文字识别(OCR)目前在多个行业中得到了广泛应用,比如金融行业的单据识别输入,餐饮行业中的发票识别, 交通领域的车票识别,企业中各种表单识别,以及日常工作生活中常用的身份证,驾驶证,护照识别等等。 OCR(文字识别)是目前常用的一种AI能力。 一般OCR的识别结果是一种按行识别的结构化输出,能够给出一行文字的检测框坐标及文字内容。 但是我们更想要的是带有字段定义的结构化输出,由于表单还活着卡证的多样性,全都预定义好是不现实的。 所以,设计了自定义模板的功能,能够让人设置参照锚点(通过锚点匹配定位,图片透视变换对齐),以及内容识别区 来得到key-value形式的结构化数据。
当前 iocr 版本包含了下面功能:
- 模板自定义
- 基于模板识别(支持旋转、倾斜的图片)
- 自由文本识别
- 文本转正
在OCR文字识别的时候,我们得到的图像一般情况下都不是正的,多少都会有一定的倾斜。 并且图片有可能是透视视角拍摄,需要重新矫正,尤其此时,将图片转正可以提高文字识别的精度。
模型本身支持 0 度,和 180 度两种方向分类。 但是由于中文的书写习惯,根据宽高比可以判断文本的90度和270度两个方向。
- 0度
- 90度
- 180度
- 270度

- 逆时针旋转
- 每次旋转90度的倍数

- ocr_v3_sdk ocr V3版本
- ocr_v4_sdk ocr V4版本
- 中文文本检测
- 英文文本检测
- 多语言文本检测

支持的语言模型:
- 中文简体
- 中文繁体
- 英文
- 韩语
- 日语
- 阿拉伯
- 梵文
- 泰米尔语
- 泰卢固语
- 卡纳达文
- 斯拉夫


CPU:2.3 GHz 四核 Intel Core i5 同样图片单线程运行时间:1172 ms 多线程运行时间:707 ms 图片检测框较多时,多线程可以显著提升识别速度。
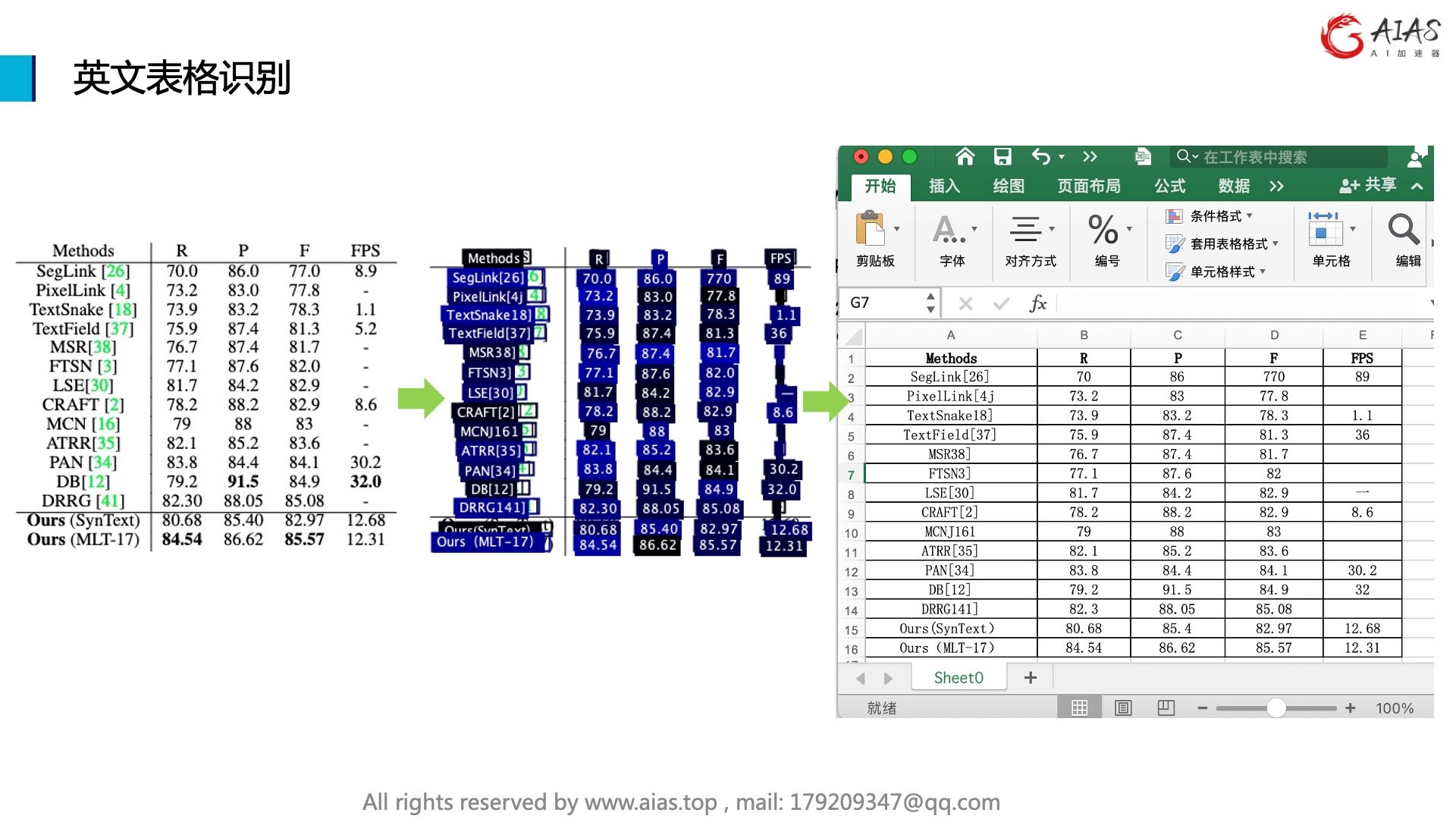
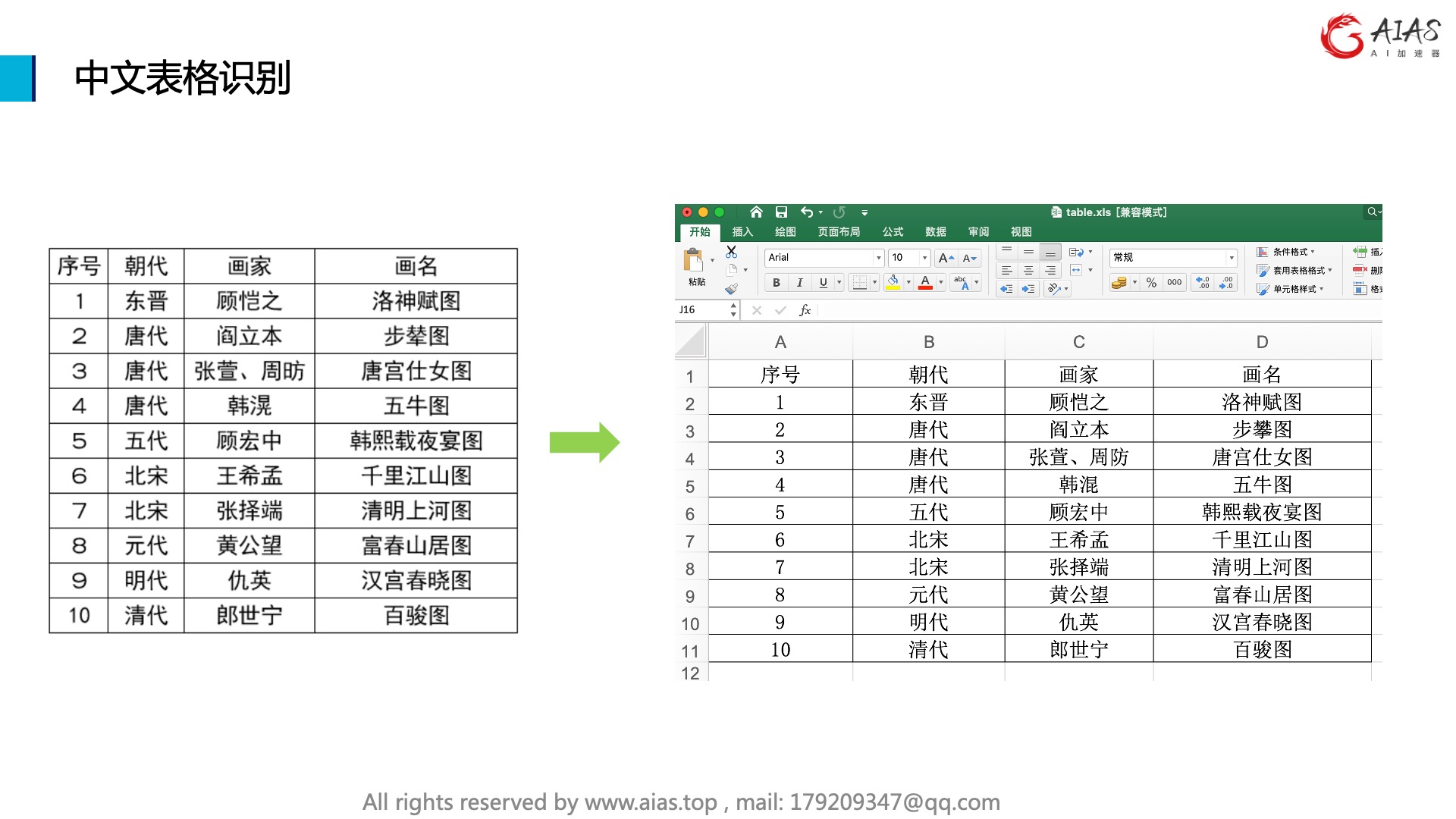
可以用于配合文字识别,表格识别的流水线处理使用。
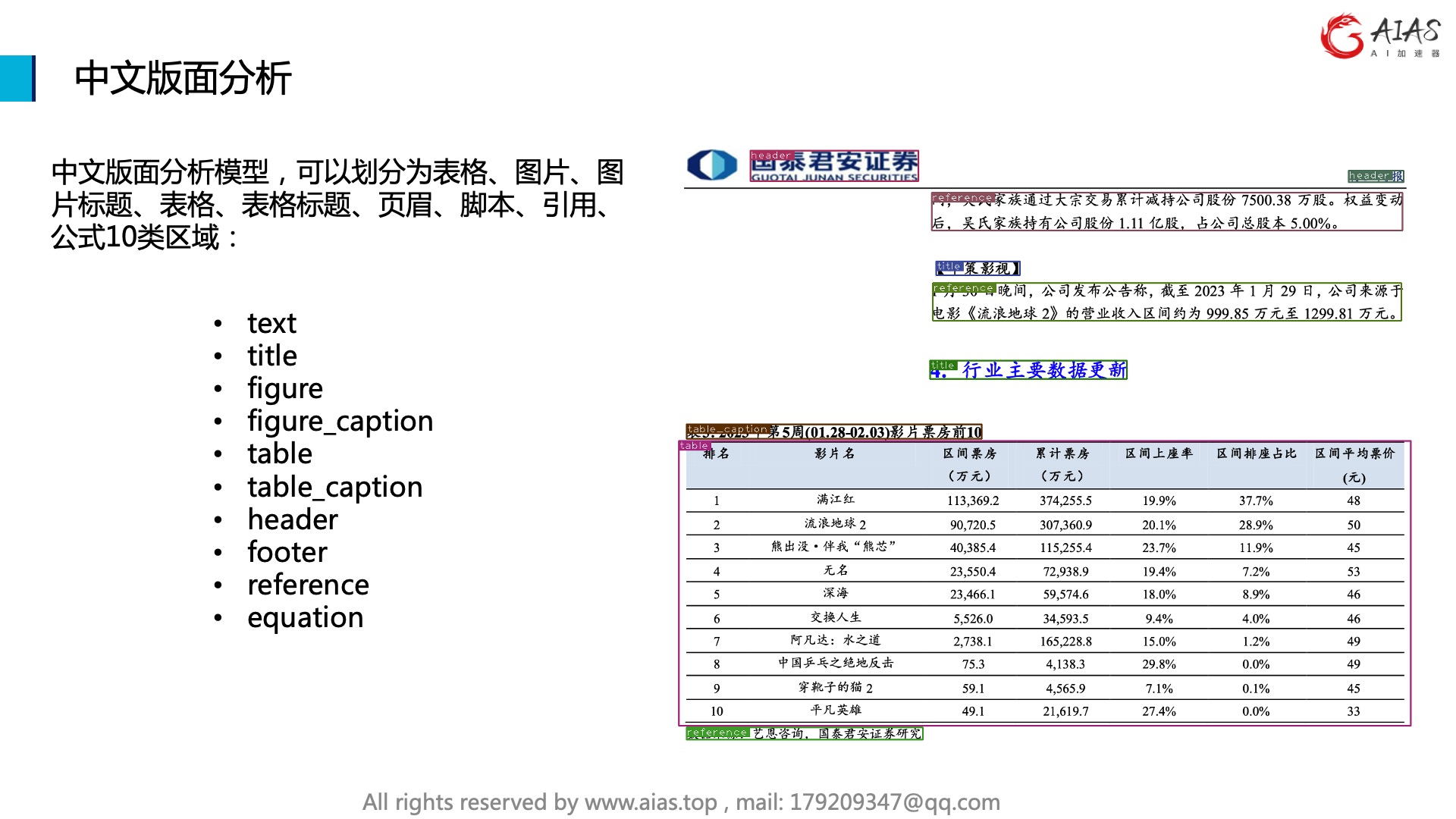
中文版面分析模型,可以划分为表格、图片、图片标题、表格、表格标题、页眉、脚本、引用、公式10类区域:
- text
- title
- figure
- figure_caption
- table
- table_caption
- header
- footer
- reference
- equation
英文版面分析模型,可以划分文字、标题、表格、图片以及列表5类区域:
- text
- title
- list
- table
- figure
- 运行成功后,命令行应该看到下面的信息:

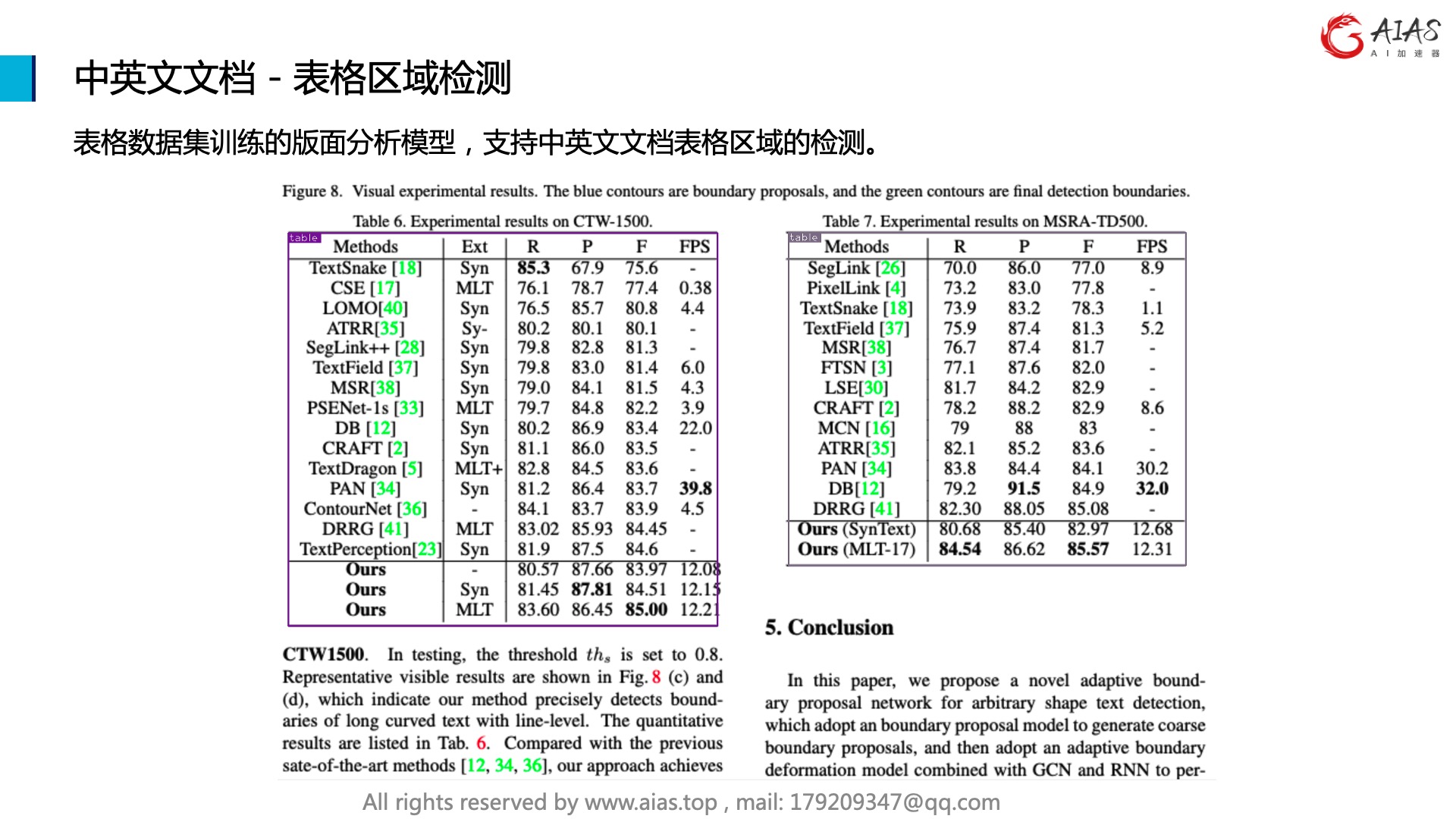
表格数据集训练的版面分析模型,支持中英文文档表格区域的检测。



- PaddleOCR
- https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.6/applications/%E6%B6%B2%E6%99%B6%E5%B1%8F%E8%AF%BB%E6%95%B0%E8%AF%86%E5%88%AB.md
(readme.md 里提供了推理模型的下载链接)
- https://aias.top/guides.html
- 1.性能优化常见问题:
- https://aias.top/AIAS/guides/performance.html
- 2.引擎配置(包括CPU,GPU在线自动加载,及本地配置):
- https://aias.top/AIAS/guides/engine_config.html
- 3.模型加载方式(在线自动加载,及本地配置):
- https://aias.top/AIAS/guides/load_model.html
- 4.Windows环境常见问题:
- https://aias.top/AIAS/guides/windows.html