
![]()

Beta: v1.4.2 / Stable: v1.2.1 / Roadmap | F.A.Q.
High-performance inference of OpenAI's Whisper automatic speech recognition (ASR) model:
- Plain C/C++ implementation without dependencies
- Apple Silicon first-class citizen - optimized via ARM NEON, Accelerate framework, Metal and Core ML
- AVX intrinsics support for x86 architectures
- VSX intrinsics support for POWER architectures
- Mixed F16 / F32 precision
- 4-bit and 5-bit integer quantization support
- Low memory usage (Flash Attention)
- Zero memory allocations at runtime
- Support for CPU-only inference
- Partial GPU support for NVIDIA via cuBLAS
- Partial OpenCL GPU support via CLBlast
- BLAS CPU support via OpenBLAS
- OpenVINO Support
- C-style API
Supported platforms:
- Mac OS (Intel and Arm)
- iOS
- Android
- Java
- Linux / FreeBSD
- WebAssembly
- Windows (MSVC and MinGW]
- Raspberry Pi
The entire implementation of the model is contained in 2 source files:
- Tensor operations: ggml.h / ggml.c
- Transformer inference: whisper.h / whisper.cpp
Having such a lightweight implementation of the model allows to easily integrate it in different platforms and applications. As an example, here is a video of running the model on an iPhone 13 device - fully offline, on-device: whisper.objc
whisper-iphone-13-mini-2.mp4
You can also easily make your own offline voice assistant application: command
command-0.mp4
On Apple Silicon, the inference runs fully on the GPU via Metal:
metal-base-1.mp4
Or you can even run it straight in the browser: talk.wasm
- The core tensor operations are implemented in C (ggml.h / ggml.c)
- The transformer model and the high-level C-style API are implemented in C++ (whisper.h / whisper.cpp)
- Sample usage is demonstrated in main.cpp
- Sample real-time audio transcription from the microphone is demonstrated in stream.cpp
- Various other examples are available in the examples folder
The tensor operators are optimized heavily for Apple silicon CPUs. Depending on the computation size, Arm Neon SIMD intrinsics or CBLAS Accelerate framework routines are used. The latter are especially effective for bigger sizes since the Accelerate framework utilizes the special-purpose AMX coprocessor available in modern Apple products.
First clone the repository.
Then, download one of the Whisper models converted in ggml format. For example:
bash ./models/download-ggml-model.sh base.enIf you wish to convert the Whisper models to ggml format yourself, instructions are in models/README.md.
Now build the main example and transcribe an audio file like this:
# build the main example
make
# transcribe an audio file
./main -f samples/jfk.wavFor a quick demo, simply run make base.en:
$ make base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [2 ] number of best candidates to keep
-bs N, --beam-size N [-1 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of token
bash ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 msThe command downloads the base.en model converted to custom ggml format and runs the inference on all .wav samples in the folder samples.
For detailed usage instructions, run: ./main -h
Note that the main example currently runs only with 16-bit WAV files, so make sure to convert your input before running the tool.
For example, you can use ffmpeg like this:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavIf you want some extra audio samples to play with, simply run:
make samples
This will download a few more audio files from Wikipedia and convert them to 16-bit WAV format via ffmpeg.
You can download and run the other models as follows:
make tiny.en
make tiny
make base.en
make base
make small.en
make small
make medium.en
make medium
make large-v1
make large
| Model | Disk | Mem | SHA |
|---|---|---|---|
| tiny | 75 MB | ~125 MB | bd577a113a864445d4c299885e0cb97d4ba92b5f |
| base | 142 MB | ~210 MB | 465707469ff3a37a2b9b8d8f89f2f99de7299dac |
| small | 466 MB | ~600 MB | 55356645c2b361a969dfd0ef2c5a50d530afd8d5 |
| medium | 1.5 GB | ~1.7 GB | fd9727b6e1217c2f614f9b698455c4ffd82463b4 |
| large | 2.9 GB | ~3.3 GB | 0f4c8e34f21cf1a914c59d8b3ce882345ad349d6 |
whisper.cpp supports integer quantization of the Whisper ggml models.
Quantized models require less memory and disk space and depending on the hardware can be processed more efficiently.
Here are the steps for creating and using a quantized model:
# quantize a model with Q5_0 method
make quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wavOn Apple Silicon devices, the Encoder inference can be executed on the Apple Neural Engine (ANE) via Core ML. This can result in significant
speed-up - more than x3 faster compared with CPU-only execution. Here are the instructions for generating a Core ML model and using it with whisper.cpp:
-
Install Python dependencies needed for the creation of the Core ML model:
pip install ane_transformers pip install openai-whisper pip install coremltools
- To ensure
coremltoolsoperates correctly, please confirm that Xcode is installed and executexcode-select --installto install the command-line tools. - Python 3.10 is recommended.
- [OPTIONAL] It is recommended to utilize a Python version management system, such as Miniconda for this step:
- To create an environment, use:
conda create -n py310-whisper python=3.10 -y - To activate the environment, use:
conda activate py310-whisper
- To create an environment, use:
- To ensure
-
Generate a Core ML model. For example, to generate a
base.enmodel, use:./models/generate-coreml-model.sh base.en
This will generate the folder
models/ggml-base.en-encoder.mlmodelc -
Build
whisper.cppwith Core ML support:# using Makefile make clean WHISPER_COREML=1 make -j # using CMake cmake -B build -DWHISPER_COREML=1 cmake --build build -j --config Release
-
Run the examples as usual. For example:
./main -m models/ggml-base.en.bin -f samples/jfk.wav ... whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc' whisper_init_state: first run on a device may take a while ... whisper_init_state: Core ML model loaded system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 | ...
The first run on a device is slow, since the ANE service compiles the Core ML model to some device-specific format. Next runs are faster.
For more information about the Core ML implementation please refer to PR #566.
On platforms that support OpenVINO, the Encoder inference can be executed on OpenVINO-supported devices including x86 CPUs and Intel GPUs (integrated & discrete).
This can result in significant speedup in encoder performance. Here are the instructions for generating the OpenVINO model and using it with whisper.cpp:
-
First, setup python virtual env. and install python dependencies. Python 3.10 is recommended.
Windows:
cd models python -m venv openvino_conv_env openvino_conv_env\Scripts\activate python -m pip install --upgrade pip pip install -r openvino-conversion-requirements.txtLinux and macOS:
cd models python3 -m venv openvino_conv_env source openvino_conv_env/bin/activate python -m pip install --upgrade pip pip install -r openvino-conversion-requirements.txt -
Generate an OpenVINO encoder model. For example, to generate a
base.enmodel, use:python convert-whisper-to-openvino.py --model base.enThis will produce ggml-base.en-encoder-openvino.xml/.bin IR model files. It's recommended to relocate these to the same folder as ggml models, as that is the default location that the OpenVINO extension will search at runtime.
-
Build
whisper.cppwith OpenVINO support:Download OpenVINO package from release page. The recommended version to use is 2023.0.0.
After downloading & extracting package onto your development system, set up required environment by sourcing setupvars script. For example:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (cmd):
C:\Path\To\w_openvino_toolkit_windows_2023.0.0.10926.b4452d56304_x86_64\setupvars.batAnd then build the project using cmake:
cmake -B build -DWHISPER_OPENVINO=1 cmake --build build -j --config Release
-
Run the examples as usual. For example:
./main -m models/ggml-base.en.bin -f samples/jfk.wav ... whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml' whisper_ctx_init_openvino_encoder: first run on a device may take a while ... whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache whisper_ctx_init_openvino_encoder: OpenVINO model loaded system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 | ...
The first time run on an OpenVINO device is slow, since the OpenVINO framework will compile the IR (Intermediate Representation) model to a device-specific 'blob'. This device-specific blob will get cached for the next run.
For more information about the Core ML implementation please refer to PR #1037.
With NVIDIA cards the Encoder processing can to a large extent be offloaded to the GPU through cuBLAS.
First, make sure you have installed cuda: https://developer.nvidia.com/cuda-downloads
Now build whisper.cpp with cuBLAS support:
make clean
WHISPER_CUBLAS=1 make -j
For cards and integrated GPUs that support OpenCL, the Encoder processing can be largely offloaded to the GPU through CLBlast. This is especially useful for users with AMD APUs or low end devices for up to ~2x speedup.
First, make sure you have installed CLBlast for your OS or Distribution: https://github.com/CNugteren/CLBlast
Now build whisper.cpp with CLBlast support:
Makefile:
cd whisper.cpp
make clean
WHISPER_CLBLAST=1 make -j
CMake:
cd whisper.cpp
cmake -B build -DWHISPER_CLBLAST=ON
cmake --build build -j --config Release
Run all the examples as usual.
Encoder processing can be accelerated on the CPU via OpenBLAS.
First, make sure you have installed openblas: https://www.openblas.net/
Now build whisper.cpp with OpenBLAS support:
make clean
WHISPER_OPENBLAS=1 make -j
- Inference only
Here is another example of transcribing a 3:24 min speech
in about half a minute on a MacBook M1 Pro, using medium.en model:
Expand to see the result
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 msThis is a naive example of performing real-time inference on audio from your microphone. The stream tool samples the audio every half a second and runs the transcription continuously. More info is available in issue #10.
make stream
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000rt_esl_csgo_2.mp4
Adding the --print-colors argument will print the transcribed text using an experimental color coding strategy
to highlight words with high or low confidence:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors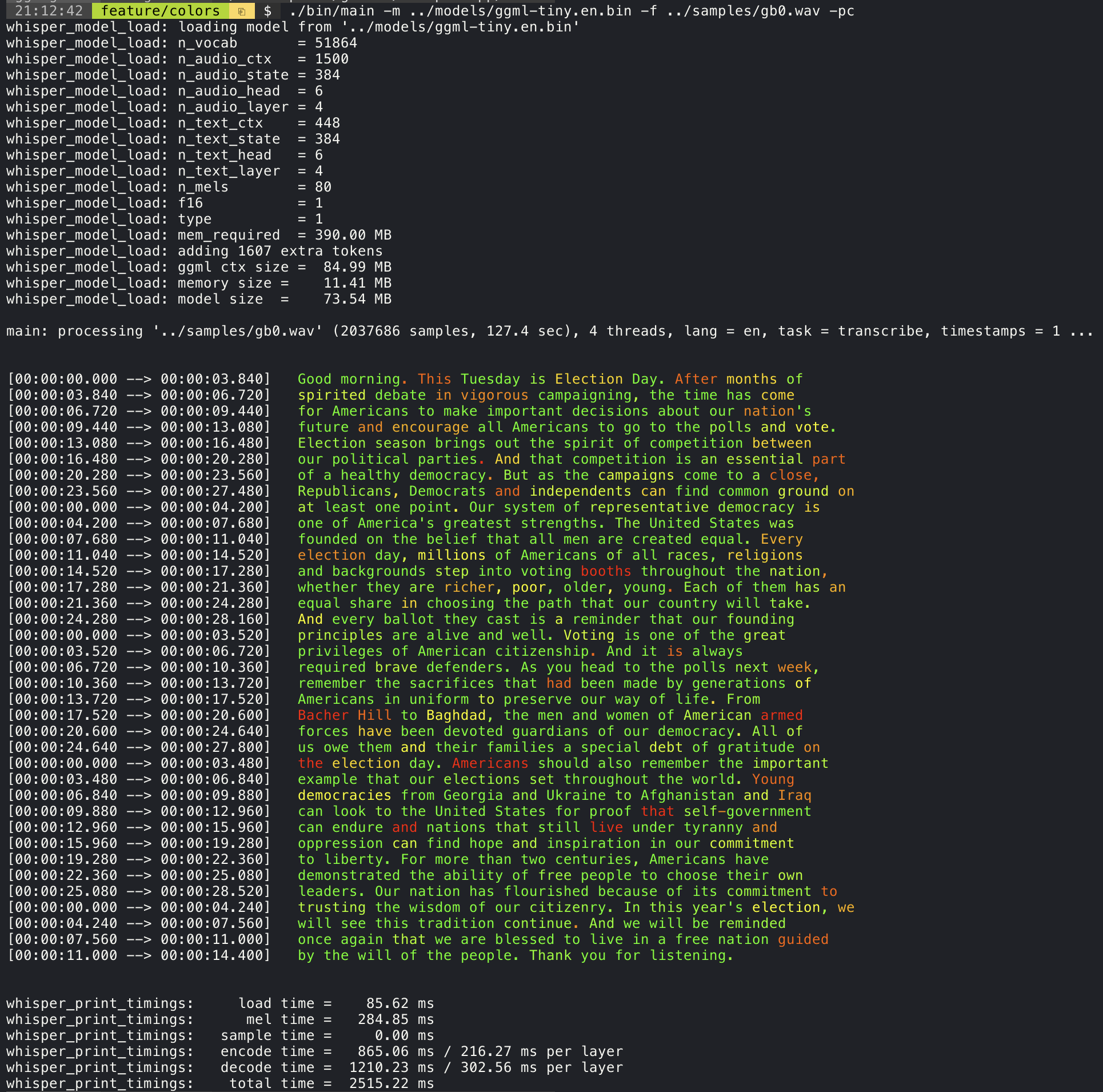
For example, to limit the line length to a maximum of 16 characters, simply add -ml 16:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.The --max-len argument can be used to obtain word-level timestamps. Simply use -ml 1:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .More information about this approach is available here: ggerganov#1058
Sample usage:
# download a tinydiarize compatible model
./models/download-ggml-model.sh small.en-tdrz
# run as usual, adding the "-tdrz" command-line argument
./main -f ./samples/a13.wav -m ./models/ggml-small.en-tdrz.bin -tdrz
...
main: processing './samples/a13.wav' (480000 samples, 30.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, tdrz = 1, timestamps = 1 ...
...
[00:00:00.000 --> 00:00:03.800] Okay Houston, we've had a problem here. [SPEAKER_TURN]
[00:00:03.800 --> 00:00:06.200] This is Houston. Say again please. [SPEAKER_TURN]
[00:00:06.200 --> 00:00:08.260] Uh Houston we've had a problem.
[00:00:08.260 --> 00:00:11.320] We've had a main beam up on a volt. [SPEAKER_TURN]
[00:00:11.320 --> 00:00:13.820] Roger main beam interval. [SPEAKER_TURN]
[00:00:13.820 --> 00:00:15.100] Uh uh [SPEAKER_TURN]
[00:00:15.100 --> 00:00:18.020] So okay stand, by thirteen we're looking at it. [SPEAKER_TURN]
[00:00:18.020 --> 00:00:25.740] Okay uh right now uh Houston the uh voltage is uh is looking good um.
[00:00:27.620 --> 00:00:29.940] And we had a a pretty large bank or so.The main example provides support for output of karaoke-style movies, where the
currently pronounced word is highlighted. Use the -wts argument and run the generated bash script.
This requires to have ffmpeg installed.
Here are a few "typical" examples:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4jfk.wav.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4mm0.wav.mp4
./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4gb0.wav.mp4
Use the extra/bench-wts.sh script to generate a video in the following format:
./extra/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4jfk.wav.all.mp4
In order to have an objective comparison of the performance of the inference across different system configurations, use the bench tool. The tool simply runs the Encoder part of the model and prints how much time it took to execute it. The results are summarized in the following Github issue:
Additionally a script to run whisper.cpp with different models and audio files is provided bench.py.
You can run it with the following command, by default it will run against any standard model in the models folder.
python3 extra/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2It is written in python with the intention of being easy to modify and extend for your benchmarking use case.
It outputs a csv file with the results of the benchmarking.
The original models are converted to a custom binary format. This allows to pack everything needed into a single file:
- model parameters
- mel filters
- vocabulary
- weights
You can download the converted models using the models/download-ggml-model.sh script or manually from here:
For more details, see the conversion script models/convert-pt-to-ggml.py or the README in models.
- Rust: tazz4843/whisper-rs | #310
- JavaScript: bindings/javascript | #309
- React Native (iOS / Android): whisper.rn
- Go: bindings/go | #312
- Java:
- Ruby: bindings/ruby | #507
- Objective-C / Swift: ggerganov/whisper.spm | #313
- .NET: | #422
- Python: | #9
- stlukey/whispercpp.py (Cython)
- aarnphm/whispercpp (Pybind11)
- R: bnosac/audio.whisper
- Unity: macoron/whisper.unity
There are various examples of using the library for different projects in the examples folder. Some of the examples are even ported to run in the browser using WebAssembly. Check them out!
| Example | Web | Description |
|---|---|---|
| main | whisper.wasm | Tool for translating and transcribing audio using Whisper |
| bench | bench.wasm | Benchmark the performance of Whisper on your machine |
| stream | stream.wasm | Real-time transcription of raw microphone capture |
| command | command.wasm | Basic voice assistant example for receiving voice commands from the mic |
| talk | talk.wasm | Talk with a GPT-2 bot |
| talk-llama | Talk with a LLaMA bot | |
| whisper.objc | iOS mobile application using whisper.cpp | |
| whisper.swiftui | SwiftUI iOS / macOS application using whisper.cpp | |
| whisper.android | Android mobile application using whisper.cpp | |
| whisper.nvim | Speech-to-text plugin for Neovim | |
| generate-karaoke.sh | Helper script to easily generate a karaoke video of raw audio capture | |
| livestream.sh | Livestream audio transcription | |
| yt-wsp.sh | Download + transcribe and/or translate any VOD (original) |
If you have any kind of feedback about this project feel free to use the Discussions section and open a new topic.
You can use the Show and tell category
to share your own projects that use whisper.cpp. If you have a question, make sure to check the
Frequently asked questions (#126) discussion.