Join the ServiceStack Google+ group or follow @servicestack for updates.
OrmLite's goal is to provide a convenient, DRY, config-free, RDBMS-agnostic typed wrapper that retains a high affinity with SQL, exposing intuitive APIs that generate predictable SQL and maps cleanly to (DTO-friendly) disconnected POCO's. This approach makes easier to reason-about your data access making it obvious what SQL is getting executed at what time, whilst mitigating unexpected behavior, implicit N+1 queries and leaky data access prevalent in Heavy ORMs.
OrmLite was designed with a focus on the core objectives:
- Provide a set of light-weight C# extension methods around .NET's impl-agnostic
System.Data.*interfaces - Map a POCO class 1:1 to an RDBMS table, cleanly by conventions, without any attributes required.
- Create/Drop DB Table schemas using nothing but POCO class definitions (IOTW a true code-first ORM)
- Simplicity - typed, wrist friendly API for common data access patterns.
- High performance - with support for indexes, text blobs, etc.
- Amongst the fastest Micro ORMs for .NET (just behind Dapper).
- Expressive power and flexibility - with access to IDbCommand and raw SQL
- Cross platform - supports multiple dbs (currently: Sql Server, Sqlite, MySql, PostgreSQL, Firebird) running on both .NET and Mono platforms.
In OrmLite: 1 Class = 1 Table. There should be no surprising or hidden behaviour. Any non-scalar properties (i.e. complex types) are by default text blobbed in a schema-less text field using any of the avilable pluggable text serializers. Support for POCO-friendly references is also available to provide a convenient API to persist related models. Effectively this allows you to create a table from any POCO type and it should persist as expected in a DB Table with columns for each of the classes 1st level public properties.

- ServiceStack.OrmLite.SqlServer
- ServiceStack.OrmLite.MySql
- ServiceStack.OrmLite.PostgreSQL
- ServiceStack.OrmLite.Sqlite.Mono - Compatible with Mono / Windows (x86)
- ServiceStack.OrmLite.Sqlite.Windows - 32/64bit Mixed mode .NET for WIndows only
- ServiceStack.OrmLite.Oracle (unofficial)
- ServiceStack.OrmLite.Firebird (unofficial)
- ServiceStack.OrmLite.VistaDb (unofficial)
Latest v4+ on NuGet is a commercial release with free quotas.
Since September 2013, ServiceStack source code is available under GNU Affero General Public License/FOSS License Exception, see license.txt in the source. Alternative commercial licensing is also available.
Contributors need to approve the Contributor License Agreement before submitting pull-requests, see the Contributing wiki for more details.
There's new support for returning unstructured resultsets letting you Select List<object> instead of having results mapped to a concrete Poco class, e.g:
db.Select<List<object>>(db.From<Poco>()
.Select("COUNT(*), MIN(Id), MAX(Id)"))[0].PrintDump();Output of objects in the returned List<object>:
[
10,
1,
10
]
You can also Select Dictionary<string,object> to return a dictionary of column names mapped with their values, e.g:
db.Select<Dictionary<string,object>>(db.From<Poco>()
.Select("COUNT(*) Total, MIN(Id) MinId, MAX(Id) MaxId"))[0].PrintDump();Output of objects in the returned Dictionary<string,object>:
{
Total: 10,
MinId: 1,
MaxId: 10
}
and can be used for API's returning a Single row result:
db.Single<List<object>>(db.From<Poco>()
.Select("COUNT(*) Total, MIN(Id) MinId, MAX(Id) MaxId")).PrintDump();or use object to fetch an unknown Scalar value:
object result = db.Scalar<object>(db.From<Poco>().Select(x => x.Id));To enable even finer-grained control of parameterized queries we've added new overloads that take a collection of IDbDataParameter's:
List<T> Select<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
T Single<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
T Scalar<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
List<T> Column<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
IEnumerable<T> ColumnLazy<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
HashSet<T> ColumnDistinct<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
Dictionary<K, List<V>> Lookup<K, V>(string sql, IEnumerable<IDbDataParameter> sqlParams)
List<T> SqlList<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
List<T> SqlColumn<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)
T SqlScalar<T>(string sql, IEnumerable<IDbDataParameter> sqlParams)Including Async equivalents for each of the above Sync API's.
The new API's let you execute parameterized SQL with finer-grained control over the IDbDataParameter used, e.g:
IDbDataParameter pAge = db.CreateParam("age", 40, dbType:DbType.Int16);
db.Select<Person>("SELECT * FROM Person WHERE Age > @pAge", new[] { pAge });The new CreateParam() extension method above is a useful helper for creating custom IDbDataParameter's.
The new OrmLiteConfig.OnDbNullFilter lets you to replace DBNull values with a custom value, so you could convert all null strings to be populated with "NULL" using:
OrmLiteConfig.OnDbNullFilter = fieldDef =>
fieldDef.FieldType == typeof(string)
? "NULL"
: null;A quick overview of Async API's can be seen in the class diagram below:
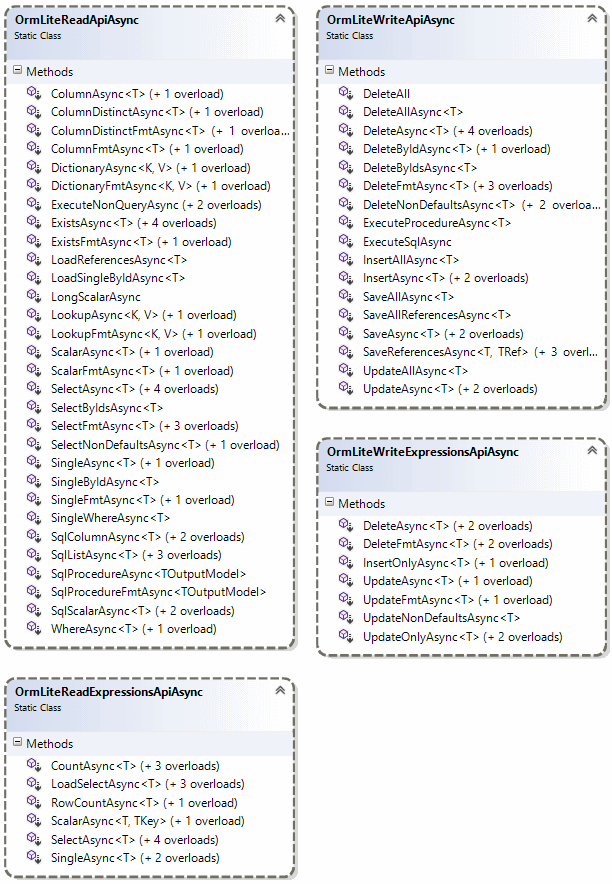
Essentially most of OrmLite public API's now have async equivalents of the same name and an additional conventional *Async suffix.
The Async API's also take an optional CancellationToken making converting sync code trivial, where you just need to
add the Async suffix and await keyword, as can be seen in the
Customer Orders UseCase upgrade to Async diff
, e.g:
Sync:
db.Insert(new Employee { Id = 1, Name = "Employee 1" });
db.Save(product1, product2);
var customer = db.Single<Customer>(new { customer.Email }); Async:
await db.InsertAsync(new Employee { Id = 1, Name = "Employee 1" });
await db.SaveAsync(product1, product2);
var customer = await db.SingleAsync<Customer>(new { customer.Email });Effectively the only Data Access API's that doesn't have async equivalents are
*LazyAPIs yielding a lazy sequence (incompatible with async) as well as Schema DDL API's which are typically not used at runtime.
For a quick preview of many of the new Async API's in action, checkout ApiSqlServerTestsAsync.cs.
Currently only a limited number of RDBMS providers offer async API's which are only available in their .NET 4.5 builds, which at this time are only:
We've also added a
.NET 4.5 build for Sqlite
as it's a common use-case to swapout to use Sqlite's in-memory provider for faster tests.
But as Sqlite doesn't provide async API's under-the-hood we fallback to pseudo async support where we just wrap its synchronous responses in Task results.
OrmLite's SQL Expression support lets you use LINQ-liked querying in all our providers. To give you a flavour here are some examples with their partial SQL output (using SqlServer dialect):
int agesAgo = DateTime.Today.AddYears(-20).Year;
db.Select<Author>(q => q.Birthday >= new DateTime(agesAgo, 1, 1)
&& q.Birthday <= new DateTime(agesAgo, 12, 31));WHERE (("Birthday" >= '1992-01-01 00:00:00.000') AND ("Birthday" <= '1992-12-31 00:00:00.000'))
db.Select<Author>(q => Sql.In(q.City, "London", "Madrid", "Berlin"));WHERE "JobCity" In ('London', 'Madrid', 'Berlin')
db.Select<Author>(q => q.Earnings <= 50);WHERE ("Earnings" <= 50)
db.Select<Author>(q => q.Name.StartsWith("A"));WHERE upper("Name") like 'A%'
db.Select<Author>(q => q.Name.EndsWith("garzon"));WHERE upper("Name") like '%GARZON'
db.Select<Author>(q => q.Name.Contains("Benedict"));WHERE upper("Name") like '%BENEDICT%'
db.Select<Author>(q => q.Rate == 10 && q.City == "Mexico");WHERE (("Rate" = 10) AND ("JobCity" = 'Mexico'))
Right now the Expression support can satisfy most simple queries with a strong-typed API. For anything more complex (e.g. queries with table joins) you can still easily fall back to raw SQL queries as seen below.
OrmLite also includes a number of convenient API's providing DRY, typed data access for common queries:
Person personById = db.SingleById<Person>(1);SELECT "Id", "FirstName", "LastName", "Age" FROM "Person" WHERE "Id" = @Id
Person personByAge = db.Single<Person>(x => x.Age == 42);SELECT TOP 1 "Id", "FirstName", "LastName", "Age" FROM "Person" WHERE ("Age" = 42)
int maxAgeUnder50 = db.Scalar<Person, int>(x => Sql.Max(x.Age), x => x.Age < 50);SELECT Max("Age") FROM "Person" WHERE ("Age" < 50)
int peopleOver40 = db.Scalar<int>(
db.From<Person>().Select(Sql.Count("*")).Where(q => q.Age > 40));SELECT COUNT(*) FROM "Person" WHERE ("Age" > 40)
int peopleUnder50 = db.Count<Person>(x => x.Age < 50);SELECT COUNT(*) FROM "Person" WHERE ("Age" < 50)
bool has42YearOlds = db.Exists<Person>(new { Age = 42 });WHERE "Age" = @Age
List<string> results = db.Column<string>(db.From<Person>().Select(x => x.LastName)
.Where(q => q.Age == 27));SELECT "LastName" FROM "Person" WHERE ("Age" = 27)
HashSet<int> results = db.ColumnDistinct<int>(db.From<Person>().Select(x => x.Age)
.Where(q => q.Age < 50));SELECT "Age" FROM "Person" WHERE ("Age" < 50)
Dictionary<int,string> results = db.Dictionary<int, string>(
db.From<Person>().Select(x => new { x.Id, x.LastName }).Where(x => x.Age < 50));SELECT "Id","LastName" FROM "Person" WHERE ("Age" < 50)
Dictionary<int, List<string>> results = db.Lookup<int, string>(
db.From<Person>().Select(x => new { x.Age, x.LastName }).Where(q => q.Age < 50));SELECT "Age","LastName" FROM "Person" WHERE ("Age" < 50)
To see the behaviour of the different APIs, all examples uses this simple model
public class Person
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public int? Age { get; set; }
}In its most simple form, updating any model without any filters will update every field, except the Id which is used to filter the update to this specific record:
db.Update(new Person { Id = 1, FirstName = "Jimi", LastName = "Hendrix", Age = 27});UPDATE "Person" SET "FirstName" = 'Jimi',"LastName" = 'Hendrix',"Age" = 27 WHERE "Id" = 1
If you supply your own where expression, it updates every field (inc. Id) but uses your filter instead:
db.Update(new Person { Id = 1, FirstName = "JJ" }, p => p.LastName == "Hendrix");UPDATE "Person" SET "Id" = 1,"FirstName" = 'JJ',"LastName" = NULL,"Age" = NULL WHERE ("LastName" = 'Hendrix')
One way to limit the fields which gets updated is to use an Anonymous Type:
db.Update<Person>(new { FirstName = "JJ" }, p => p.LastName == "Hendrix");Or by using UpdateNonDefaults which only updates the non-default values in your model using the filter specified:
db.UpdateNonDefaults(new Person { FirstName = "JJ" }, p => p.LastName == "Hendrix");UPDATE "Person" SET "FirstName" = 'JJ' WHERE ("LastName" = 'Hendrix')
As updating a partial row is a common use-case in Db's, we've added a number of methods for just this purpose, named UpdateOnly.
The first expression in an UpdateOnly statement is used to specify which fields should be updated:
db.UpdateOnly(new Person { FirstName = "JJ" }, p => p.FirstName);UPDATE "Person" SET "FirstName" = 'JJ'
db.UpdateOnly(new Person { FirstName = "JJ", Age = 12 },
onlyFields: p => new { p.FirstName, p.Age });UPDATE "Person" SET "FirstName" = 'JJ', "Age" = 12
When present, the second expression is used as the where filter:
db.UpdateOnly(new Person { FirstName = "JJ" },
onlyFields: p => p.FirstName,
where: p => p.LastName == "Hendrix");UPDATE "Person" SET "FirstName" = 'JJ' WHERE ("LastName" = 'Hendrix')
Instead of using the expression filters above you can choose to use an ExpressionVisitor builder which provides more flexibility when you want to programatically construct the update statement:
db.UpdateOnly(new Person { FirstName = "JJ", LastName = "Hendo" },
onlyFields: q => q.Update(p => p.FirstName));UPDATE "Person" SET "FirstName" = 'JJ'
db.UpdateOnly(new Person { FirstName = "JJ" },
onlyFields: q => q.Update(p => p.FirstName).Where(x => x.FirstName == "Jimi"));UPDATE "Person" SET "FirstName" = 'JJ' WHERE ("LastName" = 'Hendrix')
For the ultimate flexibility we also provide un-typed, string-based expressions. Use the .Params() extension method escape parameters (inspired by massive):
db.Update<Person>(set: "FirstName = {0}".Params("JJ"),
where: "LastName = {0}".Params("Hendrix"));Even the Table name can be a string so you perform the same update without requiring the Person model at all:
db.Update(table: "Person", set: "FirstName = {0}".Params("JJ"),
where: "LastName = {0}".Params("Hendrix"));UPDATE "Person" SET FirstName = 'JJ' WHERE LastName = 'Hendrix'
Insert's are pretty straight forward since in most cases you want to insert every field:
db.Insert(new Person { Id = 1, FirstName = "Jimi", LastName = "Hendrix", Age = 27 });INSERT INTO "Person" ("Id","FirstName","LastName","Age") VALUES (1,'Jimi','Hendrix',27)
But do provide an API that takes an Expression Visitor for the rare cases you don't want to insert every field
db.InsertOnly(new Person { FirstName = "Amy" }, q => q.Insert(p => new {p.FirstName}))INSERT INTO "Person" ("FirstName") VALUES ('Amy')
Like updates for DELETE's we also provide APIs that take a where Expression:
db.Delete<Person>(p => p.Age == 27);Or an Expression Visitor:
db.Delete<Person>(q => q.Where(p => p.Age == 27));DELETE FROM "Person" WHERE ("Age" = 27)
As well as un-typed, string-based expressions:
db.Delete<Person>(where: "Age = {0}".Params(27));Which also can take a table name so works without requiring a typed Person model
db.Delete(table: "Person", where: "Age = {0}".Params(27));DELETE FROM "Person" WHERE Age = 27
The API is minimal, providing basic shortcuts for the primitive SQL statements:
OrmLite Extension methods hang off ADO.NET's IDbConnection.
CreateTable<T> and DropTable<T> create and drop tables based on a classes type definition (only public properties used).
By default the Select API's use parameterized SQL whilst any selection methods ending with Fmt allow you to construct Sql using C# string.Format() syntax.
If your SQL doesn't start with a SELECT statement, it is assumed a WHERE clause is being provided, e.g:
var tracks = db.SelectFmt<Track>("Artist = {0} AND Album = {1}",
"Nirvana",
"Heart Shaped Box");Which is equivalent to:
var tracks = db.SelectFmt<Track>("SELECT * FROM track WHERE Artist={0} AND Album={1}",
"Nirvana",
"Heart Shaped Box");Select returns multiple records:
List<Track> tracks = db.Select<Track>()Single returns a single record:
Track track = db.Single<Track>(q => q.RefId == refId)Dictionary returns a Dictionary made from the first two columns:
Dictionary<int, string> trackIdNamesMap = db.Dictionary<int, string>(
"select Id, Name from Track")Lookup returns an Dictionary<K, List<V>> made from the first two columns:
Dictionary<int, List<string>> albumTrackNames = db.Lookup<int, string>(
"select AlbumId, Name from Track")Column returns a List of first column values:
List<string> trackNames = db.Column<string>("select Name from Track")HashSet returns a HashSet of distinct first column values:
HashSet<string> uniqueTrackNames = db.ColumnDistinct<string>("select Name from Track")Scalar returns a single scalar value:
var trackCount = db.Scalar<int>("select count(*) from Track")Anonymous types passed into Where are treated like an AND filter:
var track3 = db.Where<Track>(new { AlbumName = "Throwing Copper", TrackNo = 3 })Select statements take in parameterized SQL using properties from the supplied anonymous type (if any):
var track3 = db.Select<Track>(
"select * from Track Where AlbumName = @album and TrackNo = @trackNo",
new { album = "Throwing Copper", trackNo = 3 })SingleById(s), SelectById(s), etc provide strong-typed convenience methods to fetch by a Table's Id primary key field.
var track = db.SingleById<Track>(1);
var tracks = db.SelectByIds<Track>(new[]{ 1,2,3 });API's ending with Lazy yield an IEnumerable sequence letting you stream the results without having to map the entire resultset into a disconnected List of POCO's first, e.g:
var lazyQuery = db.SelectLazy<Person>("Age > @age", new { age = 40 });
// Iterate over a lazy sequence
foreach (var person in lazyQuery) {
//...
}var topVIPs = db.WhereLazy<Person>(new { Age = 27 }).Where(p => IsVip(p)).Take(5)
var topVIPs = db.SelectLazyFmt<Person>("Age > {0}", 40).Where(p => IsVip(p)).Take(5)- All Insert, Update, and Delete methods take multiple params, while
InsertAll,UpdateAllandDeleteAlltake IEnumerables. SaveandSaveAllwill Insert if no record with Id exists, otherwise it Updates.- Methods containing the word Each return an IEnumerable and are lazily loaded (i.e. non-buffered).
Whilst OrmLite aims to provide a light-weight typed wrapper around SQL, it offers a number of convenient features that makes working with RDBMS's a clean and enjoyable experience:
Starting with the most basic example you can simply specify the table you want to join with:
var dbCustomers = db.Select<Customer>(q => q.Join<CustomerAddress>());This query rougly maps to the following SQL:
SELECT Customer.*
FROM Customer
INNER JOIN
CustomerAddress ON (Customer.Id == CustomerAddress.Id)Just like before q is an instance of SqlExpression<Customer> which is bounded to the base Customer type (and what any subsequent implicit API's apply to).
To better illustrate the above query, lets expand it to the equivalent explicit query:
SqlExpression<Customer> q = db.From<Customer>();
q.Join<Customer,CustomerAddress>((cust,address) => cust.Id == address.CustomerId);
List<Customer> dbCustomers = db.Select(q);The above query implicitly joins together the Customer and CustomerAddress POCO's using the same {ParentType}Id property convention used in OrmLite's support for References, e.g:
class Customer {
public int Id { get; set; }
...
}
class CustomerAddress {
public int Id { get; set; }
public int CustomerId { get; set; } // Reference based on Property name convention
}References based on matching alias names is also supported, e.g:
[Alias("LegacyCustomer")]
class Customer {
public int Id { get; set; }
...
}
class CustomerAddress {
public int Id { get; set; }
[Alias("LegacyCustomerId")] // Matches `LegacyCustomer` Alias
public int RenamedCustomerId { get; set; } // Reference based on Alias Convention
}Self References are also supported for 1:1 relations where the Foreign Key can instead be on the parent table:
public class Customer
{
...
public int CustomerAddressId { get; set; }
[Reference]
public CustomerAddress PrimaryAddress { get; set; }
}References that don't follow the above naming conventions can be declared explicitly using
the [References] and [ForeignKey] attributes:
public class Customer
{
[References(typeof(CustomerAddress))]
public int PrimaryAddressId { get; set; }
[Reference]
public CustomerAddress PrimaryAddress { get; set; }
}Reference Attributes take precedence over naming conventions
The example below shows a customer with multiple CustomerAddress references which are able to be matched with
the {PropertyReference}Id naming convention, e.g:
public class Customer
{
[AutoIncrement]
public int Id { get; set; }
public string Name { get; set; }
[References(typeof(CustomerAddress))]
public int? HomeAddressId { get; set; }
[References(typeof(CustomerAddress))]
public int? WorkAddressId { get; set; }
[Reference]
public CustomerAddress HomeAddress { get; set; }
[Reference]
public CustomerAddress WorkAddress { get; set; }
}Once defined, it can be saved and loaded via OrmLite's normal Reference and Select API's, e.g:
var customer = new Customer
{
Name = "The Customer",
HomeAddress = new CustomerAddress {
Address = "1 Home Street",
Country = "US"
},
WorkAddress = new CustomerAddress {
Address = "2 Work Road",
Country = "UK"
},
};
db.Save(customer, references:true);
var c = db.LoadSelect<Customer>(q => q.Name == "The Customer");
c.WorkAddress.Address.Print(); // 2 Work Road
var ukAddress = db.Single<CustomerAddress>(q => q.Country == "UK");
ukAddress.Address.Print(); // 2 Work RoadThe implicit relationship above allows you to use any of these equilvalent APIs to JOIN tables:
q.Join<CustomerAddress>();
q.Join<Customer,CustomerAddress>();
q.Join<Customer,CustomerAddress>((cust,address) => cust.Id == address.CustomerId);Another implicit behaviour when selecting from a typed SqlExpression is that results are mapped to the Customer POCO. To change this default we just need to explicitly specify what POCO it should map to instead:
List<FullCustomerInfo> customers = db.Select<FullCustomerInfo>(
db.From<Customer>().Join<CustomerAddress>());Where FullCustomerInfo is any POCO that contains a combination of properties matching any of the joined tables in the query.
The above example is also equivalent to the shorthand db.Select<Into,From>() API:
var customers = db.Select<FullCustomerInfo,Customer>(q => q.Join<CustomerAddress>());Rules for how results are mapped is simply each property on FullCustomerInfo is mapped to the first matching property in any of the tables in the order they were added to the SqlExpression.
The mapping also includes a fallback for referencing fully-qualified names in the format: {TableName}{FieldName} allowing you to reference ambiguous fields, e.g:
CustomerId=> "Customer"."Id"OrderId=> "Order"."Id"CustomerName=> "Customer"."Name"OrderCost=> "Order"."Cost"
Seeing how the SqlExpression is constructed, joined and mapped, we can take a look at a more advanced example to showcase more of the new API's available:
List<FullCustomerInfo> rows = db.Select<FullCustomerInfo>( // Map results to FullCustomerInfo POCO
db.From<Customer>() // Create typed Customer SqlExpression
.LeftJoin<CustomerAddress>() // Implict left join with base table
.Join<Customer, Order>((c,o) => c.Id == o.CustomerId) // Explicit join and condition
.Where(c => c.Name == "Customer 1") // Implicit condition on base table
.And<Order>(o => o.Cost < 2) // Explicit condition on joined Table
.Or<Customer,Order>((c,o) => c.Name == o.LineItem)); // Explicit condition with joined TablesThe comments next to each line document each Type of API used. Some of the new API's introduced in this example include:
- Usage of
LeftJoinfor specifying a LEFT JOIN,RightJoinandFullJoinalso available - Usage of
And<Table>(), to specify an AND condition on a Joined table - Usage of
Or<Table1,Table2>, to specify an OR condition against 2 joined tables
More code examples of References and Joined tables are available in:
OrmLite lets you Store and Load related entities in separate tables using [Reference] attributes in primary tables in conjunction with {Parent}Id property convention in child tables, e.g:
public class Customer
{
[AutoIncrement]
public int Id { get; set; }
public string Name { get; set; }
[Reference] // Save in CustomerAddress table
public CustomerAddress PrimaryAddress { get; set; }
[Reference] // Save in Order table
public List<Order> Orders { get; set; }
}
public class CustomerAddress
{
[AutoIncrement]
public int Id { get; set; }
public int CustomerId { get; set; } //`{Parent}Id` convention to refer to Customer
public string AddressLine1 { get; set; }
public string AddressLine2 { get; set; }
public string City { get; set; }
public string State { get; set; }
public string Country { get; set; }
}
public class Order
{
[AutoIncrement]
public int Id { get; set; }
public int CustomerId { get; set; } //`{Parent}Id` convention to refer to Customer
public string LineItem { get; set; }
public int Qty { get; set; }
public decimal Cost { get; set; }
}With the above structure you can save a POCO and all its entity references with db.Save(T,references:true), e.g:
var customer = new Customer {
Name = "Customer 1",
PrimaryAddress = new CustomerAddress {
AddressLine1 = "1 Australia Street",
Country = "Australia"
},
Orders = new[] {
new Order { LineItem = "Line 1", Qty = 1, Cost = 1.99m },
new Order { LineItem = "Line 2", Qty = 2, Cost = 2.99m },
}.ToList(),
};
db.Save(customer, references:true);This saves the root customer POCO in the Customer table, its related PrimaryAddress in the CustomerAddress table and its 2 Orders in the Order table.
The Load* API's are used to automatically load a POCO and all it's child references, e.g:
var customer = db.LoadSingleById<Customer>(customerId);Using Typed SqlExpressions:
var customers = db.LoadSelect<Customer>(q => q.Name == "Customer 1");More examples available in LoadReferencesTests.cs
Unlike normal complex properties, references:
- Doesn't persist as complex type blobs
- Doesn't impact normal querying
- Saves and loads references independently from itself
- Are serializable with Text serializers (only populated are visible).
- Loads related data only 1-reference-level deep
Basically they provides a better story when dealing with referential data that doesn't impact the POCO's ability to be used as DTO's.
The Merge extension method can stitch disconnected POCO collections together as per their relationships defined in OrmLite's POCO References.
For example you can select a collection of Customers who've made an order with quantities of 10 or more and in a separate query select their filtered Orders and then merge the results of these 2 distinct queries together with:
//Select Customers who've had orders with Quantities of 10 or more
List<Customer> customers = db.Select<Customer>(q =>
q.Join<Order>()
.Where<Order>(o => o.Qty >= 10)
.SelectDistinct());
//Select Orders with Quantities of 10 or more
List<Order> orders = db.Select<Order>(o => o.Qty >= 10);
customers.Merge(orders); // Merge disconnected Orders with their related Customers
customers.PrintDump(); // Print merged customers and orders datasetsOptimistic concurrency can be added to any table by adding the ulong RowVersion { get; set; } property, e.g:
public class Poco
{
...
public ulong RowVersion { get; set; }
}RowVersion is implemented efficiently in all major RDBMS's, i.e:
- Uses
rowversiondatatype in SqlServer - Uses PostgreSql's
xminsystem column (no column on table required) - Uses UPDATE triggers on MySql, Sqlite and Oracle whose lifetime is attached to Create/Drop tables APIs
Despite their differing implementations each provider works the same way where the RowVersion property is populated when the record is selected and only updates the record if the RowVersion matches with what's in the database, e.g:
var rowId = db.Insert(new Poco { Text = "Text" }, selectIdentity:true);
var row = db.SingleById<Poco>(rowId);
row.Text += " Updated";
db.Update(row); //success!
row.Text += "Attempting to update stale record";
//Can't update stale record
Assert.Throws<OptimisticConcurrencyException>(() =>
db.Update(row));
//Can update latest version
var updatedRow = db.SingleById<Poco>(rowId); // fresh version
updatedRow.Text += "Update Success!";
db.Update(updatedRow);
updatedRow = db.SingleById<Poco>(rowId);
db.Delete(updatedRow); // can delete fresh versionOptimistic concurrency is only verified on API's that update or delete an entire entity, i.e. it's not enforced in partial updates. There's also an Alternative API available for DELETE's:
db.DeleteById<Poco>(id:updatedRow.Id, rowversion:updatedRow.RowVersion)OrmLite's core Exec filters makes it possible to inject your own behavior, tracing, profiling, etc.
It's useful in situations like wanting to use SqlServer in production but use an in-memory Sqlite database in tests and being able to emulate any missing SQL Server Stored Procedures in code:
public class MockStoredProcExecFilter : OrmLiteExecFilter
{
public override T Exec<T>(IDbConnection dbConn, Func<IDbCommand, T> filter)
{
try
{
return base.Exec(dbConn, filter);
}
catch (Exception ex)
{
if (dbConn.GetLastSql() == "exec sp_name @firstName, @age")
return (T)(object)new Person { FirstName = "Mocked" };
throw;
}
}
}
OrmLiteConfig.ExecFilter = new MockStoredProcExecFilter();
using (var db = OpenDbConnection())
{
var person = db.SqlScalar<Person>("exec sp_name @firstName, @age",
new { firstName = "aName", age = 1 });
person.FirstName.Print(); //Mocked
}Results filters makes it trivial to implement the CaptureSqlFilter which allows you to capture SQL Statements without running them, e.g:
CaptureSqlFilter is an simple Results Filter which can be used to quickly found out what SQL your DB calls generate by surrounding DB access in a using scope like:
using (var captured = new CaptureSqlFilter())
using (var db = OpenDbConnection())
{
db.Where<Person>(new { Age = 27 });
captured.SqlCommandHistory[0].PrintDump();
}Emits the Executed SQL along with any DB Parameters:
{
Sql: "SELECT ""Id"", ""FirstName"", ""LastName"", ""Age"" FROM ""Person"" WHERE ""Age"" = @Age",
Parameters:
{
Age: 27
}
}
Or if you want to do things like executing each operation multiple times, e.g:
public class ReplayOrmLiteExecFilter : OrmLiteExecFilter
{
public int ReplayTimes { get; set; }
public override T Exec<T>(IDbConnection dbConn, Func<IDbCommand, T> filter)
{
var holdProvider = OrmLiteConfig.DialectProvider;
var dbCmd = CreateCommand(dbConn);
try
{
var ret = default(T);
for (var i = 0; i < ReplayTimes; i++)
{
ret = filter(dbCmd);
}
return ret;
}
finally
{
DisposeCommand(dbCmd);
OrmLiteConfig.DialectProvider = holdProvider;
}
}
}
OrmLiteConfig.ExecFilter = new ReplayOrmLiteExecFilter { ReplayTimes = 3 };
using (var db = OpenDbConnection())
{
db.DropAndCreateTable<PocoTable>();
db.Insert(new PocoTable { Name = "Multiplicity" });
var rowsInserted = db.Count<PocoTable>(q => q.Name == "Multiplicity"); //3
}The Result Filters also lets you easily mock results and avoid hitting the database, typically useful in Unit Testing Services to mock OrmLite API's directly instead of using a repository, e.g:
using (new OrmLiteResultsFilter {
PrintSql = true,
SingleResult = new Person {
Id = 1, FirstName = "Mocked", LastName = "Person", Age = 100
},
})
{
db.Single<Person>(x => x.Age == 42).FirstName // Mocked
db.Single(db.From<Person>().Where(x => x.Age == 42)).FirstName // Mocked
db.Single<Person>(new { Age = 42 }).FirstName // Mocked
db.Single<Person>("Age = @age", new { age = 42 }).FirstName // Mocked
}More examples showing how to mock different API's including support for nesting available in MockAllApiTests.cs
There's also a specific filter for strings available which allows you to apply custom sanitization on String fields, e.g. you can ensure all strings are right trimmed with:
OrmLiteConfig.StringFilter = s => s.TrimEnd();
db.Insert(new Poco { Name = "Value with trailing " });
db.Select<Poco>().First().Name // "Value with trailing"Pluggable serialization lets you specify different serialization strategies of Complex Types for each available RDBMS provider, e.g:
//ServiceStack's JSON and JSV Format
SqliteDialect.Provider.StringSerializer = new JsvStringSerializer();
PostgreSqlDialect.Provider.StringSerializer = new JsonStringSerializer();
//.NET's XML and JSON DataContract serializers
SqlServerDialect.Provider.StringSerializer = new DataContractSerializer();
MySqlDialect.Provider.StringSerializer = new JsonDataContractSerializer();
//.NET XmlSerializer
OracleDialect.Provider.StringSerializer = new XmlSerializableSerializer();You can also provide a custom serialization strategy by implementing IStringSerializer.
By default all dialects use the existing JsvStringSerializer, except for PostgreSQL which due to its built-in support for JSON, uses the JSON format by default.
Similar to interceptors in some heavy ORM's, Insert and Update filters get fired just before any INSERT or UPDATE operation using OrmLite's typed API's (i.e. not dynamic SQL or partial updates using anon types). This functionality can be used for easily auto-maintaining Audit information for your POCO data models, e.g:
public interface IAudit
{
DateTime CreatedDate { get; set; }
DateTime ModifiedDate { get; set; }
string ModifiedBy { get; set; }
}
OrmLiteConfig.InsertFilter = (dbCmd, row) => {
var auditRow = row as IAudit;
if (auditRow != null)
auditRow.CreatedDate = auditRow.ModifiedDate = DateTime.UtcNow;
};
OrmLiteConfig.UpdateFilter = (dbCmd, row) => {
var auditRow = row as IAudit;
if (auditRow != null)
auditRow.ModifiedDate = DateTime.UtcNow;
};Which will ensure that the CreatedDate and ModifiedDate fields are populated on every insert and update.
The filters can also be used for validation where throwing an exception will prevent the operation and bubble the exception, e.g:
OrmLiteConfig.InsertFilter = OrmLiteConfig.UpdateFilter = (dbCmd, row) => {
var auditRow = row as IAudit;
if (auditRow != null && auditRow.ModifiedBy == null)
throw new ArgumentNullException("ModifiedBy");
};
try
{
db.Insert(new AuditTable());
}
catch (ArgumentNullException) {
//throws ArgumentNullException
}
db.Insert(new AuditTable { ModifiedBy = "Me!" }); //succeedsA number of new hooks are available to provide more flexibility when creating and dropping your RDBMS tables.
The [CustomField] attribute can be used for specifying custom field declarations in the generated Create table DDL statements, e.g:
public class PocoTable
{
public int Id { get; set; }
[CustomField("CHAR(20)")]
public string CharColumn { get; set; }
[CustomField("DECIMAL(18,4)")]
public decimal? DecimalColumn { get; set; }
}
db.CreateTable<PocoTable>(); Generates and executes the following SQL:
CREATE TABLE "PocoTable"
(
"Id" INTEGER PRIMARY KEY,
"CharColumn" CHAR(20) NULL,
"DecimalColumn" DECIMAL(18,4) NULL
); Pre / Post Custom SQL Hooks allow you to inject custom SQL before and after tables are created or dropped, e.g:
[PostCreateTable("INSERT INTO TableWithSeedData (Name) VALUES ('Foo');" +
"INSERT INTO TableWithSeedData (Name) VALUES ('Bar');")]
public class TableWithSeedData
{
[AutoIncrement]
public int Id { get; set; }
public string Name { get; set; }
}Which like other ServiceStack attributes, can also be added dynamically, e.g:
typeof(TableWithSeedData)
.AddAttributes(new PostCreateTableAttribute(
"INSERT INTO TableWithSeedData (Name) VALUES ('Foo');" +
"INSERT INTO TableWithSeedData (Name) VALUES ('Bar');"));Custom SQL Hooks also allow executing custom SQL before and after a table has been created or dropped, i.e:
[PreCreateTable(runSqlBeforeTableCreated)]
[PostCreateTable(runSqlAfterTableCreated)]
[PreDropTable(runSqlBeforeTableDropped)]
[PostDropTable(runSqlAfterTableDropped)]
public class Table {}The IUntypedApi interface is useful for when you only have access to a late-bound object runtime type which is accessible via db.CreateTypedApi, e.g:
public class BaseClass
{
public int Id { get; set; }
}
public class Target : BaseClass
{
public string Name { get; set; }
}
var row = (BaseClass)new Target { Id = 1, Name = "Foo" };
var useType = row.GetType();
var typedApi = db.CreateTypedApi(useType);
db.DropAndCreateTables(useType);
typedApi.Save(row);
var typedRow = db.SingleById<Target>(1);
typedRow.Name //= Foo
var updateRow = (BaseClass)new Target { Id = 1, Name = "Bar" };
typedApi.Update(updateRow);
typedRow = db.SingleById<Target>(1);
typedRow.Name //= Bar
typedApi.Delete(typedRow, new { Id = 1 });
typedRow = db.SingleById<Target>(1); //= nullOrmLite's T4 Template are useful in database-first development or when wanting to use OrmLite with an existing RDBMS by automatically generating POCO's and strong-typed wrappers for executing stored procedures.
OrmLite's T4 support can be added via NuGet with:
PM> Install-Package ServiceStack.OrmLite.T4
The Custom SQL API's allow you to map custom SqlExpressions into different responses:
List<Person> results = db.SqlList<Person>(
db.From<Person>().Select("*").Where(q => q.Age < 50));
List<Person> results = db.SqlList<Person>(
"SELECT * FROM Person WHERE Age < @age", new { age=50});
List<string> results = db.SqlColumn<string>(db.From<Person>().Select(x => x.LastName));
List<string> results = db.SqlColumn<string>("SELECT LastName FROM Person");
HashSet<int> results = db.ColumnDistinct<int>(db.From<Person>().Select(x => x.Age));
HashSet<int> results = db.ColumnDistinct<int>("SELECT Age FROM Person");
int result = db.SqlScalar<int>(
db.From<Person>().Select(Sql.Count("*")).Where(q => q.Age < 50));
int result = db.SqlScalar<int>("SELCT COUNT(*) FROM Person WHERE Age < 50");The Raw SQL API's provide a convenient way for mapping results of any Custom SQL like executing Stored Procedures:
List<Poco> results = db.SqlList<Poco>("EXEC GetAnalyticsForWeek 1");
List<Poco> results = db.SqlList<Poco>(
"EXEC GetAnalyticsForWeek @weekNo", new { weekNo = 1 });
List<int> results = db.SqlList<int>("EXEC GetTotalsForWeek 1");
List<int> results = db.SqlList<int>(
"EXEC GetTotalsForWeek @weekNo", new { weekNo = 1 });
int result = db.SqlScalar<int>("SELECT 10");The SqlProc API provides even greater customization by letting you modify the underlying
ADO.NET Stored Procedure call by returning a prepared IDbCommand allowing for
advanced customization like setting and retriving OUT parameters, e.g:
string spSql = @"DROP PROCEDURE IF EXISTS spSearchLetters;
CREATE PROCEDURE spSearchLetters (IN pLetter varchar(10), OUT pTotal int)
BEGIN
SELECT COUNT(*) FROM LetterFrequency WHERE Letter = pLetter INTO pTotal;
SELECT * FROM LetterFrequency WHERE Letter = pLetter;
END";
db.ExecuteSql(spSql);
using (var cmd = db.SqlProc("spSearchLetters", new { pLetter = "C" }))
{
var pTotal = cmd.AddParam("pTotal", direction: ParameterDirection.Output);
var results = cmd.ConvertToList<LetterFrequency>();
var total = pTotal.Value;
}An alternative approach is to use SqlList which lets you use a filter to customize a
Stored Procedure or any other command type, e.g:
IDbDataParameter pTotal = null;
var results = db.SqlList<LetterFrequency>("spSearchLetters", cmd => {
cmd.CommandType = CommandType.StoredProcedure;
cmd.AddParam("pLetter", "C");
pTotal = cmd.AddParam("pTotal", direction: ParameterDirection.Output);
});
var total = pTotal.Value;More examples can be found in SqlServerProviderTests.
Creating a foreign key in OrmLite can be done by adding [References(typeof(ForeignKeyTable))] on the relation property,
which will result in OrmLite creating the Foreign Key relationship when it creates the DB table with db.CreateTable<Poco>.
@brainless83 has extended this support further by adding more finer-grain options
and behaviours with the new [ForeignKey] attribute which will now let you specify the desired behaviour when deleting
or updating related rows in Foreign Key tables.
An example of a table with all the different options:
public class TableWithAllCascadeOptions
{
[AutoIncrement] public int Id { get; set; }
[References(typeof(ForeignKeyTable1))]
public int SimpleForeignKey { get; set; }
[ForeignKey(typeof(ForeignKeyTable2), OnDelete = "CASCADE", OnUpdate = "CASCADE")]
public int? CascadeOnUpdateOrDelete { get; set; }
[ForeignKey(typeof(ForeignKeyTable3), OnDelete = "NO ACTION")]
public int? NoActionOnCascade { get; set; }
[Default(typeof(int), "17")]
[ForeignKey(typeof(ForeignKeyTable4), OnDelete = "SET DEFAULT")]
public int SetToDefaultValueOnDelete { get; set; }
[ForeignKey(typeof(ForeignKeyTable5), OnDelete = "SET NULL")]
public int? SetToNullOnDelete { get; set; }
}The ForeignKeyTests show the resulting behaviour with each of these configurations in more detail.
Note: Only supported on RDBMS's with foreign key/referential action support, e.g. Sql Server, PostgreSQL, MySQL. Otherwise they're ignored.
We now support multiple nested database connections so you can now trivially use OrmLite to access multiple databases
on different connections. The OrmLiteConnectionFactory class has been extended to support named connections which
allows you to conveniently define all your db connections when you register it in your IOC and access them with the
named property when you use them.
A popular way of scaling RDBMS's is to create a Master / Shard setup where datasets for queries that span entire system are kept in the master database, whilst context-specific related data can be kept together in an isolated shard. This feature makes it trivial to maintain multiple separate db shards with a master database in a different RDBMS.
Here's an (entire source code) sample of the code needed to define, and populate a Master/Shard setup. Sqlite can create DB shards on the fly so only the blank SqlServer master database needed to be created out-of-band:
public class MasterRecord {
public Guid Id { get; set; }
public int RobotId { get; set; }
public string RobotName { get; set; }
public DateTime? LastActivated { get; set; }
}
public class Robot {
public int Id { get; set; }
public string Name { get; set; }
public bool IsActivated { get; set; }
public long CellCount { get; set; }
public DateTime CreatedDate { get; set; }
}
const int NoOfShards = 10;
const int NoOfRobots = 1000;
var dbFactory = new OrmLiteConnectionFactory(
"Data Source=host;Initial Catalog=RobotsMaster;Integrated Security=SSPI", //Connection String
SqlServerDialect.Provider);
dbFactory.Run(db => db.CreateTable<MasterRecord>(overwrite:false));
NoOfShards.Times(i => {
var namedShard = "robots-shard" + i;
dbFactory.RegisterConnection(namedShard,
"~/App_Data/{0}.sqlite".Fmt(shardId).MapAbsolutePath(), //Connection String
SqliteDialect.Provider);
dbFactory.OpenDbConnection(namedShard).Run(db => db.CreateTable<Robot>(overwrite:false));
});
var newRobots = NoOfRobots.Times(i => //Create 1000 Robots
new Robot { Id=i, Name="R2D"+i, CreatedDate=DateTime.UtcNow, CellCount=DateTime.Now.ToUnixTimeMs() % 100000 });
foreach (var newRobot in newRobots)
{
using (IDbConnection db = dbFactory.OpenDbConnection()) //Open Connection to Master DB
{
db.Insert(new MasterRecord { Id = Guid.NewGuid(), RobotId = newRobot.Id, RobotName = newRobot.Name });
using (IDbConnection robotShard = dbFactory.OpenDbConnection("robots-shard"+newRobot.Id % NoOfShards)) //Shard
{
robotShard.Insert(newRobot);
}
}
}Using the SQLite Manager Firefox extension
we can peek at one of the created shards to see 100 Robots in each shard. This is the dump of robots-shard0.sqlite:

As expected each shard has every 10th robot inside.
Below is a complete stand-alone example. No other config or classes is required for it to run. It's also available as a stand-alone unit test.
public enum PhoneType {
Home,
Work,
Mobile,
}
public enum AddressType {
Home,
Work,
Other,
}
public class Address {
public string Line1 { get; set; }
public string Line2 { get; set; }
public string ZipCode { get; set; }
public string State { get; set; }
public string City { get; set; }
public string Country { get; set; }
}
public class Customer {
public Customer() {
this.PhoneNumbers = new Dictionary<PhoneType, string>();
this.Addresses = new Dictionary<AddressType, Address>();
}
[AutoIncrement] // Creates Auto primary key
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
[Index(Unique = true)] // Creates Unique Index
public string Email { get; set; }
public Dictionary<PhoneType, string> PhoneNumbers { get; set; } //Blobbed
public Dictionary<AddressType, Address> Addresses { get; set; } //Blobbed
public DateTime CreatedAt { get; set; }
}
public class Order {
[AutoIncrement]
public int Id { get; set; }
[References(typeof(Customer))] //Creates Foreign Key
public int CustomerId { get; set; }
[References(typeof(Employee))] //Creates Foreign Key
public int EmployeeId { get; set; }
public Address ShippingAddress { get; set; } //Blobbed (no Address table)
public DateTime? OrderDate { get; set; }
public DateTime? RequiredDate { get; set; }
public DateTime? ShippedDate { get; set; }
public int? ShipVia { get; set; }
public decimal Freight { get; set; }
public decimal Total { get; set; }
}
public class OrderDetail {
[AutoIncrement]
public int Id { get; set; }
[References(typeof(Order))] //Creates Foreign Key
public int OrderId { get; set; }
public int ProductId { get; set; }
public decimal UnitPrice { get; set; }
public short Quantity { get; set; }
public decimal Discount { get; set; }
}
public class Employee {
public int Id { get; set; }
public string Name { get; set; }
}
public class Product {
public int Id { get; set; }
public string Name { get; set; }
public decimal UnitPrice { get; set; }
}
//Setup SQL Server Connection Factory
var dbFactory = new OrmLiteConnectionFactory(
@"Data Source=.\SQLEXPRESS;AttachDbFilename=|DataDirectory|\App_Data\Database1.mdf;Integrated Security=True;User Instance=True",
SqlServerDialect.Provider);
//Use in-memory Sqlite DB instead
//var dbFactory = new OrmLiteConnectionFactory(
// ":memory:", false, SqliteDialect.Provider);
//Non-intrusive: All extension methods hang off System.Data.* interfaces
using (IDbConnection db = Config.OpenDbConnection())
{
//Re-Create all table schemas:
db.DropTable<OrderDetail>();
db.DropTable<Order>();
db.DropTable<Customer>();
db.DropTable<Product>();
db.DropTable<Employee>();
db.CreateTable<Employee>();
db.CreateTable<Product>();
db.CreateTable<Customer>();
db.CreateTable<Order>();
db.CreateTable<OrderDetail>();
db.Insert(new Employee { Id = 1, Name = "Employee 1" });
db.Insert(new Employee { Id = 2, Name = "Employee 2" });
var product1 = new Product { Id = 1, Name = "Product 1", UnitPrice = 10 };
var product2 = new Product { Id = 2, Name = "Product 2", UnitPrice = 20 };
db.Save(product1, product2);
var customer = new Customer {
FirstName = "Orm",
LastName = "Lite",
Email = "ormlite@servicestack.net",
PhoneNumbers =
{
{ PhoneType.Home, "555-1234" },
{ PhoneType.Work, "1-800-1234" },
{ PhoneType.Mobile, "818-123-4567" },
},
Addresses =
{
{ AddressType.Work, new Address {
Line1 = "1 Street", Country = "US", State = "NY", City = "New York", ZipCode = "10101" }
},
},
CreatedAt = DateTime.UtcNow,
};
var customerId = db.Insert(customer, selectIdentity: true); //Get Auto Inserted Id
customer = db.Single<Customer>(new { customer.Email }); //Query
Assert.That(customer.Id, Is.EqualTo(customerId));
//Direct access to System.Data.Transactions:
using (IDbTransaction trans = db.OpenTransaction(IsolationLevel.ReadCommitted))
{
var order = new Order {
CustomerId = customer.Id,
EmployeeId = 1,
OrderDate = DateTime.UtcNow,
Freight = 10.50m,
ShippingAddress = new Address {
Line1 = "3 Street", Country = "US", State = "NY", City = "New York", ZipCode = "12121" },
};
db.Save(order); //Inserts 1st time
//order.Id populated on Save().
var orderDetails = new[] {
new OrderDetail {
OrderId = order.Id,
ProductId = product1.Id,
Quantity = 2,
UnitPrice = product1.UnitPrice,
},
new OrderDetail {
OrderId = order.Id,
ProductId = product2.Id,
Quantity = 2,
UnitPrice = product2.UnitPrice,
Discount = .15m,
}
};
db.Save(orderDetails);
order.Total = orderDetails.Sum(x => x.UnitPrice * x.Quantity * x.Discount) + order.Freight;
db.Save(order); //Updates 2nd Time
trans.Commit();
}
}Running this against a SQL Server database will yield the results below:

Notice the POCO types are stored in the very fast and Versatile JSV Format which although hard to do - is actually more compact, human and parser-friendly than JSON :)
You may use the [Ignore] attribute to denote DTO properties that are not fields in the table. This will force the SQL generation to ignore that property.
In its simplest useage, OrmLite can persist any POCO type without any attributes required:
public class SimpleExample
{
public int Id { get; set; }
public string Name { get; set; }
}
//Set once before use (i.e. in a static constructor).
OrmLiteConfig.DialectProvider = SqliteDialect.Provider;
using (IDbConnection db = "/path/to/db.sqlite".OpenDbConnection())
{
db.CreateTable<SimpleExample>(true);
db.Insert(new SimpleExample { Id=1, Name="Hello, World!"});
var rows = db.Select<SimpleExample>();
Assert.That(rows, Has.Count(1));
Assert.That(rows[0].Id, Is.EqualTo(1));
}To get a better idea of the features of OrmLite lets walk through a complete example using sample tables from the Northwind database. _ (Full source code for this example is available here.) _
So with no other configuration using only the classes below:
[Alias("Shippers")]
public class Shipper
: IHasId<int>
{
[AutoIncrement]
[Alias("ShipperID")]
public int Id { get; set; }
[Required]
[Index(Unique = true)]
[StringLength(40)]
public string CompanyName { get; set; }
[StringLength(24)]
public string Phone { get; set; }
[References(typeof(ShipperType))]
public int ShipperTypeId { get; set; }
}
[Alias("ShipperTypes")]
public class ShipperType
: IHasId<int>
{
[AutoIncrement]
[Alias("ShipperTypeID")]
public int Id { get; set; }
[Required]
[Index(Unique = true)]
[StringLength(40)]
public string Name { get; set; }
}
public class SubsetOfShipper
{
public int ShipperId { get; set; }
public string CompanyName { get; set; }
}
public class ShipperTypeCount
{
public int ShipperTypeId { get; set; }
public int Total { get; set; }
}Creating tables is a simple 1-liner:
using (IDbConnection db = ":memory:".OpenDbConnection())
{
db.CreateTable<ShipperType>();
db.CreateTable<Shipper>();
}
/* In debug mode the line above prints:
DEBUG: CREATE TABLE "ShipperTypes"
(
"ShipperTypeID" INTEGER PRIMARY KEY AUTOINCREMENT,
"Name" VARCHAR(40) NOT NULL
);
DEBUG: CREATE UNIQUE INDEX uidx_shippertypes_name ON "ShipperTypes" ("Name" ASC);
DEBUG: CREATE TABLE "Shippers"
(
"ShipperID" INTEGER PRIMARY KEY AUTOINCREMENT,
"CompanyName" VARCHAR(40) NOT NULL,
"Phone" VARCHAR(24) NULL,
"ShipperTypeId" INTEGER NOT NULL,
CONSTRAINT "FK_Shippers_ShipperTypes" FOREIGN KEY ("ShipperTypeId") REFERENCES "ShipperTypes" ("ShipperID")
);
DEBUG: CREATE UNIQUE INDEX uidx_shippers_companyname ON "Shippers" ("CompanyName" ASC);
*/As we have direct access to IDbCommand and friends - playing with transactions is easy:
var trainsType = new ShipperType { Name = "Trains" };
var planesType = new ShipperType { Name = "Planes" };
//Playing with transactions
using (IDbTransaction dbTrans = db.OpenTransaction())
{
db.Save(trainsType);
db.Save(planesType);
dbTrans.Commit();
}
using (IDbTransaction dbTrans = db.OpenTransaction(IsolationLevel.ReadCommitted))
{
db.Insert(new ShipperType { Name = "Automobiles" });
Assert.That(db.Select<ShipperType>(), Has.Count.EqualTo(3));
}
Assert.That(db.Select<ShipperType>(), Has.Count(2));No ORM is complete without the standard crud operations:
//Performing standard Insert's and Selects
db.Insert(new Shipper { CompanyName = "Trains R Us", Phone = "555-TRAINS", ShipperTypeId = trainsType.Id });
db.Insert(new Shipper { CompanyName = "Planes R Us", Phone = "555-PLANES", ShipperTypeId = planesType.Id });
db.Insert(new Shipper { CompanyName = "We do everything!", Phone = "555-UNICORNS", ShipperTypeId = planesType.Id });
var trainsAreUs = db.SingleFmt<Shipper>("ShipperTypeId = {0}", trainsType.Id);
Assert.That(trainsAreUs.CompanyName, Is.EqualTo("Trains R Us"));
Assert.That(db.SelectFmt<Shipper>("CompanyName = {0} OR Phone = {1}", "Trains R Us", "555-UNICORNS"), Has.Count.EqualTo(2));
Assert.That(db.SelectFmt<Shipper>("ShipperTypeId = {0}", planesType.Id), Has.Count.EqualTo(2));
//Lets update a record
trainsAreUs.Phone = "666-TRAINS";
db.Update(trainsAreUs);
Assert.That(db.SingleById<Shipper>(trainsAreUs.Id).Phone, Is.EqualTo("666-TRAINS"));
//Then make it dissappear
db.Delete(trainsAreUs);
Assert.That(db.SingleById<Shipper>(trainsAreUs.Id), Is.Null);
//And bring it back again
db.Insert(trainsAreUs);And with access to raw sql when you need it - the database is your oyster :)
var partialColumns = db.SelectFmt<SubsetOfShipper>(typeof (Shipper), "ShipperTypeId = {0}", planesType.Id);
Assert.That(partialColumns, Has.Count.EqualTo(2));
//Select into another POCO class that matches sql
var rows = db.SelectFmt<ShipperTypeCount>(
"SELECT ShipperTypeId, COUNT(*) AS Total FROM Shippers GROUP BY ShipperTypeId ORDER BY COUNT(*)");
Assert.That(rows, Has.Count.EqualTo(2));
Assert.That(rows[0].ShipperTypeId, Is.EqualTo(trainsType.Id));
Assert.That(rows[0].Total, Is.EqualTo(1));
Assert.That(rows[1].ShipperTypeId, Is.EqualTo(planesType.Id));
Assert.That(rows[1].Total, Is.EqualTo(2));
//And finally lets quickly clean up the mess we've made:
db.DeleteAll<Shipper>();
db.DeleteAll<ShipperType>();
Assert.That(db.Select<Shipper>(), Has.Count.EqualTo(0));
Assert.That(db.Select<ShipperType>(), Has.Count.EqualTo(0));For simplicity, and to be able to have the same POCO class persisted in db4o, memcached, redis or on the filesystem (i.e. providers included in ServiceStack), each model must have a single primary key, by convention OrmLite expects it
to be Id although you use [Alias("DbFieldName")] attribute it map it to a column with a different name or use
the [PrimaryKey] attribute to tell OrmLite to use a different property for the primary key.
You can still SELECT from these tables, you will just be unable to make use of APIs that rely on it, e.g.
Update or Delete where the filter is implied (i.e. not specified), all the APIs that end with ById, etc.
A potential workaround to support tables with multiple primary keys is to create an auto generated Id property that
returns a unique value based on all the primary key fields, e.g:
public class OrderDetail
{
public string Id { get { return this.OrderId + "/" + this.ProductId; } }
public int OrderId { get; set; }
public int ProductId { get; set; }
public decimal UnitPrice { get; set; }
public short Quantity { get; set; }
public double Discount { get; set; }
}The Oracle provider requires an installation of Oracle's ODP.NET. It has been tested with Oracle 11g but should work with 10g and perhaps even older versions. It has not been tested with Oracle 12c and does not support any new 12c features such as AutoIncrement keys. It also does not support the new Oracle fully-managed client.
By default the Oracle provider stores Guids in the database as character strings and when generating SQL it quotes only table and column names that are reserved words in Oracle. That requires that you use the same quoting if you code your own SQL. Both of these options can be overridden, but overriding them will cause problems: the provider can store Guids as raw(16) but it cannot read them.
The Oracle provider uses Oracle sequences to implement AutoIncrement columns and it queries the sequence to get a new value in a separate database call. You can override the automatically generated sequence name with a
[Sequence("name")]
attribute on a field. The Sequence attribute implies [AutoIncrement], but you can use both on the same field.
Since Oracle has a very restrictive 30 character limit on names, it is strongly suggested that you use short entity class and field names or aliases, remembering that indexes and foreign keys get compound names. If you use long names, the provider will squash them to make them compliant with the restriction. The algorithm used is to remove all vowels ("aeiouy") and if still too long then every fourth letter starting with the third one and finally if still too long to truncate the name. You must apply the same squashing algorithm if you are coding your own SQL.
The previous version of ServiceStack.OrmLite.Oracle used System.Data.OracleClient to talk to the database. Microsoft has deprecated that client, but it does still mostly work if you construct the Oracle provider like this:
OracleOrmLiteDialectProvider.Instance = new OracleOrmLiteDialectProvider(
compactGuid: false,
quoteNames: false,
clientProvider: OracleOrmLiteDialectProvider.MicrosoftProvider);
DateTimeOffset fields and, in locales that use a comma to separate the fractional part of a floating point number, some aspects of using floating point numbers, do not work with System.Data.OracleClient.
- OrmLite and Redis: New alternatives for handling db communication by @abtosoftware
- Object Serialization as Step Towards Normalization by @ 82unpluggd
- Creating a Data Access Layer using OrmLite by Lydon Bergin
- Code Generation using ServiceStack.OrmLite and T4 Text templates by @jokecamp
- Simple ServiceStack OrmLite Example by @robrtc
- OrmLite Blobbing done with NHibernate and Serialized JSON by @philliphaydon
- Creating An ASP.NET MVC Blog With ServiceStack.OrmLite by @peterbromberg
Many performance problems can be mitigated and a lot of use-cases can be simplified without the use of a heavyweight ORM, and their config, mappings and infrastructure. As performance is the most important feature we can recommend the following list, each with their own unique special blend of features.
- Dapper - by @samsaffron and @marcgravell
- The current performance king, supports both POCO and dynamic access, fits in a single class. Put in production to solve StackOverflow's DB Perf issues. Requires .NET 4.
- PetaPoco - by @toptensoftware
- Fast, supports dynamics, expandos and typed POCOs, fits in a single class, runs on .NET 3.5 and Mono. Includes optional T4 templates for POCO table generation.
- Massive - by @robconery
- Fast, supports dynamics and expandos, smart use of optional params to provide a wrist-friendly api, fits in a single class. Multiple RDBMS support. Requires .NET 4.
- Simple.Data - by @markrendle
- A little slower than above ORMS, most wrist-friendly courtesy of a dynamic API, multiple RDBMS support inc. Mongo DB. Requires .NET 4.