Created using vue ui and Boilerplate template (which I created).
Installed vue-cli-plugin-vuetify via vue ui tool. Default configuration.
Created empty voice-poc repo on github.
git remote add origin https://github.com/captainnurple/voice-poc.git
git branch -M master
git push -u origin master
git add .
git commit -m "Initial commit."
git push
Create a new site on Netlify via Import Existing Project and grabbing it from github (just use default settings). Netlify will run the initial deploy and you can verify it worked.
suppress build dev spam in vue.config.js via
devServer: { // suppresses the massive webpack.Progress terminal spam when running dev server
progress: false
}
Multiple layouts:
- Initialize layouts in
main.jsand add the vue files in src/layouts - Set up routes in router.js, with a meta variable denoting whether it's a logged-in view or not.
- Implement dynamic layout switching in
App.vuebased on what router sets tothis.$route.meta.layout; - The above will require your layout views, Landing view (at least)
- Will throw errors if copying from other project until you set up Netlify Identity, so let's do that next...
Run npm add netlify-identity-widget on terminal.
Copy over store files from boilerplate and replace.
Enable Identity on your Netlify project and paste in the API endpoint in your init code (currently in Landing.vue).
Deploy and create a user on the deployed site (I think you have to do it this way before you can use local dev sign-in). Verify your email and you should be able to log in now on the landing page.
If you didn't missing anything you should now be able to inspect the vuex user object from the Landing page to check login status.
Add the following to your router:
{
path: '/dashboard',
name: 'Dashboard',
meta: {
layout: "logged_in_layout",
requiresAuth: true
},
component: () => import(/* webpackChunkName: "dashboard" */ '../views/Dashboard.vue'),
},
copy over Dashboard.vue and loggedInLayout index.vue. You should now see the HelloWorld landing page on the dashboard link. And if you log out you should be redirected to the Landing Page.
We don't have nav guard in though yet. So copy over the navigation guard code into the router file now. (make sure to also include import store from '@/store' at top)
Now you should be redirected to the Landing Page if you attempt direct navigation w/o being logged in.
Great milestone! We now have multiple layouts enabled. Netlify identity signup. And conditional content displayed based on whether or not user is signed in.
Next step: Add uppy widget and pull the transloading template ID via Netlify API call that only returns if the user has a valid logged in session.
**Install netlify CLI if you haven't yet.
**
npm install netlify-cli -g
Create (if doesn't exist) netlify.toml file with
[build]
functions="/functions"
Create (if doesn't exit) directory /functions in root. This is where Netlify functions go.
See sample syntax in /functions/hello.js
Make sure you've saved all the files lol. Then you should be able to hit GET http://localhost:8888/.netlify/functions/hello in apitests.http using the REST Client plugin
Go to "Build & Deploy > Environment variables" in your Netlify dashboard.
Create:
- TRANSLOADIT_KEY
- TRANSLOADIT_TEMPLATE_ID
You'll access those in code via process.env.{KEY_NAME}
Make sure you link your Netlify site so the ENV vars are injected at dev time. Just use netlify link on command line
Now you can check for a user object within the function, and only return the keys for logged-in users. (This object only exists w/in Netlify functions if there is a logged-in Identity user)
Test on command line via, e.g.
netlify functions:invoke uploadKey --identity
netlify functions:invoke uploadKey --no-identity
You should now be able to conditionally provide the upload/transloadit keys at runtime only to logged-in users. Woohoo!
Netlify Identity makes it very easy to verify that a user is validly logged in. Just check for a user object! Per the forum answer linked below, you can verify a logged in user via:
exports.handler = async (event, context) => {
if (context?.clientContext?.user) {
// process the function
} else {
return {
statusCode: 401,
body: JSON.stringify('Unauthorized')
}
}
}
See Approach 3: Using authorisation here: https://answers.netlify.com/t/how-to-apply-access-control-for-netlify-functions/46519
And also docs on the user object etc here: https://docs.netlify.com/functions/functions-and-identity/
This is great! Because it means that from within our Netlify Function we just pull the user object at time of request and we can 1) Verify that we have a logged in user, and 2) Extract the userID object from the user object (I believe via user.id) to know who we're dealing with! (side-side note: the Gotrue API looks like there's email in the user object too.)
Login to Fauna and click "Create Database."
Name your database, and then select GraphQL on the sidebar.
Locally, create a database folder with a schema in it db/schema.gql with the following schema (modify as necessary):
type User {
netlifyID: ID! # ! means can't return null
email: String!
}
After importing your schema, test the following GraphQL query to ensure functionality:
# Write your query or mutation here
mutation {
createUser(data: {netlifyID: 1, email:"bob"}) {
netlifyID
email
}
}
If it worked, you should see the new entry in your Collections (as an entry in a new "User" collection). Hooray! Go ahead and delete that entry, and now we can wire up the new user signup hooks.
We can now bring Netlify fuctions together with FaunaDB, using Identity Function hooks.
Create your signup hook in functions/identity-signup.js. This will get called every time a new user signs up via Identity.
See discussion here
Test via the following:
exports.handler = async (event) => {
const { user } = JSON.parse(event.body);
console.log(JSON.stringify(user, null, 2));
return {
statusCode: 200,
// body: JSON.stringify({ app_metadata: { roles: ["user"] } }), // Optional metadata args; see docs
};
};
Commit and push to test live.
If everything is working, you should be able to register a new user, and AFTER clicking the confirmation email, the Netlify function log should output the user object for that new signup! (To view the function log you go to the Functions page and select the identity signup function).
Netlify can now include anything you npm install in root, so add the following:
npm i node-fetch@2.6.2
(node-fetch v3 requires different syntax so avoid it for now)
Navigate to your database in Fauna and go to the "Security" tab on the left. Select create a new key, and select "Server" key in the Role dropdown. Give it a name and the Key will appear.
Copy the key and go back over to Netlify.
Go to Site Settings > Build & Deploy > Environment > Edit Variables
Add an environment variable called FAUNA_SERVER_KEY and paste in the Key you copied above.
(Note for local dev you have to kill and restart netlify dev to update these keys I think.)
Now modify identity-signup as follows:
const fetch = require("node-fetch");
exports.handler = async (event) => {
const { user } = JSON.parse(event.body);
console.log(JSON.stringify(user, null, 2));
const netlifyID = user.id;
const email = user.email;
const response = await fetch("https://graphql.us.fauna.com/graphql", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.FAUNA_SERVER_KEY}`,
},
body: JSON.stringify({
query: `
mutation ($netlifyID: ID! $email: String!) {
createUser(data: {netlifyID: $netlifyID, email: $email}) {
netlifyID
email
}
}
`,
variables: {
netlifyID,
email,
},
}),
})
.then((res) => res.json())
.catch((err) => console.error(JSON.stringify(err, null, 2)));
console.log(JSON.stringify(response, null, 2));
return {
statusCode: 200,
// body: JSON.stringify({ app_metadata: { roles: ["user"] } }), // Optional metadata args; see docs
};
};
Depending on Fauna region you may need to modify endpoint.
Don't forget to commit and push!!!
Now run through a test user signup. If all goes well, you should see a new entry in your FaunaDB containing that user's email and netlifyID!
Woohoo!!
Next step: fix landing page login wiring. Set up logged-in dashboard.
This time the Dashboard will be simpler. I can keep the general template for future expansion. But for now the dashboard should be simplified to focus on the file upload interface.
Get the right hooks for logged-in/out UI.
Need to bind to Identity events in all the relevant places. Possibly the best place is in the layout templates themselves. Essentially need to check for a persisted logged in cookie (Identity itself checks for this) and if it's there go ahead and load it into vuex. Otherwise need to bind to login event and update all requisite UI elements accordingly. And of course Vue bindings are a core design principle here so it shouldn't be too difficult.
See current implementation in voice-v2 for an approach that seems to work and successfully load logged-in user into vuex store even after page close/refresh (I think I really worked it out pretty well in that).
Remember: security in depth. Build in security checks/verifications at multiple layers so that even if e.g. a user modifies the logged in state to true they still can't see anything valuable on those pages.
NOTE: This actually seems to be working now. I think I copied over a bunch of boilerplate code and nav guards already, and it looks like vuex store is being properly set/unset at login. So for now I'm going to move on. Can test more later. I think there might be an edge case where the landing page UI is still acting like you're not logged in when you are, but I need to test.
Ref: https://uppy.io/docs/vue/
npm install @uppy/vue
npm install @uppy/robodog
lollll ok it's working with hideously ugly code
NEED TO REFACTOR WRITER DASHBOARD
I'm fetching the Transloadit keys when the page mounts, then waiting until the fetch calls have both returned before initializing Uppy. It's ugly, strung together code and it's hideous and I'm sure it's wrong in many ways BUT it works.
between the above and now, I did a bunch of work getting Uppy working AND pinging my back-end when a transcoding is completed.
See commits around b0d3082..64d942a master -> master
Updating schema for recordings as follows:
type User {
name: String!
recordings: [Recording!] @relation
}
type Recording {
title: String
date: Time
original: RecordingURL!
transcoded: RecordingURL
low_fi: RecordingURL
transloadit: String
user: User!
}
type RecordingURL {
url: String!
ssl_url: String
}
That's what I'll try. (It appears to work.)
created ngrok account malcolm.murdock@gmail.com
Downloaded ngrok to vue-learning directory
Connect my account
../ngrok authtoken 25763lYQm6bC1vzgwDPxtyUN82S_6ABNZudCw837NvmJz5ZWT
start a tunnel for forwarding callbacks (in this case netlify dev has functions on 8888)
../ngrok http 8888
Test with the listed url. In this case
http://5aba-76-170-96-113.ngrok.io
So using REST Client plugin test e.g. via
GET http://5aba-76-170-96-113.ngrok.io/.netlify/functions/hello
It works!!
Now I can use ngrok endpoints for local dev/testing of e.g. Transloadit callback URLs which should save SO MUCH TIME.
Okay this is sick...
Within a vue file I can now check whether I'm in a local dev environment or not, and based on that I can change the notify_url that Transloadit uses when the assembly is done.
TODO CHANGE THESE TO ENV VARS OR SOMETHING (at least your website URL should be ENV var and not in git)
const notifyURL =
process.env.NODE_ENV == "development"
? "http://5ca2-76-170-96-113.ngrok.io"
: "https://boring-varahamihira-cc7a90.netlify.app";
Then, in the transloadit call:
...
return {
params: {
auth: { key: `${UPLOAD_KEYS.TRANSLOADIT_KEY}` },
template_id: `${UPLOAD_KEYS.TRANSLOADIT_TEMPLATE_ID}`,
notify_url: `${notifyURL}/.netlify/functions/onboardRecording`,
},
...
One shortcoming of this is the ngrok URL constantly changes, so an improvement would be to make that more dynamic/automatic.
At this stage I've updated my Fauna schema. A few notes at this point:
TODO: Figure out how to enforce a uniqueness constraint on necessary fields. What if two users have the same email? What am I indexing against? I should ultimately index against netlifyID and enforce that as a unique key.
Also, document retrieval is done via Index in Fauna.
Okay I've done a lot of fauna work the past few days. here's where we're at: I think I've finally started to grok fauna commands and FQL. I'm now going to try to get the fauna javascript driver up and running and see if I can hit a UDF successfully.
to start with I'll create a temp server key on fauna, then install the javascript driver
npm install faunadb
The following code works! (you can test in a separate js file by running node faunaTest.js)
var faunadb = require('faunadb')
var q = faunadb.query
const TEMP_SERVER_KEY = 'fnAEfu2CM1AARr_nE73_Hr-qZ-DdizaK98slAhgg'
var client = new faunadb.Client({
secret: TEMP_SERVER_KEY,
domain: 'db.us.fauna.com'
})
client.query(
q.ToDate('2018-06-06')
)
.then(function (res) { console.log('Result:', res) })
.catch(function (err) { console.log('Error:', err) })
console.log(TEMP_SERVER_KEY)
Following this: https://towardsdatascience.com/speech-to-text-using-aws-transcribe-s3-and-lambda-a6e88fb3a48e
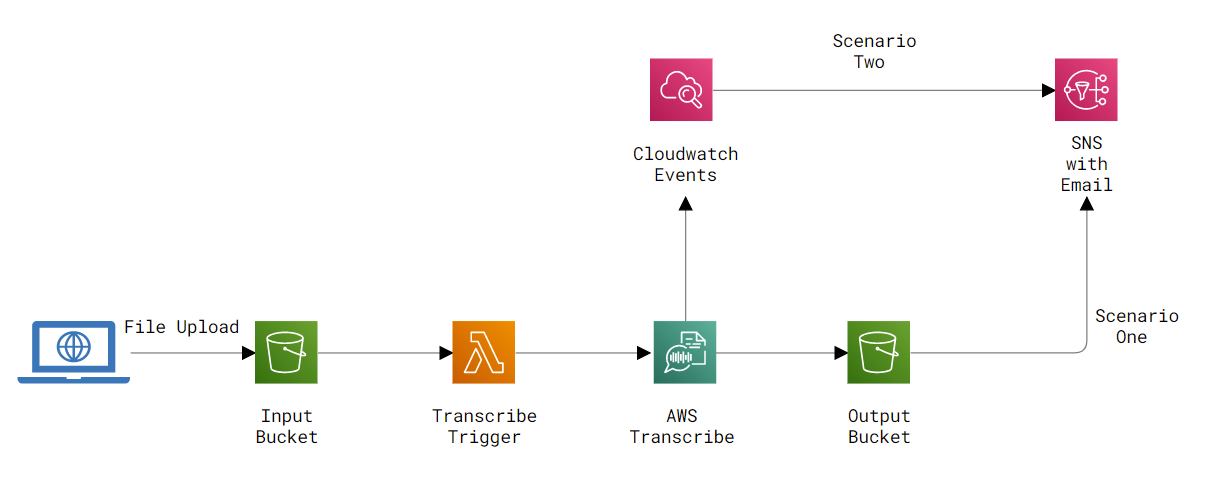
Yup it works. An audio file uploaded to wv-transcribe-upload is now transcribed into wv-transcribe-output.
Need: A function I can hit from Netlify with the file info of a file to be transcribed. From there handle it all internal to aws and only hit Netlify function as final API alert of finished transcription.
API Gateway: wv-initialize-transcribe-endpoint invokes wv-initialize-transcribe Lambda function
check for auth_key header as defined in the lambda function code
set API_GATE_TRANSCRIBE_KEY in Netlify to the value at the top of wv-initialize-transcribe Lambda function
I also set API_GATE_INIT_TRANSCRIBE_ENDPOINT to the url of the gateway endpoint to pull it out of sourcecode
Anyway, passing the request with auth_key successfully receives response from the Lambda function!! (And unauthorized response w/o header so that's good.)
So I can now invoke initializeTranscriptionAWS to fire off a request into my AWS lambda workflow!
Next steps:
- call
initializeTranscriptionAWSat the end ofonboardRecordingto fire off the transcription request! - make the callback endpoint for when transcription is completed
SO MANY MESSY PERMISSIONS Basically need to redo this whole workflow from scratch now that I have a slightly better understanding of Roles and Policies. Or at least start simplifying; eliminating policies one at a time to figure out which ones I really need for the workflow and consolidating into more rational roles and policies.
Functions receives new upload alert from Transloadit.
Persist received data to FaunaDB. Then invoke...
Enqueue Transcription (separating this out also allows to not automatically transcribe every uploaded file)
- Add job to queue tracker in FaunaDB
- Init transcription on AWS
- AWS when finished hits completion function
- completion function verifies job; persists JSON; then removes from queue
Post-Process
- JSON to natural text
- Any special post-processing
(need to go through commits to comprehensivey document)
in WriterDashboard.vue, I'm now constructing a file prefix prior to upload where I take the netlify uid, replace - with _, then add a timestamp (separated by __). This will serve as the bucket/upload prefix for now. It will make my buckets fully "flat" with no folder organization but scale later. Done is better than perfect.
Now going to work through function flow to track file name evolution. Ideally it'll all stay the same/consistent...
Okay onboardRecording.js receives the callback from Transloadit and appears to have the proper s3 upload structure. This then persists into faunaDB and calls initializeTranscriptionAWS.js, which extracts the s3 "key" from the filename (properly, it appears).
Modification In onboardRecording I'm now (hackily) extracting the returned object ID to pass along to aws. We'll need this later to find the right fauna record. This is super hacky, I need to figure out the right way to return a desired value with a record...
NEVER MIND I now have a faunadb UDF that will fetch a Recording object based on original ssl_url
fetch_recording_by_original_recordingUrl_ssl_url
Lambda aws is successfully returning from here. Which is good news. Let's head over to the actual lambda functions now...
from initializeTranscriptionAWS.js we hit (in Lambda) wv-initialize-transcribe which (should) copy the uploaded file over to the wv-transcribe-upload bucket.
The bucket should then trigger lambda-transcribe upon new object creation.
I've now modified jobName in lambda-transcribe to no longer add a uuid, under the assumption that with my timestamp the filenames are sufficiently unique (MAYBE FIX THIS LATER).
lambda-transcribe then fires off a transcription job with "wv-transcribe-output" as the output bucket and returns some job info to (somewhere???)
Now, two separate functions SHOULD be watching for completion of the transcription job...
wv-transcribe-cleanup should delete the file copied over during wv-initialize-transcribe, with the filename simply the transcription job name now.
wv-transcribe-cleanup should... DO WHAT?
omg it's working
- attach a listener to the post-processed bucket that consolidates results into one location and fires back to
completedTranscriptionCallback- done lol
- generated a NETLIFY_CALLBACK_KEY and pasted it into the lambda and stored in netlify env vars
- lol nm apparently iz complicated calling external API from lambda (ironically since Netlify is inside aws ha). Got it working with nodjs code in
wv-post-completed-listenerin Lambda
- In
completedTranscriptionCallbackpersist whatever I need to: reference to the json file (or the json itself); and of course the post-processed transcription - Figure out how to "watch" for completion: something indexed in fauna so I'm not hitting the db repeatedly. maybe just an indexed queue?
- Event stream!
- Once completed, update the front-end!
Recording.vue
FOR NOW: Implement the waiting for transcription as a polling operation to the netlify backend. Fauna event stream is a way better way to do this BUT I've already implemented client auth on the netlify API side, and polling Fauna from the frontend adds an entirely new authentication requirement for Fauna tokens, user auth, expiry time etc.
fetchUserRecordings.js
catch up on documentation
2/11 I got uppy successfully sending netlifyID and JWT to transloadit and then passing that along to the pingback URL, where I can now decode it successfully in the netlify function. This is huge! I now can use this userID to associate the recording with the proper user!
- Implement Identity refresh when users return to the site after their JWT is expired so they don't get errors or have to re-login. See https://answers.netlify.com/t/vuejs-app-out-of-sync-after-role-updated-externally-via-netlify-functions/31969/4 and https://answers.netlify.com/t/netlify-identity-refresh-role-on-client-side/32055/2