A fast & minimal embedded full-text indexing library, written in Objective-C, built on top of Objective-LevelDB.
By far, the easiest way to integrate this library in your project is by using CocoaPods.
-
Have CocoaPods installed, if you don't already
-
In your Podfile, add the line
pod 'MHTextSearch' -
Run
pod install -
Add the
libc++.dylibFramework to your project.
MHTextIndex *index = [MHTextIndex textIndexInLibraryWithName:@"my.awesome.index"];You can tell a MHTextIndex instance to index your objects (any object)
[index indexObject:anyObjectYouWant];
[index updateIndexForObject:anotherPreviousIndexedObject];
[index removeIndexForObject:anotherPreviousIndexedObject];But for this to work, you need to tell us what identifier as NSData * can be used to
uniquely refer to this object.
[index setIdentifier:^NSData *(MyCustomObject *object){
return object.indexID; // a NSData instance
}];You also need to give us details about the objects, like what are the pieces of text to index
[index setIndexer:^MHIndexedObject *(MyCustomObject *object, NSData *identifier){
MHIndexedObject *indx = [MHIndexedObject new];
indx.strings = @[ object.title, object.description ]; // Indexed strings
indx.weight = object.awesomenessLevel; // Weight given to this object, when sorting results
indx.context = @{@"title": object.title}; // A NSDictionary that will be given alongside search results
return indx;
}];Finally, if you want to be able to get easy reference to your original object when you get search results, you can tell us how to do that for you
[index setObjectGetter:^MyCustomObject *(NSData *identifier){
return [MyCustomObject customObjectFromIdentifier:identifier];
}];and that's it! That's all you need to get a full-text index going. MHTextSearch takes care of splitting text into words, factoring out diacritics and capitalization, all with respect to locale, as you'd expect (well, Foundation does most of the job here).
You can then start searching:
[index enumerateObjectsForKeyword:@"duck" options:0 withBlock:^(MHSearchResultItem *item,
NSUInteger rank,
NSUInteger count,
BOOL *stop){
item.weight; // As provided by you earlier
item.rank; // The effective rank in the search result
item.object; // The first time it is used, it will use the block
// you provided earlier to get the object
item.context; // The dictionary you provided in the "indexer" block
item.identifier; // The object identifier you provided in the "identifier" block
NSIndexPath *token = item.resultTokens[0];
/* This is an NSArray of NSIndexPath instances, each containing 3 indices:
* - mh_string : the string in which the token occured
* (here, 0 for the object's title)
* - mh_word : the position in the string where the word containing
* the token occured
* - mh_token : the position in the word where the token occured
*/
NSRange tokenRange = [item rangeOfToken:token];
/* This gives the exact range of the matched token in the string where it was found.
*
* So, according to the example setup I've been giving from the start,
* if token.mh_string == 0, that means the token was found in the object's "title",
* and [item.object.title substringWithRange:tokenRange] would yield "duck" (minus
* capitalization and diacritics).
*/
}];You can also fetch the whole array of MHSearchResultItem instances at once using
NSArray *resultSet = [index searchResultForKeyword:@"duck"
options:NSEnumerationReverse];If giving blocks for specifying behavior is not your thing, you can also override the following methods:
-[MHTextIndex getIdentifierForObject:]which, by default uses theidentifierblock-[MHTextIndex getIndexInfoForObject:andIdentifier:]which, by default uses theindexerblock-[MHTextIndex compareResultItem:withItem:reversed:]which is used to order the search result set
You can use NSManagedObject lifecycle methods to trigger changes to the text index. The following example
was taken from
http://www.adevelopingstory.com/blog/2013/04/adding-full-text-search-to-core-data.html and adapted to use with
this project:
- (void)prepareForDeletion
{
[super prepareForDeletion];
if (self.indexID.length) {
[textindex deleteIndexForObject:self.indexID];
}
}
+ (NSData *)createIndexID {
NSUUID *uuid = [NSUUID UUID];
uuid_t uuidBytes;
[uuid getUUIDBytes:uuidBytes];
return [NSData dataWithBytes:uuidBytes length:16];
}
- (void)willSave
{
[super willSave];
if (self.indexID.length) {
[textindex updateIndexForObject:self.indexID];
} else {
self.indexID = [[self class] createIndexID];
[textindex indexObject:self.indexID];
}
}MHTextIndex uses a NSOperationQueue under the hood to coordinate indexing operations. It is
exposed as a property named indexingQueue. You can thus set its maxConcurrentOperationCount
property to control how concurrent the indexing can be. Since the underlying database library
performing I/O is thread-safe, concurrency is not a problem. This also means you can explicitly
wait for indexing operations to finish using:
[index.indexingQueue waitUntilAllOperationsAreFinished];The three indexing methods -[MHTextIndex indexObject:], -[MHTextIndex updateIndexForObject:],
-[MHTextIndex removeIndexForObject:] all return NSOperation instances, that you can take advantage of,
if you need, using its completionBlock property or -[NSOperation waitUntilFinished] method.
Searching is also concurrent, but it uses a dispatch_queue_t (not yet exposed or tunable).
There are a few knobs you can play with to make MHTextSeach better fit your needs.
-
A
MHTextIndexinstance has askipStopWordsboolean property that is true by default and that avoids indexing very common english words. (TODO: make that work with other languages) -
It also has a
minimalTokenLengththat is equal to2by default. This sets a minimum for the number of letters that a token needs to be for it to be indexed. This also greatly minimizes the size of the index, as well as the indexing and searching time. It skips indexing single-letter words and the last letter of every word, when set to2. -
When indexing long form texts (documents rather than, say, simple names), you can turn on the
discardDuplicateTokensboolean property onMHTextIndex. This makes the index only consider the first occurence of every indexed token for a given piece of texts. If you are okay with only knowing if a token appears in a text, rather than where does every occurence appear, you can gain a speed bump in indexing time, by a factor of 3 to 5.
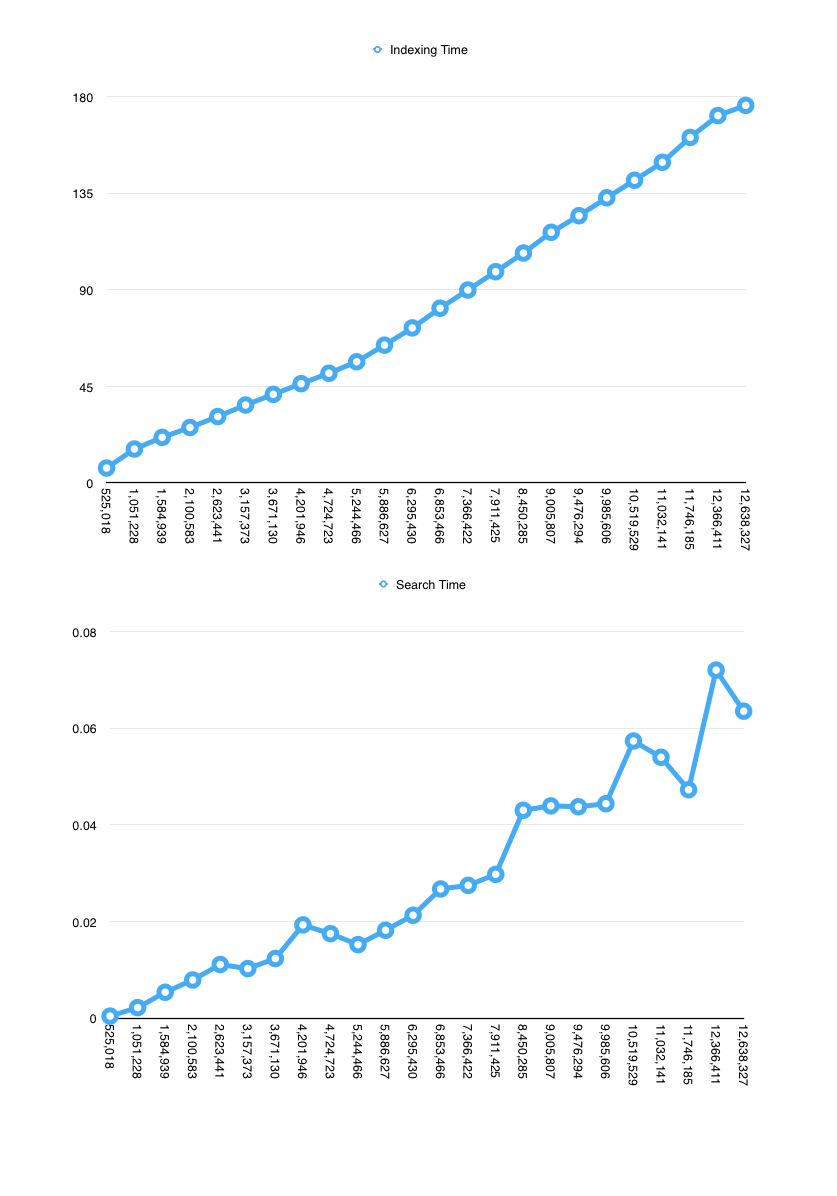
The following graphs show the indexing and searching time (in seconds), as a function of the size of text indexed, ranging from 500 KB to about 10 MB. The benchmarks were run on an iPhone 5.
If you want to run the tests, you will need Xcode 5, as the test suite uses the new XCTest.
Clone this repository and, once in it,
$ cd MHTextSearch\ iOS\ Tests
$ pod install
$ cd .. && open *.xcworkspaceCurrently, all tests were setup to work with the iOS test suite.
Distributed under the MIT license