This project addresses the problem of sarcasm detection - often quoted as a subtask of sentiment analysis. There are two main scripts used to begin using this code - train.py requires a fair amount of setup, however console.py can be run very quickly, so long as the correct dependencies are installed (listed below)
- train.py : trains and evaluates new models on chosen dataset, saving these models to Code/pkg/trained_models/
- To run train.py, follow the Data configuration and Setup instructions before proceeding
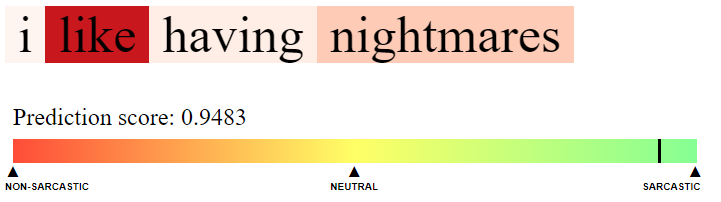
- console.py : makes predictions using existing trained models, where user input can be provided via a console. A visualisation of attention weights is produced in /colorise.html
- Our best-performing model, the Bidirectional Long Short-Term Memory model trained on ElMo vectors with Attention is provided to get started
- It is possible to interact with other models, however they will need to be trained first using train.py
To use this code, clone this repository then navigate to the root directory.
- Move to Code/, then:
- On Windows, execute the command "python console.py" or "python train.py"
- On Linux, execute the command "python3 console.py" or "python3 train.py"
- en-core-web-md == 2.2.5
- Keras == 2.3.1
- matplotlib == 3.1.3
- numpy == 1.18.0
- pandas == 0.25.3
- pycorenlp == 0.3.0
- scikit-learn == 0.22
- spacy == 2.2.3
- tensorflow == 2.1.0
- tensorflow-hub == 0.7.0
- tweepy == 3.8.0
- twitter == 1.18.0
Datasets can be collected from the following sources:
-
Twitter data - Ptáček et al. (2014):
- Collected from: http://liks.fav.zcu.cz/sarcasm/
- Uses the EN balanced corpus containing 100,000 tweet IDs that must be scraped from the Twitter API - Twitter scraper can be found in Code/pkg/datasets/ptacek/processing_scrips/TwitterCrawler
- Once downloaded, move normal.txt and sarcastic.txt (files from download) into Code/pkg/datasets/ptacek/raw_data\
-
News headlines - Misra et al. (2019):
- Data is downloaded in JSON format
- https://www.kaggle.com/rmisra/news-headlines-dataset-for-sarcasm-detection
- Once downloaded, move Sarcasm_Headlines_Dataset_v2.json (files from download) into Code/pkg/datasets/news_headlines/raw_data
-
Amazon reviews - Filatova et al. (2012):
- Data is downloaded in .rar format
- https://github.com/ef2020/SarcasmAmazonReviewsCorpus/
- Only Ironic.rar and Regular.rar is used in this project
- Convert Ironic.rar and Regular.rar (files from download) into regular folders, then move them to Code/pkg/datasets/amazon_reviews/raw_data
After downloading the data - proceed to reformat it into a csv and apply our data cleaning processes:
- Run p1_create_raw_csv.py followed by p2_clean_original_data.py to achieve the correct configuration => NOTE: p1_create_raw_csv.py will take some time on the Twitter dataset, as it is slow to scrape the Tweets given their ids
e.g. Code/pkg/datasets/news_headlines/
├── /processed_data
├── ...
├── /CleanData.csv
├── /OriginalData.csv
├── /processing_scripts/...
├── /raw_Data/...
Language models can be downloaded from the following sources:
-
ELMO:
- Download the ELMo tensorflow-hub module
- Move the elmo contents into a directory named elmo e.g. Code/pkg/language_models/elmo/
-
GloVe
- Download the GloVe database
- Select the glove.twitter.27B.50d.txt file and place it in a subdirectory called glove, e.g. Code/pkg/language_models/glove/