

This repository contains Reinforcement Learning algorithms which are being used for research activities at Medipixel. The source code will be frequently updated. We are warmly welcoming external contributors! :)
 |
 |
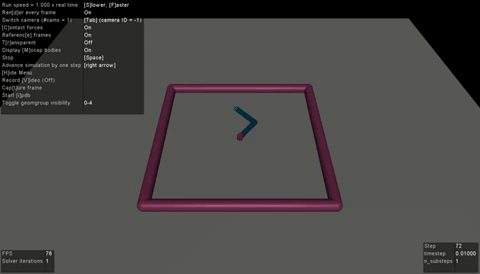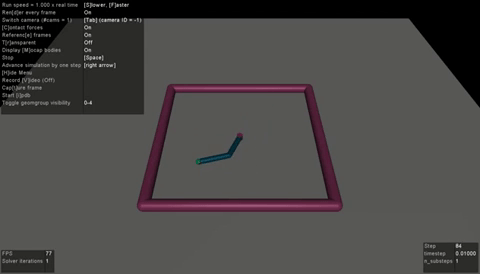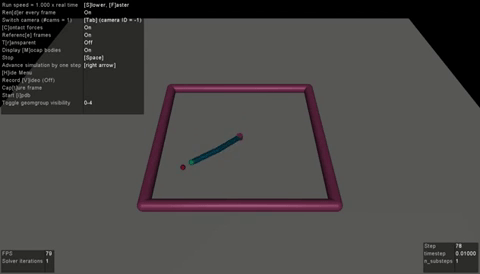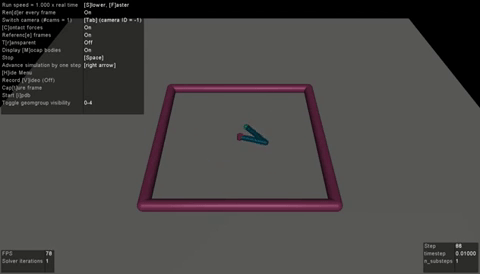 |
|---|---|---|
| BC agent on LunarLanderContinuous-v2 | RainbowIQN agent on PongNoFrameskip-v4 | SAC agent on Reacher-v2 |
Thanks goes to these wonderful people (emoji key):
 Jinwoo Park (Curt) 💻 |
 Kyunghwan Kim 💻 |
 darthegg 💻 |
 Mincheol Kim 💻 |
 김민섭 💻 |
 Leejin Jung 💻 |
 Chris Yoon 💻 |
 Jiseong Han 💻 |
 Sehyun Hwang 🚧 |
 eunjin 💻 |
This project follows the all-contributors specification.
- Advantage Actor-Critic (A2C)
- Deep Deterministic Policy Gradient (DDPG)
- Proximal Policy Optimization Algorithms (PPO)
- Twin Delayed Deep Deterministic Policy Gradient Algorithm (TD3)
- Soft Actor Critic Algorithm (SAC)
- Behaviour Cloning (BC with DDPG, SAC)
- From Demonstrations (DDPGfD, SACfD, DQfD)
- Rainbow DQN
- Rainbow IQN (without DuelingNet) - DuelingNet degrades performance
- Rainbow IQN (with ResNet)
- Recurrent Replay DQN (R2D1)
- Distributed Pioritized Experience Replay (Ape-X)
- Policy Distillation
- Generative Adversarial Imitation Learning (GAIL)
- Sample Efficient Actor-Critic with Experience Replay (ACER)
We have tested each algorithm on some of the following environments.
❗Please note that this won't be frequently updated.
RainbowIQN learns the game incredibly fast! It accomplishes the perfect score (21) within 100 episodes! The idea of RainbowIQN is roughly suggested from W. Dabney et al..
See W&B Log for more details. (The performance is measured on the commit 4248057)

RainbowIQN with ResNet's performance and learning speed were similar to those of RainbowIQN. Also we confirmed that R2D1 (w/ Dueling, PER) converges well in the Pong enviornment, though not as fast as RainbowIQN (in terms of update step).
Although we were only able to test Ape-X DQN (w/ Dueling) with 4 workers due to limitations to computing power, we observed a significant speed-up in carrying out update steps (with batch size 512). Ape-X DQN learns Pong game in about 2 hours, compared to 4 hours for serial Dueling DQN.
See W&B Log for more details. (The performance is measured on the commit 9e897ad)


We used these environments just for a quick verification of each algorithm, so some of experiments may not show the best performance.
LunarLander-v2: RainbowDQN, RainbowDQfD, R2D1
See W&B log for more details. (The performance is measured on the commit 9e897ad)

LunarLander-v2:ACER, RainbowDQN, R2D1
See W&B log for more details. (The performance is measured on the commit 82fae77)

LunarLanderContinuous-v2: A2C, PPO, DDPG, TD3, SAC
See W&B log for more details. (The performance is measured on the commit 9e897ad)

LunarLanderContinuous-v2: DDPG, DDPGfD, BC-DDPG
See W&B log for more details. (The performance is measured on the commit 9e897ad)

LunarLanderContinuous-v2: SAC, SACfD, BC-SAC
See W&B log for more details. (The performance is measured on the commit 9e897ad)

LunarLanderContinuous-v2: PPO, SAC, GAIL
See W&B log for more details. (The performance is measured on the commit 9e897ad)

We reproduced the performance of DDPG, TD3, and SAC on Reacher-v2 (Mujoco). They reach the score around -3.5 to -4.5.

- This repository is tested on Anaconda virtual environment with python 3.6.1+
$ conda create -n rl_algorithms python=3.7.9 $ conda activate rl_algorithms - In order to run Mujoco environments (e.g.
Reacher-v2), you need to acquire Mujoco license.
First, clone the repository.
git clone https://github.com/medipixel/rl_algorithms.git
cd rl_algorithms
Install packages required to execute the code. It includes python setup.py install. Just type:
make dep
If you want to modify code you should configure formatting and linting settings. It automatically runs formatting and linting when you commit the code. Contrary to make dep command, it includes python setup.py develop. Just type:
make dev
After having done make dev, you can validate the code by the following commands.
make format # for formatting
make test # for linting
You can train or test algorithm on env_name if configs/env_name/algorithm.yaml exists. (configs/env_name/algorithm.yaml contains hyper-parameters)
python run_env_name.py --cfg-path <config-path>
e.g. running soft actor-critic on LunarLanderContinuous-v2.
python run_lunarlander_continuous_v2.py --cfg-path ./configs/lunarlander_continuous_v2/sac.yaml <other-options>
e.g. running a custom agent, if you have written your own configs: configs/env_name/ddpg-custom.yaml.
python run_env_name.py --cfg-path ./configs/lunarlander_continuous_v2/ddpg-custom.py
You will see the agent run with hyper parameter and model settings you configured.
In addition, there are various argument settings for running algorithms. If you check the options to run file you should command
python <run-file> -h
--test- Start test mode (no training).
--off-render- Turn off rendering.
--log- Turn on logging using W&B.
--seed <int>- Set random seed.
--save-period <int>- Set saving period of model and optimizer parameters.
--max-episode-steps <int>- Set maximum episode step number of the environment. If the number is less than or equal to 0, it uses the default maximum step number of the environment.
--episode-num <int>- Set the number of episodes for training.
--render-after <int>- Start rendering after the number of episodes.
--load-from <save-file-path>- Load the saved models and optimizers at the beginning.
You can show a feature map that the trained agent extract using Grad-CAM(Gradient-weighted Class Activation Mapping) and Saliency map.
Grad-CAM is a way of combining feature maps using the gradient signal, and produce a coarse localization map of the important regions in the image. You can use it by adding Grad-CAM config and --grad-cam flag when you run. For example:
python run_env_name.py --cfg-path <config-path> --test --grad-cam
The results will be rendered as follows:

You can also use Saliency-map in a similar way to Grad-CAM just by adding --saliency-map flag. Saliency-map need trained weight carried by --load-from flag.
python run_env_name.py --cfg-path <config-path> --load-from <save-file-path> --test --saliency-map
Saliency map will be stored in data/saliency_map

Both Grad-CAM and Saliency-map can be only used for the agent that uses convolutional layers like DQN for Pong environment. You can see feature maps of all the configured convolution layers.
We seperate the document about using policy distillation in rl_algorithms/distillation/README.md.
We use W&B for logging of network parameters and others. For logging, please follow the steps below after requirement installation:
- Create a wandb account
- Check your API key in settings, and login wandb on your terminal:
$ wandb login API_KEY- Initialize wandb:
$ wandb init
For more details, read W&B tutorial.
Class diagram at #135.
❗This won't be frequently updated.

To cite this repository in publications:
@misc{rl_algorithms,
author = {Kim, Kyunghwan and Lee, Chaehyuk and Jeong, Euijin and Han, Jiseong and Kim, Minseop and Yoon, Chris and Kim, Mincheol and Park, Jinwoo},
title = {Medipixel RL algorithms},
year = {2020},
publisher = {Github},
journal = {GitHub repository},
howpublished = {\url{https://github.com/medipixel/rl_algorithms}},
}
- T. P. Lillicrap et al., "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971, 2015.
- J. Schulman et al., "Proximal Policy Optimization Algorithms." arXiv preprint arXiv:1707.06347, 2017.
- S. Fujimoto et al., "Addressing function approximation error in actor-critic methods." arXiv preprint arXiv:1802.09477, 2018.
- T. Haarnoja et al., "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor." arXiv preprint arXiv:1801.01290, 2018.
- T. Haarnoja et al., "Soft Actor-Critic Algorithms and Applications." arXiv preprint arXiv:1812.05905, 2018.
- T. Schaul et al., "Prioritized Experience Replay." arXiv preprint arXiv:1511.05952, 2015.
- M. Andrychowicz et al., "Hindsight Experience Replay." arXiv preprint arXiv:1707.01495, 2017.
- A. Nair et al., "Overcoming Exploration in Reinforcement Learning with Demonstrations." arXiv preprint arXiv:1709.10089, 2017.
- M. Vecerik et al., "Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards."arXiv preprint arXiv:1707.08817, 2017
- V. Mnih et al., "Human-level control through deep reinforcement learning." Nature, 518 (7540):529–533, 2015.
- van Hasselt et al., "Deep Reinforcement Learning with Double Q-learning." arXiv preprint arXiv:1509.06461, 2015.
- Z. Wang et al., "Dueling Network Architectures for Deep Reinforcement Learning." arXiv preprint arXiv:1511.06581, 2015.
- T. Hester et al., "Deep Q-learning from Demonstrations." arXiv preprint arXiv:1704.03732, 2017.
- M. G. Bellemare et al., "A Distributional Perspective on Reinforcement Learning." arXiv preprint arXiv:1707.06887, 2017.
- M. Fortunato et al., "Noisy Networks for Exploration." arXiv preprint arXiv:1706.10295, 2017.
- M. Hessel et al., "Rainbow: Combining Improvements in Deep Reinforcement Learning." arXiv preprint arXiv:1710.02298, 2017.
- W. Dabney et al., "Implicit Quantile Networks for Distributional Reinforcement Learning." arXiv preprint arXiv:1806.06923, 2018.
- Ramprasaath R. Selvaraju et al., "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization." arXiv preprint arXiv:1610.02391, 2016.
- Kaiming He et al., "Deep Residual Learning for Image Recognition." arXiv preprint arXiv:1512.03385, 2015.
- Steven Kapturowski et al., "Recurrent Experience Replay in Distributed Reinforcement Learning." in International Conference on Learning Representations https://openreview.net/forum?id=r1lyTjAqYX, 2019.
- Horgan et al., "Distributed Prioritized Experience Replay." in International Conference on Learning Representations, 2018
- Simonyan et al., "Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps", 2013
- Ho et al., "Generative adversarial imitation learning", 2016
- Wang, Ziyu, et al. "Sample efficient actor-critic with experience replay", 2016.