This repo contains my solutions for the exercises of https://devopswithkubernetes.com/.
Note: I created my solutions during the beta phase of the course.
- Solving the DevOps with Kubernetes MOOC
- Solutions for Part 1
- Solutions for Part 2
- Solutions for Part 3
- Exercise 3.01: deploy main app and ping/pong to GKE
- Exercise 3.02: automatic GKE deployment for project
- Exercise 3.03: Namespace from git branch
- Exercise 3.04: Deleting namespace when branch gets deleted
- Exercise 3.05: DBaaS pro/cons list
- Exercise 3.06: Deciding between using PersistentVolumeClaim or Cloud SQL
- Exercise 3.07 and 3.08: Resource limits
- Exercise 3.09: Monitoring with GKE
- Solutions for Part 4
- Solutions for Part 5
| exercise | solution in subfolder |
|---|---|
| 1.01 | hashgenerator |
| 1.02 | project |
| 1.03 | hashgenerator |
| 1.04 | project |
| 1.05 | project |
| 1.06 | project |
| 1.07 | hashgenerator |
| 1.08 | project |
| 1.09 | hashgenerator & pingpong |
| 1.10 | hashgenerator |
| 1.11 | hashgenerator |
| 1.12 | project |
| 1.13 | project |
Against better judgement I used the "latest" tag for some assignments and Kubernetes yaml configurations. That's why some solutions can't be played through again, because the automatically built Image at Docker Hub doesn't match the step of the solution anymore. This is especially true for the main application. The project on the other hand is logically tagged.
The solution for exercises are based on each other. For this reason, not all of them are documented here.
# Create ping/pong app with namespace
$ kubectl create namespace pingpong
namespace/pingpong created
$ kubectl apply -f pingpong/manifests/
deployment.apps/pingpong-dep created
ingress.extensions/pingpong-ingress created
service/pingpong-svc created
# test
$ curl -s http://localhost:8081/pingpong
{"counter":1}
# Create main app in namespace that fetches ping/pongs and prints uuid every 5secs
$ kubectl create namespace hashgenerator
namespace/hashgenerator created
$ kubectl apply -f hashgenerator/manifests/
deployment.apps/hashgenerator-dep created
ingress.extensions/hashgenerator-ingress created
service/hashgenerator-svc created
# test
$ curl -s http://localhost:8081/pingpong
{"counter":2}
$ curl -s http://localhost:8081/
2020-07-17T11:44:52.631Z: 4bdeb719-73cb-482f-b66c-40d04d0d880d<br> 2
# what's in the namespaces?
$ kubens pingpong
Context "k3s-default" modified.
Active namespace is "pingpong".
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/pingpong-dep-777dbbd675-5kvrr 1/1 Running 0 3m49s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/pingpong-svc ClusterIP 10.43.219.90 <none> 6789/TCP 3m49s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/pingpong-dep 1/1 1 1 3m49s
NAME DESIRED CURRENT READY AGE
replicaset.apps/pingpong-dep-777dbbd675 1 1 1 3m49s
$ kubens hashgenerator
Context "k3s-default" modified.
Active namespace is "hashgenerator".
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/hashgenerator-dep-66c9cc599d-wgkzg 2/2 Running 0 2m31s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/hashgenerator-svc ClusterIP 10.43.228.139 <none> 3001/TCP,2345/TCP 2m31s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hashgenerator-dep 1/1 1 1 2m31s
NAME DESIRED CURRENT READY AGE
replicaset.apps/hashgenerator-dep-66c9cc599d 1 1 1 2m31sConfigMaps for hashgenerator-server aka main application
$ kubectl config set-context --current --namespace=hashgenerator
# Create ConfigMap from `hashgenerator-env-file.properties`
$ cat hashgenerator/manifests/hashgenerator-env-file.properties
SERVER_PORT=3001
GENERATOR_PORT=3002
HASHGENERATOR_URL=http://hashgenerator-svc:2345/
PINGPONG_URL=http://pingpong-svc.pingpong:6789/pingpong
MESSAGE=Hello%
$ kubectl create configmap hashgenerator-config-env-file --from-env-file hashgenerator/manifests/hashgenerator-env-file.properties
configmap/hashgenerator-config-env-file created
# It's live
$ curl -s http://localhost:8081
Hello<br> 2020-07-17T17:25:59.300Z: 14c4d2ff-25f2-4b45-86b8-4b7e3b80b435<br> 13This spins up two pods. One Deployment with the ping/pong app and one StatefulSet with a PostgreSQL database container. During the creation of the database pod, the very very complex schema gets seeded. The database password is stored as as SealedSecret.
$ kubectl apply -f pingpong/manifests/
deployment.apps/pingpong-dep created
ingress.extensions/pingpong-ingress created
sealedsecret.bitnami.com/postgres-pw created
service/pingpong-svc created
service/postgres-pingpong-svc created
configmap/postgres-pingpong-seed created
statefulset.apps/postgres-pingpong-stateful created
$ curl -s http://localhost:8081/pingpong
{"counter":4}%
$ kubectl logs -f pingpong-dep-6bcb74f875-w5r72 pingpong
> pingpong@1.0.0 start /app
> node server.js
Writing to txt is disabled
NEVER log a db password to stdin: 'passw0rd'
Server started on: 3000
added a new ping to db
added a new ping to db
added a new ping to dbThe state of the todo application gets stored in a PostgreSQL database. The app is hooked up via Sequelize. The table gets created based on the Task model. For deployment the db connection parameter and password are stored and read from secret.yaml. This time around I'm not using SealedSecret. Only the backend and the deployment setup were changed.
$ kubectl apply -f project/manifests/
deployment.apps/project-dep created
ingress.extensions/project-ingress-frontend created
ingress.extensions/project-ingress-api-static created
persistentvolume/project-pv created
persistentvolumeclaim/project-claim created
secret/postgres-pw-url created
service/project-svc created
service/postgres-project-svc created
statefulset.apps/postgres-project-stateful created |
http://localhost:8081/project
|
I followed the steps in the course notes and installed Grafana and Loki via Helm. I added request logging via morgan to my project application.
$ kubectl apply -f project/manifests/
deployment.apps/project-dep created
ingress.extensions/project-ingress-frontend created
ingress.extensions/project-ingress-api-static created
# ...just like in the exercise beforeGrafana dashboard:
$ kubectl port-forward prometheus-operator-1595404775-grafana-7964b4fb7d-4hflq 3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Handling connection for 3000
From the final course:
Created Cronjob with:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: daily-todos
namespace: default
labels:
run: curl
spec:
schedule: "0 9 * * *" # every day at 09:00
jobTemplate:
spec:
template:
spec:
containers:
- name: curl
image: curlimages/curl:7.73.0
args:
- sh
- -c
- "echo -n 'Read: '; curl -sI https://en.wikipedia.org/wiki/Special:Random |grep 'location:' |awk '{print $2}'"
restartPolicy: OnFailureGet result of last run with:
$ kubectl logs $(kubectl get pod -o name |grep daily-todos| tail -1)
Read: https://en.wikipedia.org/wiki/Dungeons_%26_Dragons:_Wrath_of_the_Dragon_GodCreate cluster in Frankfurt with two nodes and connect to it:
$ gcloud container clusters create dwk-cluster --zone=europe-west3 --num-nodes=2
Creating cluster dwk-cluster in europe-west3... Cluster is being configured...Cluster is being deployed...Cluster is being health-checked...done.
Created [https://container.googleapis.com/v1/projects/dwk-gke-123456/zones/europe-west3/clusters/dwk-cluster].
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/europe-west3/dwk-cluster?project=dwk-gke-123456
kubeconfig entry generated for dwk-cluster.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
dwk-cluster europe-west3 1.15.12-gke.2 34.89.245.27 n1-standard-1 1.15.12-gke.2 6 RUNNING
$ gcloud container clusters get-credentials dwk-cluster --region europe-west3 --project dwk-gke-123456
Fetching cluster endpoint and auth data.
kubeconfig entry generated for dwk-clusterCreate ping/pong App with it's own public ip adress. So that external users can ping it via:http://EXTERNAL-IP/pingpong. The hashgenerator-server reaches it internally via http://pingpong-svc.pingpong:6789/pingpong
$ kubectl create namespace pingpong
namespace/pingpong created
$ kubectl apply -f pingpong/manifests-gke/
deployment.apps/pingpong-dep created
secret/postgres-pw created
service/pingpong-svc-loadbalancer created
service/pingpong-svc created
service/postgres-pingpong-svc created
configmap/postgres-pingpong-seed created
statefulset.apps/postgres-pingpong-stateful created
$ kubens pingpong
Context "gke_dwk-gke-123456_europe-west3_dwk-cluster" modified.
Active namespace is "pingpong".
# Wait for external IP...
$ kubectl get svc --watch
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
pingpong-svc ClusterIP 10.51.248.145 <none> 6789/TCP 42s
pingpong-svc-loadbalancer LoadBalancer 10.51.246.118 <pending> 80:31106/TCP 42s
postgres-pingpong-svc ClusterIP 10.51.255.120 <none> 5432/TCP 42s
pingpong-svc-loadbalancer LoadBalancer 10.51.246.118 34.89.233.5 80:31106/TCP 50s
ping to pong:
$ curl -s http://34.89.233.5/pingpong
{"counter":0}%
$ curl -s http://34.89.233.5/pingpong
{"counter":1}%Create the hashgenerator app + server:
$ kubectl create namespace hashgenerator
namespace/hashgenerator created
$ kubens hashgenerator
Context "gke_dwk-gke-123456_europe-west3_dwk-cluster" modified.
Active namespace is "hashgenerator".
$ kubectl apply -f hashgenerator/manifests-gke/
configmap/hashgenerator-config-env-file created
deployment.apps/hashgenerator-dep created
service/hashgenerator-svc-loadbalancer created
service/hashgenerator-svc created
# Wait for external IP address
$ kubectl get svc --watch
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hashgenerator-svc ClusterIP 10.51.249.229 <none> 2345/TCP 35s
hashgenerator-svc-loadbalancer LoadBalancer 10.51.241.121 <pending> 80:32281/TCP 35s
hashgenerator-svc-loadbalancer LoadBalancer 10.51.241.121 35.242.205.114 80:32281/TCP 42s
Both LoadBalancers should be running now:
$ kubectl get svc --all-namespaces | grep LoadBalancer
hashgenerator hashgenerator-svc-loadbalancer LoadBalancer 10.51.241.121 35.242.205.114 80:32281/TCP 6m17s
pingpong pingpong-svc-loadbalancer LoadBalancer 10.51.246.118 34.89.233.5 80:31106/TCP 10mIt works:
$ curl http://35.242.205.114/
Hello<br> 2020-07-27T16:55:59.611Z: 5fa214bc-a6a5-4fc7-ad28-8dd7c8bc0b53<br> 2%
$ kubectl logs hashgenerator-dep-5764f96cc5-jrq4z --all-containers
HASHGENERATOR_URL: http://hashgenerator-svc:2345/
HASHFILE_PATH: undefined
PINGPONG_URL: http://pingpong-svc.pingpong:6789/pingpong
PINGPONGFILE_PATH: undefined
Server started on: 3001
::ffff:10.48.5.1 requested a hashFile + pingPongFile
Writing to txt is disabled
Server started on: 3002
current: 2020-07-27T16:55:19.580Z: 6f2c833d-c268-4c92-a4a2-045710d48615
current: 2020-07-27T16:55:24.581Z: 2b83ff58-b42d-4bb4-9c9a-8937bfa9e8f9
current: 2020-07-27T16:55:29.586Z: 79261074-c50a-433e-8557-1d55269857d4
current: 2020-07-27T16:55:34.591Z: 82d34fad-04b6-4227-97da-61d73baf418aDelete the cluster:
$ gcloud container clusters delete dwk-cluster
The following clusters will be deleted.
- [dwk-cluster] in [europe-west3]
Do you want to continue (Y/n)? y
Deleting cluster dwk-cluster...⠹
At first I created a cluster dwk-cluster like in the exercise before. I also decided to switch from the default GKE Ingress to Traefik v2. I had problems creating rewrite rules with Google's default Ingress (it looks like I'm not the only one). Since I need this function to prevent the backend and frontend of my CRUD app from interfering with each other, I decided to use Traefik v2 instead of the standard Ingress Controller.
$ kubectl create namespace project
namespace/project created
$ kubectl config set-context --current --namespace=project
Context "gke_dwk-gke-284614_europe-west3_dwk-cluster" modified.
$ helm repo add traefik https://containous.github.io/traefik-helm-chart && \
helm repo update && \
helm install traefik traefik/traefik
"traefik" has been added to your repositories
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "traefik" chart repository
...Successfully got an update from the "loki" chart repository
...Successfully got an update from the "stable" chart repository
Update Complete. ⎈ Happy Helming!⎈
NAME: traefik
LAST DEPLOYED: Fri Jul 31 17:37:27 2020
NAMESPACE: project
STATUS: deployed
REVISION: 1
TEST SUITE: None
The helm chart creates a LoadBalancer service. Like manually created Service in the exercise before this gets a public external IP address:
$ kubectl get service --watch
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
traefik LoadBalancer 10.51.247.87 35.234.119.98 80:31601/TCP,443:30377/TCP 5m43sWith the cluster running and Traefik installed my automatic deployment for the project will work.
Added a new Action workflow yaml so that when pushing to a branch. The application gets deployed into a namespace with the same name as the branch.
Added a new a new Action workflow: project-delete-branch-namespace.yml
The following is a short pro and contra list that compares Database as a Service vs. self-configured and deployed database solutions. I have informed myself about the subject at DBaaS providers, in magazine articles and forums1, 2.
Pros for DBaaS:
- Very easy to setup ➡️ no own know-how or personell necessary for the operation of the database server
- scalability and elasticity
- High Availability such as replications are provided
- Easy backups (point in time recovery)
- The billing is usage-based
Cons against DBaaS:
- The billing is usage-based ➡️ Unpredictable costs can arise during peak loads
- You need to trust the provider: Legal requirements may prohibit storing personal data on servers of third parties
- Upgrades must be installed by the provider
- No far-reaching changes to the server configuration are possible
Because I have already used PersistentVolumeClaims I stuck to it. To ensure that the data in the database is preserved, I set the Reclaim policy to Retain for the automatically created PersistentVolume of my PersistentVolumeClaim. (GKE takes care of creating the PV for the PVC).
$ kubectl patch pv pvc-e662f066-fb2d-4efa-98fe-130743e5f77a -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'As I already ran into resource limits and quotas while using k3d and the VScode Extension was constantly nagging to set limits my applications already had resource tried and tested limits set.
While creating the cluster I added --enable-stackdriver-kubernetes:
gcloud container clusters create dwk-cluster --zone=europe-west3 --enable-stackdriver-kubernetes --num-nodes=2Now I could marvel at both monitoring and logging in the Cloud Console:


All steps in my solutions to this exercise were executed on a local minikube cluster with the NGINX Ingress controller installed. The configuration should be the same on GKE.
I. Readiness Probes for ping/pong app
When commenting out the environment variable section in pingpong/manifests/deployment.yaml. My app will default POSTGRES_HOST to localhost instead of right the service hostname. Thus no connection to the database will succeed. The app is unhealhty.
Steps to reproduce:
Comment out env variables in pingpong/manifests/deployment.yaml:
# env:
# - name: POSTGRES_HOST
# value: "postgres-pingpong-svc"Apply the manifests:
$ kubectl apply -f pingpong/manifests
$ kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
pingpong-dep-588f7f998d-9b5f7 0/1 Running 0 7s
pingpong-dep-588f7f998d-9kjlp 0/1 Running 0 7s
pingpong-dep-588f7f998d-pkb9z 0/1 Running 0 7sWhy is it not entering Ready state???
$ kubectl describe pod pingpong-dep-588f7f998d-9b5f7
...
Events:
Type Reason Age From Message
[...]
Normal Created 36s kubelet, minikube Created container pingpong
Normal Started 36s kubelet, minikube Started container pingpong
Warning Unhealthy 0s (x7 over 30s) kubelet, minikube Readiness probe failed: HTTP probe failedMy /healthz endpoint returns the following output:
$ kubectl port-forward pingpong-dep-588f7f998d-9b5f7 3000:3000
$ curl -s localhost:3000/healthz | jq '.'
{
"status": "connect ECONNREFUSED 127.0.0.1:5432",
"hostname": "pingpong-dep-588f7f998d-9b5f7"
}
$ curl -sI localhost:3000/healthz
HTTP/1.1 400 Bad Request
[...]
Fixing the deployment.yaml be uncommenting the env variable:
spec:
containers:
- name: pingpong
image: movd/devopswithkubernetes-pingpong:sha-746a640
env:
- name: POSTGRES_HOST
value: "postgres-pingpong-svc"
...After reapplying the manifests all pods are started sucessfully.
$ kubectl apply -f pingpong/manifests
$ kubectl get pod --watch
NAME READY STATUS RESTARTS AGE
pingpong-dep-567dbf4bd9-cnnws 0/1 Running 0 3s
pingpong-dep-567dbf4bd9-frdwp 1/1 Running 0 14s
pingpong-dep-567dbf4bd9-sg5vv 1/1 Running 0 8s
pingpong-dep-588f7f998d-9b5f7 0/1 Running 0 12m
postgres-pingpong-stateful-0 1/1 Running 0 12m
pingpong-dep-567dbf4bd9-cnnws 1/1 Running 0 4s
pingpong-dep-588f7f998d-9b5f7 0/1 Terminating 0 12mII. Readiness Probes for hashgenerator (main app)
If the previously created deployment of the pingpong app is deleted, the main application will not become Ready. I'll be brief this time:
$ kubectl create configmap hashgenerator-config-env-file --from-env-file manifests/hashgenerator-env-file.properties
configmap/hashgenerator-config-env-file created
$ kubectl apply -f hashgenerator/manifests
deployment.apps/hashgenerator-dep created
...
$ kubectl delete -f pingpong/manifests
deployment.apps "pingpong-dep" deleted
...
$ kubectl rollout restart deployment hashgenerator-dep
deployment.apps/hashgenerator-dep restarted
...
$ kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
hashgenerator-dep-5b84db6b5b-jtsf6 1/2 Running 0 4m19s
hashgenerator-dep-8677c5f6b8-8gd98 1/2 Running 0 24s
$ kubectl describe pods hashgenerator-dep-8677c5f6b8-8gd98
[...]
Events:
Type Reason Age From Message
[...]
Normal Created 45s kubelet, minikube Created container hashgenerator
Normal Started 45s kubelet, minikube Started container hashgenerator
Warning Unhealthy 5s (x9 over 45s) kubelet, minikube Readiness probe failed: HTTP probe failed with statuscode: 400This exercise was solved via a GKE cluster.
The application has an API endpoint :3000/api/healthz. If wrong database credentials are set up or the connection to the database times out the backend container becomes unhealthy. The frontend is checked at :80/ (nginx).
To try out how my app behaves when no volumes are mounted I commented out the PersistentVolumeClaims.
Backend probes
readinessProbe:
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 5
failureThreshold: 5
successThreshold: 1
httpGet:
path: /api/healthz?readiness
port: 3000
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 60 # every 60 seconds
failureThreshold: 10
httpGet:
path: /api/healthz?liveness
port: 3000 |
Frontend probe
readinessProbe:
initialDelaySeconds: 1
timeoutSeconds: 5
periodSeconds: 5
successThreshold: 1
httpGet:
path: /
port: 80 |
This exercise was solved via a GKE cluster.
Installed Prometheus via helm like shown in the course notes.
$ kubectl port-forward -n prometheus prometheus-prometheus-operator-159793-prometheus-0 9090 &
Forwarding from [::1]:9090 -> 9090
Handling connection for 9090

scalar(sum(kube_pod_info{namespace="prometheus", created_by_kind="StatefulSet"}))
returns:
| Element | Value |
|---|---|
| scalar | 2 |
My test runs for 10 minutes and checks that the memory consumption does not exceed 652.8 Mb. Based on my memory resource limits per container (128*6)*0.85.
First I deleted the Deployment, switched to a Rollout and added my AnalysisTemplate.
$ kubectl apply -n argo-rollouts -f https://raw.githubusercontent.com/argoproj/argo-rollouts/stable/manifests/install.yaml
customresourcedefinition.apiextensions.k8s.io/analysisruns.argoproj.io unchanged
[...]
$ kubectl delete deployments.apps project-dep
deployment.apps "project-dep" deleted
$ kubectl apply -f project/manifests-gke/analysistemplate.yaml
analysistemplate.argoproj.io/memory-consumption-after-start created
$ kubectl apply -f project/manifests-gke/rollout.yaml
rollout.argoproj.io/project-dep createdAfter that I updated the backend from 1.7.0 to 1.7.1 in rollout.yaml:
$ kubectl apply -f project/manifests-gke/rollout.yaml
rollout.argoproj.io/project-dep configured
$ kubectl get analysisruns.argoproj.io project-dep-86c4f867f-4-1 --watch
NAME STATUS
project-dep-86c4f867f-4-1 Running
project-dep-86c4f867f-4-1 Running
I have configured it so that 25% of my pods are tested for 10 minutes before the upgrade is rolled out completly. With my 3 replicas, this results in one extra pod, running the newer version:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
postgres-project-stateful-0 1/1 Running 0 22h
project-dep-7c74d795d4-mhpkb 2/2 Running 0 6m3s
project-dep-7c74d795d4-srcxs 2/2 Running 0 6m3s
project-dep-7c74d795d4-vlrkx 2/2 Running 0 6m3s
project-dep-86c4f867f-7fm65 2/2 Running 0 14sThe newest pod is running v1.7.1:
$ kubectl get pod \
-o=jsonpath='{range .items[*]}{.metadata.namespace}, {.metadata.name}, {.spec.containers[].image}{"\n"}'
project, postgres-project-stateful-0, postgres:10-alpine
project, project-dep-7c74d795d4-mhpkb, docker.io/movd/devopswithkubernetes-project-backend:v1.7.0
project, project-dep-7c74d795d4-srcxs, docker.io/movd/devopswithkubernetes-project-backend:v1.7.0
project, project-dep-7c74d795d4-vlrkx, docker.io/movd/devopswithkubernetes-project-backend:v1.7.0
project, project-dep-86c4f867f-7fm65, docker.io/movd/devopswithkubernetes-project-backend:v1.7.1Thanks to eldada for this very handy snippet!
Now some users could already use the new version. For this, to work I added the hostname of the pod to the API response.
$ while sleep 1; do curl -s http://35.234.93.113/api/todos | jq '.hostname'; done
"project-dep-7c74d795d4-mhpkb"
"project-dep-7c74d795d4-vlrkx"
"project-dep-7c74d795d4-srcxs"
"project-dep-86c4f867f-7fm65" # Pod with new version
"project-dep-7c74d795d4-mhpkb"After testing for ten minutes two additional replicas got added with the new version. All old called project-dep-7c74d795d-* where deleted.
$ do kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
postgres-project-stateful-0 1/1 Running 0 22h
project-dep-7c74d795d4-mhpkb 0/2 Terminating 0 16m
project-dep-86c4f867f-7fm65 2/2 Running 0 10m
project-dep-86c4f867f-d2t72 2/2 Running 0 30s
project-dep-86c4f867f-f4f9p 2/2 Running 0 19sAll pods now run the newest version:
$ kubectl get pod \
-o=jsonpath='{range .items[*]}{.metadata.namespace}, {.metadata.name}, {.spec.containers[].image}{"\n"}'
project, postgres-project-stateful-0, postgres:10-alpine
project, project-dep-86c4f867f-7fm65, docker.io/movd/devopswithkubernetes-project-backend:v1.7.1
project, project-dep-86c4f867f-d2t72, docker.io/movd/devopswithkubernetes-project-backend:v1.7.1
project, project-dep-86c4f867f-f4f9p, docker.io/movd/devopswithkubernetes-project-backend:v1.7.1$ curl -s -X GET http://35.234.93.113/api/todos | jq '.todos'
[
{
"id": "b4be36c5-14ea-4429-bfb4-a169993d013d",
"userId": null,
"task": "Buy milk",
"done": false,
"createdAt": "2020-08-21T12:45:51.104Z",
"updatedAt": "2020-08-21T12:45:51.104Z"
}
]
$ curl -s -X PUT -H "Content-Type: application/json" \
-d '{"task": "Buy milk","done": true}' \
http://35.234.93.113/api/todos/b4be36c5-14ea-4429-bfb4-a169993d013d | jq
{
"task": "Buy milk",
"done": true,
"id": "b4be36c5-14ea-4429-bfb4-a169993d013d"
}If the NATS_URL environment variable is set the backend sends messages to NATS on create, update, and deletion of tasks:
| Action | NATS queue | NATS payload |
|---|---|---|
| POST /api/todos | todos.created |
JSON of created task |
| PUT /api/todos/uuid | todos.updated |
JSON of updated task |
| DELETE /api/todos/uuid | todos.deleted |
JSON of just deleted task |
The JSON objects stem directly from sequelize and always contain:
{id:uuidv4, userId: null, task: string, done: boolean, createdAt: timestamp, updatedAt: timestamp}
"project-broadcaster" is subscribing to NATS. It listens to messages that are sent by the backend to either the queue "todos.created", "todos.updated" or "todos.deleted". The JSON payload gets forwarded in a message to a Telegram Chat informing the admin on the just happened change.
"project-broadcaster" requires the following environmental variables:
- NATS_URL =
nats://my-nats:4222 - TELEGRAM_ACCESS_TOKEN = looks something like
123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11 - TELEGRAM_CHAT_ID= looks something like
-987654321
Both token and chat id must be acquired using the Telegram API.
The broadcaster can be scaled horizontally without Telegram messages getting sent by multiple subscribers/replicas at the same time. This is achieved by using NATS queue groups. My replicas join the queue "todos_broadcasters".
As messages on the registered subject are published, one member of the group is chosen randomly to receive the message. Although queue groups have multiple subscribers, each message is consumed by only one.
Source: https://docs.nats.io/nats-concepts/queue
Here is an example how it behaves during runtime:

Whats going on here?
The deployment is installed in the left pane of the terminal. In the right pane nats-cli is listening. It prints all messages unfiltered.
This works because kubectl -n project port-forward my-nats-0 4222 was executed in the second tab which is not visible.
While I was working on my solutions, exercises 6 and 7 were one. In the final course, they will get split into two consecutive tasks.
Here is the basic run down:
- Custom Resource Definition
- My DummySite resource is defined in
02-ressourcedefinition.yaml. - properties:
website_url(string): url of website that should get dumpedsuccessful(boolean): status after executionhtml(string): full html of website after execution (only viewable with-o wideor describe)path_in_pod(string): path to html dump in controller container
- My DummySite resource is defined in
- RBAC
- In
03-rbac.yamla role is defined that allows the manipulation of only DummySite resources
- In
- Controller Deployment
- The dummysite-controller constantly watches for new DummySite k8s objects using
k8s.Watch(from @kubernetes/client-node) - If a new or updated object was found, it extracts the
website_urlproperty and creates a website dump with website-scraper - The results gets patched back to the DummySite object using
client.patchNamespacedCustomObject(fromk8s.CustomObjectsApi) - Output:
- via
kubectl get dummysites.stable.dwk - via a web browser + port-forward to port 8080 (using halverneus/static-file-server)
- via
- The dummysite-controller constantly watches for new DummySite k8s objects using
My DummySite setup can be run like so:
$ kubectl apply -f dummysite/manifests
namespace/dummysite created
customresourcedefinition.apiextensions.k8s.io/dummysites.stable.dwk created
serviceaccount/dummysite-controller-account created
clusterrole.rbac.authorization.k8s.io/dummysite-controller-role created
clusterrolebinding.rbac.authorization.k8s.io/dummysite-rolebinding created
deployment.apps/dummysite-controller-dep created
dummysite.stable.dwk/example created
dummysite.stable.dwk/google created
dummysite.stable.dwk/not-reachable-url created
dummysite.stable.dwk/empty-spec createdThis created four DummySite objects. The controller notices this, scrapes the websites and writes the results back to each object:
$ kubectl get dummysites.stable.dwk
NAME WEBSITEURL SUCCESSFUL PATHINPOD
devopswithkubernetes https://devopswithkubernetes.com/ true /usr/src/app/output/devopswithkubernetes.com
empty-spec false N/A
example http://example.com true /usr/src/app/output/example.com
not-reachable-url http://notreachableurl.foo/ false N/AA small webserver also serves the html dumps
$ kubectl port-forward $(kubectl get pod -l app=dummysite-controller -o=name) 8080
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080
Controller log (shortened to the example.com object):
kubectl logs $(kubectl get pod -l app=dummysite-controller -o=name) dummysite-controller -f
> dummysite-controller@0.0.1 start /usr/src/app
> node index.js
☸️ k8s Cluster config: {
name: 'inCluster',
caFile: '/var/run/secrets/kubernetes.io/serviceaccount/ca.crt',
server: 'https://10.96.0.1:443',
skipTLSVerify: false
}
🎆 DummySite controller launched
☸️ the k8s object "example" was created or updated
📸 scraped "http://example.com/" to /usr/src/app/output/example.comI created a k3d cluster: k3d create --publish 8081:80 --publish 8082:30080@k3d-k3s-default-worker-0 --workers 2 and installed the service mesh Linkerd as described in the getting started guide.
Files where injected with linkerd inject:
$ cd project/manifests-linkerd
$ echo "$(cat 01-namespace.yaml |linkerd inject -)" > 01-namespace.yaml
namespace "project" injected
$ echo "$(cat 04-statefulset.yaml |linkerd inject -)" > 04-statefulset.yaml
service "postgres-project-svc" skipped
statefulset "postgres-project-stateful" injected
$ echo "$(cat 06-deployment.yaml |linkerd inject -)" > 06-deployment.yaml
deployment "project-dep" injectedI found the nice command to write output from the same file as the input on serverfault.
After applying the injected yaml files and waiting for the rollout to finish
$ linkerd stat deployments -n project
NAME MESHED SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99 TCP_CONN
project-dep 3/3 100.00% 1.2rps 1ms 3ms 4ms 6recorded with asciinema:

I decided to compare Google Anthos and VMware Tanzu. I arbitrarily decided VMware Tanzu is the "better" option.
- Both over hybrid solutions, they allow deploying Kubernetes across on-premise, hybrid, and multi-cloud environments.
- VMware has extensive adoption and is trusted for on-premise hosting in both public institutions and also private companies. Last year VMware decided to make K8s an integral part of their offerings.
- The hypervisor ESXi integrates K8s natively on the lowest level of infrastructure, whereas Anthos integrates itself as a VMware Appliance
- Tanzu provides a service mesh built upon Istio and expands it across multiple clusters and clouds.
- Tanzu provides its cloud native networking called "NSX" this provides firewalls, load balancing, and namespace isolation on the lowest level.
- There might be the possibility of cost-saving if a company already has licenses from VMware
- A aspect to take into consideration is that Tanzu is a newer solution than Anthos
Sources:
- "Steuerjonglage" (iX, May 2020) German article that compares commercial Kubernetes distributions
- "Will Tanzu, the VMware Kubernetes Play, Succeed?" (ITProTody, May 2020) Blog article on the chances of success of Tanzu
- "Top Use Cases for VMware Tanzu Service Mesh, Built on VMware NSX" (VMware, March 2020) white paper for Tanzu
I adapted my pingpong app to also serve from / not just from /pingpong and created a knative service. The database remains a default Kubernetes StatefulSet.
$ kubectl apply -f pingpong/manifests-knative/db-statefulset.yaml
secret/postgres-pw created
service/postgres-pingpong-svc created
configmap/postgres-pingpong-seed created
statefulset.apps/postgres-pingpong-stateful created
# Check if database is available
$ kubectl exec postgres-pingpong-stateful-0 -c db -- psql -U postgres -c 'SELECT * FROM pingpongers;'
id | name
----+------
(0 rows)
$ kubectl apply -f pingpong/manifests-knative/knative-service-pingpong.yaml
service.serving.knative.dev/pingpong created
# Check if knative service gets created
$ kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
helloworld-go http://helloworld-go.default.example.com helloworld-go-dwk-message-v1 helloworld-go-dwk-message-v1 True
pingpong http://pingpong.default.example.com pingpong-app pingpong-app True
# Wait till knative deletes pingpong pod
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
postgres-pingpong-stateful-0 1/1 Running 0 6m55s
# Review how pods get created automatically by knative when pinpong gets pinged
$ curl -sH "Host: pingpong.default.example.com" http://localhost:8081/
{"counter":1,"hostname":"pingpong-app-deployment-5859d4c5cc-d2bwg"}
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
postgres-pingpong-stateful-0 1/1 Running 0 10m
pingpong-app-deployment-5859d4c5cc-d2bwg 1/2 Running 0 3s
# Check that pings where counted in database
$ kubectl exec postgres-pingpong-stateful-0 -c db -- psql -U postgres -c 'SELECT COUNT(*) FROM pingpongers;'
count
-------
2Here is my marked map of projects and products I have used from the Cloud Native landscape. I highlighted both the ones used in the course and outside of the course.
green = used knowingly / blue = used indirectly
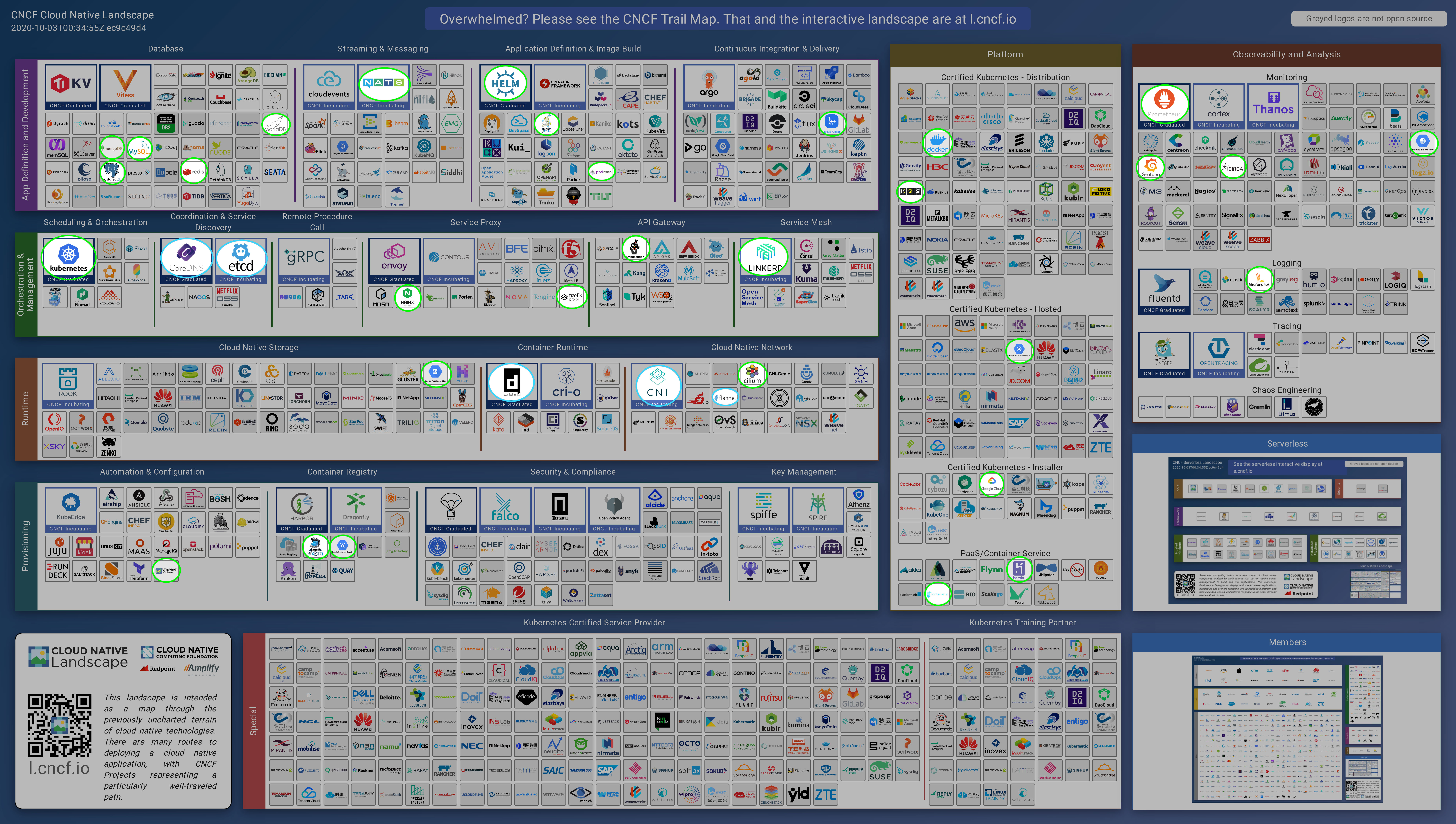
Source: https://landscape.cncf.io/images/landscape.png (Version 2020-10-03T00:34:55Z ec9c49d4)
{kind=link}
View as Table (click to expand)
| Product/Project | Where | Used knowingly or indirectly (dependency)? |
|---|---|---|
| Ambassador | will use in Ex. 5.02 | knowingly |
| containerd | k3d, minikube, GKE | dontainerd is used by Docker |
| CoreDNS | k3d, minikube, GKE | indirectly used as DNS in clusters |
| etcd | GKE, minikube | indirectly as a store for all cluster data |
| GitHub Actions | whole course | knowingly |
| Google Cloud | whole Part 3 and 4 | knowingly |
| Google Container Registry | Ex. 3.03 | knowingly |
| Google Kubernetes Engine | Part 3 and 4 | knowingly |
| Google Stackdriver | Ex. 3.09 | knowingly |
| Grafana Loki | Ex. 2.08 | knowingly |
| Grafana | Ex. 2.08, 4.03, 4.06 | knowingly |
| Helm | Ex. 2.08, 3.02, 4.03 | knowingly |
| k3s | whole course | knowingly in k3d clusters |
| Kubernetes | whole course | knowingly |
| Linkerd | will use in Ex. 5.X | knowingly |
| NATS | Ex. 4.06 | knowingly |
| PostreSQL | course project backend | knowingly |
| Prometheus | Ex. 4.03, 4.04 | indirectly in Part 2 knowingly in Part 4 |
| Traefik Proxy | GKE, k3d and minikube | knowingly in GKE and minikube,indirectly in k3d |
| Docker | whole course | knowingly for testing images and indirectly in clusters |
| Flannel | k3d | indirectly as networking for cluster |
| NGINX | as a default Ingress in minikube and outside the course | knowingly |
| Cilium | outside of course | knowingly for k8s NetworkPolicy |
| CNI | outsisde of course | indirectly in minikube to use Cilium |
| Docker Compose | outside of course | knowingly |
| Docker Registry | outside of course | knowingly |
| heroku | outside of course | knowingly |
| Icinga | outside of course | knowingly |
| MariadDB | outside of course | knowingly |
| mongoDB | outside of course | knowingly |
| MySQL | outside of course | knowingly |
| podman | outside of course | knowingly |
| portainer | outside of course | knowingly |
| redis | outside of course | knowingly |
| VMware vSphere | outside of course | knowingly |