference) for it to memo the value.
For example:
Try<Seq<string>> ReadAllLines(string path) => () =>
File.ReadAllLines(path).ToSeq();
var lines = ReadAllLines("c:/text.txt");
var count = lines.Map(ls => ls.Count); // This invokes the ReadAllLines Try once
var first = lines.Map(ls => ls.Head); // This uses the cached valueTo ignore the memoisation, then you'd generate the ReadAllLines Try twice:
var count = ReadAllLines("c:/text.txt").Map(ls => ls.Count);
var first = ReadAllLines("c:/text.txt").Map(ls => ls.Head);Another interesting aspect of this is that lazy values that are never used don't do any work. Haskell has made a big deal about this over the years, and to an extent it's oversold to justify lazy-everything in Haskell.
To give a simple view on what I mean you could imagine something like a downloader process, that has a Lst of URLs to download from.
Try<string> Download(string url) =>
...;
Try<Lst<string>> DownloadMany(Lst<string> urls)
urls.Map(Download).Sequence();Lst isn't lazy and so calling Map on the Lst<string> will first project Lst<string> to a Lst<Try<string>>. But nothing is yet being downloaded. Then calling Sequence will flip Lst<Try<string>> to Try<Lst<string>>, which will kick of the downloading one-by-one. If any of the downloads fail then the rest are not downloaded.
It may not translate into an obvious solution, it is just a trivial example, but it shows how you can leverage the laziness to write very declarative code without incurring the additional processing costs that might come from a more naive solution.
Another trick to avoid the additional cost of using the delegate based types is to convert away from them quickly. Try, as mentioned above, is usually there to wrap up calls to things that could throw exceptions, which is often IO or calls to BCL functions that don't consider returning error values a good approach. If you're spending most of your time writing nice purely functional code, then you could wrap the risky bits in IO and then just call:
var opt = ReadAllLines("c:/text.txt").ToOption();Or, ToEither(), ToValidation(), etc. This then captures the exceptional code, but then switches back to the struct types for everything else.
Some of the collection types in language-ext use a self-balancing AVL tree as its backing store. They are:
Set<A>Map<A, B>Lst<A>
Immutable AVL trees work by only updating the nodes in the tree that are directly affected by an insertion or deletion.
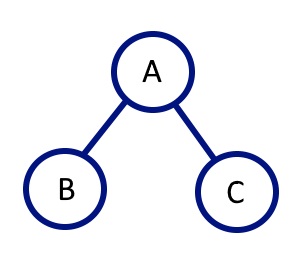
If you have a root A and two child nodes to the left and right of B and C respectively then adding D to the tree (which should be assigned to the right of C) will create a new C with the updated reference to D and then create a new A with an updated reference to the new C. The B branch is unaffected.
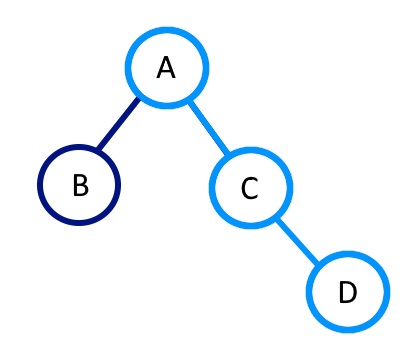
This means that the total cost of insertion or removal is n allocations where n is the depth of the tree (it's a self balancing tree so it's a function of the number of items in the tree). And so there is some cost to transforming an immutable tree structure, but it's not true that an entirely new tree needs to be built for each operation.
Iterating and reading of any of the immutable AVL backed structures will be as fast as doing so with the mutable versions in the BCL (Dictionary, SortedDictionary, HashSet, etc.)
Note also that that all of these AVL backed types can be initialised with an IEnumerable of any flavour and the initial tree will be built (in the constructor) with mutable tree that becomes locked (immutable) before you get the reference back from the constructor. This allows for a very efficient instantiation of the relevant collection.
HashMap<K, V> and HashSet<A> are, by far, the most efficient key based collection types. Internally, they use the state-of-the-art Compressed Hash Array Map Trie (CHAMP) data structure. It brings some significant performance gains over Microsoft's System.Collections.Immutable.ImmutableDictionary<K, V> which is the closest type to the lang-ext HashMap.
| Type | 10,000 Add operations |
10,000 random access operations | Enumeration of a 10,000 item collection |
|---|---|---|---|
HashMap<K, V> |
200 ns / op |
1 ns / op |
1 ns / op |
ImmutableDictionary<T> |
700 ns / op |
1 ns / op |
100 ns / op |
| Type | 100,000 Add operations |
100,000 random access operations | Enumeration of a 100,000 item collection |
|---|---|---|---|
HashMap<K, V> |
500 ns / op |
80 ns / op |
100 ns / op |
ImmutableDictionary<T> |
1160 ns / op |
60 ns / op |
180 ns / op |
| Type | 1,000,000 Add operations |
1,000,000 random access operations | Enumeration of a 1,000,000 item collection |
|---|---|---|---|
HashMap<K, V> |
651 ns / op |
72 ns / op |
63 ns / op |
ImmutableDictionary<T> |
1402 ns / op |
93 ns / op |
204 ns / op |
The closest type in the BCL is Dictionary<T> - which still outperforms the HashMap type, but I think you can see we're looking at high performance types here. It is especially the case when the collection sizes are below the 65,536 range. They're fast at all sizes, but has outstanding performance for what is the most common use-cases. Even for the heavier and most difficult use case (millions of add operations), we're still seeing 1.5 million operations per second.
You should always use Seq<A> for the maximum performance. The only time that doesn't make sense is if you need to transform a list by setting or inserting an element at an index which isn't 0 or the end of the collection. Because Lst<A> uses an immutable AVL tree behind the scenes insertion can be done without incurring a big cost (see the previous section). However, Seq<A> uses a contiguous array that can only be appended or prepended to. This is great for cache efficiency when iterating over a large number of items (which is where AVL trees suffer).
Adding new items to a Seq<A> can cause the array to fill up and so when that happens it generates a new array, double the size, and copies the old array to the new - leaving enough room to grow into. This obviously has a cost to it, but I'd say this is the accepted method of doing a list in .NET as this is the way that List<T> works in the BCL. If you have two separate references to the same Seq<A>:
var x = Seq(1,2,3,4,5);
var y = x;... and append or prepend items to both references:
x = 0.Cons(x);
y = 1.Cons(y);... then the second append or prepend will clone the Seq (maintaining the immutable integrity of the collection).
After that cloning, future operations on either Seq will have their own internal arrays, no sharing. This can be seen as branching of the structures.
In terms of outright performance List<T> from the .NET BCL (which isn't thread-safe) is about twice at fast at adding items (if you use Cons for the Seq<A>, three times if you use Add). Cons is super-slow with List<T> though, I assume it's not optimised for this, so we won't hold it against it, although I suspect most people don't realise how poor the Insert performance is for List<T>
System.Collections.Generic.List<T>cons equivalent isInsert(0, x).
Below is a table that shows the relative performance per-operation for each type.
| Type | Add |
Cons | Insert(0,x)
|
Enumeration |
|---|---|---|---|
Seq<A> |
29.5 ns / op |
20 ns / op |
10.0 ns / op |
List<T> |
11 ns / op |
10320 ns / op |
16.1 ns / op |
This is pretty amazing for an immutable, thread-safe, lock-free, type that can support appending and prepending with very similar performance benefits to List<T> as well as supports at-most-once lazy streaming. We're still looking at 33-50 million write operations per-second and enumeration that's faster than the mutable counterpart.
One thing to note is that Seq<A> also supports laziness. If you're enumerating a lazy sequence then you're looking at 54 ns / op, or about 18.5 million operations per-second. Once the lazy stream has been enumerated once then it is cached and will have the same performance as the table above.
LINQ gets expanded out into a series of Select, SelectMany, and Where invocations, each require one or more lambdas to do the computation for each line of the LINQ expression.
And so the performance minded programmer might want to be aware of that. You may find more optimal ways of doing that if necessary.
LINQ can be particularly inefficient for sequences, because each from line becomes a Bind operation and often one line might return a single item sequence. You could use a series of nested foreach loops for maximum performance, but again you lose the declarative aspects and introduce greater opportunity for error.
This is often overlooked. Working with immutable data types often means a massive reduction in synchronising and/or deep-cloning of objects when they're being shared between multiple threads. If you have a big static data-set (which can often be the case with games that have lots of level data for example) then those values can be passed around multiple threads without any concern.
Other techniques are to have a reference to the state of the world at the start of a frame. By holding a reference to a World game-state object, you have effectively taken a snapshot at that point in time, as so that can then be given to a thread to work on the assumptions that were true at the start of the frame, this can lead to an improvement in determinism and general performance for those threads.
For state that needs mutating, each thread could instead mutate its own version and then use the Patch system built into language-ext for multiple thread conflict resolution, and so again you could have many threads working on data that are then resolved at the end of a frame.
Often I think the performance aspect of functional programming is overstated. I left the games industry in 2005 and even back then the gameplay teams were using interpreted Lua to control game AI. I think it'd be relatively uncontroversial to state that you could use the functional paradigm for the main gameplay and game control loops whilst perhaps having a more aggressive strategy for anything lower level.
As always though: your mileage might vary and you should profile your code (and never prematurely optimise)