


Gorgonia is a library that helps facilitate machine learning in Go. Write and evaluate mathematical equations involving multidimensional arrays easily. If this sounds like Theano or TensorFlow, it's because the idea is quite similar. Specifically, the library is pretty low-level, like Theano, but has higher goals like Tensorflow.
Gorgonia:
- Can perform automatic differentiation
- Can perform symbolic differentiation
- Can perform gradient descent optimizations
- Can perform numerical stabilization
- Provides a number of convenience functions to help create neural networks
- Is fairly quick (comparable to Theano and Tensorflow's speed)
- Supports CUDA/GPGPU computation (OpenCL not yet supported, send a pull request)
- Will support distributed computing
The main reason to use Gorgonia is developer comfort. If you're using a Go stack extensively, now you have access to the ability to create production-ready machine learning systems in an environment that you are already familiar and comfortable with.
ML/AI at large is usually split into two stages: the experimental stage where one builds various models, test and retest; and the deployed state where a model after being tested and played with, is deployed. This necessitate different roles like data scientist and data engineer.
Typically the two phases have different tools: Python/Lua (using Theano, Torch, etc) is commonly used for the experimental stage, and then the model is rewritten in some more performant language like C++ (using dlib, mlpack etc). Of course, nowadays the gap is closing and people frequently share the tools between them. Tensorflow is one such tool that bridges the gap.
Gorgonia aims to do the same, but for the Go environment. Gorgonia is currently fairly performant - its speeds are comparable to Theano's and Tensorflow's (official benchmarks haven't yet been done because of an existing CUDA bug in Gorgonia; and also the implementations may differ slightly so an exact like-for-like model is hard to compare).
The package is go-gettable: go get -u github.com/chewxy/gorgonia.
There are very few dependencies that Gorgonia uses - and they're all pretty stable, so as of now there isn't a need for vendoring tools. These are the list of external packages that Gorgonia calls, ranked in order of reliance that this package has (subpackages are omitted):
| Package | Used For | Vitality | Notes | Licence |
|---|---|---|---|---|
| gonum/graph | Sorting *ExprGraph |
Vital. Removal means Gorgonia will not work | Development of Gorgonia is committed to keeping up with the most updated version | gonum license (MIT/BSD-like) |
| gonum/blas | Tensor subpackage linear algebra operations | Vital. Removal means Gorgonial will not work | Development of Gorgonia is committed to keeping up with the most updated version | gonum license (MIT/BSD-like) |
| cu | CUDA drivers | Needed for CUDA operations | Same maintainer as Gorgonia | MIT/BSD-like |
| math32 | float32 operations |
Can be replaced by float32(math.XXX(float64(x))) |
Same maintainer as Gorgonia, same API as the built in math package |
MIT/BSD-like |
| hm | Type system for Gorgonia | Gorgonia's graphs are pretty tightly coupled with the type system | Same maintainer as Gorgonia | MIT/BSD-like |
| vecf64 | optimized []float64 operations |
Can be generated in the tensor/genlib package. However, plenty of optimizations have been made/will be made |
Same maintainer as Gorgonia | MIT/BSD-like |
| vecf32 | optimized []float32 operations |
Can be generated in the tensor/genlib package. However, plenty of optimizations have been made/will be made |
Same maintainer as Gorgonia | MIT/BSD-like |
| set | Various set operations | Can be easily replaced | Stable API for the past 1 year | set licence (MIT/BSD-like) |
| gographviz | Used for printing graphs | Graph printing is only vital to debugging. Gorgonia can survive without, but with a major (but arguably nonvital) feature loss | Stable API for the past 1 year | gographviz licence (Apache 2.0) |
| rng | Used to implement helper functions to generate initial weights | Can be replaced fairly easily. Gorgonia can do without the convenience functions too | rng licence (Apache 2.0) | |
| errors | Error wrapping | Gorgonia won't die without it. In fact Gorgonia has also used goerrors/errors in the past. | Stable API for the past 6 months | errors licence (MIT/BSD-like) |
| gonum/matrix | Compatibility between Tensor and Gonum's Matrix |
Development of Gorgonia is committed to keeping up with the most updated version | gonum license (MIT/BSD-like) | |
| testify/assert | Testing | Can do without but will be a massive pain in the ass to test | testify licence (MIT/BSD-like) |
Gorgonia's project has a mailing list, as well as a Twitter account. Official updates and announcements will be posted to those two sites.
Gorgonia works by creating a computation graph, and then executing it. Think of it as a programming language, but is limited to mathematical functions. In fact this is the dominant paradigm that the user should be used to thinking about. The computation graph is an AST.
Microsoft's CNTK, with its BrainScript, is perhaps the best at exemplifying the idea that building of a computation graph and running of the computation graphs are different things, and that the user should be in different modes of thoughts when going about them.
Whilst Gorgonia's implementation doesn't enforce the separation of thought as far as CNTK's BrainScript does, the syntax does help a little bit.
Here's an example - say you want to define a math expression z = x + y. Here's how you'd do it:
package main
import (
"fmt"
"log"
. "github.com/chewxy/gorgonia"
)
func main() {
g := NewGraph()
var x, y, z *Node
var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y)
if err != nil {
log.Fatal(err)
}
// compile into a program
prog, locMap, err := Compile(g)
if err != nil {
log.Fatal(err)
}
// create a VM to run the program on
machine := NewTapeMachine(prog, locMap)
// set initial values then run
Let(x, 2.0)
Let(y, 2.5)
if machine.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("%v", z.Value())
// Output: 4.5
}You might note that it's a little more verbose than other packages of similar nature. For example, instead of compiling to a callable function, Gorgonia specifically compiles into a *program which requires a *TapeMachine to run. It also requires manual a Let(...) call.
The author would like to contend that this is a Good Thing - to shift one's thinking to a machine-based thinking. It helps a lot in figuring out where things might go wrong.
There are two VMs in the current version of Gorgonia:
TapeMachineLispMachine
They function differently and take different inputs. The TapeMachine is useful for executing expressions that are generally static (that is to say the computation graph does not change). Due to its static nature, the TapeMachine is good for running expressions that are compiled-once-run-many-times (such as linear regression, SVM and the like).
The LispMachine on the other hand was designed to take a graph as an input, and executes directly on the nodes of the graph. If the graph change, simply create a new lightweight LispMachine to execute it on. The LispMachine is suitable for tasks such as creating recurrent neural networks without a fixed size.
Prior to release of Gorgonia, there was a third VM - a stack based VM that is similar to TapeMachine but deals with artificial gradients better. It may see light of day again, once this author has managed to fix all the kinks.
Gorgonia performs both symbolic and automatic differentiation. There are subtle differences between the two processes. The author has found that it's best to think of it this way - Automatic differentiation is differentiation that happens at runtime, concurrently with the execution of the graph, while symbolic differentiation is differentiation that happens during the compilation phase.
Runtime of course, refers to the execution of the expression graph, not the program's actual runtime.
With the introduction to the two VMs, it's easy to see how Gorgonia can perform both symbolic and automatic differentiation. Using the same example as above, the reader should note that there was no differentiation done. Instead, let's try with a LispMachine:
package main
import (
"fmt"
"log"
. "github.com/chewxy/gorgonia"
)
func main() {
g := NewGraph()
var x, y, z *Node
var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y)
if err != nil {
log.Fatal(err)
}
// set initial values then run
Let(x, 2.0)
Let(y, 2.5)
// by default, LispMachine performs forward mode and backwards mode execution
m := NewLispMachine(g)
if m.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("z: %v\n", z.Value())
xgrad, err := x.Grad()
if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dx: %v\n", xgrad)
ygrad, err := y.Grad()
if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dy: %v\n", ygrad)
// Output:
// z: 4.5
// dz/dx: 1
// dz/dy: 1
}Of course, Gorgonia also supports the more traditional symbolic differentiation like in Theano:
package main
import (
"fmt"
"log"
. "github.com/chewxy/gorgonia"
)
func main() {
g := NewGraph()
var x, y, z *Node
var err error
// define the expression
x = NewScalar(g, Float64, WithName("x"))
y = NewScalar(g, Float64, WithName("y"))
z, err = Add(x, y)
if err != nil {
log.Fatal(err)
}
// symbolically differentiate z with regards to x and y
// this adds the gradient nodes to the graph g
var grads Nodes
grads, err = Grad(z, x, y)
if err != nil {
log.Fatal(err)
}
// compile into a program
prog, locMap, err := Compile(g)
if err != nil {
log.Fatal(err)
}
// create a VM to run the program on
machine := NewTapeMachine(prog, locMap)
// set initial values then run
Let(x, 2.0)
Let(y, 2.5)
if machine.RunAll() != nil {
log.Fatal(err)
}
fmt.Printf("z: %v\n", z.Value())
xgrad, err := x.Grad()
if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dx: %v | %v\n", xgrad, grads[0])
ygrad, err := y.Grad()
if err != nil {
log.Fatal(err)
}
fmt.Printf("dz/dy: %v | %v\n", ygrad, grads[1])
// Output:
// z: 4.5
// dz/dx: 1 | 1
// dz/dy: 1 | 1
}Currently Gorgonia only performs backwards mode automatic differentiation (aka backpropagation), although one may observe the vestiges of an older version which supported forwards mode differentiation in the existence of *dualValue. It may return in the future.
A lot has been said about a computation graph or an expression graph. But what is it exactly? Think of it as an AST for the math expression that you want. Here's the graph for the examples (but with a vector and a scalar addition instead) above:
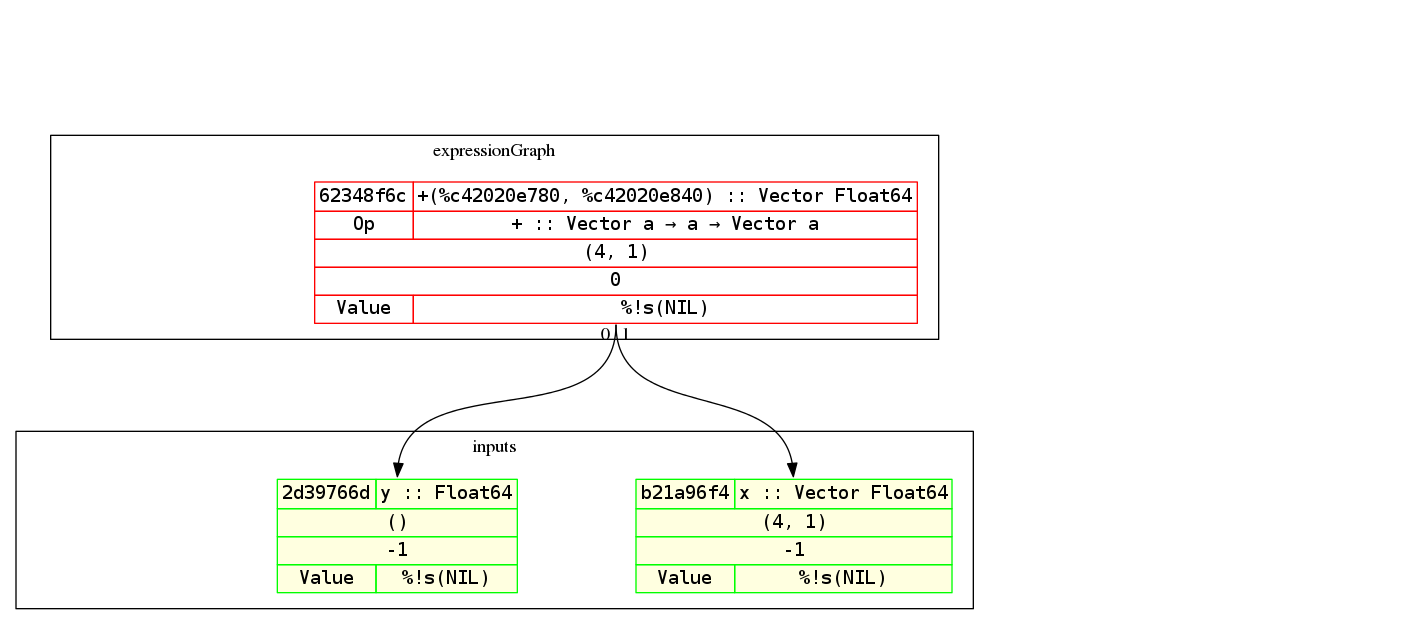
By the way, Gorgonia comes with nice-ish graph printing abilities. Here's an example of a graph of the equation y = x² and its derivation:
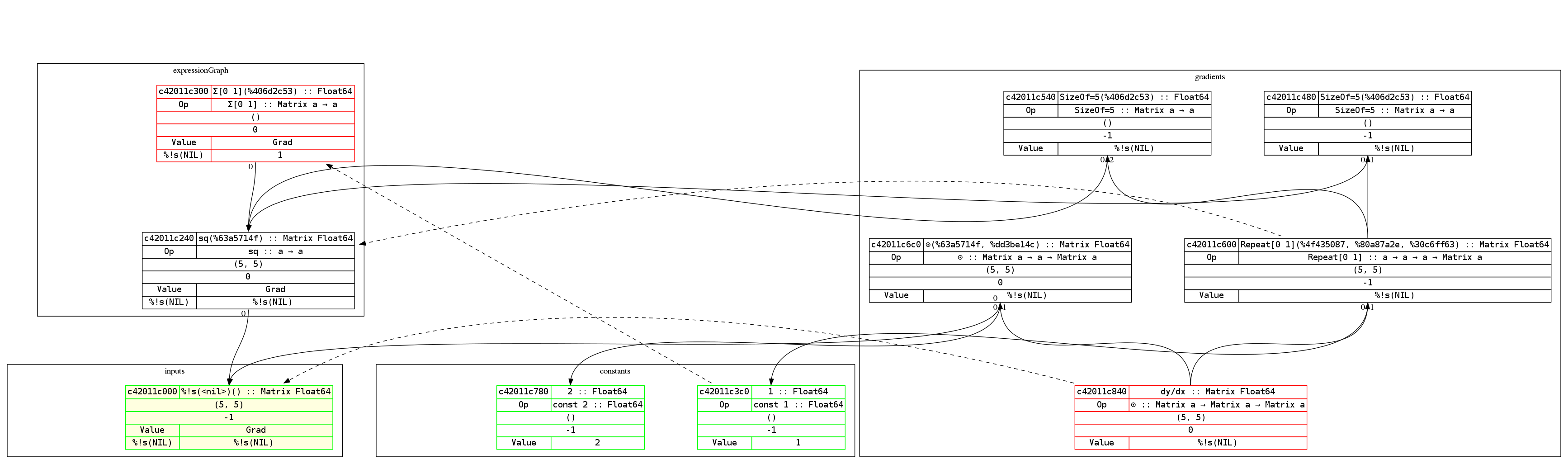
To read the graph is easy. The expression builds from bottom up, while the derivations build from top down. This way the derivative of each node is roughly on the same level.
Red-outlined nodes indicate that it's a root node. Green outlined nodes indicate that they're a leaf node. Nodes with a yellow background indicate that it's an input node. The dotted arrows indicate which node is the gradient node for the pointed-to node.
Concretely, it says that c42011e840 (dy/dx) is the gradient node of the input c42011e000 (which is x).
A Node is rendered thusly:
| ID | node name :: type |
| OP* | op name :: type |
| shape | |
| compilation metadata | |
| Value† | Gradient |
- If it's an input node, then the Op row will not show up.
- If there are no Values bound to the node, it will show up as NIL. However, when there are values and gradients, it will try to as best as possible display the values bound to the node.
Gorgonia comes with CUDA support out of the box. However, usage is specialized. To use CUDA, you must build your application with the build tag cuda, like so:
go build -tags='cuda' .
Furthermore, there are some additional requirements:
- CUDA toolkit 8.0 is required. Installing this installs the
nvcccompiler which is required to run your code with CUDA go install github.com/chewxy/gorgonia/cmd/cudagen. This installs thecudagenprogram. Runningcudagenwill generate the relevant CUDA related code for Gorgonia.- The CUDA ops must be manually enabled in your code with the
UseCudaForoption. runtime.LockOSThread()must be called in the main function where the VM is running. CUDA requires thread affinity, and therefore the OS thread must be locked.
So how do we use CUDA? Say we've got a file, main.go:
import (
"fmt"
"log"
"runtime"
T "github.com/chewxy/gorgonia"
"github.com/chewxy/gorgonia/tensor"
)
func main() {
g := T.NewGraph()
x := T.NewMatrix(g, T.Float32, T.WithName("x"), T.WithShape(100, 100))
y := T.NewMatrix(g, T.Float32, T.WithName("y"), T.WithShape(100, 100))
xpy := T.Must(T.Add(x, y))
xpy2 := T.Must(T.Tanh(xpy))
prog, locMap, _ := T.Compile(g)
m := T.NewTapeMachine(prog, locMap, T.UseCudaFor("tanh"))
T.Let(x, tensor.New(tensor.WithShape(100, 100), tensor.WithBacking(tensor.Random(tensor.Float32, 100*100))))
T.Let(y, tensor.New(tensor.WithShape(100, 100), tensor.WithBacking(tensor.Random(tensor.Float32, 100*100))))
runtime.LockOSThread()
for i := 0; i < 1000; i++ {
if err := m.RunAll(); err != nil {
log.Fatalf("iteration: %d. Err: %v", i, err)
}
}
runtime.UnlockOSThread()
fmt.Printf("%1.1f", xpy2.Value())
}If this is run normally:
go run main.go
CUDA will not be used.
If the program is to be run using CUDA, then this must be invoked:
go run -tags='cuda'
And even so, only the tanh function uses CUDA.
The main reasons for having such complicated requirements for using CUDA is quite simply performance related. As Dave Cheney famously wrote, cgo is not Go. To use CUDA, cgo is unfortunately required. And to use cgo, plenty of tradeoffs need to be made.
Therefore the solution was to nestle the CUDA related code in a build tag, cuda. That way by default no cgo is used (well, kind-of - you could still use cblas or blase).
The reason for requiring CUDA toolkit 8.0 is because there are many CUDA Compute Capabilities, and generating code for them all would yield a huge binary for no real good reason. Rather, users are encouraged to compile for their specific Compute Capabilities.
Lastly, the reason for requiring an explicit specification to use CUDA for which ops is due to the cost of cgo calls. Additional work is being done currently to implement batched cgo calls, but until that is done, the solution is keyhole "upgrade" of certain ops
As of now, only the very basic simple ops support CUDA:
Elementwise unary operations:
abssincosexplnlog2negsquaresqrtinv(reciprocal of a number)cubetanhsigmoidlog1pexpm1softplus
Elementwise binary operations - only arithmetic operations support CUDA:
addsubmuldivpow
From a lot of profiling of this author's personal projects, the ones that really matter are tanh, sigmoid, expm1, exp and cube - basically the activation functions. The other operations do work fine with MKL+AVX and aren't the major cause of slowness in a neural network
In a trivial benchmark, careful use of CUDA (in this case, used to call sigmoid) shows impressive improvements over non-CUDA code (bearing in mind the CUDA kernel is extremely naive and not optimized):
BenchmarkOneMilCUDA-8 300 3348711 ns/op
BenchmarkOneMil-8 50 33169036 ns/op
Gorgonia's API is as of right now, not considered stable. It will be stable from version 1.0 forwards.
1.0 is defined by when the test coverage hits 90%, and the relevant Tensor methods have been completed.
Here are the goals for Gorgonia, sorted by importance
- 80+% test coverage. Current coverage is 50% for Gorgonia and 80% for the
tensor. - More advanced operations (like
einsum). The current Tensor operators are pretty primitive. - TravisCI for this package.
- Coveralls for this package.
- Clean out the tests. The tests were the results of many years of accumulation. It'd be nice to refactor them out nicely. Use table driven tests where possible.
- Improve performance especially re: allocation, minimize impact of type system.
- Improve Op extensibility by exposing/changing the Op interface to be all exported, and not a mix of exported and unexported methods (Alternatively, create a
ComposeOp type for extensibility). This way everyone can make their own customOps. - Refactor the CuBLAS package as well as the Blase package to follow in vein of the CUDA implementation.
- Distributed computing. The ability to spread jobs out across multiple machines and communicating with each other has been attempted at least 3 times, but failed each time.
- Better documentation on why certain decisions were made, and the design of Gorgonia in general.
- Higher order derivative optimization algorithms (LBFGS comes to mind)
- Derivative-free optimization algorithms
The primary goal for Gorgonia is to be a highly performant machine learning/graph computation-based library that can scale across multiple machines. It should bring the appeal of Go (simple compilation and deployment process) to the ML world. It's a long way from there currently, however, the baby steps are already there.
The secondary goal for Gorgonia is to provide a platform for exploration for non-standard deep-learning and neural network related things. This includes things like neo-hebbian learning, corner-cutting algorithms, evolutionary algorithms and the like.
Obviously since you are most probably reading this on Github, Github will form the major part of the workflow for contributing to this package.
See also: CONTRIBUTING.md
All contributions are welcome. However, there is a new class of contributor, called Significant Contributors.
A Significant Contributor is one who has shown deep understanding of how the library works and/or its environs. Here are examples of what constitutes a Significant Contribution:
- Wrote significant amounts of documentation pertaining to why/the mechanics of particular functions/methods and how the different parts affect one another
- Wrote code, and tests around the more intricately connected parts of Gorgonia
- Wrote code and tests, and have at least 5 pull requests accepted
- Provided expert analysis on parts of the package (for example, you may be a floating point operations expert who optimized one function)
- Answered at least 10 support questions.
Significant Contributors list will be updated once a month (if anyone even uses Gorgonia that is).
The best way of support right now is to open a ticket on Github.
The answer to this is simple - the design of the package uses CUDA in a particular way: specifically, a CUDA device and context is tied to a VM, instead of at the package level. This means for every VM created, a different CUDA context is created per device per VM. This way all the operations will play nicely with other applications that may be using CUDA (this needs to be stress-tested, however).
The CUDA contexts are only destroyed when the VM gets garbage collected (with the help of a finalizer function). In the tests, about 100 VMs get created, and garbage collection for the most part can be considered random. This leads to cases where the GPU runs out of memory as there are too many contexts being used.
Therefore at the end of any tests that may use GPU, a runtime.GC() call is made to force garbage collection, freeing GPU memories.
In production, one is unlikely to start that many VMs, therefore it's not really a problem. If there is, open a ticket on Github, and we'll look into adding a Finish() method for the VMs.
Gorgonia is licenced under a variant of Apache 2.0. It's for all intents and purposes the same as the Apache 2.0 Licence, with the exception of not being able to commercially profit directly from the package unless you're a Significant Contributor (for example, providing commercial support for the package). It's perfectly fine to profit directly from a derivative of Gorgonia (for example, if you use Gorgonia as a library in your product)
Everyone is still allowed to use Gorgonia for commercial purposes (example: using it in a software for your business).
These are the packages and libraries which inspired and were adapted from in the process of writing Gorgonia (the Go packages that were used were already declared above):
| Source | How it's Used | Licence |
|---|---|---|
| Numpy | Inspired large portions. Directly adapted algorithms for a few methods (explicitly labelled in the docs) | MIT/BSD-like. Numpy Licence |
| Theano | Inspired large portions. (Unsure: number of directly adapted algorithms) | MIT/BSD-like Theano's licence |