Caching
There are two cache mechanisms MaidSafe-Vault will stick with, based on the data type.
As illustrated in this diagram :
The cache will be stored along the path however long that is(the closest vault to the client that getting high-demand request). This caching mechanism only works for the never-changing data, that does not matter if there are more copies as the data is always correct.
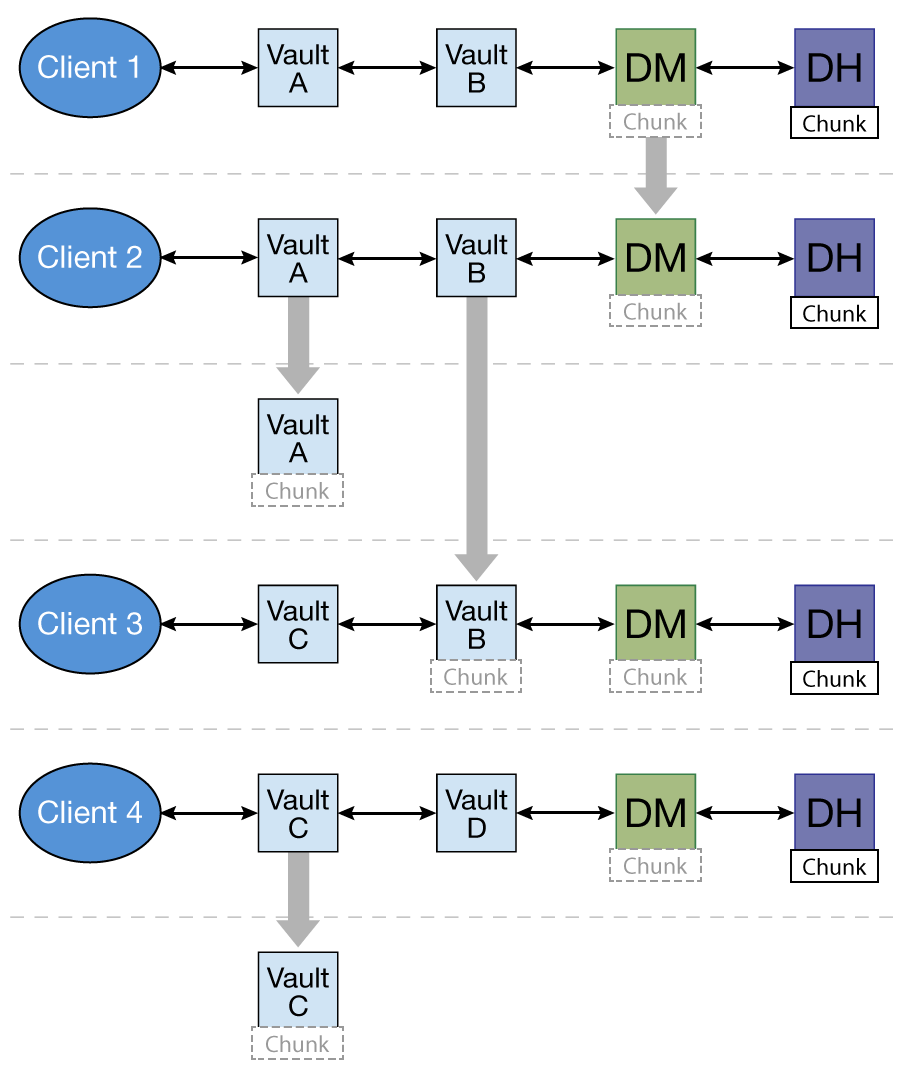
As illustrated in this diagram :

This caching mechanism is suitable for high demand data that we need to retain control of where it is located, ie. it's not self checking data like . The DM (vault acts as Data Manager for the data) decides the caching radius based on the demanding, and do so via a counter. When DM decides to expand the cache area by 1, it means that close nodes get a copy (16 copies now). If they are still burdened with requests, they cache forward 1 and send back to the originator (1 + 1), this is recursive the further it goes. So cache level 3 will have count of 3 and, if an edge vault gets swamped he caches forward with a count of 4 and sends the ++counter back to the closest node he has. That node then ++ again and so on back to the close group.. So the originator(DM) knows how far these chunks or versions or metadata have gone.
During sync, both cached data and count will get synchronized.
If data request becomes less frequent then this data leaves the vault cache and is not synced. Thereby the determinism goes both ways, cached from behind cause it's busy and deleted cause it's not. The Delete is why the originator needs that count sent, so he can send a Delete(x) where x is the depth and each node passes this on decrementing the count as it goes. This way the data (deterministically) can be found and removed.