{kind=link}


Milvus Lite is the lightweight version of Milvus, a high-performance vector database that powers AI applications with vector similarity search. This repo contains the core components of Milvus Lite.
With Milvus Lite, you can start building an AI application with vector similarity search within minutes! Milvus Lite is good for running in the following environment:
- Jupyter Notebook / Google Colab
- Laptops
- Edge Devices
Milvus Lite can be imported into your Python application, providing the core vector search functionality of Milvus. Milvus Lite is already included in the Python SDK of Milvus. To use it, you just need pip install pymilvus.
Milvus Lite uses the same API as Milvus Standalone and Distributed, providing a consistent experience across environments. Develop your GenAI applications once and run them anywhere: on a laptop or Jupyter Notebook with Milvus Lite, in a Docker container with Milvus Standalone, or on a K8s cluster with Milvus Distributed for large-scale production.
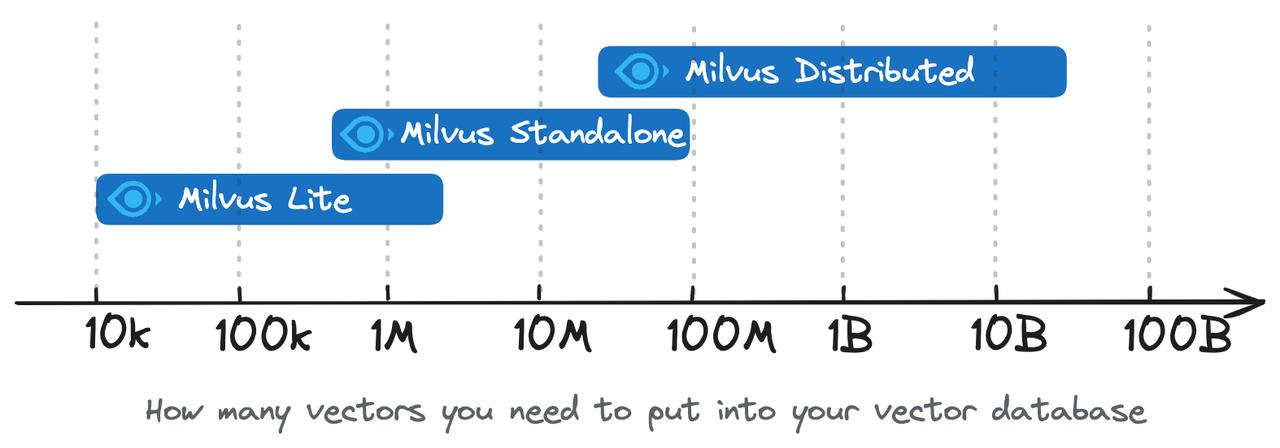
Milvus Lite is only suitable for small scale prototyping (usually less than a million vectors) or edge devices. For large scale production, we recommend using Milvus Standalone or Milvus Distributed. You can also consider the fully-managed Milvus on Zilliz Cloud.
Milvus Lite currently supports the following environmnets:
- Ubuntu >= 20.04 (x86_64 and arm64)
- MacOS >= 11.0 (Apple Silicon M1/M2 and x86_64)
Note: Windows is not yet supported.
pip install -U pymilvusWe recommend using pymilvus. Since milvus-lite is included in pymilvus version 2.4.2 or above, you can pip install with -U to force update to the latest version and milvus-lite is automatically installed.
If you want to explicitly install milvus-lite package, or you have installed an older version of milvus-lite and would like to update it, you can do pip install -U milvus-lite.
In pymilvus, specify a local file name as uri parameter of MilvusClient will use Milvus Lite.
from pymilvus import MilvusClient
client = MilvusClient("./milvus_demo.db")NOTE: Note that the same API also applies to Milvus Standalone, Milvus Distributed and Zilliz Cloud, the only difference is to replace local file name to remote server endpoint and credentials, e.g.
client = MilvusClient(uri="http://localhost:19530", token="username:password")for self-hosted Milvus server.
Following is a simple demo showing how to use Milvus Lite for text search. There are more comprehensive examples for using Milvus Lite to build applications such as RAG, image search, and using Milvus Lite in popular RAG framework such as LangChain and LlamaIndex!
from pymilvus import MilvusClient
import numpy as np
client = MilvusClient("./milvus_demo.db")
client.create_collection(
collection_name="demo_collection",
dimension=384 # The vectors we will use in this demo has 384 dimensions
)
# Text strings to search from.
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
# For illustration, here we use fake vectors with random numbers (384 dimension).
vectors = [[ np.random.uniform(-1, 1) for _ in range(384) ] for _ in range(len(docs)) ]
data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ]
res = client.insert(
collection_name="demo_collection",
data=data
)
# This will exclude any text in "history" subject despite close to the query vector.
res = client.search(
collection_name="demo_collection",
data=[vectors[0]],
filter="subject == 'history'",
limit=2,
output_fields=["text", "subject"],
)
print(res)
# a query that retrieves all entities matching filter expressions.
res = client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)
print(res)
# delete
res = client.delete(
collection_name="demo_collection",
filter="subject == 'history'",
)
print(res)Milvus Lite shares the same API as Milvus Standalone, Milvus Distributed and Zilliz Cloud, offering core features including:
- Insert/upsert operations
- Vector data persistence and collection management
- Dense, sparse, and hybrid vector search
- Metadata filtering
- Multi-vector support
Milvus Lite has limited index type support compared to other Milvus deployments:
-
Prior to version 2.4.11:
- Only supports the FLAT index type
- Uses FLAT index regardless of the specified index type in collection creation
-
Version 2.4.11 and later:
Milvus Lite does not support partitions, users/roles/RBAC, alias. To use those features, please choose other Milvus deployment types such as Standalone, Distributed or Zilliz Cloud (fully-managed Milvus).
All data stored in Milvus Lite can be easily exported and loaded into other types of Milvus deployment, such as Milvus Standalone on Docker, Milvus Distributed on K8s, or fully-managed Milvus on Zilliz Cloud.
Milvus Lite provides a command line tool that can dump data into a json file, which can be imported into self-hosted Milvus or fully-managed Milvus on Zilliz Cloud.
pip install -U "pymilvus[bulk_writer]"
# The `milvus-lite` command line tool is already included in `milvus-lite` package which is part of "pymilvus", but it also needs some dependencies from `pymilvus[bulk_writer]` for dumping data.
milvus-lite dump -h
usage: milvus-lite dump [-h] [-d DB_FILE] [-c COLLECTION] [-p PATH]
optional arguments:
-h, --help show this help message and exit
-d DB_FILE, --db-file DB_FILE
milvus lite db file
-c COLLECTION, --collection COLLECTION
collection that need to be dumped
-p PATH, --path PATH dump file storage dirThe following example dumps all data from demo_collection collection that's stored in ./milvus_demo.db (a user specified local file that persists data for Milvus Lite)
To export data:
milvus-lite dump -d ./milvus_demo.db -c demo_collection -p ./data_dir
# ./milvus_demo.db: milvus lite db file
# demo_collection: collection that need to be dumped
#./data_dir : dump file storage dirYou can use the dump file as input to upload data to Zilliz Cloud via Data Import, or a self-hosted Milvus server via Bulk Insert.
If you want to contribute to Milvus Lite, please read the Contributing Guide first.
For any bug or feature request, please report it by submitting an issue in milvus-lite repo.
Milvus Lite is under the Apache 2.0 license. See the LICENSE file for details.