Sow with little data seed, harvest much from a text field.
播撒几多种子词,收获万千领域实


在Github和码云Gitee上同步。如果在Github上浏览/下载速度慢的话可以转到码云上操作。
HarvestText是一个专注无(弱)监督方法,能够整合领域知识(如类型,别名)对特定领域文本进行简单高效地处理和分析的库。适用于许多文本预处理和初步探索性分析任务,在小说分析,网络文本,专业文献等领域都有潜在应用价值。
使用案例:
- 分析《三国演义》中的社交网络(实体分词,文本摘要,关系网络等)
- 2018中超舆情展示系统(实体分词,情感分析,新词发现[辅助绰号识别]等)
相关文章:一文看评论里的中超风云
【注:本库仅完成实体分词和情感分析,可视化使用matplotlib】
- 近代史纲要信息抽取及问答系统(命名实体识别,依存句法分析,简易问答系统)
本README包含各个功能的典型例子,部分函数的详细用法可在文档中找到:
具体功能如下:
- 基本处理
- 精细分词分句
- 可包含指定词和类别的分词。充分考虑省略号,双引号等特殊标点的分句。
- 文本清洗
- 处理URL, email, 微博等文本中的特殊符号和格式,去除所有标点等
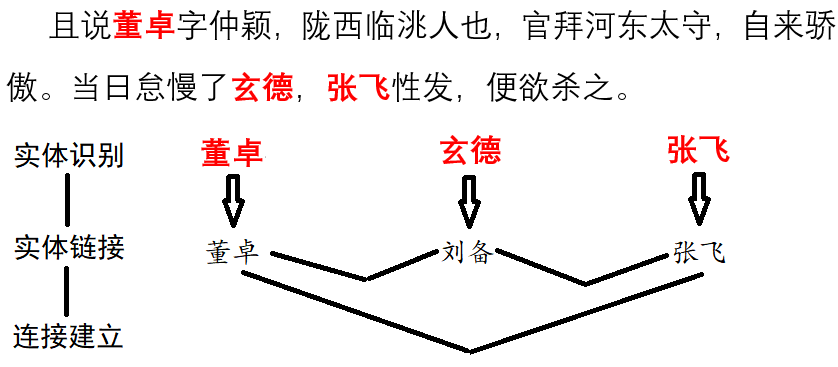
- 实体链接
- 把别名,缩写与他们的标准名联系起来。
- 命名实体识别
- 找到一句句子中的人名,地名,机构名等命名实体。
- 实体别名自动识别(更新!)
- 依存句法分析
- 分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,
- 内置资源
- 通用停用词,通用情感词,IT、财经、饮食、法律等领域词典。可直接用于以上任务。
- 信息检索
- 统计特定实体出现的位置,次数等。
- 新词发现
- 利用统计规律(或规则)发现语料中可能会被传统分词遗漏的特殊词汇。也便于从文本中快速筛选出关键词。
- 字符拼音纠错(调整)
- 把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。
- 自动分段
- 使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段
- 存取消除
- 可以本地保存模型再读取复用,也可以消除当前模型的记录。
- 英语支持
- 本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持
- 精细分词分句
- 高层应用
首先安装, 使用pip
pip install --upgrade harvesttext或进入setup.py所在目录,然后命令行:
python setup.py install随后在代码中:
from harvesttext import HarvestText
ht = HarvestText()即可调用本库的功能接口。
给定某些实体及其可能的代称,以及实体对应类型。将其登录到词典中,在分词时优先切分出来,并且以对应类型作为词性。也可以单独获得语料中的所有实体及其位置:
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
entity_mention_dict = {'武磊':['武磊','武球王'],'郜林':['郜林','郜飞机'],'前锋':['前锋'],'上海上港':['上港'],'广州恒大':['恒大'],'单刀球':['单刀']}
entity_type_dict = {'武磊':'球员','郜林':'球员','前锋':'位置','上海上港':'球队','广州恒大':'球队','单刀球':'术语'}
ht.add_entities(entity_mention_dict,entity_type_dict)
print("\nSentence segmentation")
print(ht.seg(para,return_sent=True)) # return_sent=False时,则返回词语列表上港 的 武磊 和 恒大 的 郜林 , 谁 是 中国 最好 的 前锋 ? 那 当然 是 武磊 武球王 了, 他 是 射手榜 第一 , 原来 是 弱点 的 单刀 也 有 了 进步
采用传统的分词工具很容易把“武球王”拆分为“武 球王”
词性标注,包括指定的特殊类型。
print("\nPOS tagging with entity types")
for word, flag in ht.posseg(para):
print("%s:%s" % (word, flag),end = " ")上港:球队 的:uj 武磊:球员 和:c 恒大:球队 的:uj 郜林:球员 ,:x 谁:r 是:v 中国:ns 最好:a 的:uj 前锋:位置 ?:x 那:r 当然:d 是:v 武磊:球员 武球王:球员 了:ul ,:x 他:r 是:v 射手榜:n 第一:m ,:x 原来:d 是:v 弱点:n 的:uj 单刀:术语 也:d 有:v 了:ul 进步:d
for span, entity in ht.entity_linking(para):
print(span, entity)[0, 2] ('上海上港', '#球队#') [3, 5] ('武磊', '#球员#') [6, 8] ('广州恒大', '#球队#') [9, 11] ('郜林', '#球员#') [19, 21] ('前锋', '#位置#') [26, 28] ('武磊', '#球员#') [28, 31] ('武磊', '#球员#') [47, 49] ('单刀球', '#术语#')
这里把“武球王”转化为了标准指称“武磊”,可以便于标准统一的统计工作。
分句:
print(ht.cut_sentences(para))['上港的武磊和恒大的郜林,谁是中国最好的前锋?', '那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步']
如果手头暂时没有可用的词典,不妨看看本库内置资源中的领域词典是否适合你的需要。
如果同一个名字有多个可能对应的实体("打球的李娜和唱歌的李娜不是一个人"),可以设置keep_all=True来保留多个候选,后面可以再采用别的策略消歧,见el_keep_all()
如果连接到的实体过多,其中有一些明显不合理,可以采用一些策略来过滤,这里给出了一个例子filter_el_with_rule()
本库能够也用一些基本策略来处理复杂的实体消歧任务(比如一词多义【"老师"是指"A老师"还是"B老师"?】、候选词重叠【xx市长/江yy?、xx市长/江yy?】)。 具体可见linking_strategy()
可以处理文本中的特殊字符,或者去掉文本中不希望出现的一些特殊格式。
包括:微博的@,表情符;网址;email;html代码中的 一类的特殊字符;网址内的%20一类的特殊字符;繁体字转简体字
例子如下:
print("各种清洗文本")
ht0 = HarvestText()
# 默认的设置可用于清洗微博文本
text1 = "回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]"
print("清洗微博【@和表情符等】")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1))
# URL的清理
text1 = "【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ"
print("清洗网址URL")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, remove_url=True))
# 清洗邮箱
text1 = "我的邮箱是abc@demo.com,欢迎联系"
print("清洗邮箱")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, email=True))
# 处理URL转义字符
text1 = "www.%E4%B8%AD%E6%96%87%20and%20space.com"
print("URL转正常字符")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, norm_url=True, remove_url=False))
text1 = "www.中文 and space.com"
print("正常字符转URL[含有中文和空格的request需要注意]")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, to_url=True, remove_url=False))
# 处理HTML转义字符
text1 = "<a c> ''"
print("HTML转正常字符")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, norm_html=True))
# 繁体字转简体
text1 = "心碎誰買單"
print("繁体字转简体")
print("原:", text1)
print("清洗后:", ht0.clean_text(text1, t2s=True))各种清洗文本
清洗微博【@和表情符等】
原: 回复@钱旭明QXM:[嘻嘻][嘻嘻] //@钱旭明QXM:杨大哥[good][good]
清洗后: 杨大哥
清洗网址URL
原: 【#赵薇#:正筹备下一部电影 但不是青春片....http://t.cn/8FLopdQ
清洗后: 【#赵薇#:正筹备下一部电影 但不是青春片....
清洗邮箱
原: 我的邮箱是abc@demo.com,欢迎联系
清洗后: 我的邮箱是,欢迎联系
URL转正常字符
原: www.%E4%B8%AD%E6%96%87%20and%20space.com
清洗后: www.中文 and space.com
正常字符转URL[含有中文和空格的request需要注意]
原: www.中文 and space.com
清洗后: www.%E4%B8%AD%E6%96%87%20and%20space.com
HTML转正常字符
原: <a c> ''
清洗后: <a c> ''
繁体字转简体
原: 心碎誰買單
清洗后: 心碎谁买单
找到一句句子中的人名,地名,机构名等命名实体。使用了 pyhanLP 的接口实现。
ht0 = HarvestText()
sent = "上海上港足球队的武磊是中国最好的前锋。"
print(ht0.named_entity_recognition(sent)){'上海上港足球队': '机构名', '武磊': '人名', '中国': '地名'}
分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,并以此提取可能的事件三元组。使用了 pyhanLP 的接口实现。
ht0 = HarvestText()
para = "上港的武磊武球王是中国最好的前锋。"
entity_mention_dict = {'武磊': ['武磊', '武球王'], "上海上港":["上港"]}
entity_type_dict = {'武磊': '球员', "上海上港":"球队"}
ht0.add_entities(entity_mention_dict, entity_type_dict)
for arc in ht0.dependency_parse(para):
print(arc)
print(ht0.triple_extraction(para))[0, '上港', '球队', '定中关系', 3]
[1, '的', 'u', '右附加关系', 0]
[2, '武磊', '球员', '定中关系', 3]
[3, '武球王', '球员', '主谓关系', 4]
[4, '是', 'v', '核心关系', -1]
[5, '中国', 'ns', '定中关系', 8]
[6, '最好', 'd', '定中关系', 8]
[7, '的', 'u', '右附加关系', 6]
[8, '前锋', 'n', '动宾关系', 4]
[9, '。', 'w', '标点符号', 4]
print(ht0.triple_extraction(para))[['上港武磊武球王', '是', '中国最好前锋']]
在V0.7版修改,使用tolerance支持拼音相同的检查
把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。
def entity_error_check():
ht0 = HarvestText()
typed_words = {"人名":["武磊"]}
ht0.add_typed_words(typed_words)
sent0 = "武磊和吴磊拼音相同"
print(sent0)
print(ht0.entity_linking(sent0, pinyin_tolerance=0))
sent1 = "武磊和吴力只差一个拼音"
print(sent1)
print(ht0.entity_linking(sent1, pinyin_tolerance=1))
sent2 = "武磊和吴磊只差一个字"
print(sent2)
print(ht0.entity_linking(sent2, char_tolerance=1))
sent3 = "吴磊和吴力都可能是武磊的代称"
print(sent3)
print(ht0.get_linking_mention_candidates(sent3, pinyin_tolerance=1, char_tolerance=1))武磊和吴磊拼音相同
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
武磊和吴力只差一个拼音
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
武磊和吴磊只差一个字
[([0, 2], ('武磊', '#人名#')), [(3, 5), ('武磊', '#人名#')]]
吴磊和吴力都可能是武磊的代称
('吴磊和吴力都可能是武磊的代称', defaultdict(<class 'list'>, {(0, 2): {'武磊'}, (3, 5): {'武磊'}}))
本库采用情感词典方法进行情感分析,通过提供少量标准的褒贬义词语(“种子词”),从语料中自动学习其他词语的情感倾向,形成情感词典。对句中情感词的加总平均则用于判断句子的情感倾向:
print("\nsentiment dictionary")
sents = ["武磊威武,中超第一射手!",
"武磊强,中超最第一本土球员!",
"郜林不行,只会抱怨的球员注定上限了",
"郜林看来不行,已经到上限了"]
sent_dict = ht.build_sent_dict(sents,min_times=1,pos_seeds=["第一"],neg_seeds=["不行"])
print("%s:%f" % ("威武",sent_dict["威武"]))
print("%s:%f" % ("球员",sent_dict["球员"]))
print("%s:%f" % ("上限",sent_dict["上限"]))sentiment dictionary 威武:1.000000 球员:0.000000 上限:-1.000000
print("\nsentence sentiment")
sent = "武球王威武,中超最强球员!"
print("%f:%s" % (ht.analyse_sent(sent),sent))0.600000:武球王威武,中超最强球员!
如果没想好选择哪些词语作为“种子词”,本库中也内置了一个通用情感词典内置资源,在不指定情感词时作为默认的选择,也可以根据需要从中挑选。
默认使用的SO-PMI算法对于情感值没有上下界约束,如果需要限制在[0,1]或者[-1,1]这样的区间的话,可以调整scale参数,例子如下:
print("\nsentiment dictionary using default seed words")
docs = ["张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资",
"打倒万恶的资本家",
"该公司原定资本总额为二十五万万元,现已由各界分认达二十万万元,所属各厂、各公司亦募得股金一万万余元",
"连日来解放区以外各工商人士,投函向该公司询问经营性质与范围以及股东权限等问题者甚多,络绎抵此的许多资本家,于参观该公司所属各厂经营状况后,对民主政府扶助与奖励私营企业发展的政策,均极表赞同,有些资本家因款项未能即刻汇来,多向筹备处预认投资的额数。由平津来张的林明棋先生,一次即以现款入股六十余万元"
]
# scale: 将所有词语的情感值范围调整到[-1,1]
# 省略pos_seeds, neg_seeds,将采用默认的情感词典 get_qh_sent_dict()
print("scale=\"0-1\", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="0-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))
print("scale=\"+-1\", 在正负区间内分别伸缩,保留0作为中性的语义")
sent_dict = ht.build_sent_dict(docs,min_times=1,scale="+-1")
print("%s:%f" % ("赞同",sent_dict["赞同"]))
print("%s:%f" % ("二十万",sent_dict["二十万"]))
print("%s:%f" % ("万恶",sent_dict["万恶"]))
print("%f:%s" % (ht.analyse_sent(docs[0]), docs[0]))
print("%f:%s" % (ht.analyse_sent(docs[1]), docs[1]))sentiment dictionary using default seed words
scale="0-1", 按照最大为1,最小为0进行线性伸缩,0.5未必是中性
赞同:1.000000
二十万:0.153846
万恶:0.000000
0.449412:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
0.364910:打倒万恶的资本家
scale="+-1", 在正负区间内分别伸缩,保留0作为中性的语义
赞同:1.000000
二十万:0.000000
万恶:-1.000000
0.349305:张市筹设兴华实业公司外区资本家踊跃投资晋察冀边区兴华实业公司,自筹备成立以来,解放区内外企业界人士及一般商民,均踊跃认股投资
-0.159652:打倒万恶的资本家
可以从文档列表中查找出包含对应实体(及其别称)的文档,以及统计包含某实体的文档数。使用倒排索引的数据结构完成快速检索。
docs = ["武磊威武,中超第一射手!",
"郜林看来不行,已经到上限了。",
"武球王威武,中超最强前锋!",
"武磊和郜林,谁是中国最好的前锋?"]
inv_index = ht.build_index(docs)
print(ht.get_entity_counts(docs, inv_index)) # 获得文档中所有实体的出现次数
# {'武磊': 3, '郜林': 2, '前锋': 2}
print(ht.search_entity("武磊", docs, inv_index)) # 单实体查找
# ['武磊威武,中超第一射手!', '武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
print(ht.search_entity("武磊 郜林", docs, inv_index)) # 多实体共现
# ['武磊和郜林,谁是中国最好的前锋?']
# 谁是最被人们热议的前锋?用这里的接口可以很简便地回答这个问题
subdocs = ht.search_entity("#球员# 前锋", docs, inv_index)
print(subdocs) # 实体、实体类型混合查找
# ['武球王威武,中超最强前锋!', '武磊和郜林,谁是中国最好的前锋?']
inv_index2 = ht.build_index(subdocs)
print(ht.get_entity_counts(subdocs, inv_index2, used_type=["球员"])) # 可以限定类型
# {'武磊': 2, '郜林': 1}(使用networkx实现) 利用词共现关系,建立其实体间图结构的网络关系(返回networkx.Graph类型)。可以用来建立人物之间的社交网络等。
# 在现有实体库的基础上随时新增,比如从新词发现中得到的漏网之鱼
ht.add_new_entity("颜骏凌", "颜骏凌", "球员")
docs = ["武磊和颜骏凌是队友",
"武磊和郜林都是国内顶尖前锋"]
G = ht.build_entity_graph(docs)
print(dict(G.edges.items()))
G = ht.build_entity_graph(docs, used_types=["球员"])
print(dict(G.edges.items()))获得以一个词语为中心的词语网络,下面以三国第一章为例,探索主人公刘备的遭遇(下为主要代码,例子见build_word_ego_graph())。
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
ht0.add_entities(entity_mention_dict, entity_type_dict)
sanguo1 = get_sanguo()[0]
stopwords = get_baidu_stopwords()
docs = ht0.cut_sentences(sanguo1)
G = ht0.build_word_ego_graph(docs,"刘备",min_freq=3,other_min_freq=2,stopwords=stopwords)
刘关张之情谊,刘备投奔的靠山,以及刘备讨贼之经历尽在于此。
(使用networkx实现) 使用Textrank算法,得到从文档集合中抽取代表句作为摘要信息,可以设置惩罚重复的句子,也可以设置字数限制(maxlen参数):
print("\nText summarization")
docs = ["武磊威武,中超第一射手!",
"郜林看来不行,已经到上限了。",
"武球王威武,中超最强前锋!",
"武磊和郜林,谁是中国最好的前锋?"]
for doc in ht.get_summary(docs, topK=2):
print(doc)
print("\nText summarization(避免重复)")
for doc in ht.get_summary(docs, topK=3, avoid_repeat=True):
print(doc)Text summarization
武球王威武,中超最强前锋!
武磊威武,中超第一射手!
Text summarization(避免重复)
武球王威武,中超最强前锋!
郜林看来不行,已经到上限了。
武磊和郜林,谁是中国最好的前锋?
目前提供包括textrank和HarvestText封装jieba并配置好参数和停用词的jieba_tfidf(默认)两种算法。
示例(完整见example):
# text为林俊杰《关键词》歌词
print("《关键词》里的关键词")
kwds = ht.extract_keywords(text, 5, method="jieba_tfidf")
print("jieba_tfidf", kwds)
kwds = ht.extract_keywords(text, 5, method="textrank")
print("textrank", kwds)《关键词》里的关键词
jieba_tfidf ['自私', '慷慨', '落叶', '消逝', '故事']
textrank ['自私', '落叶', '慷慨', '故事', '位置']
CSL.ipynb提供了不同算法,以及本库的实现与textrank4zh的在CSL数据集上的比较。由于仅有一个数据集且数据集对于以上算法都很不友好,表现仅供参考。
| 算法 | P@5 | R@5 | F@5 |
|---|---|---|---|
| textrank4zh | 0.0836 | 0.1174 | 0.0977 |
| ht_textrank | 0.0955 | 0.1342 | 0.1116 |
| ht_jieba_tfidf | 0.1035 | 0.1453 | 0.1209 |
现在本库内集成了一些资源,方便使用和建立demo。
资源包括:
get_qh_sent_dict: 褒贬义词典 清华大学 李军 整理自http://nlp.csai.tsinghua.edu.cn/site2/index.php/13-smsget_baidu_stopwords: 百度停用词词典 来自网络:https://wenku.baidu.com/view/98c46383e53a580216fcfed9.htmlget_qh_typed_words: 领域词典 来自清华THUNLP: http://thuocl.thunlp.org/ 全部类型['IT', '动物', '医药', '历史人名', '地名', '成语', '法律', '财经', '食物']get_english_senti_lexicon: 英语情感词典get_jieba_dict: (需要下载)jieba词频词典
此外,还提供了一个特殊资源——《三国演义》,包括:
- 三国演义文言文文本
- 三国演义人名、州名、势力知识库
大家可以探索从其中能够得到什么有趣发现😁。
def load_resources():
from harvesttext.resources import get_qh_sent_dict,get_baidu_stopwords,get_sanguo,get_sanguo_entity_dict
sdict = get_qh_sent_dict() # {"pos":[积极词...],"neg":[消极词...]}
print("pos_words:",list(sdict["pos"])[10:15])
print("neg_words:",list(sdict["neg"])[5:10])
stopwords = get_baidu_stopwords()
print("stopwords:", list(stopwords)[5:10])
docs = get_sanguo() # 文本列表,每个元素为一章的文本
print("三国演义最后一章末16字:\n",docs[-1][-16:])
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
print("刘备 指称:",entity_mention_dict["刘备"])
print("刘备 类别:",entity_type_dict["刘备"])
print("蜀 类别:", entity_type_dict["蜀"])
print("益州 类别:", entity_type_dict["益州"])
load_resources()pos_words: ['宰相肚里好撑船', '查实', '忠实', '名手', '聪明']
neg_words: ['散漫', '谗言', '迂执', '肠肥脑满', '出卖']
stopwords: ['apart', '左右', '结果', 'probably', 'think']
三国演义最后一章末16字:
鼎足三分已成梦,后人凭吊空牢骚。
刘备 指称: ['刘备', '刘玄德', '玄德']
刘备 类别: 人名
蜀 类别: 势力
益州 类别: 州名
加载清华领域词典,并使用停用词。
def using_typed_words():
from harvesttext.resources import get_qh_typed_words,get_baidu_stopwords
ht0 = HarvestText()
typed_words, stopwords = get_qh_typed_words(), get_baidu_stopwords()
ht0.add_typed_words(typed_words)
sentence = "THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。"
print(sentence)
print(ht0.posseg(sentence,stopwords=stopwords))
using_typed_words()THUOCL是自然语言处理的一套中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。
[('THUOCL', 'eng'), ('自然语言处理', 'IT'), ('一套', 'm'), ('中文', 'nz'), ('词库', 'n'), ('词表', 'n'), ('来自', 'v'), ('主流', 'b'), ('网站', 'n'), ('社会', 'n'), ('标签', '财经'), ('搜索', 'v'), ('热词', 'n'), ('输入法', 'IT'), ('词库', 'n')]
一些词语被赋予特殊类型IT,而“是”等词语被筛出。
从比较大量的文本中利用一些统计指标发现新词。(可选)通过提供一些种子词语来确定怎样程度质量的词语可以被发现。(即至少所有的种子词会被发现,在满足一定的基础要求的前提下。)
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
#返回关于新词质量的一系列信息,允许手工改进筛选(pd.DataFrame型)
new_words_info = ht.word_discover(para)
#new_words_info = ht.word_discover(para, threshold_seeds=["武磊"])
new_words = new_words_info.index.tolist()
print(new_words)["武磊"]
高级设置(展开查看)
可以使用`excluding_words`参数来去除自己不想要的结果,默认包括了停用词。算法使用了默认的经验参数,如果对结果数量不满意,可以设置auto_param=False自己调整参数,调整最终获得的结果的数量,相关参数如下:
:param max_word_len: 允许被发现的最长的新词长度
:param min_freq: 被发现的新词,在给定文本中需要达到的最低频率
:param min_entropy: 被发现的新词,在给定文本中需要达到的最低左右交叉熵
:param min_aggregation: 被发现的新词,在给定文本中需要达到的最低凝聚度
比如,如果想获得比默认情况更多的结果(比如有些新词没有被发现),可以在默认参数的基础上往下调,下面的默认的参数:
min_entropy = np.log(length) / 10
min_freq = min(0.00005, 20.0 / length)
min_aggregation = np.sqrt(length) / 15
具体的算法细节和参数含义,参考:http://www.matrix67.com/blog/archives/5044
使用结巴词典过滤旧词(展开查看)
``` from harvesttext.resources import get_jieba_dict jieba_dict = get_jieba_dict(min_freq=100) print("jiaba词典中的词频>100的词语数:", len(jieba_dict)) text = "1979-1998-2020的喜宝们 我现在记忆不太好,大概是拍戏时摔坏了~有什么笔记都要当下写下来。前几天翻看,找着了当时记下的话.我觉得喜宝既不娱乐也不启示,但这就是生活就是人生,10/16来看喜宝吧" new_words_info = ht.word_discover(text, excluding_words=set(jieba_dict), # 排除词典已有词语 exclude_number=True) # 排除数字(默认True) new_words = new_words_info.index.tolist() print(new_words) # ['喜宝'] ```根据反馈更新 原本默认接受一个单独的字符串,现在也可以接受字符串列表输入,会自动进行拼接
根据反馈更新 现在默认按照词频降序排序,也可以传入sort_by='score'参数,按照综合质量评分排序。
发现的新词很多都可能是文本中的特殊关键词,故可以把找到的新词登录,使后续的分词优先分出这些词。
def new_word_register():
new_words = ["落叶球","666"]
ht.add_new_words(new_words) # 作为广义上的"新词"登录
ht.add_new_entity("落叶球", mention0="落叶球", type0="术语") # 作为特定类型登录
print(ht.seg("这个落叶球踢得真是666", return_sent=True))
for word, flag in ht.posseg("这个落叶球踢得真是666"):
print("%s:%s" % (word, flag), end=" ")这个 落叶球 踢 得 真是 666
这个:r 落叶球:术语 踢:v 得:ud 真是:d 666:新词
也可以使用一些特殊的规则来找到所需的关键词,并直接赋予类型,比如全英文,或者有着特定的前后缀等。
# find_with_rules()
from harvesttext.match_patterns import UpperFirst, AllEnglish, Contains, StartsWith, EndsWith
text0 = "我喜欢Python,因为requests库很适合爬虫"
ht0 = HarvestText()
found_entities = ht0.find_entity_with_rule(text0, rulesets=[AllEnglish()], type0="英文名")
print(found_entities)
print(ht0.posseg(text0)){'Python', 'requests'}
[('我', 'r'), ('喜欢', 'v'), ('Python', '英文名'), (',', 'x'), ('因为', 'c'), ('requests', '英文名'), ('库', 'n'), ('很', 'd'), ('适合', 'v'), ('爬虫', 'n')]
使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段。
ht0 = HarvestText()
text = """备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”"""
print("原始文本[5段]")
print(text+"\n")
print("预测文本[手动设置分3段]")
predicted_paras = ht0.cut_paragraphs(text, num_paras=3)
print("\n".join(predicted_paras)+"\n")原始文本[5段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。
田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。
新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
预测文本[手动设置分3段]
备受社会关注的湖南常德滴滴司机遇害案,将于1月3日9时许,在汉寿县人民法院开庭审理。此前,犯罪嫌疑人、19岁大学生杨某淇被鉴定为作案时患有抑郁症,为“有限定刑事责任能力”。
新京报此前报道,2019年3月24日凌晨,滴滴司机陈师傅,搭载19岁大学生杨某淇到常南汽车总站附近。坐在后排的杨某淇趁陈某不备,朝陈某连捅数刀致其死亡。事发监控显示,杨某淇杀人后下车离开。随后,杨某淇到公安机关自首,并供述称“因悲观厌世,精神崩溃,无故将司机杀害”。据杨某淇就读学校的工作人员称,他家有四口人,姐姐是聋哑人。
今日上午,田女士告诉新京报记者,明日开庭时间不变,此前已提出刑事附带民事赔偿,但通过与法院的沟通后获知,对方父母已经没有赔偿的意愿。当时按照人身死亡赔偿金计算共计80多万元,那时也想考虑对方家庭的经济状况。田女士说,她相信法律,对最后的结果也做好心理准备。对方一家从未道歉,此前庭前会议中,对方提出了嫌疑人杨某淇作案时患有抑郁症的辩护意见。另具警方出具的鉴定书显示,嫌疑人作案时有限定刑事责任能力。新京报记者从陈师傅的家属处获知,陈师傅有两个儿子,大儿子今年18岁,小儿子还不到5岁。“这对我来说是一起悲剧,对我们生活的影响,肯定是很大的”,田女士告诉新京报记者,丈夫遇害后,他们一家的主劳动力没有了,她自己带着两个孩子和两个老人一起过,“生活很艰辛”,她说,“还好有妹妹的陪伴,现在已经好些了。”
与原始论文中不同,这里以分句结果作为基本单元,而使用不是固定数目的字符,语义上更加清晰,且省去了设置参数的麻烦。因此,默认设定下的算法不支持没有标点的文本。但是可以通过把seq_chars设置为一正整数,来使用原始论文的设置,为没有标点的文本来进行分段,如果也没有段落换行,请设置align_boundary=False。例见examples/basic.py中的cut_paragraph():
print("去除标点以后的分段")
text2 = extract_only_chinese(text)
predicted_paras2 = ht0.cut_paragraphs(text2, num_paras=5, seq_chars=10, align_boundary=False)
print("\n".join(predicted_paras2)+"\n")去除标点以后的分段
备受社会关注的湖南常德滴滴司机遇害案将于月日时许在汉寿县人民法院开庭审理此前犯罪嫌疑人岁大学生杨某淇被鉴定为作案时患有抑郁症为有
限定刑事责任能力新京报此前报道年
月日凌晨滴滴司机陈师
傅搭载岁大学生杨某淇到常南汽车总站附近坐在后排的杨某淇趁陈某不备朝陈某连捅数刀致其死亡事发监控显示杨某淇杀人后下车离开随后杨某淇
到公安机关自首并供述称因悲观厌世精神崩溃无故将司机杀害据杨某淇就读学校的工作人员称他家有四口人姐姐是聋哑人今日上午田女士告诉新京
报记者明日开庭时间不变此前已提出刑事附带民事赔偿但通过与法院的沟通后获知对方父母已经没有赔偿的意愿当时按照人身死亡赔偿金计算共计
多万元那时也想考虑对方家庭的经济状况田女士说她相信法律对最后的结果也做好心理准备对方一家从未道歉此前庭前会议中对方提
出了嫌疑人杨某淇作案时患有抑郁症的辩护意见另具警方出具的鉴定书显示嫌疑人作案时有限定刑事责任能力新京
报记者从陈师傅的家属处获知陈师傅有两个儿子大儿子今年岁小儿子还不到岁这对我来说是一起悲剧对我们生活的影响肯定是很大的田女士告诉新
京报记者丈夫遇害后他们一家的主劳动力没有了她自己带着两个孩子和两个老人一起过生活很艰辛她说还好有妹妹的陪伴现在已经好些了
可以本地保存模型再读取复用,也可以消除当前模型的记录。
from harvesttext import loadHT,saveHT
para = "上港的武磊和恒大的郜林,谁是中国最好的前锋?那当然是武磊武球王了,他是射手榜第一,原来是弱点的单刀也有了进步"
saveHT(ht,"ht_model1")
ht2 = loadHT("ht_model1")
# 消除记录
ht2.clear()
print("cut with cleared model")
print(ht2.seg(para))具体实现及例子在naiveKGQA.py中,下面给出部分示意:
QA = NaiveKGQA(SVOs, entity_type_dict=entity_type_dict)
questions = ["你好","孙中山干了什么事?","谁发动了什么?","清政府签订了哪些条约?",
"英国与鸦片战争的关系是什么?","谁复辟了帝制?"]
for question0 in questions:
print("问:"+question0)
print("答:"+QA.answer(question0))问:孙中山干了什么事?
答:就任临时大总统、发动护法运动、让位于袁世凯
问:谁发动了什么?
答:英法联军侵略中国、国民党人二次革命、英国鸦片战争、日本侵略朝鲜、孙中山护法运动、法国侵略越南、英国侵略中国西藏战争、慈禧太后戊戌政变
问:清政府签订了哪些条约?
答:北京条约、天津条约
问:英国与鸦片战争的关系是什么?
答:发动
问:谁复辟了帝制?
答:袁世凯
本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持。
需要使用这些功能,需要创建一个专门英语模式的HarvestText对象。
# ♪ "Until the Day" by JJ Lin
test_text = """
In the middle of the night.
Lonely souls travel in time.
Familiar hearts start to entwine.
We imagine what we'll find, in another life.
""".lower()
ht_eng = HarvestText(language="en")
sentences = ht_eng.cut_sentences(test_text) # 分句
print("\n".join(sentences))
print(ht_eng.seg(sentences[-1])) # 分词[及词性标注]
print(ht_eng.posseg(sentences[0], stopwords={"in"}))
# 情感分析
sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=["familiar"], neg_seeds=["lonely"],
min_times=1, stopwords={'in', 'to'})
print("sentiment analysis")
for sent0 in sentences:
print(sent0, "%.3f" % ht_eng.analyse_sent(sent0))
# 自动分段
print("Segmentation")
print("\n".join(ht_eng.cut_paragraphs(test_text, num_paras=2)))
# 情感分析也提供了一个内置英文词典资源
# from harvesttext.resources import get_english_senti_lexicon
# sent_lexicon = get_english_senti_lexicon()
# sent_dict = ht_eng.build_sent_dict(sentences, pos_seeds=sent_lexicon["pos"], neg_seeds=sent_lexicon["neg"], min_times=1)in the middle of the night.
lonely souls travel in time.
familiar hearts start to entwine.
we imagine what we'll find, in another life.
['we', 'imagine', 'what', 'we', "'ll", 'find', ',', 'in', 'another', 'life', '.']
[('the', 'DET'), ('middle', 'NOUN'), ('of', 'ADP'), ('the', 'DET'), ('night', 'NOUN'), ('.', '.')]
sentiment analysis
in the middle of the night. 0.000
lonely souls travel in time. -1.600
familiar hearts start to entwine. 1.600
we imagine what we'll find, in another life. 0.000
Segmentation
in the middle of the night. lonely souls travel in time. familiar hearts start to entwine.
we imagine what we'll find, in another life.
目前对英语的支持并不完善,除去上述示例中的功能,其他功能不保证能够使用。
本库正在开发中,关于现有功能的改善和更多功能的添加可能会陆续到来。欢迎在issues里提供意见建议。觉得好用的话,也不妨来个Star~
感谢以下repo带来的启发: